文章目录[隐藏]
- 视觉招聘小黑板
- 行业资讯
- 星云智联荣获"国家高新技术企业"等三项资质认定--机器视觉网 2023-11-15 13:20:59
- AI+视觉,共话新能源企业数字化转型新可能--机器视觉网 2023-11-15 11:43:22
- 国药外贸深入布局秘鲁及拉美市场,海外再添布点!--机器视觉网 2023-11-15 11:23:32
- 艾迈斯欧司朗携手立功科技与Enabot推出智能机器人EBO X,引领家庭陪伴新潮流--机器视觉网 2023-11-15 10:23:38
- 深视智能高速相机在粒子图像测速(PIV)领域的应用--机器视觉网 2023-11-15 14:16:29
- JAKA携手大型国企打造钢构焊接解决方案,智能“焊”将再添新功能--机器视觉网 2023-11-15 13:58:54
- AI视觉软件Mech-DLK,助力集成商高效解决定位、质检等复杂应用--机器视觉网 2023-11-15 13:37:35
- 比亚迪电池焊后3D+AI视觉检测--机器视觉网 2023-11-15 13:28:48
- AI+视觉共话新能源企业数字化转型新可能―新闻频道- 视觉系统设计 2023/11/15 14:51:46
- SPS广州展欧洲展团全新启航―新闻频道- 视觉系统设计 2023/11/14 23:59:27
- “The Difference Is – Now The Whole World Is Paying Attention To AI,” Says Prof. Serge Belongie: 2023-11-14T10:40:00-0500
- Adobe快两个数量级的3D生成方法;FlashFFTConv可将FFT卷积加速高达7.93倍;LLM元提示;可微VQ-VAE 2023-11-13 18:50
- Nat. Med. | 基于视觉和语言的基础模型,用于病理图像分析 2023-11-15 15:31
- 香港科技大学(广州)IRPN实验室招聘 2023-11-15 03:28
- 多模态超详细解读 (十三):LM4VisualEncoding:语言模型中的冻结编码器来提取视觉特征 2023-11-15 16:40
- 视觉基础模型总结 2023-11-14 23:22
- 视觉检测的原理以及组成部分 2023-11-15 11:00
- CV计算机视觉每日开源代码Paper with code速览-2023.11.15 2023-11-15 17:09
- 首个!SpectralGPT:光谱遥感基础模型 2023-11-15 00:06
- A Deep Dive into Paperspace's Infrastructure: 2023-11-15T02:56:26.000Z
- Fine-Tuning BERT using Hugging Face Transformers: 2023-11-14T14:00:00+00:00
视觉招聘小黑板
机器视觉算法工程师 ,1.5-2万·14薪武汉·洪山区3-4年本科,医疗设备/器械民营
机器视觉应用工程师 ,5-7千深圳·宝安区无需经验大专,计算机软件民营
机器视觉主任工程师 ,1.8-2.5万江门5-7年本科,机械/设备/重工外资(非欧美)
机器视觉调试工程师 ,8千-1.5万重庆·渝北区3-4年大专,仪器仪表/工业自动化民营
机器视觉应用工程师 ,9千-1.5万惠州·大亚湾区1年本科,电子技术/半导体/集成电路民营
机器视觉开发工程师 ,1-1.5万苏州2年本科,汽车零配件民营
销售经理(机器视觉) ,13-26万/年深圳3-4年大专,仪器仪表/工业自动化外资(非欧美)
高级机器视觉工程师 ,1.2-2万昆山3-4年本科,多元化业务集团公司国企
机器视觉售后工程师 ,7千-1万苏州·吴江区1年大专,机械/设备/重工民营
机器视觉开发工程师 ,1.3-2.5万·13薪苏州2年大专,仪器仪表/工业自动化民营
机器视觉工程师 ,2-2.5万东莞·大岭山镇3-4年本科,仪器仪表/工业自动化民营
机器视觉产品工程师 ,8千-1.5万东莞·长安镇3-4年本科,仪器仪表/工业自动化已上市
机器视觉工程师 ,1.5-2.5万·13薪深圳·南山区2年本科,计算机软件外资(非欧美)
机器视觉工程师 ,1.1-2.2万·13薪深圳·南山区3-4年本科,仪器仪表/工业自动化民营
技术支持工程师(机器视觉) ,7-8.5千·13薪东莞·南城区1年大专,仪器仪表/工业自动化民营
机器视觉FAE ,1-2万深圳·南山区3-4年大专,计算机硬件民营
机器视觉工程师 ,1-1.8万苏州2年本科,电子技术/半导体/集成电路民营
机器视觉软件工程师 ,1-2万深圳·宝安区1年本科,电子技术/半导体/集成电路民营
机器视觉调试工程师 ,1.2-1.8万北京·通州区3-4年大专,仪器仪表/工业自动化民营
机器视觉工程师 ,1.5-2.5万深圳·南山区3-4年本科,机械/设备/重工民营
欲了解详情,请在公众号后台回复:231115
行业资讯
星云智联荣获"国家高新技术企业"等三项资质认定--机器视觉网 2023-11-15 13:20:59
2023-11-15 13:20:59 来源: 中国机器视觉网
近日,由全国高新技术企业认定管理工作领导小组办公室发布的《关于深圳市认定机构2023年认定报备的第一批高新技术企业拟进行备案的公示》、深圳市龙华区工业和信息化局发布的《关于龙华区2023年创新型中小企业名单的公示》及深圳市龙华区科技创新局发布的《关于龙华区2022年度中小微创新100强企业名单公示》三份公告中,深圳星云智联科技有限公司上榜,荣获“国家高新技术企业”、“创新型中小企业”和“龙华区2022年度中小微创新100强”认定称号,上述资质的获得,标志着公司在技术创新和科技研发方面的实力得到了政府对口部门及行业的认可和肯定。
高新技术企业是指在国家重点支持的高新技术领域内,持续进行研究开发与技术成果转化,形成企业核心自主知识产权,并以此为基础
......长按二维码访问原文

AI+视觉,共话新能源企业数字化转型新可能--机器视觉网 2023-11-15 11:43:22
2023-11-15 11:43:22 来源: 中国机器视觉网
近日,“新能源·芯机遇2023新能源行业数字化赋能高峰论坛”中,维视智造作为新能源数字化领域代表企业受邀参会,在论坛圆桌环节与嘉宾共同探讨“双碳”目标下的新能源智能制造发展前景。维视智造负责人魏代强与一众嘉宾共同分享了企业在数字化转型与创新的落地路径、大模型之下人工智能的落地模式等方面的多类变革。
AI+视觉 ,助力智能制造创新发展
魏总表示,新能源企业数字化生产面临的难点和痛点主要包括以下几点:
第一,设备智能化能力不足,新能源设备往往涉及复杂的工艺流程和高度技术化的操作,生产设备的智能化程度和数据采集管理水平参差不齐,生产过程的全面数字化还待优化;第二,数据整合难度大,生产过程中会产生的大量数据往往分散在不同的系统和管理平台中,难以实现
......长按二维码访问原文

国药外贸深入布局秘鲁及拉美市场,海外再添布点!--机器视觉网 2023-11-15 11:23:32
国药外贸深入布局秘鲁及拉美市场,海外再添布点!
2023-11-15 11:23:32 来源: 中国机器视觉网
为进一步深耕拉美市场,国药外贸正式设立秘鲁办公室,成为国药外贸海外布局的又一重要根据地。
今年是共建“一带一路”倡议提出十周年,秘鲁是我国“一带一路”倡议的重要合作伙伴之一,根据《对外投资合作国别(地区)指南》,中国是秘鲁全球第一大贸易伙伴、第一大出口市场和第一大进口来源国,秘鲁是中国在拉美地区的第四大贸易伙伴。
国药外贸积极贯彻落实“一带一路”倡议,深耕秘鲁市场已有20余年之久,已成为中国对秘鲁出口西药制剂最大的公司之一。近年来,在秘业务已覆盖医疗器械、原料等多个板块,并且积极探索更多医院建设、医疗设备供应等医疗民生项目合作的可能性,挖掘高质量合作机会。
作为国药集团在拉丁美洲国际经营
......长按二维码访问原文

艾迈斯欧司朗携手立功科技与Enabot推出智能机器人EBO X,引领家庭陪伴新潮流--机器视觉网 2023-11-15 10:23:38
2023-11-15 10:23:38 来源: 中国机器视觉网
2023年11月14日,艾迈斯欧司朗今日宣布,通过与立功科技合作,携手家庭机器人供应商Enabot成功推出AI智能陪伴机器人EBO X。。该机器人依托立功科技的算法技术支持,并搭载艾迈斯欧司朗的TMF8821传感器,实现自动避障、防跌落和辅助建图功能。
随着AI技术的日益成熟,陪伴机器人逐渐进入家庭场景,并成为拉近亲子关系的重要一环。作为一款家庭机器人,有效避障是实现安全移动、智能看护的前提。然而,在家庭空间中存在布局多样、动态障碍较多等问题。因此在使用的过程中,机器人常常面临感知不准确、路径规划不清晰等挑战。为了应对这些挑战,艾迈斯欧司朗携手广州立功科技,助力Enabot推出家庭陪伴机器人EBO X,旨在提升其避障能力并增加其移动灵活性。
......长按二维码访问原文

深视智能高速相机在粒子图像测速(PIV)领域的应用--机器视觉网 2023-11-15 14:16:29
2023-11-15 14:16:29 来源: 中国机器视觉网
作为一种可视化测量的方法,粒子图像测速(Particle Image Velocimetry,简称PIV)是一种具有瞬态、多点、非接触式等特点的激光流体力学测速方法。
流场矢量图
PIV技术的特点突破了CTA、LDA等单点测速技术的局限性,能够在同一瞬态下记录大量空间点上的速度分布信息,并可提供丰富的流场空间结构及其流动特性,计算出流场中各点的流速矢量以及流场速度矢量图、速度分量图、流线图等运动参量。
PIV测速原理
PIV技术的原理是通过在被测流场中布撒示踪粒子,并在激光片光源的照射下,利用图像记录设备连续获得时间序列图像,再运用图像处理算法,得到粒子在图像上的位移。
当已知曝光间隔时间Δt=t2-t1,以及获得粒子在图像上的平均速度
......长按二维码访问原文

JAKA携手大型国企打造钢构焊接解决方案,智能“焊”将再添新功能--机器视觉网 2023-11-15 13:58:54
2023-11-15 13:58:54 来源: 中国机器视觉网
钢结构是目前主要的建筑结构类型之一,广泛应用于高层建筑、桥梁、大型公共场所等建筑物中。焊接是钢结构制造中十分重要的加工工艺,传统钢结构焊接多采用人工作业,对工人焊接技能要求高,且焊接的质量主要取决于焊工水平和状态,焊接质量差异大,人工劳动强度较大。近年来,企业面临着焊工老龄化,劳动力短缺等问题,而一般的视觉识别焊接设备对钢结构组对要求较高,识别率不足,因此,企业迫切需要更为自动化、智能化的钢结构焊接解决方案。
客户背景及需求:
芜湖天航重工股份有限公司是历史悠久的国有大型企业,主营业务为重型钢结构制造、装配式建筑制安、智能制造等。客户企业对大型钢结构焊接需求大,希望能够通过提高焊接工艺的自动化和智能化水平,解决焊工短缺问题,同时提高生产效率和
......长按二维码访问原文

AI视觉软件Mech-DLK,助力集成商高效解决定位、质检等复杂应用--机器视觉网 2023-11-15 13:37:35
2023-11-15 13:37:35 来源: 中国机器视觉网
近日,梅卡曼德对AI视觉软件Mech-DLK进行了重磅升级。全新升级的Mech-DLK内置快速定位、目标检测、缺陷分割、实例分割、图像分类五大深度学习算法,功能更丰富,易用性更强。支持集成商伙伴“端到端”地完成高精度深度学习模型训练,高效解决定位、质检等工业场景中的复杂应用。目前,Mech-DLK已广泛应用于汽车、物流、重工、3C/半导体等众多领域,助力客户提升生产效率、产品良率,降低产线用工成本。
Mech-DLK功能&优势
· Mech-DLK五大深度学习算法
快速定位:检测图像目标区域中的物体,并旋转图像至指定朝向。目标检测:检测所有目标物体的位置,并支持类别判断。缺陷分割:用于检出各类缺陷,支持缺陷微小、背景复杂、工件位置不固定等复
......长按二维码访问原文

比亚迪电池焊后3D+AI视觉检测--机器视觉网 2023-11-15 13:28:48
2023-11-15 13:28:48 来源: 中国机器视觉网
随着3D相机在工业AI的普及,深度学习对3D点云和深度图的分析方法也越来越多样化。在3D计算机图形中,Depth Map(深度图)是包含与视点的场景对象的表面的距离有关的信息的图像或图像通道。其中,Depth Map 类似于灰度图像,只是它的每个像素值是传感器距离物体的实际距离。通常RGB图像和Depth图像是配准的,因而像素点之间具有一对一的对应关系,合成的四通道的图像称为RGB-D图像。如下图:
在业内,不少工作已经将CNN引入在RGB-D图像上的视觉任务上,这些工作中一部分直接采用4-channel的图像来进行语义分割。我们可以将3D点云做正射纠正,生成对应的深度图。再将2D图像做同样的仿射纠正,合成RGB-D图像。我们可以压缩数据量,将
......长按二维码访问原文

AI+视觉共话新能源企业数字化转型新可能―新闻频道- 视觉系统设计 2023/11/15 14:51:46
近日,“新能源·芯机遇2023新能源行业数字化赋能高峰论坛”在江苏常州隆重召开。本次论坛由常州市人民政府、中国能源研究会指导,武进区人民政府、常州市工业和信息化局、英特尔(中国)有限公司、阿里云计算有限公司共同举办,旨在通过数字化赋能、推动新能源产业创新发展。
论坛聚焦了以新能源领域数字化转型标杆政企单位为代表的「数字化行业变革者」及以数字化技术和解决方案提供方为代表的「数字化行业创新者」,共同探讨和分享最新的数字化趋势、创新技术和可持续发展的机遇与挑战。维视智造作为新能源数字化领域代表企业受邀参会,在论坛圆桌环节与嘉宾共同探讨“双碳”目标下的新能源智能制造发展前景。
一、AI+视觉,助力智能制造创新发展
在论坛的圆桌讨论环节,维视智造负责人魏代强与天合光能集团IT-智能制造部负责人顾志峰、国能日新副总经
......长按二维码访问原文

SPS广州展欧洲展团全新启航―新闻频道- 视觉系统设计 2023/11/14 23:59:27
2023年第一季度,中国对欧盟出口5063亿美元,同比增长25%,占中国总出口的17.6%;从欧盟进口3894.2亿美元,同比增长15%,占中国总进口的13.5%;中欧贸易顺差1168.8亿美元,同比扩大35%。欧盟已成为中国2023年第一季度最大的贸易伙伴,中欧已形成强大的经济共生关系。
为了欧洲品牌原厂、在华子公司或在华办事处更好地拓展亚洲市场,打造 “Made in Europe” 品质,明年SPS广州智能制造展将规划“欧洲展团”,为欧洲企业创造更多商机。
加入欧洲展团福利:
- 贸易配对活动
- 定制宣传单页
- 现场国内买家采购团
展品范围:
控制技术
电气驱动及运动控制
传感技术
连接技术
工业机器人
机器视觉
软件与IT
机械基础设施
工业通讯
人机界面装置
工业
......长按二维码访问原文

“The Difference Is – Now The Whole World Is Paying Attention To AI,” Says Prof. Serge Belongie: 2023-11-14T10:40:00-0500
In 1995, Serge Belongie earned a B.S. (with honor) in EE from Caltech, followed by a Ph.D. in EECS from Berkeley in 2000. From 2001-2013, he served as a professor in the Department of Computer Science and Engineering at the University of California, San Diego.
Serge co-founded Digital Persona, the world’s first mass-market fingerprint identification device,
......长按二维码访问原文

Adobe快两个数量级的3D生成方法;FlashFFTConv可将FFT卷积加速高达7.93倍;LLM元提示;可微VQ-VAE 2023-11-13 18:50

Instant3D: Fast Text-to-3D with Sparse-View Generation and Large Reconstruction Model
本文提出了一种名为Instant3D的新方法,它可以从文本提示中以前馈方式生成高质量和多样化的3D内容。该方法采用两阶段模式,首先通过微调的2D文本到图像扩散模型一次性生成四个结构化一致的视图,然后使用基于transformer的稀疏视图重建模型直接从生成的图像中回归NeRF。作者通过证明了此方法可以在20秒内生成高质量、多样化和无Janus problem 的3D内容,比以前基于优化的方法(需要1到10个小时)快两个数量级。
FlashFFTConv: Efficient Convolutions for Long Se
......长按二维码访问原文

Nat. Med. | 基于视觉和语言的基础模型,用于病理图像分析 2023-11-15 15:31

今天为大家介绍的是来自James Zou 团队的一篇论文。公开可用的医学图像缺乏注释,成为计算研究和教育创新的主要障碍。与此同时,许多医生在医学Twitter等公共论坛上分享了匿名化的图像和大量知识。在这里,作者利用这些群体平台来策划OpenPath,这是一个包含208,414张病理图像与自然语言描述配对的大型数据集。通过开发病理语言-图像预训练(PLIP)来展示这个数据资源的价值,这是一个具有图像和文本理解能力的多模式人工智能,它在OpenPath上进行了训练。
在计算病理学中,人工智能(AI)算法可以帮助区分细胞或组织类型,生成诊断结果,并从常规染色的血红素和伊红染色(H&E)图像中检索相关图像。尽管存在几个高质量的专项机器学习数据集,如Pan-Nuke、Lizard和NuCLS等,但计算病理学的进展受到
......长按二维码访问原文

香港科技大学(广州)IRPN实验室招聘 2023-11-15 03:28
香港科技大学(广州)IRPN实验室招收博士、研究助理、实习生
研究方向:三维计算机视觉,机器人定位与建图等
(以下信息更新于2023年11月15日)
团队现招收于 2024年9月 入学的 博士生 和若干名于 2024年3月或更晚 入职的 研究助理 。同时 长期 招收 实习生 。(团队未来也将招聘博士后。若有兴趣,可提前联系。)
【导师介绍】
李昊昂博士将于2024年2月加入香港科技大学(广州)机器人与自主系统学域Robotics and Autonomous Systems (ROAS) Thrust担任助理教授,并组建智能机器人感知与导航实验室Intelligent Robot Perception and Navigation (IRPN) Lab。他现为慕尼黑工业大学博士后研究员,师从Danie
......长按二维码访问原文

多模态超详细解读 (十三):LM4VisualEncoding:语言模型中的冻结编码器来提取视觉特征 2023-11-15 16:40
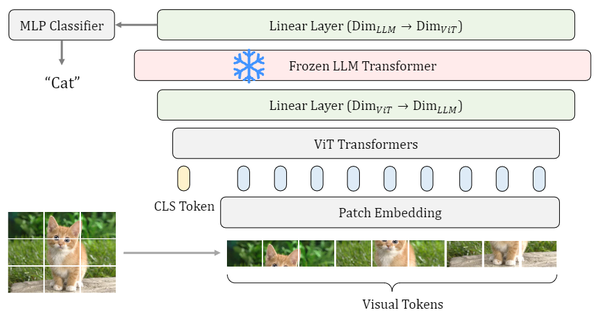
本系列已授权极市平台,未经允许不得二次转载,如有需要请私信作者。
专栏目录
本文目录
1 LM4VisualEncoding:语言模型中的冻结编码器来提取视觉特征
(来自伊利诺伊大学香槟分校)
1.1 背景:当 LLM 遇到视觉任务
1.2 LM4VisualEncoding 框架
1.3 与 Vision-Language 模型比较
1.4 与 LLM 模型比较
1.5 图像分类实验结果
1.6 多模态任务实验结果
1.7 消融实验:其他的 LLM
1.8 消融实验:更大的 LLM
1.9 添加 LLM 有效的原因猜想:信息过滤假设
太长不看版
LM4VisualEncoding 发现一个有趣的现象:大语言模型 (large language models, LLM),尽管仅在文
......长按二维码访问原文

视觉基础模型总结 2023-11-14 23:22
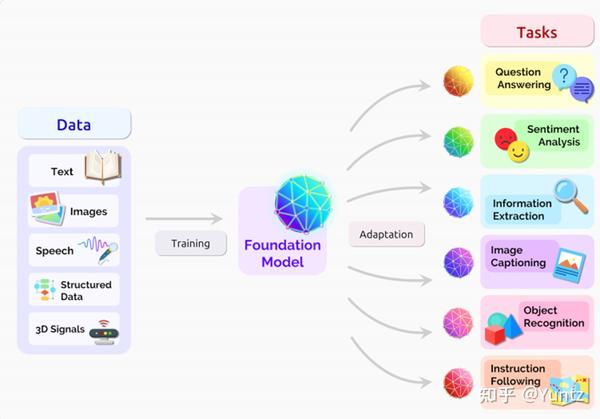
基础模型是什么?
基础模型是指能够从大量数据中提取知识并将其应用于各种下游任务的模型。斯坦福大学基础模型研究中心(CRFM)于 2021 年创造了这一术语,以概括这一范式的意义和挑战[1]。它们基于在海量数据上训练大型神经网络,通常使用自监督学习技术。这样,神经网络就能学习通用的表征和能力,并将其应用到不同的领域和应用中。技术涉及的领域如下图
虽然如何在基础模型中实现这些能力的确切路线图仍然是一个开放问题,但新的高效和灵活的架构(§4.1:建模)、大规模训练(§4.5:系统)、自监督技术(§4.2:训练)和少样本适应方法(§4.3:适应)的组合可能为迄今为止难以达到的能力打开大门。
基础模型的五个关键特性:表达能力、可扩展性、多模态、记忆容量和组合性,实现:
(1)从各种来源和领域提取和积累知识,
(
......长按二维码访问原文

视觉检测的原理以及组成部分 2023-11-15 11:00
机器视觉就是用机器代替人眼来做测量和判断。机器视觉系统是指通过机器视觉产品(即图像摄取装置,分 CMOS 和CCD 两种)将被摄取目标转换成图像信号,传送给专用的图像处理系统,根据像素分布和亮度、颜色等信息,转变成数字化信号;图像系统对这些信号进行各种运算来抽取目标的特征,进而根据判别的结果来控制现场的设备动作。
视觉系统组成部分:
1.照明光源2.镜头3.工业摄像机4.图像采集/处理卡5.图像处理系统6.其它外部设备
视觉检测工作原理,尽管机器视觉应用各异,但都包含以下几个过程:
1.图像采集:光学系统采集图像,将图像转换成数字格式并传入计算机存储器。
2.图像处理:处理器运用不同的算法来提高对检测有影响的图像因素。
3.特征提取:处理器识别并量化图像的关键特征,例如位置、数量、面积等。然后将这些
......长按二维码访问原文

CV计算机视觉每日开源代码Paper with code速览-2023.11.15 2023-11-15 17:09
精华置顶
墙裂推荐!小白如何1个月系统学习CV核心知识:链接
点击@CV计算机视觉,关注更多CV干货
论文已打包,点击进入—>下载界面
点击加入—>CV计算机视觉交流群
1.【基础网络架构:CNN】PadChannel: Improving CNN Performance through Explicit Padding Encoding
2.【语义分割】(ICLR2024)Test-Time Training for Semantic Segmentation with Output Contrastive Loss
3.【医学图像分割:3D】Assessing Test-time Variability for Interactive 3D Medical Image Segmentation
......长按二维码访问原文

首个!SpectralGPT:光谱遥感基础模型 2023-11-15 00:06
一句话总结
SpectralGPT:第一个通用遥感基础模型,专门为使用新型 3D 生成预训练Transformer(GPT) 处理光谱遥感图像而构建的,对一百万个光谱 RS 图像进行训练,超6亿参数,在四个下游任务(分类/分割/变化检测等)上性能表现SOTA!
SpectralGPT
SpectralGPT: Spectral Foundation Model
单位:中科院, 国科大, 东南大学, 东京大学, 慕尼黑工业大学等(6位IEEE Fellow)
论文:https://arxiv.org/abs/2311.07113
基础模型最近因其以自监督的方式彻底改变视觉表征学习领域的潜力而引起了极大的关注。 虽然大多数基础模型都是为有效处理各种视觉任务的 RGB 图像而定制的,但针对光谱数据的研究存
......长按二维码访问原文

A Deep Dive into Paperspace's Infrastructure: 2023-11-15T02:56:26.000Z
In this article, we overview the infrastructure that allows Paperspace to serve its powerful GPU, CPU, and IPU machines.
Add speed and simplicity to your Machine Learning workflow today Get started
Cloud computing has significantly transformed the manner in which people and entities acquire and use computer resources. Paperspace, a prominent supplier of cl
......长按二维码访问原文

Fine-Tuning BERT using Hugging Face Transformers: 2023-11-14T14:00:00+00:00

BERT, an acronym for Bidirectional Encoder Representations from Transformers, is a Natural Language Processing model that revolutionized the domain with its capability to understand the nuances of language in a bidirectional context, as opposed to the traditional left-to-right or right-to-left architectures. What sets BERT apart is its ability to grasp the c
......长按二维码访问原文







