文章目录[隐藏]
- 视觉招聘小黑板
- 行业资讯
- 在控制、自动化领域,用到的最高深最先进的数学理论工具是什么?控制是否是工科里用到数学最多最深的领域? 2022-08-25 15:27
- 大族机器人:用机器人技术助力PCB行业智造升级--机器视觉网 2023-12-25 15:30:08
- 钜融集团与深慧视达成战略合作意向,紧盯以机器视觉为核心的重点发展方向--机器视觉网 2023-12-25 15:23:51
- 全国首个MaaS模型即服务标准!腾讯云牵头编制--机器视觉网 2023-12-25 15:17:35
- 文心大模型率先通过国家大模型标准测试--机器视觉网 2023-12-25 15:07:32
- ToF相机与畜牧业:数字化养殖的关键要素--机器视觉网 2023-12-25 17:44:56
- 深视智能位移传感器精密点胶行业解决方案--机器视觉网 2023-12-25 17:28:40
- 华汉伟业助力锂电池顶盖焊接质量检测--机器视觉网 2023-12-25 17:19:58
- 国产视觉检测设备崛起,以AI机器视觉及自研算法破解智造难题--机器视觉网 2023-12-25 17:09:05
- 机器视觉光学基础——放大率 视场角--机器视觉网 2023-12-25 16:30:51
- 高精度双目视觉3D点云推动高阶智驾规模化量产落地--机器视觉网 2023-12-25 15:38:04
- 关于工业镜头使用中的常见问题-电子发烧友网 2023-12-23 08:34
- 金维集电成功上市辅导备案,获国家级高新技术认定-电子发烧友网 2023-12-25 15:04
- 卫星导航-电子发烧友网 2023-12-25
- 【机器视觉】3D抓取—基于模板匹配 2023-12-25 11:15:10
- 机器视觉的四大核心功能-电子发烧友网 2023-12-25 11:15
- MagikEye推出Pico深度传感器:为机器人时代提供人工智能之眼―新闻频道- 视觉系统设计 2023/12/25 10:58:42
- 海思机器人开发平台首次实现了基于dToF全向3D立体感知拼接避障方案―新闻频道- 视觉系统设计 2023/12/23 11:02:01
- 艾迈斯欧司朗推炫彩新作,引领纤薄照明新世代―新闻频道- 视觉系统设计 2023/12/22 23:35:46
- Xscale像素尺寸缩放功能使Go-X系列如虎添翼 ―技术与应用频道- 视觉系统设计 2023/12/25 10:39:59
- 智光眼焊接专用相机助力工业智能化焊接―技术与应用频道- 视觉系统设计 2023/12/23 10:55:14
- 晶圆缺陷检测,解决“螺旋线”运动轨迹及“等弧长触发”难题―技术与应用频道- 视觉系统设计 2023/12/22 23:50:54
- 控制工程网-全球工控自动化和智能制造门户网站 2023/11/14 14:00:00
- 2023年小型计算机视觉总结 2023-12-24 09:55
- MAE论文解读 2023-12-25 12:00
- SPGroup3D:室内3D物体检测的超点分组网络(代码已开源) 2023-12-24 16:09
- 关于Diffusion模型在计算机视觉领域中的应用现状调研 2023-12-25 14:15
- 3D点云自监督预训练的自编码器 :Point-M2AE - 知乎 2023-12-25 15:58
- ICLR2023 | 3D表示新网络:多视图+点云! 2023-12-25 15:19
- 在自动驾驶企业摆脱高精地图依赖的情况下,SLAM算法在自动驾驶行车过程中还有什么意义? 2023-12-25 16:18
- 遥遥领先!华为SOTA!无监督自适应3D目标检测!ICCV2023!即将开源! 2023-12-25 18:04
- CV计算机视觉每日开源代码Paper with code速览-2023.12.24 2023-12-25 01:03
- CVPR 2022 真实超分:LDL 2023-12-25 10:54
- 中科大&华为提出TinySAM:突破高效分割一切模型的极限 2023-12-24 17:28
- CVPR2023 | 如何设计一个更快更鲁棒的P3P求解器? 2023-12-25 17:41
- 卷积神经网络中的平移等变性分析 2023-12-25 12:09
- 【三维重建实战】手把手搭建自己的3D扫描仪 2023-12-24 10:42
- 实时动态手部重建的3D点喷洒技术 2023-12-24 10:54
- 神奇!G-SHELL:一种强大且通用的3D表示 2023-12-25 17:25
- CVPR2023 Highlight|ECON:最新单图穿衣人三维重建SOTA算法 2023-12-25 17:37
视觉招聘小黑板
欲了解详情,请在公众号后台回复:231225
行业资讯
在控制、自动化领域,用到的最高深最先进的数学理论工具是什么?控制是否是工科里用到数学最多最深的领域? 2022-08-25 15:27
控制不是工科数学最多的,上面还有信息论 ,平级的还有信号处理。
我之前给想要真心做理论的学生的建议: 学好线性代数+矩阵的各种技巧,然后随机和凸优化掌握至少一个。这几个哪个方向都有用,哪怕你不搞控制都有用。
学随机的另外好处是可以故作高深,比如各种收敛来回搞。比如 u(k) 是 y(0),\ldots,y(k) 的函数,你可以说 y(0),\ldots,y(k) 生成了一个filtration叫做 \{\mathcal F_k\} ,然后u(k) is adapted with respect to这个filtration。
特定研究方向可能再额外补一补,比如频域的话弄弄复变,非线性搞搞微分几何。另外就是我个人99%做的都是离散时间,毕竟计算机啥的都是离散的,要是搞连续时间的话也许再补补分析吧。不过说实话
......长按二维码访问原文

大族机器人:用机器人技术助力PCB行业智造升级--机器视觉网 2023-12-25 15:30:08
2023-12-25 15:30:08 来源: 中国机器视觉网
PCB是电子产品之母,它是承载电子元器件并连接电路的桥梁,应用非常广泛,几乎所有电子设备都需要用到它。随着新一代信息技术的不断突破,以车载ADAS、可穿戴设备、AR/VR元宇宙设备等领域为代表的新兴电子产品市场快速崛起,推动了中高端PCB需求的快速增长;与此同时,行业竞争加剧,PCB企业盈利空间不断压缩。当务之急,企业需要找到能够提高产能、缩短交期、加强品控、降低成本、提高管理水平,扩大盈利空间。
今年来,大族机器人深入走访了江西、珠海等地区PCB生产企业,发现产线上的机器人装备呈现出爆发式增长,一些新建厂房已经把机器人作为标配,作为衡量产线自动化的核心指标之一。那么,是哪些原因让工业机器人成了PCB厂竞相配置的“香饽饽”呢?
就加工对象来说
......长按二维码访问原文

钜融集团与深慧视达成战略合作意向,紧盯以机器视觉为核心的重点发展方向--机器视觉网 2023-12-25 15:23:51
2023-12-25 15:23:51 来源: 中国机器视觉网
12月20日,钜融集团董事长、北京闽商联盟投资协会会长郑而兵与协会执行会长黄国潘一行来访深慧视实地考察,联想集团副总裁、深慧视董事长韦卫博士、深慧视副总裁杨坤进行了接待。此次考察旨在增进双方了解,推动业务合作。
洽谈会上,韦卫博士对钜融集团董事长一行表示热烈欢迎并对深慧视、业务发展、产品情况做了详细的介绍。他指出,当前深慧视紧盯以机器视觉为核心的智能制造为重点发展方向,积极探索和拓展与其他相关产业的合作。希望通过本次考察对接,各方能够促成更大范围、更深层次的务实合作。钜融集团董事长郑而兵表示,钜融集团一直注重与优秀企业的合作,深慧视在机器视觉领域具有强大的技术实力,是钜融集团理想的合作伙伴,后续双方将共同探索在智能制造领域的合作机会,并共享资源
......长按二维码访问原文

全国首个MaaS模型即服务标准!腾讯云牵头编制--机器视觉网 2023-12-25 15:17:35
2023-12-25 15:17:35 来源: 中国机器视觉网
AI大模型驱动"智慧涌现",为千行百业带来了全新发展机遇,模型即服务(MaaS)过去一年来也迎来了较快发展与突破。
作为最早一批提出MaaS并实践落地的企业,腾讯云在最近召开的全国信息技术标准化技术委员会人工智能分委会全体会议上,以提案牵头方的身份,正式启动了《人工智能 模型即服务(MaaS)功能要求》的讨论与编制工作。同时,腾讯混元大模型也率先通过国家大模型标准测试。
面对越来越多的科技厂商基于MaaS模式提供大模型产品服务的新形势,这一提案详细规定了MaaS系统的设计、实现、部署和使用,涵盖了用户层、访问层、服务层、跨层功能、运营支撑和安全系统等多维度,旨在规范MaaS领域的标准化工作,更好地实现模型即服务产品或平台的设计、开发、测试及应
......长按二维码访问原文

文心大模型率先通过国家大模型标准测试--机器视觉网 2023-12-25 15:07:32
2023-12-25 15:07:32 来源: 中国机器视觉网
12月22日,在全国信息技术标准化技术委员会人工智能分委会全体会议上,百度文心大模型首批通过大模型标准符合性测试。
“大模型标准符合性测试”由中国电子技术标准化研究院发起,吸收覆盖大模型产业全链路数十家头部单位意见,重点完成大语言模型理解、生成、逻辑等核心能力的38项具体评测维度,以充分检验中国大模型标准符合性水平,引领人工智能产业健康有序发展。
百度是国内AI领域标准的主导力量,多次参与国家人工智能技术标准体系设计和讨论,作为标准核心贡献单位之一,起草人工智能预训练大模型系列国家标准;今年7月,百度被中国电子技术标准化研究院授予“国家人工智能标准化总体组大模型专题组联合组长单位”。此前,百度同时获批向公众开放服务备案和深度合成服务算法备案。
......长按二维码访问原文

ToF相机与畜牧业:数字化养殖的关键要素--机器视觉网 2023-12-25 17:44:56
2023-12-25 17:44:56 来源: 中国机器视觉网
飞行时间(Time-of-Flight)是一种先进的成像技术,它测量光线反弹物体并返回相机的时间,从而实现深度感知和三维建模。虽然ToF相机通常与机器人技术、自动驾驶汽车和增强现实等应用联系在一起,但它们也在畜牧业领域找到了有价值的应用。
ToF相机在畜牧业的应用场景
牲畜监测 & 健康评估:ToF相机可用于监测牲畜在牛舍或户外围栏中的运动和行为。它们提供实时的动物三维跟踪,使饲养者能够观察它们的健康状况;动物的步态或姿势的任何变化都可以早期检测出来,如跛行或受伤。
饲料自动化:ToF相机可以与自动饲料系统集成,以确保为每只动物分发适量的饲料。通过准确测量相机与饲料槽之间的距离,系统可以实时调整饲养过程,减少浪费并确保动物获得适当的营养。
......长按二维码访问原文

深视智能位移传感器精密点胶行业解决方案--机器视觉网 2023-12-25 17:28:40
2023-12-25 17:28:40 来源: 中国机器视觉网
随着工业自动化设备的发展,以手机电子和汽车电子为代表的高精密点胶设备对于点胶等工艺的要求也越来越高。激光位移传感器的精密点胶应用以及光谱共焦位移传感器的胶厚检测应用,一起看看吧。
精密点胶引导
在点胶过程中,头部点胶机厂家桌面型精密三轴点胶机配合深视SD33系列点激光进行高度测距并将数据反馈给上位机,系统则根据所测量的高度值,换算得到点胶阀出胶的最佳焦距位。
精密三轴点胶机应用
同时,根据点激光的反馈数值,点胶设备也将实时补偿Z轴点胶阀高度,防止撞针或点胶异常,保证点胶的精度。
精密五轴点胶机应用
产品介绍
在精密点胶机行业,深视智能SD33系列激光位移传感器能够精准配合完成FATP段、SMT段、TP触摸屏等点胶引导和胶路补偿的工序
......长按二维码访问原文

华汉伟业助力锂电池顶盖焊接质量检测--机器视觉网 2023-12-25 17:19:58
2023-12-25 17:19:58 来源: 中国机器视觉网
随着中国新能源汽车的快速发展,汽车锂电池正迈入大规模制造时代。锂电池生产的成本、技术、制造等水平,决定了新能源汽车的成本、续驶里程和性能,是掣肘新能源汽车发展的核心部件。
项目背景
目前,锂离子动力电池在新能源汽车行业应用广泛。电芯是一个电池系统的最小单元,是车用动力电池的基本结构。电芯的制造是需要经过制浆、涂布、冷压、分切、卷绕、烘焙、注液、化成、二次注液等等一系列精密复杂的过程,最后通过激光焊接工艺将顶盖盖板与电芯外壳密封。
动力电池工艺流程图
在上述流程中,电芯顶盖板焊接作为封口焊接流程的重要一环,关系到锂电池能否安全稳定工作,相关焊接质量问题不容小觑,容易受到激光功率、保护气体以及产品材质等因素影响,极易发生爆点、焊坑、孔洞、断焊
......长按二维码访问原文

国产视觉检测设备崛起,以AI机器视觉及自研算法破解智造难题--机器视觉网 2023-12-25 17:09:05
国产视觉检测设备崛起,以AI机器视觉及自研算法破解智造难题
2023-12-25 17:09:05 来源: 中国机器视觉网
机器视觉作为人工智能的前沿分支之一,被称为智能制造的“智慧之眼”,在工业领域中,能够代替人工完成识别、测量、定位、检测等工作,以实现对设备精密控制及产线智能化、自动化升级。
同时,深度学习和3D视觉的技术升级,实现了对传统机器视觉算法进一步优化并提供了丰富维度的信息。深眸科技整合相关技术,创新研发AI驱动的2D/3D视觉解决方案,赋能制造业实现数智化转型。
国产机器视觉崛起,持续拓展工业场景应用
长期以来,工业视觉检测市场一直被国外厂商垄断,相比于国外完整且成熟的产业链,国内机器视觉在工业领域的技术应用起步较晚。1995-1999年,我国机器视觉行业依靠引进和吸收国外的设备和技术
......长按二维码访问原文

机器视觉光学基础——放大率 视场角--机器视觉网 2023-12-25 16:30:51
2023-12-25 16:30:51 来源: 中国机器视觉网
今天跟大家讲解放大率和视场角这两个基础概念。
一、放大率
机器视觉行业里提到的镜头光学放大倍率通常是指垂轴放大倍率,即像和物的大小之比,计算方法如下:
可见,光学放大倍率和所选相机芯片及所需视场相关。如:已知相机芯片为2/3英寸(8.8mm*6.6mm),视场长宽为:10mm* 8mm。
如用长边计算,放大倍率=8.8mm/10mm=0.88x;如用短边计算,放大倍率=6.6mm/8mm=0.825x;此时应取小的倍率0.825x 作为待选镜头的光学放大倍率。否则,短边视场将不能满足要求。(若取0.88倍,则短边视场=6.6mm/0.88x=7.5mm<8mm)。 在实际工程项目中,通常无需长短边都计算。经验的方法是:若视场接近于正方形 ......长按二维码访问原文

高精度双目视觉3D点云推动高阶智驾规模化量产落地--机器视觉网 2023-12-25 15:38:04
2023-12-25 15:38:04 来源: 中国机器视觉网
第一性原理指的是:回归事物最基本的条件,将其拆分成各要素进行解构分析,从而找到实现目标最优路径的方法。也就是说,撕开事物一层层复杂的表象,从本质出发而不是从陈旧的或者来自于他人的经验去思考,才能找到最简洁的答案。
智驾安全正在用户心智中占领高位,政策法规为行业未来划定上层纲要
智能驾驶已经经历了一段较长时间的发展,从刚开始的概念与技术萌芽,到如今大算力、大数据平台涌现,感知、预测、决策、规控等领域百花齐放,车已经做的越来越像一个机器人,智能化程度大大提高。
前段时间业内很大的一个热点是“AEB之争”,争议漩涡中心的“AEB”是指自动紧急刹车(Autonomous Emergency Breaking),它并不是一个新鲜的概念,起源最早可
......长按二维码访问原文

关于工业镜头使用中的常见问题-电子发烧友网 2023-12-23 08:34
镜头的基本功能就是实现光束变换(调制),在 机器视觉 系统中, 工业 镜头的主要作用是将目标成像在 图像传感器 的光敏面上。工业镜头是机器视觉系统设计的重要环节。鉴于部分客户在实际应用过程中,会遇到一些常见问题。现以 问答 形式大致罗列如下: 01Q如何判断镜头分辨率是否与相机匹配?
A: 像方分辨率VS物方分辨率×2
像方分辨率=物方分辨率×倍率
02Q这支镜头我想要到xx倍,需要加多少接圈?
A: 接圈=焦距*(1-β)-后侧主点位置-LB
(β为镜头 光学 倍率)
03Q如何判断一支镜头的景深够不够?
A: 景深= (2×有效Fno×可接受弥散斑直径)/β²(β为 镜头光学倍率)有效Fno =(1+β)Fno
在实际项目中,如可接受的过度像素是3个,那么此3个过度像素的长度就作为弥散斑的半
......长按二维码访问原文

金维集电成功上市辅导备案,获国家级高新技术认定-电子发烧友网 2023-12-25 15:04
12月25日,中国证监会公示了长沙金维 集成电路 股份有限 公司 (即“金维集电”)IPO辅导备案报告。就在此前的12月21日,金维集电正式签约西部证券进行股民辅导事宜。这家坐落在被誉为“星城”的湖南长沙的公司,起步于2013年。在专注于创新与成长的道路上,金维集电利用北斗 高精度 芯片 以及 人工智能 & 机器视觉 芯片的研制实力,为客户提供全芯片化解决方案。
扫一扫,分享给好友
相关推荐
极致4K音视频传输行业又添一家“国家级高新技术企业”,你知道吗? `在2016年国家高新技术企业评选活动中,根据国家《高新技术企业认定管理办法》和《高新技术企业 发表于 03-20 11:35
国家高新技术企业认定通过的好处 式投资于未上市的中小高新技术企业2年以上的,可以按照其投资额的70%在股权持有满2年的当年
......长按二维码访问原文

卫星导航-电子发烧友网 2023-12-25
卫星导航(Satellite navigation)是指采用导航卫星对地面、海洋、空中和空间用户进行导航定位的技术。常见的GPS导航,北斗星导航等均为卫星导航。
文章:172个 视频:3个 浏览:26441次 帖子:19个
卫星导航技术
水下仿生光磁导航技术的发展趋势探讨 从水下偏振光场、生物的地磁导航机理以及生物的光磁复合导航机理入手,介绍了水下仿生偏振光导航、仿生地磁导航以及仿生光磁复合导航的基本原理和研究现状;通过分... 2023-12-25 标签:gps定位系统卫星导航 61 0
卫星导航的定位原理及未来趋势 卫星导航或卫星导航系统是使用卫星提供自主地理定位的系统。覆盖全球的卫星导航系统称为全球导航卫星系统(Global Navigation Satellit... 2023-12-04 标签
......长按二维码访问原文

【机器视觉】3D抓取—基于模板匹配 2023-12-25 11:15:10
相关推荐
一文了解3D视觉和2D视觉的区别 一文了解3D视觉和2D视觉的区别 3D视觉和2D视觉是两种不同的视觉模式,其区别主要体现在立体感、深度感和逼真度上。本文将详细阐述这些区别,并解释为什么3D视觉相比2D视觉更具吸引力和影响力。 首先 2023-12-25 11:15:10 45
2D与3D视觉技术的比较 作为一个多年经验的机器视觉工程师,我将详细介绍2D和3D视觉技术的不同特点、应用场景以及它们能够解决的问题。在这个领域内,2D和3D视觉技术是实现自动化和智能制造的关键技术,它们在工业检测、机器人导航、质量控制等众多领域都有着广泛的应用。 2023-12-21 09:19:06 92
图漾科技发布3D工业视觉应用开发平台Vision++ 2023年12月20日,全球领先的3D机器视觉企业图漾科技
......长按二维码访问原文

机器视觉的四大核心功能-电子发烧友网 2023-12-25 11:15
机器视觉 的四大核心功能
机器视觉是一种通过 电子 系统和计算机软件实现人类视觉功能的技术。它运用 计算机视觉 、模式识别、图像处理和 机器学习 等技术,以摄像机和图像处理技术为基础,将图像转化为 数字信号 ,并通过计算机软件进行处理和分析。机器视觉在 工业 、医疗、农业、交通、安防等领域都有广泛的应用。
机器视觉的核心功能可以归纳为四个方面:图像获取、图像处理、图像分析和图像识别。下面将详细介绍这四个方面的功能。
一、图像获取:
图像获取是机器视觉的基础,也是机器视觉系统实现其他功能的先决条件。通过摄像机、相机等设备获取图像并将其转化为数字信号,这为后续的图像处理和分析提供了数据基础。图像获取涉及到 图像传感器 、 光学 系统和图像采集设备等技术,包括图像的分辨率、帧率、灵敏度等。
......长按二维码访问原文

MagikEye推出Pico深度传感器:为机器人时代提供人工智能之眼―新闻频道- 视觉系统设计 2023/12/25 10:58:42
3D传感技术的先驱MagikEye将在美国内华达州拉斯维加斯举行的2024年消费电子展(CES)上展示其开创性的Pico深度传感器(Pico Depth Sensor)。肩负着“为机器人时代提供人工智能之眼”A的使命,Pico深度传感器堪称MagikEye在迈向人工智能与机器人卓越之旅的一大关键里程碑。
Pico深度传感器创新的核心在于它使用了MagikEye专有的Invertible Light™可逆光技术(ILT)。该技术可在Raspberry Pi RP2040中的“裸金属”ARM M0处理器上高效运行。这一非凡功能彰显传感器无需专用芯片即可提供高品质3D传感的能力。此外,尽管Pico Sensor使用RP2040展示其功能,但其底层技术在设计时考虑了适应性,以便在各种微控制器内核上无缝运行,包括基于流
......长按二维码访问原文

海思机器人开发平台首次实现了基于dToF全向3D立体感知拼接避障方案―新闻频道- 视觉系统设计 2023/12/23 11:02:01
近日,openEuler Summit 2023峰会在北京召开,这是一场致力于推动操作系统产业发展的盛大峰会,聚焦推动操作系统技术不断创新,共建全球开源新生态。在本次大会上,海思携手多家合作伙伴,带来基于openEuler的机器人开发平台以及多样化解决方案。
基于openEuler的多传感器融合机器人开发平台
在这次峰会上,海思带来了基于openEuler的多传感器融合机器人开发平台,该方案在业界首次实现了将dToF、视觉在内的多传感器拼接与融合,同时结合海思领先的分布式异构计算、全场景联接、精准执行/表达/交互等技术,成为强大的机器人开发平台。峰会现场除了海思机器人开发平台和原型样机,还展示了合作伙伴基于海思平台开发的相关生态产品,包括微型固态激光雷达、多向固态激光雷达、短距星闪Wi-Fi通信模组、广域通
......长按二维码访问原文

艾迈斯欧司朗推炫彩新作,引领纤薄照明新世代―新闻频道- 视觉系统设计 2023/12/22 23:35:46
全球领先的光学解决方案供应商艾迈斯欧司朗(瑞士证券交易所股票代码:AMS)近日宣布,推出OSTAR® Projection Compact系列半高、超高亮度LED的红光、纯绿光和蓝光版本,机器视觉系统或舞台照明设备制造商因此可创造出功能更强大、外形更纤薄的产品。艾迈斯欧司朗此前已推出采用该封装规格的白光版本,当时称为OSLON Boost。
新型LED拥有高电流密度和极高亮度,非常适用于高功率照明产品。这些LED采用艾迈斯欧司朗新型2mm2芯片,可产生高亮度的光输出。其中,520nm波长的纯绿光版本是同类型产品中最亮的(6A时达到1000lm)。
OSTAR® Projection Compact LED散热性能优异、封装小巧扁平,在高功率灯具设计中可以紧密安装。热阻仅为1.4K/W,而4040封装的尺寸为
......长按二维码访问原文

Xscale像素尺寸缩放功能使Go-X系列如虎添翼 ―技术与应用频道- 视觉系统设计 2023/12/25 10:39:59
现有的Go-X系列GigE Vision和USB3 Vision相机共有24个机型,新机型加入后,总型号增至48款,总有一款能够满足你的需要!
所有Go-X系列相机都具备抗冲击和抗振动的性能(80G / 10G)以及优秀的散热性能,可避免在常规工业环境和不间断工作条件下出现故障。新机型与原有机型均提供六年的保修期。
Go-X系列所有的新机型还配备一项灵活的“Xscale”像素尺寸缩放功能。Xscale是一种替代传统像素合并的方法。传统合并仅限于 “整个”像素,如2x1、2x2、4x4等。而Xscale支持使用浮点数来重新分割出虚拟像素,有助在更换旧相机时匹配像素尺寸、光学格式和分辨率。此外,传统的合并仅限单色相机,而Xscale适用于单色、拜尔和RGB格式。Xscale支持在水平和垂直方向上独立缩放
......长按二维码访问原文

智光眼焊接专用相机助力工业智能化焊接―技术与应用频道- 视觉系统设计 2023/12/23 10:55:14
随着工业自动化的快速发展,焊接技术也在不断进步。在焊接过程中,精准的定位和焊缝跟踪是确保焊接质量的关键。为了满足这一需求,伟景智能倾心研发的智光眼智能焊接专用相机应运而生。其中,智光眼相机作为一款高性能的工业级线激光3D相机,为工业智能焊接领域带来了全新的解决方案。
智光眼相机以其高精度、抗强光、体积小、防飞溅盖和动静态一体等特点,成为工业智能焊接的得力助手。首先,它能够实现工件定位、焊缝提取和焊缝跟踪等功能。借助于智光眼相机配合专用软件,用户可以轻松完成工件扫描、焊缝规划等操作。在焊接过程中,智光眼相机可切换成动态相机,实时检测焊缝位置,从而保证焊枪始终沿着焊缝进行焊接,提高焊接质量。此外,焊接动作完成后,智光眼相机还可以作为检测工具,配合焊接系统,实现焊缝平整度和尺寸偏差的检查。
产品功能
工件定位
......长按二维码访问原文

晶圆缺陷检测,解决“螺旋线”运动轨迹及“等弧长触发”难题―技术与应用频道- 视觉系统设计 2023/12/22 23:50:54
“地心科技高精密直线运动台SMH225LM,搭配RAB系列高精度气浮转台,完美实现晶圆缺陷检测应用中的螺旋线运动,并实现了等弧长触发高速相机采集图像,在晶圆缺陷检测领域发挥重要作用。”
地心科技,追求精度,永无止境。
01. 晶圆缺陷检测
晶圆缺陷光学检测一直是一个长期伴随IC制造发展的工程问题。晶圆缺陷检测要准确识别出晶圆的缺陷,并得到缺陷的具体信息,包括缺陷的位置,面积大小等等;满足大规模工业化生产的速度和产能需求,实现快速检测。
半导体行业中晶圆缺陷检测的常见方法主要有两种:自动光学检测系统(Automatic Optic Inspection , AOI )以及扫描电子显微镜检测系统(Scanning Electron Microscope ,SEM)。AOI自动光学检测系统基于光学原理
......长按二维码访问原文

控制工程网-全球工控自动化和智能制造门户网站 2023/11/14 14:00:00
资讯 > 工业安全
作者:www.cechina.cn2023.12.25阅读 328
这本书的作者是北京联讯动力咨询公司总经理、上海交通大学中国质量发展研究院客座研究员、天津大学兼职教授林雪萍。作者从全球制造业的变化切入,结合国际政治和疫情后的新局势,援引大量供应链企业的案例,分析了供应链发生的深刻变化,并深度解读了当今时代格局下中国在全球供应链竞争中的角色,对未来发展做出推演与展望。
余永定表示,对于处理好效率和安全的对立统一,现在学术界最大的挑战是如何提出更多、更明确、更具体的政策建议。这种建议必须也只能建立在对全球供应链深入、细致的调查研究的基础之上,而《供应链攻防战》一书为填补上述空白做出了非常有益的贡献。
本书基于实地调查研究提出:“中国制造业所发生的迁移与流失,并不直接对应美国‘再工业化’
......长按二维码访问原文

2023年小型计算机视觉总结 2023-12-24 09:55
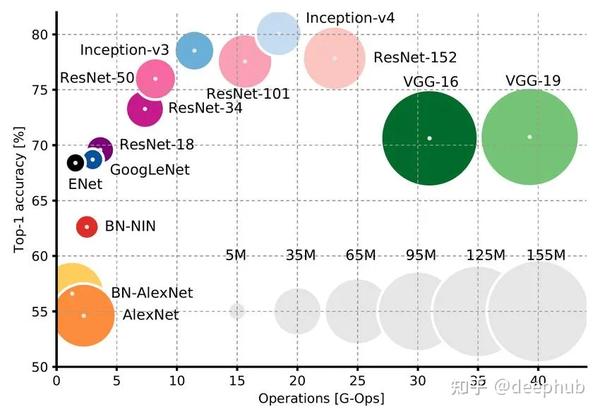
在过去的十年中,出现了许多涉及计算机视觉(CV)的项目,无论是小型的概念验证项目还是更大规模的生产应用。应用计算机视觉的方法是相当标准化的:
1、定义问题(分类、检测、跟踪、分割)、输入数据(图片的大小和类型、视野)和类别(正是我们想要的)
2、注释一些图片
3、选择一个网络架构,训练-验证,得到一些统计数据
4、构建推理系统并进行部署
到2023年底,人工智能领域迎来了生成式人工智能的新成功:大型语言模型(llm)和图像生成模型。每个人都在谈论它,它们对小型计算机视觉应用有什么改变吗?
本文将探索是否可以利用它们来构建数据集,利用新的架构和新的预训练权重,或者从大模型中提取知识。
小型计算机视觉
在这里,我们通常感兴趣的是可以以相对较小的规模构建和部署的应用程序:
开发成本不应该太高
它不
......长按二维码访问原文

MAE论文解读 2023-12-25 12:00

论文地址:Masked Autoencoders Are Scalable Vision Learners
代码地址:https://github.com/facebookresearch/mae
NLP CV 监督 Transformer Vision Transformer 自监督 Bert(MLM)
GPT(ALM) MAE
一、标题
Masked Autoencoders Are Scalable Vison Learners
标题翻译过来就是:带掩码的自编码器是一个可拓展的视觉学习器。Scalable 说明模型可以用于大规模数据集训练,Masked 思想来源于BERT,每次mask输入的一部分,然后去预测被mask的部分。
二、摘要
本文表明MAE(Masked Autoencoder
......长按二维码访问原文

SPGroup3D:室内3D物体检测的超点分组网络(代码已开源) 2023-12-24 16:09
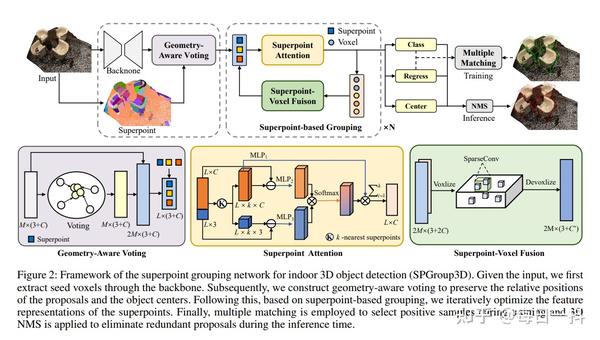
SPGroup3D: Superpoint Grouping Network for Indoor 3D Object Detection
地址:https://arxiv.org/pdf/2312.13641.pdf
github: https://github.com/zyrant/SPGroup3D
标题:SPGroup3D:室内3D物体检测的超点分组网络
摘要:目前,室内场景的三维物体检测方法主要采用投票和分组策略生成提案。然而,大多数方法使用实例不可知的分组方式,如球查询,导致语义信息不一致和提案回归不准确。为此,我们提出了一种新颖的超点分组网络,用于室内无锚单阶段三维物体检测。具体而言,我们首先采用无监督方式将原始点云划分为超点,即具有语义一致性和空间相似性的区域。然后,我们设计了一个几何感
......长按二维码访问原文

关于Diffusion模型在计算机视觉领域中的应用现状调研 2023-12-25 14:15
关于Diffusion模型在计算机视觉领域中的应用现状调研
一、引言
深度生成模型的出现极大推动了计算机视觉领域的发展,为图像、视频和三维场景的生成、编辑和重建提供了能力。早期的深度生成模型包括生成式对抗网络[1](Generative Adversarial Networks,GAN)、变分自编码器[2](Variational AutoEncoder,VAE)、标准流[3](normalizing flow)等,并在图像生成领域表现出了一定的潜力。在过去的几十年里,GAN因其高质量的样本生成能力而占据了深度生成模型的统治地位,并不断发展出了一系列能够进行实际运用的模型,例如SytleGAN[4]、StyleGAN2[5]、ProGAN[6]等等,这些模型在生成多样化且高质量的图像上表现出了极大的优势。但
......长按二维码访问原文

3D点云自监督预训练的自编码器 :Point-M2AE - 知乎 2023-12-25 15:58
这篇论文介绍了一种新型自监督预训练框架,用于学习 3D 点云的分层表示。Point-M2AE 通过掩码自编码器(MAE)来学习 3D 点云数据的不规则表示。关键的改进包括以下几点:
与传统的 MAE 中的标准 Transformer 不同,Point-M2AE 将编码器和解码器修改为金字塔架构,这有助于逐步建模空间几何形状,并捕获 3D 形状的细粒度和高级语义。 论文引入了一种多尺度掩蔽策略,该策略可以生成跨尺度一致的可见区域,保持局部几何形状的完整性和网络的连贯性。在微调过程中,Point-M2AE 使用了局部空间自注意力机制,以便更好地关注相邻的模式。 为了更好地从局部到全局的角度重建3D几何形状,论文提出了利用跳连接以补充解码器中来自编码器相应阶段的细粒度信息
Point-M2AE 显示出强大的3D表
......长按二维码访问原文

ICLR2023 | 3D表示新网络:多视图+点云! 2023-12-25 15:19
多视图投影方法在 3D 分类和分割等 3D 理解任务上表现出了良好的性能。然而,目前尚不清楚如何将这种多视图方法与广泛使用的 3D 点云相结合。
人类视觉系统更接近于使用多个视角的间接方法来理解3D物体,而不是直接处理3D数据。相比之下,间接方法通常通过渲染对象或场景的多个2D视图,并使用基于2D图像的传统架构来处理每个图像。人类视觉系统更接近于这种多视图间接方法,因为它接收到的是渲染图像流,而不是显式的3D数据。
引入了 Voint cloud 这个新的3D数据表示形式,并设计了 VointNet 模型来学习和处理这种表示。 Voint cloud 将每个3D点表示为从多个视角提取的特征集合,以融合点云表示的紧凑性和多视图表示的自然感知能力。
作者通过定义在Voint级别的池化和卷积操作,构建了Voin
......长按二维码访问原文

在自动驾驶企业摆脱高精地图依赖的情况下,SLAM算法在自动驾驶行车过程中还有什么意义? 2023-12-25 16:18
引言
在讨论自动驾驶及其相关技术的过程中,时常会遇到以下这几个观点:“自动驾驶技术偏感知”、“自动驾驶中是LiDAR方法有优势?还是视觉方案更优?”、“自动驾驶企业中感知岗位机会和待遇都不错”、“自动驾驶到底需不需要高精地图?”,等,以上问题的讨论、回复和解答在网络上大都能一一对应地找到,但大多数的讨论和回答本人认为是缺乏一些 “系统大局视角” 和 “相似领域间的横向对比” 分析的,大部分的内容仅仅只是让读者们“知其然”而难以“明其所以然”。
恰巧本人在工作后接触了“移动机器人工业”和“自动驾驶工业”中定位建图技术的应用,故而本人将依据个人经验和理解,尝试从两个角度:
自动驾驶中的高精地图; SLAM算法在移动机器人和自动驾驶中的工业实现侧重点异同
来分析、讨论在 自动驾驶企业摆脱高精地图依赖的情况下,
......长按二维码访问原文

遥遥领先!华为SOTA!无监督自适应3D目标检测!ICCV2023!即将开源! 2023-12-25 18:04
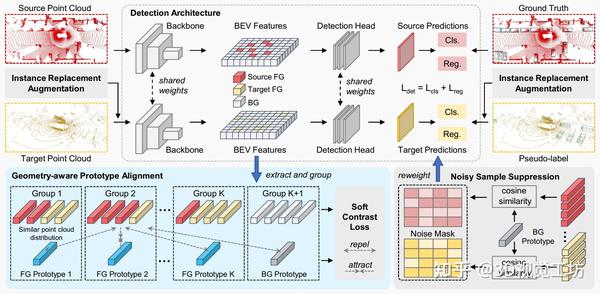
1. 摘要
基于激光雷达的3D检测在最近几年取得了显著的进步。然而,当3D检测器应用于不同的数据集时,其性能会受到域间差异的严重影响。现有的基于激光雷达的域自适应3D检测方法没有充分解决特征空间中的分布差异问题,这限制了检测器跨域的泛化能力。为此,我们提出了一种新的无监督域自适应3D检测框架,即GPA-3D,它利用点云对象固有的几何关系来缩小特征差异,从而促进现有激光雷达3D检测器的跨域迁移。具体来说,GPA-3D为点云对象的不同几何结构设计了一系列可学习的原型。每个原型在对应的点云对象的BEV(俯视图)特征上进行对齐,以减少分布差异并实现更好的自适应。为了达到这个目的,我们设计了软对比损失,它在表示空间中拉近同类特征-原型对,并推远异类对。此外,我们还开发了两个组件来增强该框架的效果,即噪声样本抑制(NSS
......长按二维码访问原文

CV计算机视觉每日开源代码Paper with code速览-2023.12.24 2023-12-25 01:03
精华置顶
墙裂推荐!小白如何1个月系统学习CV核心知识:链接
点击@CV计算机视觉,关注更多CV干货
论文已打包,点击进入—>下载界面
点击加入—>CV计算机视觉交流群
1.【基础网络架构】Forging Tokens for Improved Storage-efficient Training
2.【目标检测】PETDet: Proposal Enhancement for Two-Stage Fine-Grained Object Detection
3.【Open-Vocabulary Object Detection】(AAAI2024)Simple Image-level Classification Improves Open-vocabulary Object Detection
......长按二维码访问原文

CVPR 2022 真实超分:LDL 2023-12-25 10:54

港理工张磊的工作,很好的一个真实超分工作
Motivation
用GAN做真实超分,细节和伪影作为高频信息是交织的,因此一个难点是在保留细节的同时抑制伪影。
这张图上展示了不同位置SR可视化结果。A是超分难度较低的区域,例如平滑区域、大尺度结构等,超分结果也比较好;B、C是存在细粒度细节的区域,由于都是高频区域,超分难度较高,而相比而言,B虽然超分结果不好,但由于纹理比较无规则,没有明显的结构先验,人眼很难察觉像素差异,因此看起来还好;但C是存在明显、清晰、规则的纹理变化和结构先验,局部的patch在退化后的LR中不明显,因此超分结果中的过冲(overshoot,比如振铃伪影)和结构畸变(distorted structures)视觉上就很明显了。
思考:本质上是从频域角度考虑可视化结果。
......长按二维码访问原文

中科大&华为提出TinySAM:突破高效分割一切模型的极限 2023-12-24 17:28
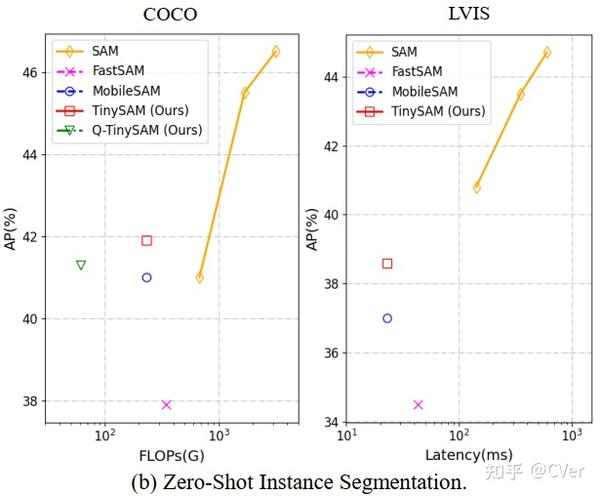
一句话总结
TinySAM:一种微型分割一切模型,旨在突破高效分割一切的极限,引入全阶段知识蒸馏方法和分层分割一切策略,计算量显著减少,同时保持强大的零样本性能,代码刚刚开源!
点击关注 @CVer官方知乎账号,可以第一时间看到最优质、最前沿的CV、AI工作~
TinySAM
TinySAM: Pushing the Envelope for Efficient Segment Anything Model
单位:中科大, 华为诺亚
代码1:https://github.com/xinghaochen/TinySAM
代码2:https://gitee.com/mindspore/models/tree/master/research/cv/TinySAM
论文:https://arxiv.or
......长按二维码访问原文

CVPR2023 | 如何设计一个更快更鲁棒的P3P求解器? 2023-12-25 17:41
P3P 问题是经典的多视图几何问题之一,其中标定的相机的绝对位姿由三个 2D-3D 对应关系决定。由于这是许多视觉系统的关键(例如定位和SfM),因此过去有很多研究关注于如何开发更快、更稳定的P3P算法。虽然当前SOTA的求解器既非常快又稳定,但仍然存在可能崩溃的配置。 本文将问题代数化为寻找两个圆锥的交点。通过这个方式,我们能够分析表征多项式系统的实根,并为每个问题实例采用量身定制的解决方案。这导出了一个快速稳定的P3P求解器,它能够正确解决其它方法可能会失败的情况。实验评估表明,该方法在速度和成功率方面都优于当前的SOTA方法。
论文题目:Revisiting the P3P Problem
作者:Yaqing Ding, Jian Yang, Viktor Larsson, Carl Olsson,
......长按二维码访问原文

卷积神经网络中的平移等变性分析 2023-12-25 12:09
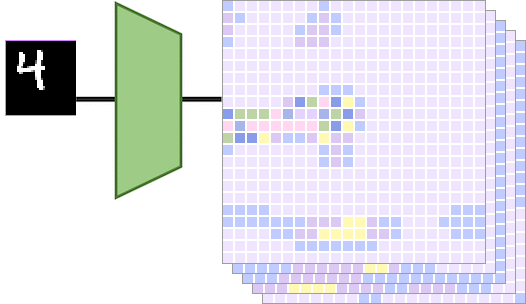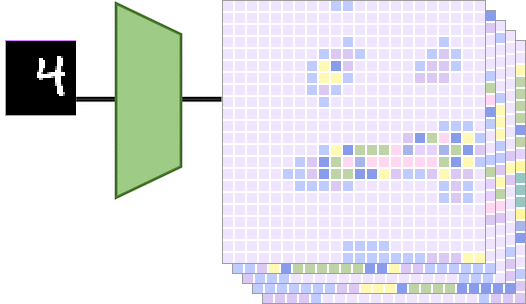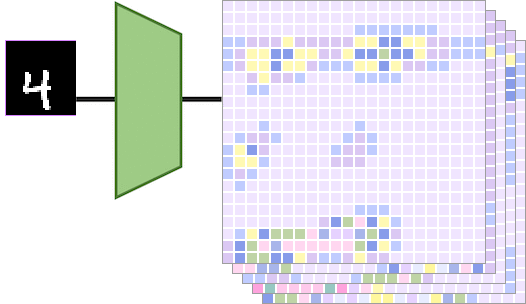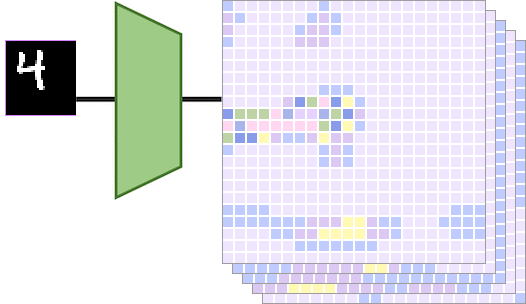
卷积神经网络(CNN)具有平移等变性的观点在某种程度上深入人心,但很少有人去探寻其原因或者理论根据。这篇文章将对这个问题进行系统地讲解,为后续进一步研究CNN的其他等变性和不变性设计夯实基础。
介绍
在机器学习中,我们通常关注模型的灵活性。我们希望知道选择的模型实际上能够完成我们想要的任务。例如,神经网络的通用逼近定理使我们相信神经网络可以近似任何所需精度的广泛类别的函数。但完全的灵活性也有缺点。虽然我们知道我们可以学习目标函数,但也存在许多错误的函数,它们在我们的训练数据上看起来完全一样。如果我们是完全灵活的,我们的模型可能会学习其中任何一个函数,一旦我们移开了训练数据,我们可能无法进行泛化。因此,需要对网络的灵活性加以限制。卷积神经网络是减少灵活性的一个著名成功案例。相较于早期的MLP网络,CNN的卷积
......长按二维码访问原文

【三维重建实战】手把手搭建自己的3D扫描仪 2023-12-24 10:42

视频介绍如下:
一、概述
过去的十年里,3D扫描逐渐火热起来了,廉价的微型相机经常被纳入消费电子产品中。数字投影也将产生类似的影响,各种供应商都提供小尺寸、低成本的投影仪。因此,三维重建是计算机图形学界中重点关注的一个话题。特别是低成本的自制3D扫描仪在预算适中的学生和业余爱好者手中触手可及。本教程主要为大家讲解结构光三维成像技术,提供必要的数学、软件和实践细节,以利用相机、投影仪或线激光构建自己的桌面3D扫描仪。
图1 3D扫描仪机器扫描效果
二、光学三维重建技术
计算机视觉中的光学三维重建技术根据是否需要额外投射光源分成被动成像和主动成像两类。被动成像主要是指双目视觉,其完全依赖于环境光,立体视觉是基于对人类视觉系统的研究,从多幅图像中获取物体的3维几何信息。主动成像利用可控制光源进行三维成像,主
......长按二维码访问原文

实时动态手部重建的3D点喷洒技术 2023-12-24 10:54
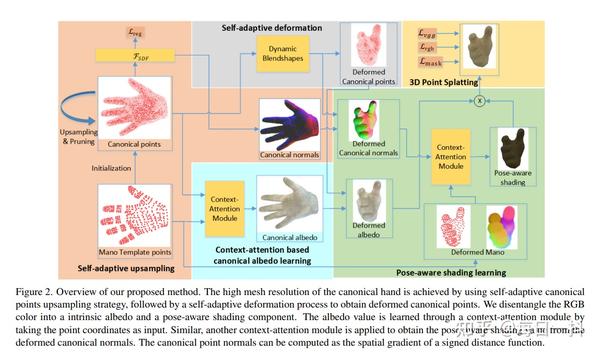
3D Points Splatting for Real-Time Dynamic Hand Reconstruction
地址:https://arxiv.org/pdf/2312.13770.pdf
标题:实时动态手部重建的3D点喷洒技术
摘要:我们提出了一种名为3D Points Splatting Hand Reconstruction(3D-PSHR)的实时、照片逼真的手部重建方法。我们提出了一种自适应的规范点上采样策略,以实现高分辨率的手部几何表示。接着采用自适应变形将手部从规范空间变形到目标姿势,以适应规范点的动态变化。与常见的细分MANO模型的做法相比,这种方法提供了更大的灵活性,结果是改善的几何拟合。为了建模纹理,我们将外观颜色分解为固有的反照率和姿势感知的阴影,通过Context-At
......长按二维码访问原文

神奇!G-SHELL:一种强大且通用的3D表示 2023-12-25 17:25

原文标题:GHOST ON THE SHELL: AN EXPRESSIVE REPRESENTATION OF GENERAL 3D SHAPES
作者:Zhen Liu, Yao Feng, Yuliang Xiu, Weiyang Liu, Liam Paull, Michael J. Black, Bernhard Schölkopf
作者机构:Max Planck Institute for Intelligent Systems - Tübingen;Mila, Université de Montréal; ETH Zürich;University of Cambridge
论文链接:https://arxiv.org/abs/2310.15168
项目主页:https://gs
......长按二维码访问原文

CVPR2023 Highlight|ECON:最新单图穿衣人三维重建SOTA算法 2023-12-25 17:37
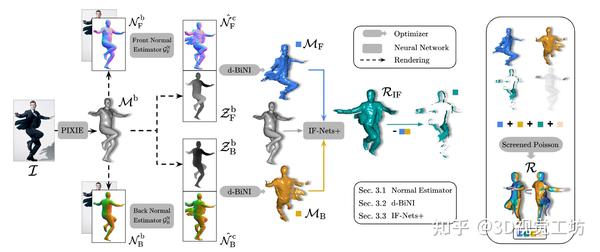
0.笔者个人体会
这篇文章讨论了单图像的穿着人类重建问题。
隐式方法可以用来表示任意3D穿着人类形状,因为它不依赖于拓扑结构,因此具有更高的灵活性。这种方法的缺点是难以扩展到多种服装样式,限制了其在真实场景中的应用。
相比之下,显式方法则使用网格或深度图或点云来重建3D人类。这些方法主要关注于估计或回归最小穿着的3D身体网格,而忽略了衣服。为了考虑穿着人类的形状,另一类工作通过添加3D偏移量到身体网格上来进行建模。这种方法与当前的动画管道兼容,因为它们继承了从统计身体模型中得出的层次化骨架和权重。然而,这种方法对于宽松的衣服来说不够灵活,因为它们与身体拓扑结构有很大的不同,例如衣服和裙子。为了增加拓扑灵活性,一些方法通过识别服装类型并使用适当的模型来重建它。但是,这种方法很难扩展到多种服装样式,限制了其在
......长按二维码访问原文







