文章目录[隐藏]
- 视觉招聘小黑板
- 行业资讯
- 蓝芯科技被认定为余杭区“准独角兽”企业--机器视觉网 2023-12-29 16:55:19
- 深慧视荣获2023深圳市“专精特新”中小企业认定--机器视觉网 2023-12-29 16:34:02
- 视比特揽双重荣誉,荣膺“国家知识产权优势企业”并入选《上海市智能机器人标杆企业与应用场景推荐目录》--机器视觉网 2023-12-29 16:28:56
- VS Technology 推出VS-TLS(FR)系列20种倍率 分离组合式大视野远心镜头--机器视觉网 2023-12-29 16:19:20
- 线扫描成像:发展、应用与未来--机器视觉网 2023-12-29 17:41:28
- 通过去除传感器玻璃(RCG),实现更精确的光束分析--机器视觉网 2023-12-29 17:32:27
- 星猿哲无序混码助力上存下拣,赋能海外头部 3PL 旧仓升级--机器视觉网 2023-12-29 17:11:19
- SICK强势打造新能源锂电池制造解决方案--机器视觉网 2023-12-29 16:13:02
- CamSim相机模拟器:极大加速图像处理开发与验证过程--机器视觉网 2023-12-29 15:56:19
- 研华科技助力印度钢铁集团如何闯出“智”造路--机器视觉网 2023-12-29 15:24:08
- 阿塔米W31管道环焊缝机器人系统,专为油气长距离环焊缝检测而设计--机器视觉网 2023-12-29 15:10:11
- 机器人与机器视觉软件实现完美交互―新闻频道- 视觉系统设计 2023/12/29 10:00:15
- Teledyne e2v发布全新高水准CMOS图像传感器系列:Emerald Gen2―新闻频道- 视觉系统设计 2023/12/28 22:58:47
- 海康机器人打造智能制造典型样本―技术与应用频道- 视觉系统设计 2023/12/29 11:04:39
- 阿丘助力攻克动力电池复杂瑕疵检测难题―技术与应用频道- 视觉系统设计 2023/12/29 10:51:36
- 机器视觉光学基础――放大率 视场角―技术与应用频道- 视觉系统设计 2023/12/28 22:55:00
- SICK强势打造新能源锂电池制造解决方案―技术与应用频道- 视觉系统设计 2023/12/28 22:42:19
- 迁移科技:传统加工制造市场仍然存在很多场景化方案需求―业界采访频道- 视觉系统设计 2023/12/29 16:03:01
- 大帧科技:2024加大研发投入,开拓海外市场―业界采访频道- 视觉系统设计 2023/12/29 15:59:11
- 映美精相机:看好医疗及运动科技市场―业界采访频道- 视觉系统设计 2023/12/29 15:55:13
- 论文解读 DetGPT: Detect What You Need via Reasoning 2023-12-27 03:44
- 用于运动目标检测与跟踪的多传感器融合与分类(下) 2023-12-27 05:28
- 长沙EI国际会议 | 计算机视觉与深度学习国际会议(CVDL 2024) 2023-12-28 17:27
- 大模型被偷家!腾讯港中文新研究修正认知:CNN搞多模态不弱于Transfromer 2023-12-29 12:50
- 刷新多个SOTA!U2Seg:无监督通用图像分割 2023-12-29 18:10
- Middlebury立体测评网站使用指南:让你的立体视觉算法脱颖而出 2023-12-28 15:58
- 相机标定,你还没读过张正友标定法吗? 2023-12-28 17:24
- 一文看懂CMOS图像传感器指标 2023-12-28 12:06
- 刷新多个SOTA!InternVL:大型视觉语言基础模型 2023-12-28 21:51
- 制作目标检测的训练样本图像 2023-12-29 16:15
- 通用性超强!同时实现6D位姿估计和跟踪! 2023-12-28 18:11
- RAL 2023 开源 基于多输入多尺度Surfel的激光惯性连续时间里程计和建图 2023-12-28 18:44
- Talk | 北京大学博士生汪海洋:通向3D感知大模型的前置方案 2023-12-29 12:00
- CV计算机视觉每日开源代码Paper with code速览-2023.12.28 2023-12-28 23:24
- 开源4D生成框架|4DGen: 基于动态 3D 高斯的可控 4D 生成 2023-12-29 12:01
视觉招聘小黑板
欲了解详情,请在公众号后台回复:231229
行业资讯
蓝芯科技被认定为余杭区“准独角兽”企业--机器视觉网 2023-12-29 16:55:19
2023-12-29 16:55:19 来源: 中国机器视觉网
昨日,《2023年度余杭区拟认定独角兽、准独角兽企业》名单已完成公示,蓝芯科技被正式认定为2023年度余杭区准独角兽企业。
《余杭区独角兽、准独角兽企业》认定工作由杭州市余杭区经济和信息化局组织开展,旨在加快辖区内“独角兽”、“准独角兽”企业培育,充分发挥“独角兽”、“准独角兽”企业在引领产业新技术、新业态、新模式升级中的重要作用,推动余杭区经济高质量发展。
《余杭区独角兽、准独角兽企业》评审委员会由区委常委、常务副区长担任评委会主任,工信经济分管区长担任副主任;区委组织部(人才办)、区委宣传部(文创办)、区发改局(金融办)、区经信局、区科技局、区财政局(国资办)、区人力社保局、区住建局、区商务局、区市场监管局、区金控集团、未来科技城、良渚新
......长按二维码访问原文

深慧视荣获2023深圳市“专精特新”中小企业认定--机器视觉网 2023-12-29 16:34:02
2023-12-29 16:34:02 来源: 中国机器视觉网
近日,深圳市中小企业服务局公布了《关于2023年深圳市专精特新中小企业名单公示》,经专家评审和各项综合评定,深慧视凭借技术实力、产品创新、市场等方面的优异表现,成功入选该名单。
深慧视专注于机器视觉和人工智能技术创新研发。在过去的几年中,深慧视不断加大技术研发投入,不断推动"视觉技术+AI+机器人"的规模化应用,与多家知名企业和研究机构展开深入合作,取得一系列重要的研究成果。包括,深慧视自主研发的全系列3D工业相机、成型鞋智能线、医疗3D视觉装备、医疗机器人等产品,引发行业高度关注。
全系列3D工业项目
成型鞋智能线
医疗3D视觉装备
医疗机器人
深慧视凭借深厚的技术积累和行业理解,利用先进的AI技术能力和算法模型,使3D视觉系统与行
......长按二维码访问原文

视比特揽双重荣誉,荣膺“国家知识产权优势企业”并入选《上海市智能机器人标杆企业与应用场景推荐目录》--机器视觉网 2023-12-29 16:28:56
2023-12-29 16:28:56 来源: 中国机器视觉网
2023年,视比特凭借领先的技术、专业的产品和卓越的服务,持续助力工业智能化,本年度已斩获十多项重要荣誉。近日,视比特荣膺“国家知识产权优势企业”荣誉称号,上海公司入选《上海市智能机器人标杆企业与应用场景推荐目录》,公司强劲的综合实力、研发创新能力以及产品规模化应用能力再次受到高度认可。
国家知识产权优势企业
近日,国家知识产权局公布了2023年度国家知识产权优势企业的评定结果,视比特凭借行业领先的研发创新实力、完备的知识产权管理体系以及突出的知识产权管理水平成功入选。
“国家知识产权优势企业”是国家对企业知识产权创造、运用、保护、管理等方面工作突出授予的最高荣誉和评价之一。主要颁发给国家和地方重点发展的产业领域,能承接国家和地方重大、重点
......长按二维码访问原文

VS Technology 推出VS-TLS(FR)系列20种倍率 分离组合式大视野远心镜头--机器视觉网 2023-12-29 16:19:20
2023-12-29 16:19:20 来源: 中国机器视觉网
日前,VS Technology 推出VS-TLS(FR)系列20种倍率 分离组合式大视野远心镜头,采用前后配件分离式组合远心镜头,使用八角接口x-锁定系统设计,更加便利牢固,最大支持芯片 φ38mm,最大视场角为 φ80.7。
特征
独特设计,前后配件分离式组合远心镜头
采用了 Fit-X 技术,将镜头分离成前后两部分配件(front & rear),在保持前置配件不变,更换后置配件时可以拓宽视野大小;保持后置配件不变,更换前置配件时可以在工作距离(WD)以及视野大小(FOV)保持不变的情况下,增加光学倍率以及清晰度;可通过组合不同的前后配件来实现 0.136x 至 1x 的20种倍率的不同视野大小的高分辨率成像,在原有系列的基础上,
......长按二维码访问原文

线扫描成像:发展、应用与未来--机器视觉网 2023-12-29 17:41:28
2023-12-29 17:41:28 来源: 中国机器视觉网
在本次采访中,AZoSensors与Teledyne公司的Xing Fei He就线扫描成像及其优势、发展和未来进行了交流。
什么是线扫描成像,如何创建线扫描图像?
线扫描相机采用一维线性阵列,快速将图像数据从传感器传输到相机,然后再传输到主机,传输速度可达数百千赫兹。第二个维度来自于被成像物体或摄像机的运动。
线扫描成像设备在现实中的运用?最常见的运用是传真机。
设备工作原理
二维图像是在物体或相机(垂直)移动经过图像传感器中的像素线时,通过连续的单线扫描逐行获取。 在某确定视野内,一台2k线扫描相机可以提供与400万像素区域扫描相机(面扫描相机)完全相同的分辨率,且不会出现图像斑点或帧重叠的冗余处理。
线扫描成像经过十年发展后
......长按二维码访问原文

通过去除传感器玻璃(RCG),实现更精确的光束分析--机器视觉网 2023-12-29 17:32:27
光束质量分析技术用于分析和鉴定光束特性,与简单的功率或能量测量方法互为补充。这一技术涉及各种参数的测量,例如空间能量或强度分布、光束宽度、质心、椭圆率和方向。
光束质量分析的主要目标是全面了解光束特性——这有助于评估光束性能,并针对特定应用进行优化。
合适的波长范围:支持准确拍摄和测量所需波长的光束;高空间分辨率:更好地分析光束特征,如光束宽度、形状和强度分布;合适的传感器尺寸:以适应待分析激光的光束直径。应确保能够捕获整个光束,无需拼接或截断;高动态范围:可处理高低强度光束,不会出现饱和或感光度损失的现象;低噪声水平:是防止像素值随机波动、避免出现颗粒状或斑点图案的关键;高线性度:是确保拍摄图像准确代表光束真实强度值的重要特性。分析不同强度的光束时,这一点尤其重要;可轻松进行系统连接:通过标准化数据接口进
......长按二维码访问原文

星猿哲无序混码助力上存下拣,赋能海外头部 3PL 旧仓升级--机器视觉网 2023-12-29 17:11:19
近期,创新物流系统集成商 Chinoh.Ai 携手星猿哲,在日本琦玉县莲田市落地了上存下拣四向穿梭立库及混码托盘订单拣选解决方案,成功对头部 3PL 公司 Trancom 的旧有仓库进行了自动化升级改造,向行业展现了劳动力短缺背景下,智能仓储前沿应用的新范式。
星猿哲的混码解决方案已在电子、食品等领域积累了成熟的落地实践,此次旧仓的成功升级,再次验证了混码机器人技术在仓储自动化领域的灵活应用与巨大潜力,为其在仓储全流程的落地应用,又添一例标杆。
上存下拣+订单拣选解决方案
为 Trancom 提供的上存下拣 + 订单拣选解决方案,由 RGV 加提升机的四向穿梭立库,搭配 AGV,及混码机器人组成,一套方案解决存储与拣选两大场景需求,真正实现了入库、存储、出库的全流程自动化:
......长按二维码访问原文

SICK强势打造新能源锂电池制造解决方案--机器视觉网 2023-12-29 16:13:02
2023-12-29 16:13:02 来源: 中国机器视觉网
在全球对可再生能源和电动汽车日益关注的趋势下,锂电池制造行业发展迅猛。作为电动汽车的核心组件,锂电池的需求不断增长,同时也带来了更多的创新、发展和挑战。
同时伴随锂电池在电动汽车、电子设备等领域的广泛应用,锂电池制造行业迅速崛起,并已成为全球制造业的重要组成部分。在这个充满竞争的市场中,如何提高生产效率、确保产品质量以及降低成本成为了关键。SICK作为智能传感技术的供应商,已在锂电池制造行业深耕多年,并为行业客户提供了许多出色的传感技术综合解决方案,助力锂电行业发展。
检测与测量
电池的自动化生产需要柔性生产线、最少停机时间和强大的诊断功能。SICK 现代智能传感器可用于检测物体和测量物理量,并具备参数存储、自动示教和诊断功能。
提高安全
......长按二维码访问原文

CamSim相机模拟器:极大加速图像处理开发与验证过程--机器视觉网 2023-12-29 15:56:19
2023-12-29 15:56:19 来源: 中国机器视觉网
随着图像处理技术的不断发展,相机模拟器在图像处理开发和验证中扮演着越来越重要的角色。相机模拟器能够模拟真实相机的成像过程,提供高质量的图像输入,使开发人员能够更好地评估和调整图像处理算法。本文将探讨如何通过相机模拟器来加速图像处理的开发和验证过程。
在现实生活中,图像处理算法的开发人员在测试和验证他们的系统时经常面临各种障碍,包括但不限于:测试数据不可复制;测试阶段时间消耗长;不必要的时间/成本的增加。
因此,友思特带来Gidel的CamSim模拟器,该模拟器能够生成图像数据,不仅可以回放之前实验记录的真实图像数据,同时也可以为开发人员创建虚拟图像。
CamSim相机模拟器的测试模式可以以高速、慢动作甚至逐帧运行来达到最优可视化。用户可以在
......长按二维码访问原文

研华科技助力印度钢铁集团如何闯出“智”造路--机器视觉网 2023-12-29 15:24:08
2023-12-29 15:24:08 来源: 中国机器视觉网
钢铁行业作为大型复杂流程工业,生产管理的复杂性意味着必须要走数字化转型之路;同时,钢铁行业生产环境苛刻,关键参数的稳定性至关重要,这就对数字化系统与工业计算终端提出更高要求。
一家印度大型国营钢铁集团,是印度最大的钢铁制造公司之一,在印度东部和中部地区拥有五个综合工厂和三个特殊钢厂,靠近原材料来源,生产和销售板材、管道、卷材等各种钢铁产品。
2022年,该钢铁制造公司新启用的热轧卷板生产车间,实施了全新的MES系统,但是由于钢铁厂极端的操作环境,配合MES系统的工业计算终端一直没有找到合适的产品。
DLT-V8315,15吋强固型车载终端
Intel® Core™ i5-4300U/Celeron® 2980U双核处理器;宽温操作 (-3
......长按二维码访问原文

阿塔米W31管道环焊缝机器人系统,专为油气长距离环焊缝检测而设计--机器视觉网 2023-12-29 15:10:11
2023-12-29 15:10:11 来源: 中国机器视觉网
本系列文章我们将从超声检测、光学检测、电磁检测、射线检测这四个方面来介绍阿塔米公司的主要产品。本文是光学检测中的W31管道环焊缝机器人系统的详细介绍。
W31管道环焊缝机器人系统是专门为油气长距离环焊缝检测而设计的,它采用无线代替重型脐带电缆来传输数据和控制运动,这是一个革命性的变化。在油气管道施工现场,特别是在一些极端现场条件下,不需要重电缆,操作起来更加容易和方便。
W31管道环焊缝机器人系统的运动和驱动控制单元和电源都集成在底盘上,锂电池为轨道上的电机提供动力。采集后的数据存储在运动和驱动控制单元中。将存储在运动和驱动控制单元中的数据通过无线传输到终端设备也可以通过软件无线控制动。无需重型脐带。
电机&驱动单元
W31管道环焊缝机器
......长按二维码访问原文

机器人与机器视觉软件实现完美交互―新闻频道- 视觉系统设计 2023/12/29 10:00:15
西班牙专业机器人公司 Tekniker 开发出一套解决方案,可自动抓取杂乱放置的零件并整齐摆放。其中集成的机器视觉软件 MVTec HALCON 利用 3D 视觉技术可确保精确抓取,由此实现整个流程的自动化,加快速度,提高生产效率,进而节约成本。
由机器人进行全自动零件抓取是一项重大的技术挑战。尤为困难的是,部件传给机器人时并不总是井然有序,而是杂乱无章,甚至相互重叠。这意味着仍需频繁人工干预。
西班牙公司 Tekniker 开发出一款基于机器视觉的应用,使用两台机器人即可实现全自动分拣。该应用的一大亮点是 3D 视觉技术“基于表面的匹配”,它能可靠地识别传来的部件,实现精确抓取。
Tekniker 公司总部位于西班牙北部的埃瓦尔,专门从事自动化、工业机器人和传感器等技术解决方案的开发。
西班牙汽车供应
......长按二维码访问原文

Teledyne e2v发布全新高水准CMOS图像传感器系列:Emerald Gen2―新闻频道- 视觉系统设计 2023/12/28 22:58:47
Teledyne e2v的全新Emerald™ Gen2 CMOS图像传感器系列,以其卓越的性能和出色的图像质量,为机器视觉应用、室外监控以及交通检测与监控相机市场带来了全新的选择。基于Teledyne e2v的先进成像技术,Emerald™ Gen2 在提升性能的同时,保证了出色的图像质量,满足了市场对于高精度、高稳定性图像传感器的需求。
Emerald™ Gen2采用了最新的图像处理技术,能够提供清晰、稳定、抗干扰的图像,使得机器视觉系统能够更准确地识别和分析目标。同时,其优异的低光性能,使得在光线较弱的环境下也能获得清晰的图像,进一步扩大了其应用范围。在设计方面,其紧凑的尺寸和低功耗设计,使得交通检测与监控相机能够更加灵活地安装和使用,大大提高了系统的便捷性和实用性,为机器视觉、
......长按二维码访问原文

海康机器人打造智能制造典型样本―技术与应用频道- 视觉系统设计 2023/12/29 11:04:39
海康机器人与长安汽车、英特尔携手,实现IT及OT的融合创新应用,并作为先进制造业产业链上的典型样本,登陆人民网《创新中国》智能制造专题。
《创新中国》节目组深入工厂一线,探访创新要素最集中、最活跃的地方,发掘我国经济高质量发展中诞生的新技术、新业态、新模式,揭秘智造背后的智囊团。
作为机器视觉、移动机器人产品及解决方案提供商,海康机器人主要发力于柔性自动化生产线和智慧内物流系统,不断“让机器更智能”,同时深度调研不同行业需求,与产业上下游、生态伙伴一起,让智能技术赋能各行各业,惠及生产生活的方方面面。
海康机器人&长安汽车
解决行业难题,实现价值落地
场景化AI技术联合开发
2022年,长安汽车与海康机器人联合筹建的工业AI联合创新中心正式揭牌成立。一起研究攻关智能化技术在汽车智能制
......长按二维码访问原文

阿丘助力攻克动力电池复杂瑕疵检测难题―技术与应用频道- 视觉系统设计 2023/12/29 10:51:36
由于动力电池工艺流程复杂、安全性以及质量一致性要求高,产能和质量控制成为这一行业的重要关注点。基于AI的解决方案,正是帮助动力电池行业提升品质和良率的重要突破点。
基于在动力电池行业多年来的工艺沉淀,阿丘科技针对该行业常见复杂检测场景推出标准化AI解决方案,有效帮助电池厂商实现品质管控和良率提升。
方壳电芯AI外观检测
结合方壳电芯缺陷特征,采用独特的FlexOPT成像方案和柔性机构模组,配合专有优化的AI算法模组,即可实现蓝膜破损、膜下异物、气泡、褶皱、划痕等缺陷360 度无死角检出。
方案亮点
准确区分膜下异物和气泡
棱边与R角无死角检测
2.5D重建替换3D相机
电池极片瑕疵AI检测
采用多分时频闪光学方案,配合工艺沉淀的AI检测算法模组、多线程计算和图像分割双并行处理方式,达到高速处理
......长按二维码访问原文

机器视觉光学基础――放大率 视场角―技术与应用频道- 视觉系统设计 2023/12/28 22:55:00
放大率
机器视觉行业里提到的镜头光学放大倍率通常是指垂轴放大倍率,即像和物的大小之比,计算方法如下:
可见,光学放大倍率和所选相机芯片及所需视场相关。
如:已知相机芯片为2/3英寸(8.8mm*6.6mm),
视场长宽为:10mm* 8mm。
如用长边计算,放大倍率=8.8mm/10mm=0.88x;
如用短边计算,放大倍率=6.6mm/8mm=0.825x;
此时应取小的倍率0.825x 作为待选镜头的光学放大倍率。否则,短边视场将不能满足要求。
(若取0.88倍,则短边视场=6.6mm/0.88x=7.5mm<8mm)。 在实际工程项目中,通常无需长短边都计算。经验的方法是:若视场接近于正方形或圆形,则取短边计算;若视场为长条形,则取长边计算。 另外,您还可能听到过电子放大倍率和显示器放 ......长按二维码访问原文

SICK强势打造新能源锂电池制造解决方案―技术与应用频道- 视觉系统设计 2023/12/28 22:42:19
在全球对可再生能源和电动汽车日益关注的趋势下,锂电池制造行业发展迅猛。作为电动汽车的核心组件,锂电池的需求不断增长,同时也带来了更多的创新、发展和挑战。
同时伴随锂电池在电动汽车、电子设备等领域的广泛应用,锂电池制造行业迅速崛起,并已成为全球制造业的重要组成部分。在这个充满竞争的市场中,如何提高生产效率、确保产品质量以及降低成本成为了关键。
SICK作为智能传感技术的供应商,已在锂电池制造行业深耕多年,并为行业客户提供了许多出色的传感技术综合解决方案,助力锂电行业发展。
检测与测量
电池的自动化生产需要柔性生产线、最少停机时间和强大的诊断功能。SICK 现代智能传感器可用于检测物体和测量物理量,并具备参数存储、自动示教和诊断功能。
提高安全性
自动化生产设备与半自动化装配单元的互联需要智能且
......长按二维码访问原文

迁移科技:传统加工制造市场仍然存在很多场景化方案需求―业界采访频道- 视觉系统设计 2023/12/29 16:03:01
尽管从长远的发展角度看,更高程度的自动化、智能化、解放人力是大势所趋,这将为机器视觉应用带来潜在的可观市场;但在刚刚过去的2023年,经济下行等诸多因素如多米诺骨牌般波及众多行业,很多机器视觉企业也难逃影响,遭遇困境。另一方面,近年来机器视觉行业自身的发展热度吸引了众多新企业入局,加之大量资本的涌入,使得这个行业竞争加剧。
面对经济下行、行业竞争激烈,投身机器视觉领域的企业该如何度过困难期?未来的增长点在哪里?如何更好地规划未来发展,以及对整个行业的良性可持续发展有哪些真知灼见?为此,《视觉系统设计》杂志有幸采访了北京迁移科技有限公司创始人兼CEO 樊钰,在此将采访内容与读者分享。
北京迁移科技有限公司创始人兼CEO 樊钰
VSDC:2023年经济下行波及众多行业,机器视觉企业普遍反应发展
......长按二维码访问原文

大帧科技:2024加大研发投入,开拓海外市场―业界采访频道- 视觉系统设计 2023/12/29 15:59:11
尽管从长远的发展角度看,更高程度的自动化、智能化、解放人力是大势所趋,这将为机器视觉应用带来潜在的可观市场;但在刚刚过去的2023年,经济下行等诸多因素如多米诺骨牌般波及众多行业,很多机器视觉企业也难逃影响,遭遇困境。另一方面,近年来机器视觉行业自身的发展热度吸引了众多新企业入局,加之大量资本的涌入,使得这个行业竞争加剧。
面对经济下行、行业竞争激烈,投身机器视觉领域的企业该如何度过困难期?未来的增长点在哪里?如何更好地规划未来发展,以及对整个行业的良性可持续发展有哪些真知灼见?为此,《视觉系统设计》杂志有幸采访了大帧科技董事长王棠猛,在此将采访内容与读者分享。
大帧科技董事长王棠猛
VSDC:2023 年经济下行波及众多行业,机器视觉企业普遍反应发展不景气。贵司 2023 年的业绩情况如何?您认为,在行
......长按二维码访问原文

映美精相机:看好医疗及运动科技市场―业界采访频道- 视觉系统设计 2023/12/29 15:55:13
尽管从长远的发展角度看,更高程度的自动化、智能化、解放人力是大势所趋,这将为机器视觉应用带来潜在的可观市场;但在刚刚过去的2023年,经济下行等诸多因素如多米诺骨牌般波及众多行业,很多机器视觉企业也难逃影响,遭遇困境。另一方面,近年来机器视觉行业自身的发展热度吸引了众多新企业入局,加之大量资本的涌入,使得这个行业竞争加剧。
面对经济下行、行业竞争激烈,投身机器视觉领域的企业该如何度过困难期?未来的增长点在哪里?如何更好地规划未来发展,以及对整个行业的良性可持续发展有哪些真知灼见?为此,《视觉系统设计》杂志有幸采访了The Imaging Source 映美精相机产品经理Allen Yang,在此将采访内容与读者分享。
VSDC:2023 年经济下行波及众多行业,机器视觉企业普遍反应发展不景气。贵司 2023
......长按二维码访问原文

论文解读 DetGPT: Detect What You Need via Reasoning 2023-12-27 03:44
贴一下论文地址:
一、整体概述
本文介绍了一种新的对象检测范式DetGPT,称之为基于推理的对象检测。
不像传统的对象检测方法,依赖于特定的对象名称,该方法使用户能够使用自然语言指令与系统交互,允许更高水平的交互性。
DetGPT能够基于用户表达的期望自动定位感兴趣的对象,即使该对象没有被明确提及。
总的来说,DetGPT展示了人类和机器更复杂和直观交互的潜力,有利于更通用更交互的目标检测系统的研究。
二、方法
2.1 模型结构
作为基于推理的目标检测的初步尝试,作者提出了一种两阶段的方法。
首先,利用多模态模型来解释图像并列出与用户指令匹配的相关对象名称/短语;
然后,利用开放词汇对象检测器来定位给定多模态模型结果的相关对象。
具体来说,对于多模态模型,使用预训练的视觉编码器来提取图像特
......长按二维码访问原文

用于运动目标检测与跟踪的多传感器融合与分类(下) 2023-12-27 05:28

用于运动目标检测与跟踪的多传感器融合与分类(下)
摄像头图像
为了从相机图像中提取关于物体视觉外观的信息,我们必须能够使用视觉特征来表示这些物体。
视觉表示:定向梯度直方图(HOG)描述符在车辆和行人检测中显示出了很好的结果。我们决定将这个描述符作为我们的车辆和行人视觉表示的核心。对象表示的目标是生成要在未来阶段使用的图像区域的视觉描述符,以确定这些区域是否包含感兴趣的对象。
我们提出了HOG描述符(SHOG)的稀疏版本,该描述符专注于图像块的特定区域。这允许我们减少常见的高维HOG描述符。图6说明了我们选择的一些块,以生成不同对象类的描述符:行人、自行车、汽车和卡车。这些块对应于物体的有意义的区域(例如,行人的头部、肩部和腿部)。为了加速S-HOG特征计算,我们采用了积分图像方案。
图6. 每个对象
......长按二维码访问原文

长沙EI国际会议 | 计算机视觉与深度学习国际会议(CVDL 2024) 2023-12-28 17:27
计算机视觉与深度学习国际会议(CVDL 2024)将于2024年1月19日-21日召开。
一、基本信息
大会官网:http://www.iccvdl.org
会议地点:中国 长沙
会议时间:2024年1月19日-21日
主办单位:湖南大学
出版信息:提交EI、Scopus检索
二、主讲嘉宾
1. 陈阳教授,东南大学 国家杰出青年科学基金获得者
2. Prof. Wei Xiang, La Trobe University, Australia 拉筹伯大学思科-拉筹伯人工智能和物联网中心主任
3. 刘晋教授,上海海事大学 航运信息技术研究所副所长
4. 任文琦副教授,中山大学 国家自然科学基金优秀青年基金获得者
5. 唐晓颖副教授,南方科技大学
三、征稿主题
集中但不限
......长按二维码访问原文

大模型被偷家!腾讯港中文新研究修正认知:CNN搞多模态不弱于Transfromer 2023-12-29 12:50

前言 在Transformer占据多模态工具半壁江山的时代,大核CNN又“杀了回来”,成为了一匹新的黑马。腾讯AI实验室与港中文联合团队提出了一种新的CNN架构,图像识别精度和速度都超过了Transformer架构模型。切换到点云、音频、视频等其他模态,也无需改变模型结构,简单预处理即可接近甚至超越SOTA。
本文转载自量子位
仅用于学术分享,若侵权请联系删除
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
CV各大方向专栏与各个部署框架最全教程整理
【CV技术指南】CV全栈指导班、基础入门班、论文指导班 全面上线!!
论文题目:
UniRepLKNet: A Universal Perception Large-Kernel ConvNet f
......长按二维码访问原文

刷新多个SOTA!U2Seg:无监督通用图像分割 2023-12-29 18:10
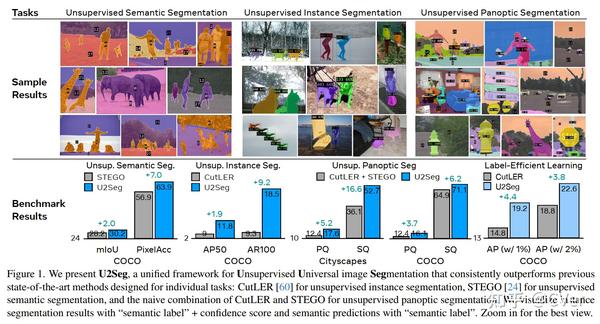
U2Seg:一种无监督通用图像分割模型,即使用一个统一框架执行各种图像分割任务,在无监督实例/语义/全景分割上性能表现SOTA!优于CutLER等网络,代码刚刚开源!
点击关注 @CVer官方知乎账号,可以第一时间看到最优质、最前沿的CV、AI工作~
Unsupervised Universal Image Segmentation
单位:UC伯克利(Trevor Darrell巨佬团队)
代码:https://github.com/u2seg/U2Seg
论文:https://arxiv.org/abs/2312.17243
已经提出了几种无监督的图像分割方法,这些方法消除了对密集的手动注释分割mask的需要;当前的模型分别处理语义分割(例如STEGO)或类不可知的实例分割(例如CutLER),但
......长按二维码访问原文

Middlebury立体测评网站使用指南:让你的立体视觉算法脱颖而出 2023-12-28 15:58

Middlebury立体测评网站是计算机视觉领域的重要资源,它为研究人员和工程师提供了一个评估和比较立体视觉算法的标准化平台。无论你是学术界的研究者还是工业界的从业者,通过使用Middlebury立体测评网站,你可以在算法开发中更好地了解和改进立体匹配算法。本文将为你提供关于Middlebury立体测评网站的详细使用指南,帮助你充分利用该平台。
一、middlebury数据集是什么?
Middlebury数据集是用于立体视觉算法评估的一系列标准化数据集,由Middlebury大学维护。立体视觉是计算机视觉领域中的一个重要研究方向,其目标是从不同角度获取的图像中,恢复出场景中物体的三维信息,即深度或视差图。
Middlebury数据集的设计旨在提供一组公共标准,让研究者和开发者能够在相同的基准下比较和评估他
......长按二维码访问原文

相机标定,你还没读过张正友标定法吗? 2023-12-28 17:24
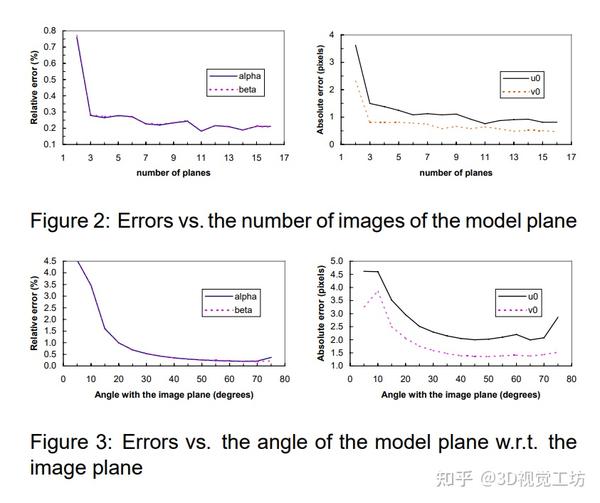
张正友标定方法是一种经典的相机标定方法,目前是最受欢迎的方法之一。该方法通过一种机器学习的方法,利用大量匹配的数据点像素坐标、世界坐标,基于极大似然估计拟合得到一个最优解。 作者提出了一种基于平面模式观察的灵活相机标定技术,包括一个闭合解和基于最大似然准则的非线性优化程序。通过该技术能够建立径向镜头畸变模型,同时实现相机校准。该技术的优势在于灵活易用、不需要昂贵的设备,适用于实际应用。其实现对于将三维计算机视觉技术从实验室推广到实际场景应用具有促进作用。
1 前言
本文的研究背景是建立在摄像机校准技术的基础上,提出了一种新的技术,在不需要高昂成本设备(如正交平面)的前提下,让普通计算机使用者也能容易、灵活地校准相机,以获取2D图像对应的3D度量信息。该技术采用了平面模式观察的方法,获得了非常好的实验结果。相
......长按二维码访问原文

一文看懂CMOS图像传感器指标 2023-12-28 12:06
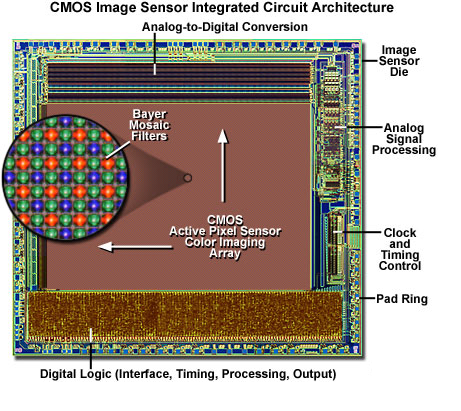
CMOS图像传感器本质是一块芯片,主要包括:感光区阵列(像素阵列)、时序控制、模拟信号处理以及模数转换等模块。
本文简单总结了CMOS图像传感器的主要指标。
Resolution (Number of Pixels)分辨率/像素数量
MP:megapixel,兆像素(百万像素)常见的有0.3M、1M、2M、5M、13M、20M、40M、100M(1亿像素)等。像素数量和分辨率是两个密不可分的重要概念,它们的组合方式决定了图像的数据量,同样大小的图像,分辨率越高,包含的像素越多。像素总数是指所有像素的总和,像素总数是衡量CMOS图像传感器的主要技术指标之一。CMOS图像传感器的总体像素中被用来进行有效的光电转换并输出图像信号的像素为有效像素。有效像素总数隶属于像素总数集合。有效像素数目直接决定了CMOS图像
......长按二维码访问原文

刷新多个SOTA!InternVL:大型视觉语言基础模型 2023-12-28 21:51
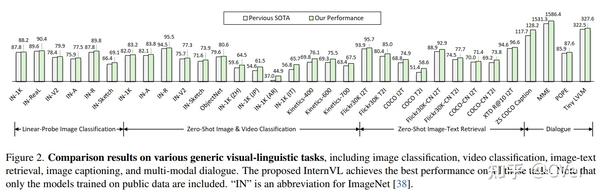
60亿参数!InternVL:大型视觉语言基础模型,使用来自各种来源网络规模的图像文本数据,将视觉基础模型扩展到60亿个参数,并逐步将其与大语言模型对齐,可应用于视觉感知任务,如图像级或像素级识别,视觉语言任务,并实现最先进的性能!代码刚刚开源!
点击关注 @CVer官方知乎账号,可以第一时间看到最优质、最前沿的CV、AI工作~
InternVL
InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks
单位:南大, 上海AI Lab, 港大, 港中大, 清华, 中科大, 商汤
代码:https://github.com/OpenGVLab/InternVL
论文:ht
......长按二维码访问原文

制作目标检测的训练样本图像 2023-12-29 16:15
1. 图像像元值归一化
将图像的像元值的取值范围归一化为0到255。
普通数码相机拍摄出来的图像各个通道的取值范围是0-255。但这个0-255的取值范围是从更大取值范围中处理得到的。在局部强烈光照下或者均匀光照下,还是弱光环境或者强光环境,人眼能够感受到相同的颜色,但是数码相机的传感器会量化出不同的像元值。
RGB的取值对应了固定的颜色,不同环境下传感器会量化出的像元值需要映射为一致的颜色。这个技术就叫做宽动态。为了宽动态处理结果更细腻,传感器的量化范围通常更大。如下图,左侧是关闭了宽动态的效果,在这个图上要想把手机检测出来几乎是不可能的。
数码相机做过了宽动态处理,对普通数码照片进行归一化,可以简单的将0-255线性映射到0-1。而医学图像、遥感图像则不能简单的利用最小-最大像元值归一化到0-1。由
......长按二维码访问原文

通用性超强!同时实现6D位姿估计和跟踪! 2023-12-28 18:11
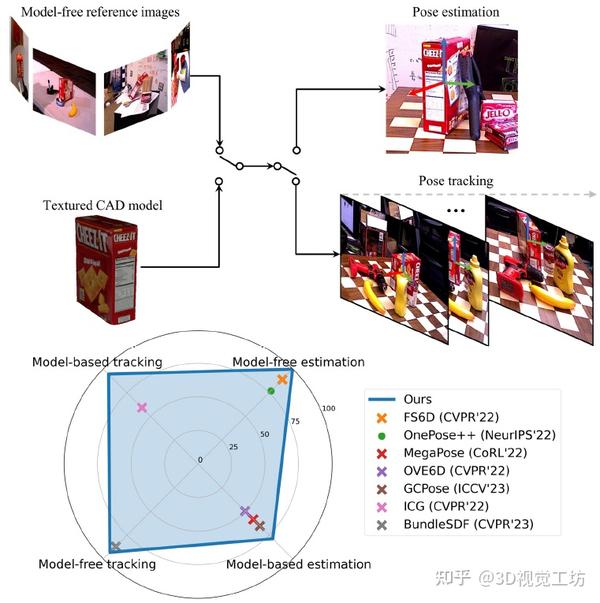
0. 笔者个人体会
今天笔者将为大家分享NVIDIA的最新开源方案FoundationPose,是一个用于 6D 姿态估计和跟踪的统一基础模型。只要给出CAD模型或少量参考图像,FoundationPose就可以在测试时立即应用于新物体,无需任何微调,关键是各项指标明显优于专为每个任务设计的SOTA方案。
下面一起来阅读一下这项工作
1. 效果展示
FoundationPose实现了新物体的6D姿态估计和跟踪,支持基于模型和无模型设置。在这四个任务中的每一个上,FoundationPose都优于专用任务的SOTA方案。(·表示仅RGB,×表示RGBD)。
2. 具体原理是什么?
为减少大规模训练的人工工作,FoundationPose利用3D模型数据库、大型语言模型和扩散模型等新技术,开发了一种新的
......长按二维码访问原文

RAL 2023 开源 基于多输入多尺度Surfel的激光惯性连续时间里程计和建图 2023-12-28 18:44
1. 摘要
虽然与全局地图的特征关联有很大的好处,但为了防止计算呈指数级增长,大多数基于激光雷达的里程计和建图方法都选择将特征与一个体素尺度的局部地图关联。不同体素尺度的曲面可以组织成树状结构,因此我们提出了一种基于八叉树的多尺度曲面全局地图,该地图可以增量更新。这减小了重复计算整个地图的k-d树的耗时。该系统还可以从单个或多个传感器获取输入,从而增强退化情况下的鲁棒性。我们还提出了一种点到表面(PTS)关联方案,对PTS和IMU预积分因子进行连续时间优化,以及闭环和束调整(BA),提供了一个完整的激光雷达惯性连续时间建图定位框架。在公共和内部数据集上的实验表明,与其他最先进的方法相比,我们的系统具有优势。
2. 主要贡献
一个完整的激光雷达惯性里程计和测绘框架,具有前端里程计、闭环和全局姿态图优化,能够
......长按二维码访问原文

Talk | 北京大学博士生汪海洋:通向3D感知大模型的前置方案 2023-12-29 12:00
公众号:将门创投(thejiangmen)
本期为TechBeat人工智能社区第559期线上Talk。
这次我“门”有幸邀请到,北京大学博士生—汪海洋来到TechBeat人工智能社区,为我们分享主题为“通向3D感知大模型的前置方案”,Talk已在TechBeat人工智能社区上线!【点击这里】,即可马上免费观看!
本次Talk中,他介绍了他的团队在3D视觉大模型的前置方案上所做的研究。
Talk·介绍
大模型的兴起正在革新自然语言领域,也改变了人工智能其它领域科研范式。本次讲座主要提供一种3D视觉大模型的前置方案。首先设计针对点云的高效处理Transformer网络, 并进一步拓展到多模态3D领域。这是第一次针对3D感知的多模态网络,开创统一且一致的多模态3D编码新方案,为3D感知大模型打下坚实基础。
......长按二维码访问原文

CV计算机视觉每日开源代码Paper with code速览-2023.12.28 2023-12-28 23:24
精华置顶
墙裂推荐!小白如何1个月系统学习CV核心知识:链接
点击@CV计算机视觉,关注更多CV干货
论文已打包,点击进入—>下载界面
点击加入—>CV计算机视觉交流群
1.【目标检测】Context Enhanced Transformer for Single Image Object Detection
2.【目标跟踪】Cross-Modal Object Tracking via Modality-Aware Fusion Network and A Large-Scale Dataset
3.【点云3D目标检测】FM-OV3D: Foundation Model-based Cross-modal Knowledge Blending for Open-Vocabulary 3D Det
......长按二维码访问原文

开源4D生成框架|4DGen: 基于动态 3D 高斯的可控 4D 生成 2023-12-29 12:01

本文分享4D生成方向新工作,由北京交通大学和得克萨斯大学奥斯汀分校共同完成的“4DGen: Grounded 4D Content Generation with Spatial-temporal Consistency”,文章使用Gaussian Splatting实现了高质量的4D生成。
文章主页:https://vita-group.github.io/4DGen/
论文地址:https://arxiv.org/abs/2312.17225
开源代码:https://github.com/VITA-Group/4DGen
研究背景
尽管3D和视频生成取得了飞速的发展,由于缺少高质量的4D数据集,4D生成始终面临着巨大的挑战。过去几篇工作尝试了Text-To-4D的任务,但依然存在两个主要问题:
......长按二维码访问原文







