文章目录[隐藏]
论文:PV-RCNN++: Point-Voxel Feature Set Abstraction With Local Vector Representation for 3D Object Detection
PVRCNN的作者又放出了PVRCNN++,主要在效率上做了改进。
PV-RCNN++
本文首先介绍了PVRCNN,然后基于PVRCNN的框架介绍了PVRCNN++的改进。PVRCNN就不介绍了,可以详见另一篇博客。
PVRCNN速度慢主要是慢在了point-based network这个部分。PVRCNN对做了如下改进。
SPC
FPS比较慢,因为FPS是
O
(
n
2
)
O(n^2)
O(n2)的时间复杂度。并且FPS是覆盖了整个场景的采样,大量的点会采在背景点上。所以作者提出SPC:第一步是用预测的proposal选出靠近物体的点,从而降低点的数量;第二步是将整个场景以激光雷达为原点,按角度分成多份,每个角度内,再用FPS。
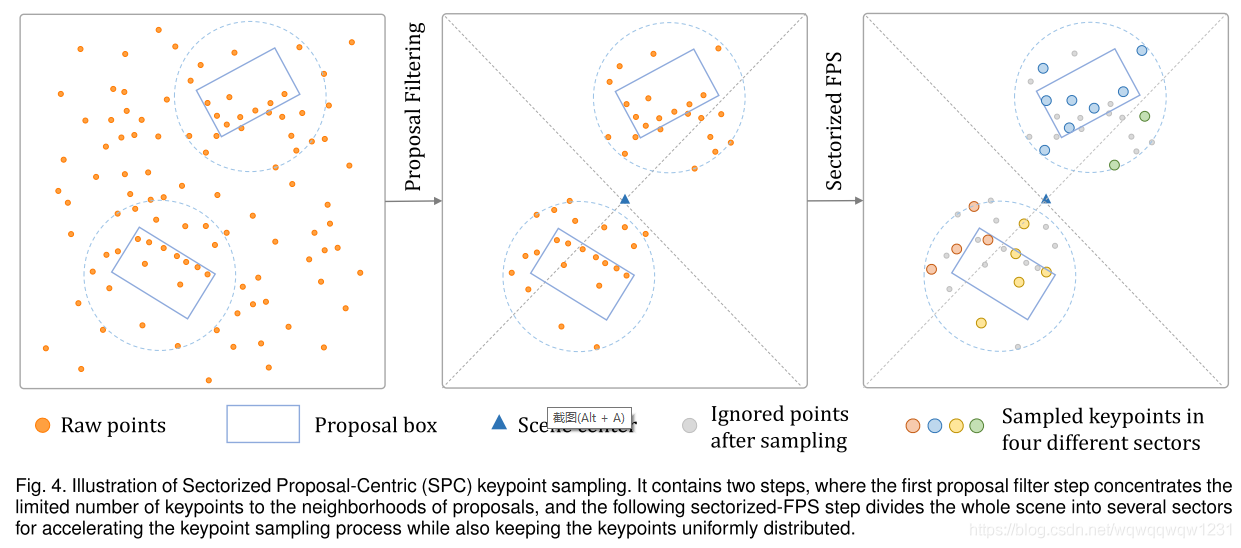
通过减少FPS输入点的数量,来降低FPS的计算时间。而且使得选出来的key point都在物体附近
VectorPool aggregation
SA另外慢还慢在了要做radiusNN,而且SA用的MLP会丢失相对位置关系。所以作者提出了VectorPool的操作,如下图:

对于一个key point,在其周围构建一个voxel,然后对每个格子内的点做平均,然后用一个MLP做特征提取,然后把每个格子的特征拼接起来。
KITTI上报告的运算速度是每帧0.06s,感觉也已经很高了。
版权声明:本文为CSDN博主「麒麒哈尔」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/wqwqqwqw1231/article/details/113923665





![[目标检测]End-to-End Object Detection with Transformers文献解读(2020)](https://sup.51qudong.com/wp-content/uploads/csmbjc/20201205161521549.png?imageMogr2/thumbnail/!300x300r|imageMogr2/gravity/Center/crop/300x300)
