看目标检测网络方面的论文时,出现了一组对比词汇: bottom-up和top-down,查了一些资料,结合个人理解,得到的看法是:
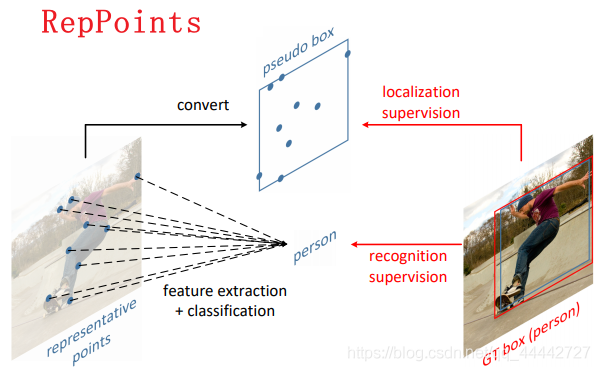
top-down: 顾名思义是自上而下进行,最初来源于行人检测框架,在行人检测中,先检测行人目标,得到边界框,再在边界框中检测人体关键点,连接成每个人的姿态。应用到目标检测网络,就是先获取目标的大致边界,再进一步确定目标的位置,比如RepPoints,通过可变形卷积确定目标边界。
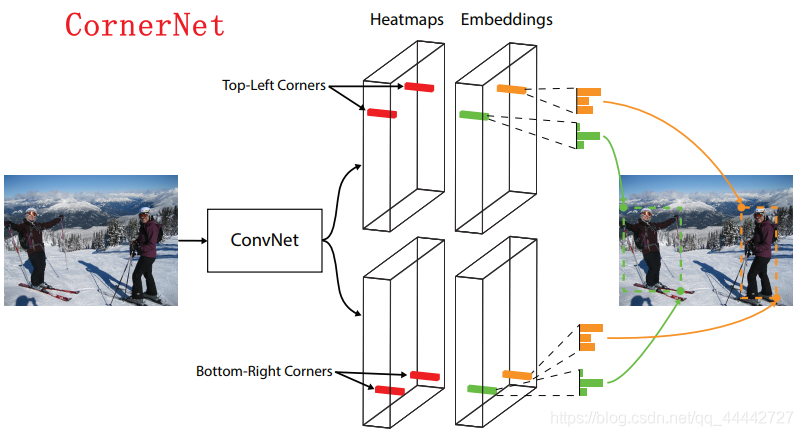
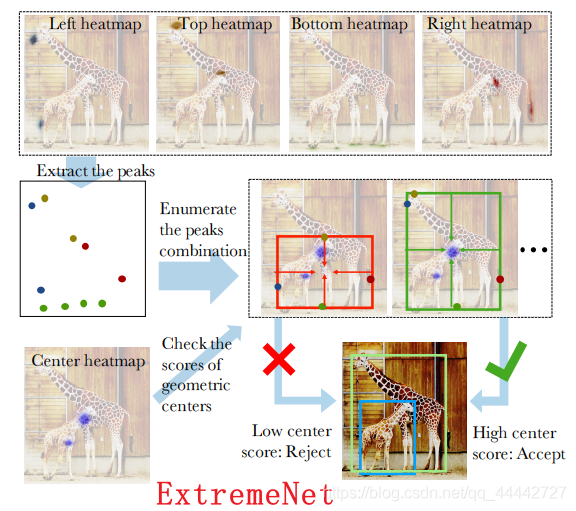
bottom-up:自底向上,图像提取到特征图后,网络先确定目标的边缘极值点或角点,再通过定义这些点是否属于同一个目标,得到目标的边界来确定检测目标,比如CornerNet(左上角点、右下角点)、ExtremeNet(上、下、左、右极值点+中心点)。
版权声明:本文为CSDN博主「清梦枕星河~」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_44442727/article/details/114692401






