DETR是FIR提出的基于Transformers的端到端目标检测,没有NMS后处理步骤、没有anchor,结果在coco数据集上效果与Faster RCNN相当,且可以很容易地将DETR迁移到其他任务例如全景分割。
引用知乎大佬的话来说,这种做目标检测的方法更合理。

优点:
1、提出了一种目标检测新思路,真正的end-to-end,更少的先验(没有anchor、nms等);
2、在coco上,准确率、运行效率与高度优化的faster R-CNN基本持平。在大目标上效果比faster R-CNN好。
3、与大多数现有的检测方法不同,DETR不需要任何自定义层,因此复现容易,涉及到模块都能在任何深度学习框架中找到。
项目地址:https://github.com/facebookresearch/detr
快速查看detr效果:https://github.com/plotly/dash-detr
目标检测效果如下:




可见确实在大目标上检测较为准确。
DETR原理:
DETR总体思路是把检测看成一个set prediction的问题,并且使用Transformer来预测box的set。DETR 利用标准 Transformer 架构来执行传统上特定于目标检测的操作,从而简化了检测 pipeline。


DETR的流程大为简化,可以归结如下:Backbone -> Transformer -> detect header。

DETR模型架构:
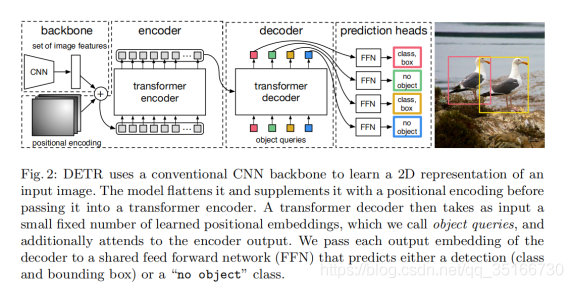
DETR的整体结构Transformer类似:Backbone得到的特征铺平,加上Position信息之后送到一堆Encoder里,得到一些candidates的特征。Candidates又被Decoder并行解码得到最后的检测框。

首先是encoder,DETR Encoder网络一开始是使用Backbone(比如ResNet)提取一些feature,然后降维到d×HW。Feature降维之后与Spatial Positional Encoding相加,然后被送到Encoder里。为了体现图像在x和y维度上的信息,作者的代码里分别计算了两个维度的Positional Encoding,然后Cat到一起。FFN、LN等操作也与Transformer类似。Encoder最后得到的结果是对N个物体编码后的特征。
然后是decoder。DETR Decoder的结构也与Transformer类似,每个Decoder有两个输入:一个是Object Query(或者是上一个Decoder的输出),另一个是Encoder的结果,区别在于这里是并行解码N个object。与原始的transformer不同的地方在于decoder每一层都输出结果,计算loss。另外一个与Transformer不同的地方是,DETR的Decoder和encoder一样也加入了可学习的positional embedding,其功能类似于anchor。最后一个Decoder后面接了两个FFN,分别预测检测框及其类别。
最后是FFN,最终预测是由具有ReLU激活功能且具有隐藏层的3层感知器和线性层计算的。FFN预测框标准化中心坐标,高度和宽度,输入图像,然后线性层使用softmax函数预测类标签。它预测了一组固定大小的N个边界框,其中N通常比图像中感兴趣的对象的实际数量大得多,因此使用了一个额外的特殊类标签∅来表示在未检测到任何对象。此类在标准对象检测方法中与“背景”类具有相似的作用。(这里N被设计为固定的100个,100个完全够用且存在一些冗余输出的,这可能会是一个改进模型的改进点。当然,定长的输出有利于显存对齐,训练的时候会方便一些。一般实验环境是无法达到这么大的显存条件的,可以修改为不并行生成100个)。
bipartite matching loss:




其中IoU 简单来讲就是模型产生的目标box和正确box的交叠率,即检测结果(DetectionResult)与 Ground Truth 的交集比上它们的并集。
所谓二分最大匹配,即保证预测值与真值实现最大的匹配,保证预测的N的实例(包括∅)按照位置与真值对应起来。实现一一对应之后,便能够利用分类Loss以及boundingbox Loss进行优化。
代码理解可参考:
https://blog.csdn.net/feng__shuai/article/details/106625695
版权声明:本文为CSDN博主「夏离」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_35166730/article/details/106680251






