1.背景
1.R-CNN网络训练、测试速度都很慢:R-CNN网络中,一张图经由selective search算法提取约2k个建议框(这2k个建议框大量重叠),而所有建议框变形后都要输入AlexNet CNN网络提取特征(即约2k次特征提取),会出现上述重叠区域多次重复提取特征,提取特征操作冗余;
2.R-CNN网络训练、测试繁琐:R-CNN网络训练过程分为ILSVRC 2012样本下有监督预训练、PASCAL VOC 2007该特定样本下的微调、20类即20个SVM分类器训练、20类即20个Bounding-box 回归器训练,该训练流程繁琐复杂;同理测试过程也包括提取建议框、提取CNN特征、SVM分类和Bounding-box 回归等步骤,过于繁琐;
3.R-CNN网络训练需要大量存储空间:20类即20个SVM分类器和20类即20个Bounding-box 回归器在训练过程中需要大量特征作为训练样本,这部分从CNN提取的特征会占用大量存储空间;
4.R-CNN网络需要对建议框进行形变操作后(形变为227×227 size)再输入CNN网络提取特征,其实像AlexNet CNN等网络在提取特征过程中对图像的大小并无要求,只是在提取完特征进行全连接操作的时候才需要固定特征尺寸(R-CNN中将输入图像形变为227×227可正好满足AlexNet CNN网络最后的特征尺寸要求),然后才使用SVM分类器分类,R-CNN需要进行形变操作的问题在Fast R-CNN已经不存在。
2.算法原理
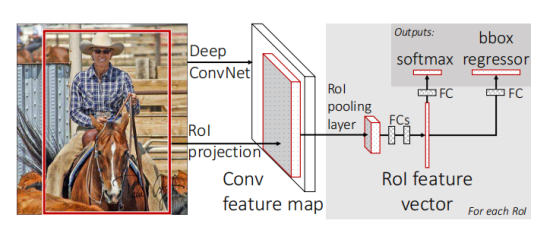
Fast R-CNN大体可分为以下三个步骤:
- 一张图像生成1k-2k个候选区域(使用Selective Search方法)。
- 将图像输入网络得到相应的特征图,将SS算法声生成的候选框投影到特征图上获得相应的特征矩阵。
- 将每个特征矩阵通过ROI pooling层缩放到7*7大小的特征图,接着将特征图展平通过一系列全连接层得到预测结果。
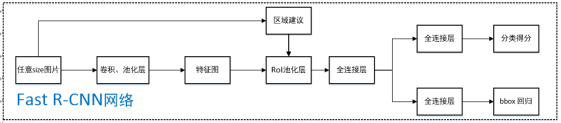
1.任意size图片输入CNN网络,经过若干卷积层与池化层,得到特征图;
2.在任意size图片上采用selective search算法提取约2k个建议框;
3.根据原图中建议框到特征图映射关系,在特征图中找到每个建议框对应的特征框,并在RoI池化层中将每个特征框池化到7*7的size;
4.固定7*7大小的特征框经过全连接层得到固定大小的特征向量;
5.第4步所得特征向量经由各自的全连接层,分别得到两个输出向量:一个是分类为器,一个是边界框回归器;
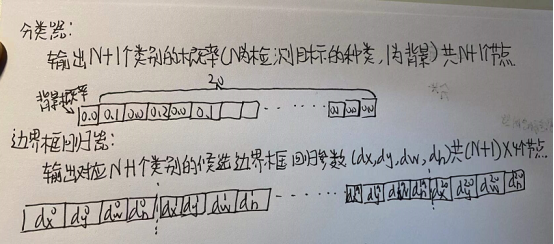


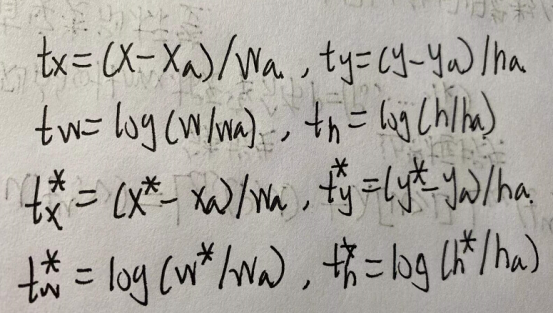
6.利用窗口得分分别对每一类物体进行非极大值抑制剔除重叠建议框,最终得到每个类别中回归修正后的得分最高的窗口。
版权声明:本文为CSDN博主「菜狗子a」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_44570701/article/details/122344585






