一、原理解析
论文地址:
https://arxiv.org/abs/1506.02640 (YOLO v1)
https://arxiv.org/abs/1612.08242 (YOLO v2)
https://arxiv.org/abs/1804.02767 (YOLO v3)
YOLO系列的论文可以说是一环套一环,每一篇论文都省略了上一篇讲到的内容。所以要了解YOLOv3的理论需要从yolov1开始看才能了解清楚。我会将三篇论文的内容尽量融合在一起简略的讲解YOLO的原理,如果想要更好了解YOLOv3的理论可以参考https://www.bilibili.com/video/BV1yi4y1g7ro,他讲解的很详细。
首先看YOLOv3的框架(这张图也出自上面那个大佬, 来源https://github.com/WZMIAOMIAO/deep-learning-for-image-processing/blob/master/pytorch_object_detection/yolov3_spp/yolov3spp.png )
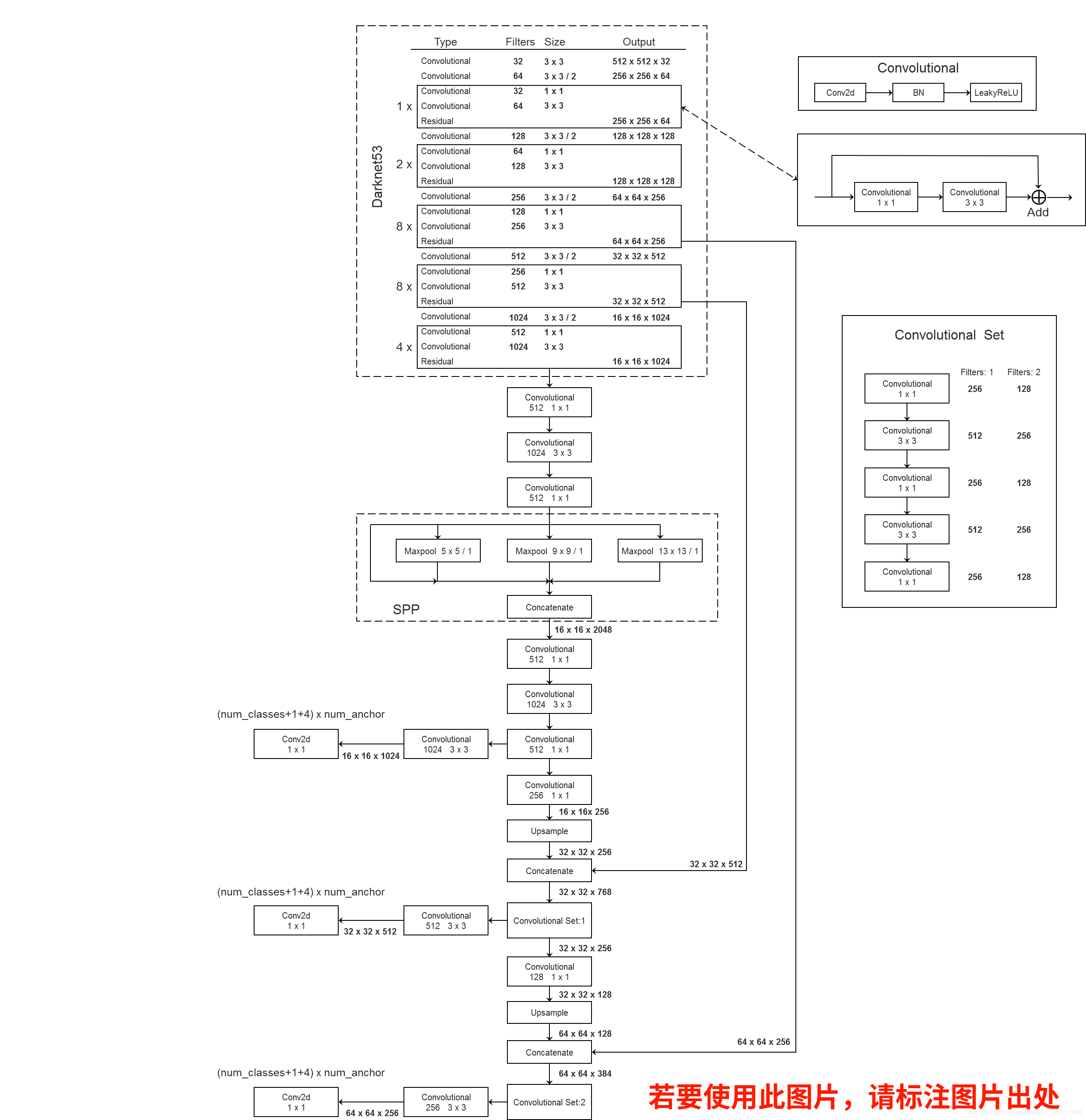
YOLO属于one-stage算法。不同于Faster-RCNN等two-stage算法,one-stage算法通常推理速度较快,但是模型精度不高,不过模型精度在YOLOv3的提出之后有了很大提升。YOLOv3的精度几乎可以媲美那些不足1FPS的模型同时自身可以达到30FPS甚至更快的速度。
1.1 特征提取
YOLO系列采用Darknet网络作为特征提取网络,YOLOv2采用Darknet-19, YOLOv3采用Darknet-53。Darknet-19长得比较像VGGnet,而Darknet-53参考了Resnet。Darknet-53大量使用残差结构从而使网络可以在53层卷积层下能够正常学习,不会受到退化问题(degradation problem)的影响(关于退化问题以及残差结构可以参考https://arxiv.org/abs/1512.03385)。Darknet-53中舍弃了池化层,并通过stride为2的卷积层实现了池化层的功能。这一步操作可能为Darknet-53带来了速度与精度上的一定提升。
现在有ResNeXt、EfficientNet等网络可以用来进行特征提取,也可以用新的网络替换Darknet-53进行训练。
1.2 目标检测
图片经过特征提取网络推理后可以得到特征图。在分类任务中,我们都是直接通过全连接层将展平
版权声明:本文为CSDN博主「Eclipse_777」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_35831198/article/details/113848741







{kind=link}