文章目录[隐藏]
1.创新和优缺点
YOLO 非常快。由于我们将检测视为回归问题,因此我们不需要复杂的管道。我们只是在测试时在新图像上运行我们的神经网络来预测检测。此外,YOLO 的平均精度是其他实时系统平均精度的两倍以上。
当进行预测时,YOLO 对图像进行全局推理。与基于滑动窗口和区域提议的技术不同,YOLO 在训练和测试期间看到整个图像,因此它隐式编码了关于类及其外观的上下文信息。与 Fast R-CNN 相比,YOLO 的背景错误数量不到其一半。
YOLO 学习目标的可概括表示。当在自然图像上进行训练并在艺术品上进行测试时,YOLO 在很大程度上优于 DPM 和 R-CNN 等顶级检测方法。由于 YOLO 是高度可推广的,因此在应用于新领域或意外输入时不太可能崩溃。
YOLO 在准确性方面仍然落后于最先进的检测系统。虽然它可以快速识别图像中的物体,但它很难精确定位某些物体,尤其是小物体。
很难泛化到具有新的或不寻常的纵横比或配置的目标。
2.算法流程
-
将输入图像划分为
S x S的网格,如果目标的中心落入网格单元中,则该网格单元负责检测该目标。 -
每个网格单元预测 B 个边界框和这些框的置信度分数。这些置信度分数反映了模型对框包含目标的置信度,以及它认为框预测的准确度。正式地,我们将置信度定义为
P
r
(
O
b
j
e
c
t
)
∗
I
O
U
p
r
e
d
t
r
u
t
h
Pr(Object) ∗IOU^{truth}_{pred}
Pr(Object)∗IOUpredtruth。如果该单元格中不存在目标,则置信度分数应为 0。否则,我们希望置信度得分等于预测框和真实边界框之间的交集(
IOU)。 -
每个边界框由 5 个预测组成:x、y、w、h 和置信度。 (x,y) 坐标表示相对于网格单元边界的框中心,宽度和高度是相对于整个图像预测的,x、y、w、h 都进行归一化。最后,置信预测表示预测框和任何真实边界框之间的
IOU。 -
每个网格单元还预测 C 条件类概率,
P
r
(
C
l
a
s
s
i
∣
O
b
j
e
c
t
)
Pr(Class_{i}|Object)
Pr(Classi∣Object)。这些概率以包含目标的网格单元为条件。我们只预测每个网格单元的一组类概率,而不管框 B 的数量。
-
每个框对于某一类别目标的置信度分数是
P
r
(
C
l
a
s
s
i
∣
O
b
j
e
c
t
)
∗
P
r
(
O
b
j
e
c
t
)
∗
I
O
U
p
r
e
d
t
r
u
t
h
=
P
r
(
C
l
a
s
s
i
)
∗
I
O
U
p
r
e
d
t
r
u
t
h
—
—
(
1
)
Pr(Class_i|Object) ∗Pr(Object) ∗IOU^{truth}_{pred} = Pr(Class_i) ∗IOU^{truth}_{pred}—— (1)
Pr(Classi∣Object)∗Pr(Object)∗IOUpredtruth=Pr(Classi)∗IOUpredtruth——(1)
这些分数编码了该类别目标出现在框中的概率,以及预测的框与目标的匹配程度。 -
预测输出是
S x S x (B x 5 + C)的张量
2.1.网络结构
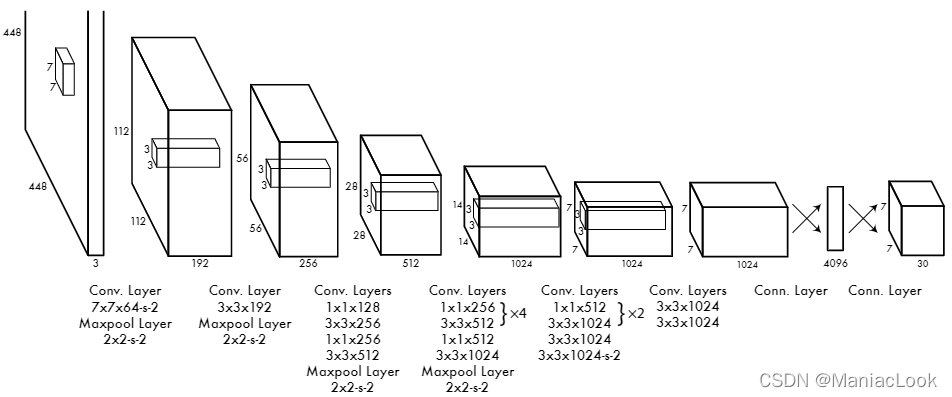
网络的初始卷积层从图像中提取特征,而全连接层预测输出概率和坐标。
网络的最终输出是 7 × 7 × 30 的预测张量,特征图有 7 x 7 个格点,每个格点有 2 个边界框,预测 20 个目标类别。
2.2.训练
2.2.1.输入图像
输入图像分辨率是 448 x 448
2.2.2.激活函数
网络中最后一层使用线性激活函数,其它层使用 leaky 整流线性激活函数:
φ
(
x
)
=
{
x
,
x
>
0
0.1
x
,
o
t
h
e
r
w
i
s
e
—
—
(
2
)
φ(x)=\begin{cases} x,x>0\\ 0.1x, otherwise\end{cases}——(2)
φ(x)={x,x>00.1x,otherwise——(2)
2.2.3.损失函数
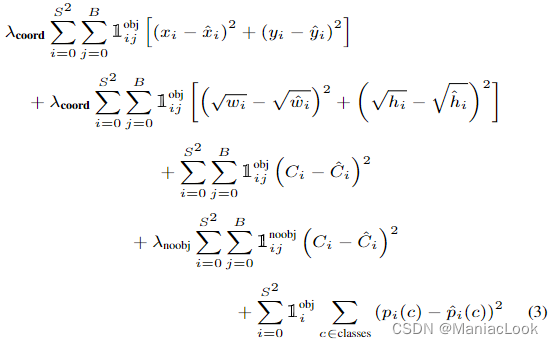
其中
1
i
o
b
j
1^{obj}_i
1iobj 表示目标是否出现在单元格 i 中,
1
i
j
o
b
j
1^{obj}_{ij}
1ijobj 表示单元格 i 中的第 j 个边界框预测器“负责”该预测。为增加边界框坐标预测的损失,并且减少了不包含对象的框的置信度预测的损失,设置
λ
c
o
o
r
d
λ_{coord}
λcoord = 5 和
λ
n
o
o
b
j
λ_{noobj}
λnoobj = .5。
2.2.4.学习率
对于第一个 epoch,我们慢慢地将学习率从
1
0
−
3
10^{-3}
10−3 提高到
1
0
−
2
10^{-2}
10−2。如果我们以高学习率开始,我们的模型通常会因梯度不稳定而发散。我们继续用
1
0
−
2
10^{-2}
10−2 训练 75 个 epoch,然后用
1
0
−
3
10^{-3}
10−3 训练 30 个 epoch,最后用
1
0
−
4
10^{-4}
10−4 训练 30 个 epoch。
2.2.5.防止过拟合
为了避免过度拟合,我们使用 dropout 和广泛的数据增强。在第一个连接层之后具有 rate = .5 的 dropout 层可防止层之间的协同适应。对于数据增强,我们引入了高达原始图像大小 20% 的随机缩放和平移。我们还在 HSV 色彩空间中随机调整图像的曝光度和饱和度,最高可达 1.5 倍。
2.3.推理
当一个目标可能被多个网格单元预测时,用 NMS 进行处理,去除掉重复检测的边界框。
版权声明:本文为CSDN博主「ManiacLook」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/ManiacLook/article/details/122102756






