下文中的开源实现以腾讯的OneDetection作为分析对象。
yolo v3基本原理:
相对于yolo v2,yolo v3做了如下改进:
更换了backbone网络,使用darknet53,没有pool层,全部使用卷积,降采样5次
使用类似于FPN的技术,融合多层特征预测
对分类和置信度使用二分类交叉熵(v1和v2全部使用MSE)
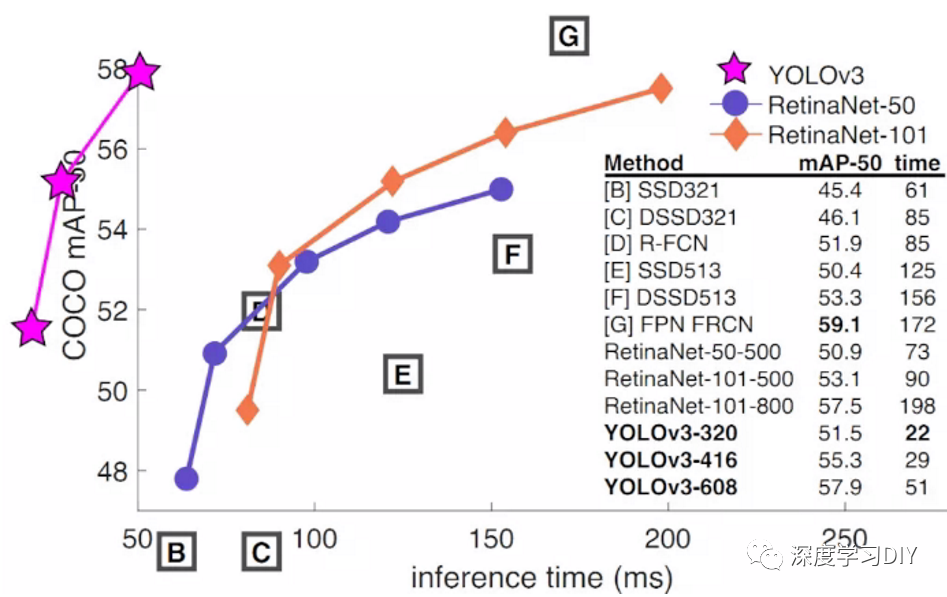
yolo v3是2018年出来的,比SSD和retinanet都要晚,在map0.5这个指标上速度比SSD和retinanet快很多。在工业应用上面map0.5已经满足使用,并且yolo v3简介,文档丰富,还有tiny版本等一些列变种。最重要的是速度非常快,比SSD和retinanet都要快。如果采用COCO mAP50做评估指标(不是太介意预测框的准确性的话),YOLO3的表现相当惊人,如下图所示,在精确度相当的情况下,YOLOv3的速度是其它模型的3、4倍。
网络结构:
Tencent项目的yolov3网络结构缩略图:

实现细节
损失系数:
在v1和v2里面,坐标损失使用系数5,not response box的confidence使用系数0.5
但是在开源实现的yolo v3里面,没有区分response和notresponse的box,confidence损失合在一起,并且使用了系数64
坐标中心损失系数:8
坐标宽高损失系数:4
分类损失系数:1
置信度损失系数:64
正负样本的确定
对于正样本,以GT来找。某一个GT对应的cell里面,最大IOU的那个anchor作为正样本训练。在开源实现里面也支持设置一个阈值,当GT和那个最大iou的anchor的IOU小于阈值的时候,舍弃其作为正样本。也就是这个GT不参与正样本的训练。除了正样本anchor之外,其余所有的anchors都作为负样本参与训练。
正样本:与GT最大IOU的那个anchor作为正样本。注意某一个GT的最大IOU只会在一个feature map中,所以只有一个feature map中的某一个anchor会作为这个GT的正样本。
负样本:除了正样本之外,预测框与GT的IOU大于阈值(0.5)当做负略样本。剩下的就全部作为负样本
anchor值
沿袭了yolo v2的方式,通过数据集中的聚类得到,但是yolov2中,anchor的尺寸相对于最后一个feature map。在yolo v3中,相对于原始图片,所以anchor的值都是相对于输入图片的宽和高。
开源作者关于yolo v3训练的经验:
pred[:,4]*=class_conf#improvesmAPfrom0.549to0.551
The loss multiples you see there, 8, 4, 64 etc.
The loss constant k that is applied to all losses. Some people believe this should be a function of the batch size, etc.
The classification loss is now CE rather than BCE as we found better results this way.
There is an IOU rejection constant of 0.10 in build_targets() which we found dramatically improved training results.
Image augmentation settings in datasets.py
数据增强
开源的yolo v3里面使用了:hsv抖动,放射变换以及flip(左右镜像)来做数据增强
yolo v3的缺点:
在map>0.5的指标上面,性能下降厉害,最终的map比retinanet要差。
yolo v3的map对比图
《深度学习: 从YOLOv1到YOLOv3》
来自

版权声明:本文为CSDN博主「clark.d」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_36171481/article/details/112449791






