文章目录[隐藏]
目录
1整体设计 1
1.1实验任务 1
1.2开发思路 1
2. 目标检测数据集的建立 2
2.1 采集目标检测对象 2
2.2 采集图像 2
2.3 图像预处理 2
2.4 图像标注 3
3. YOLOv3训练目标检测识别模型 11
3.1 搭建开发环境 11
3.2 下载、配置、编译及检验工程项目 11
3.3 将目标检测集及配置文件移植到工程项目 14
3.4 训练过程 15
4. 利用训练模型测试图片和视频 18
4.1 测试图片 18
4.2 测试视频 20
4.3 测试结果分析 21
参考资料 221整体设计
1.1实验任务
建立一个不少于10个不同种类的目标检测数据集,测试数据是实时视频并要求有一定的背景复杂度。
1.2开发思路
(1)采集目标检测建立目标检测数据集;
(2)利用YOLOv3训练模型;
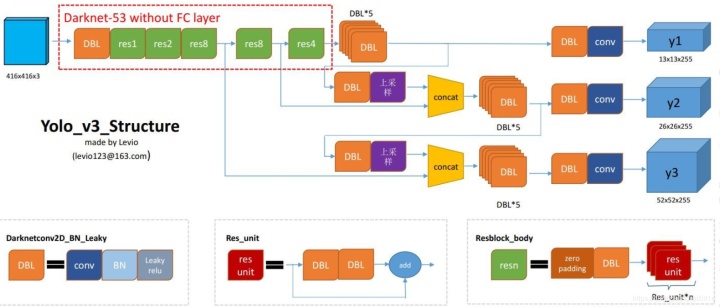
YOLO v3的Bounding Box由YOLOV2又做出了更好的改进。在yolo_v2和yolo_v3中,都采用了对图像中的object采用k-means聚类。 feature map中的每一个cell都会预测3个边界框(bounding box) ,每个bounding box都会预测三个东西:(1)每个框的位置(4个值,中心坐标tx和ty,,框的高度bh和宽度bw),(2)一个objectness prediction ,(3)N个类别,coco数据集80类,voc20类。
三次检测,每次对应的感受野不同,32倍降采样的感受野最大,适合检测大的目标,所以在输入为416×416时,每个cell的三个anchor box为(116 ,90); (156 ,198); (373 ,326)。16倍适合一般大小的物体,anchor box为(30,61); (62,45); (59,119)。8倍的感受野最小,适合检测小目标,因此anchor box为(10,13); (16,30); (33,23)。所以当输入为416×416时,实际总共有(52×52+26×26+13×13)×3=10647个proposal box。
2. 目标检测数据集的建立
2.1 采集目标检测
我们在校园内收集了上述目标检测每种各10片。收集的目标检测一般要求形态特征完整、所要图片平整,以方便后面我们的数字化处理。
2.2 采集图像
我们采用手机对采集的所要图片拍照得到目标检测图像。在采集目标检测图像的时候一般要注意以下几点。一是背景纯净,这里我们用一张白纸作为背景;二是尽量避免光线直射并不要有人为的阴影遮挡,我们是在宿舍里对采集的所要图片拍照,用了几盏台灯在四周补光。三是所要图片尽可能摆放平整,我们在收集所要图片的时候便刻意采集了比较平整的所要图片。每片目标检测我们采集其4种形态的照片,因此每类有40张目标检测照片,整个目标检测集有400张照片。
2.3 图像预处理
预处理主要包括对目标检测图像的统一像素大小和命名。我们将所有目标检测图片都编辑为416×416大小。
2.4 图像标注
图像标注是指用标注工具将目标检测图像中的所要图片选择框出,于是便会产生一个txt格式的文本,里面包含所要图片id(与我们自定义的所要图片名字一一对应)和所要图片位置信息(在训练的时候可获取“图像中该位置区域代表何种目标检测”的信息)。我们采用的是官方推荐的标注工具——Yolo_mark-master,官方下载网址是https://github.com/AlexeyAB
/Yolo_mark。编译环境是Windows10+VS2015+opencv3.4.0。
以下将详细介绍Yolo_mark-master的配置及使用步骤。
(1)编译Yolo_mark-master项目
在官网上下载darknet-master工程代码后解压,打开yolo_mark.sln,编译运行前还需要做两件事情。
①在“解决资源管理器”下右键项目,打开项目属性窗口,设置为Release&64。
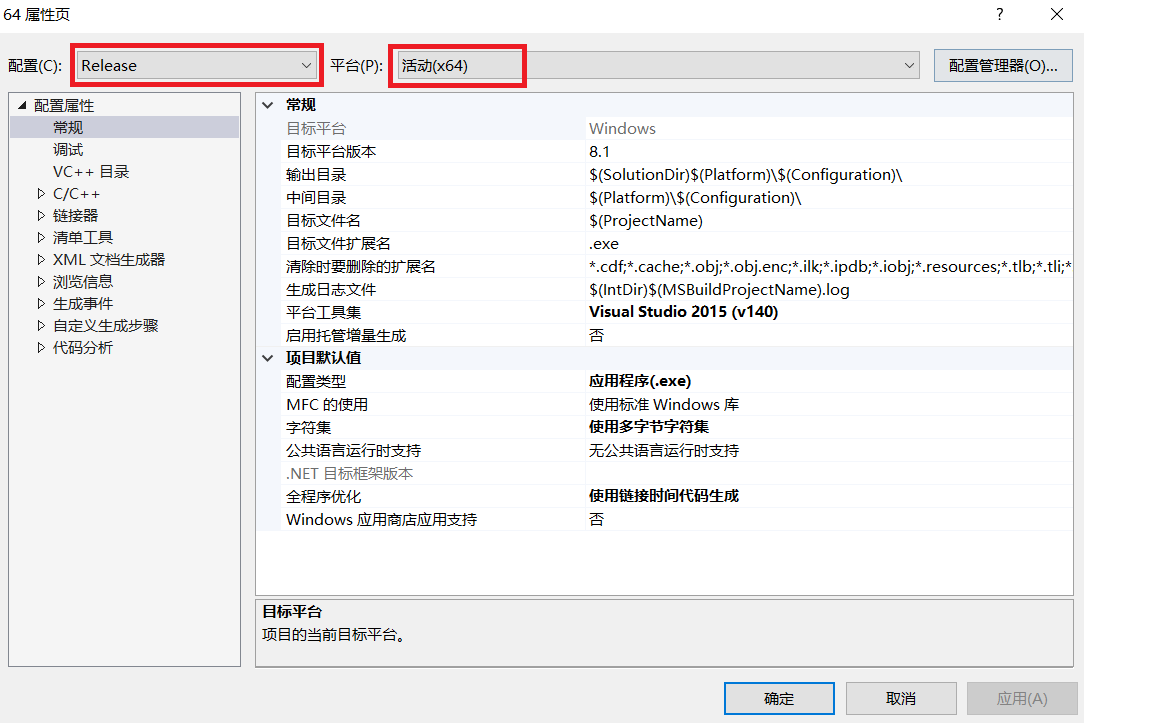
图3.3 设置属性窗口(1)
②将项目与自己电脑的opencv文件路径链接。
在“C/C++—>常规—>附加包含目录”,修改为自己的opencv中“include”文件夹路径。我这里是“C:opencvbuildinclude”。如下图所示。
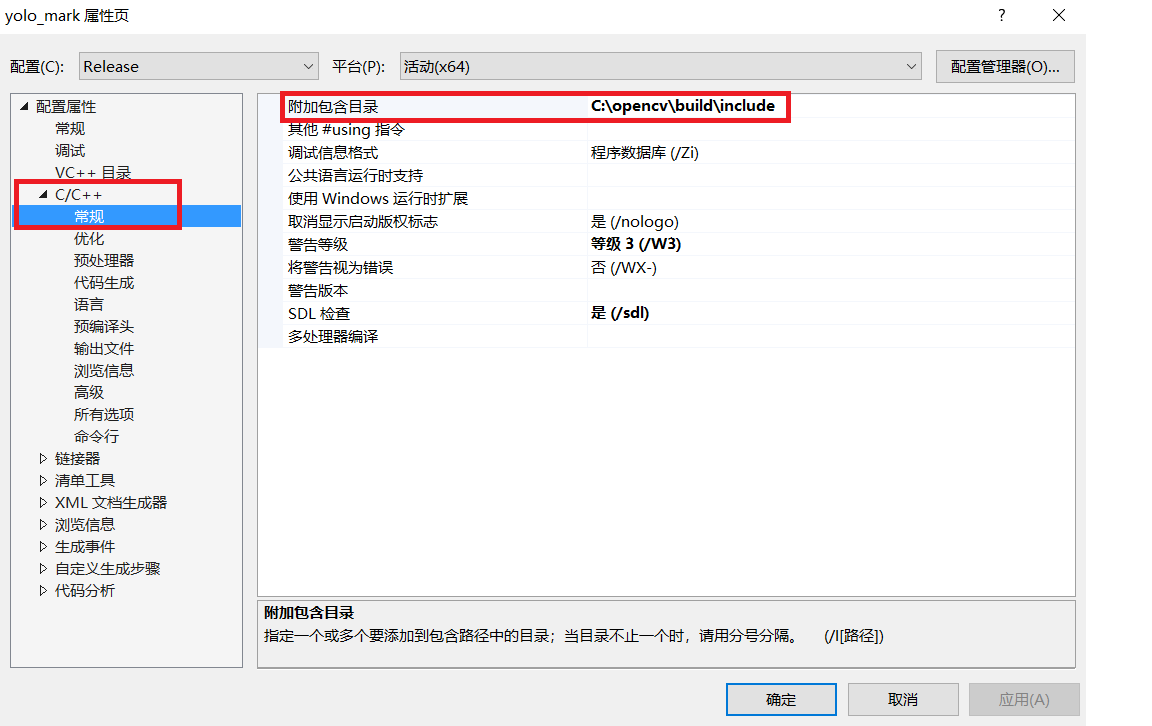
图3.4 设置属性窗口(2)
在“链接器—>常规—>附加包含目录”,修改为自己的opencv中“lib”文件夹路径。我这里是“C:opencvbuildx64vc14lib”。如下图所示。(补充说明:v14——VS2015,V15——VS2017)
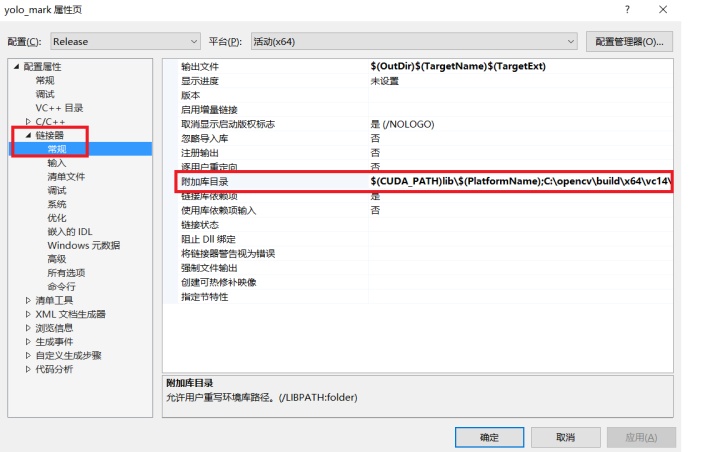
图3.5 设置属性窗口(3)
完成a、b以后,注意要先点“应用”,然后点“确定”,窗口关闭。另外,编译运行项目前注意工具栏这里也要设置为Release&64。
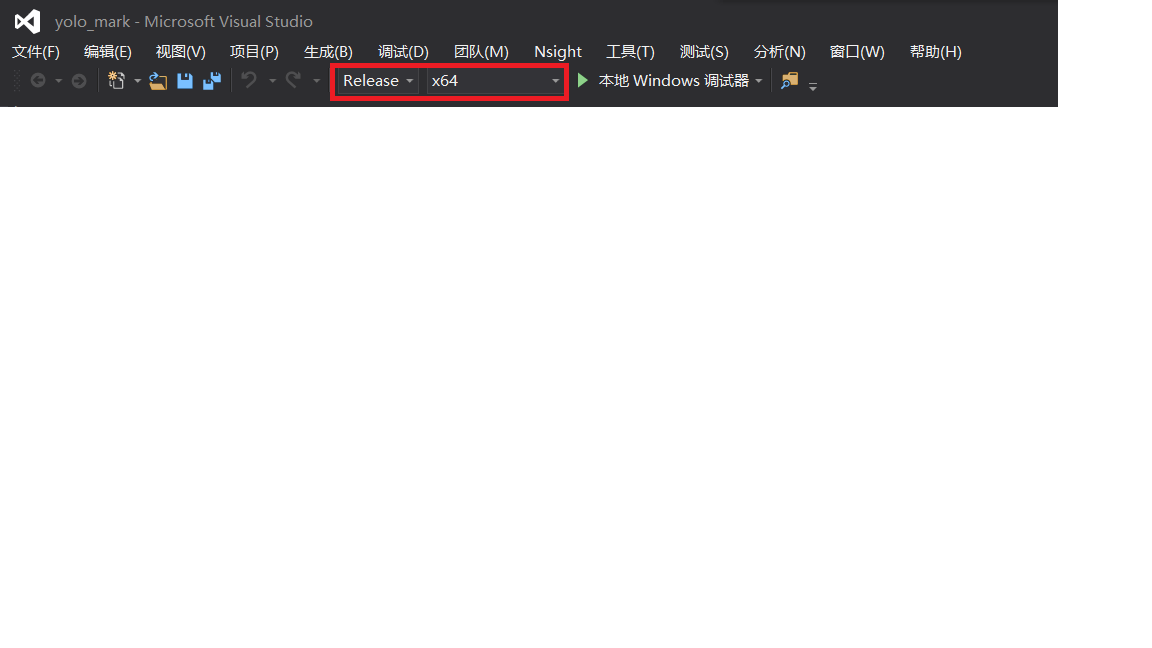
图3.6 设置工具栏
编译运行项目后,会在“Yolo_mark-masterx64Release”路径下产生“yolo_mark.exe”文件,双击“yolo_mark.cmd”便可打开Yolo_mark-master的图形界面。如下图所示。“image num:n”指我们当前正在标注整个数据集中的第n张图片;“object id:m”指我们给标注的物体选择第m个id号,前面也已经介绍,id与我们自定义的所要图片名字一一对应。
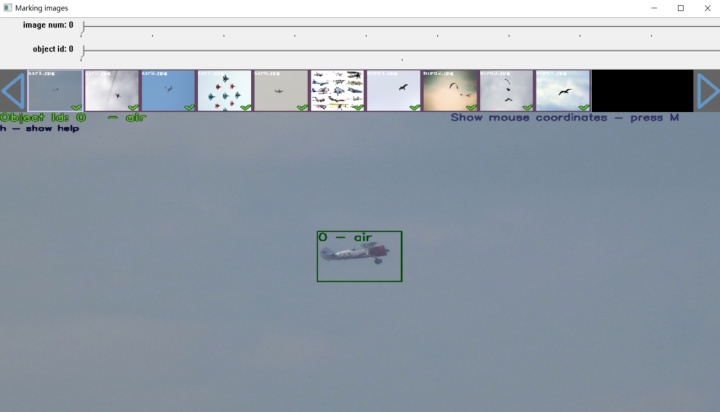
图3.7 标注工具图形界面
(2)标注图像
①删除“Yolo_mark-masterx64Releasedataimg”中的所有数据,把我们预处理好的400张目标检测图像放到该目录。
②更改“Yolo_mark-masterx64Releasedataobj.data”文件中“classes= 10”(因为我们的所要图片种类是10),保存;

③更改“Yolo_mark-masterx64/Release/data/obj.names”文件中物体名字,如下图所示,然后保存。它们对应的id分别为0-9。

④双击“yolo_mark.cmd”便可打开官方标注工具。如下图所示。图中可以看到我们目前正在标注的是400张图像的第一张(从0开始计数),id是0,对应着目标检测名
3. YOLOv3训练目标检测识别模型
制作好目标检测数据集后就要训练自己的目标检测识别模型了。这也是最核心最关键的一部分。以下为训练自己的模型的详细步骤。
3.1 搭建开发环境
我们使用的开发环境为window10+ VS2015(v14)+ OpenCV3.4.0+ cuDNNv7.1.3+ CUDA9.1。开发环境的搭建在CSDN上有很多前人的宝贵经验可以借鉴,这里不再赘述。
3.2 下载、配置、编译及检验工程项目
(1)我们从GitHub上下载项目代码(网址:https://github.com/AlexeyAB/darknet),并解压。
(2)进入“darknet-masterbuilddarknet”目录,利用编辑器(记事本即可)打开darknet.vcxproj,将CUDA修改为自己对应的版本。由于darknet.vcxproj中默认使用的是CUDA 9.1,此处我们不用修改。
(3)用VS2015打开“darknet-masterbuilddarknet”目录下的“darknet.sln”(没有GPU则打开darknet_no_gpu.sln)。首先工具栏这里设置成“Release&x64”。
图4.1 设置工具栏
(4)配置文件及编译。
在“属性页—>VC++目录—>包含目录”中添加“C:opencvbuildinclude”(即本机opencv的include文件路径);在“属性页—>VC++目录—>库目录”中添加“C:opencvbuildx64vc14lib”(即本机opencv的lib文件路径)。如下图所示。
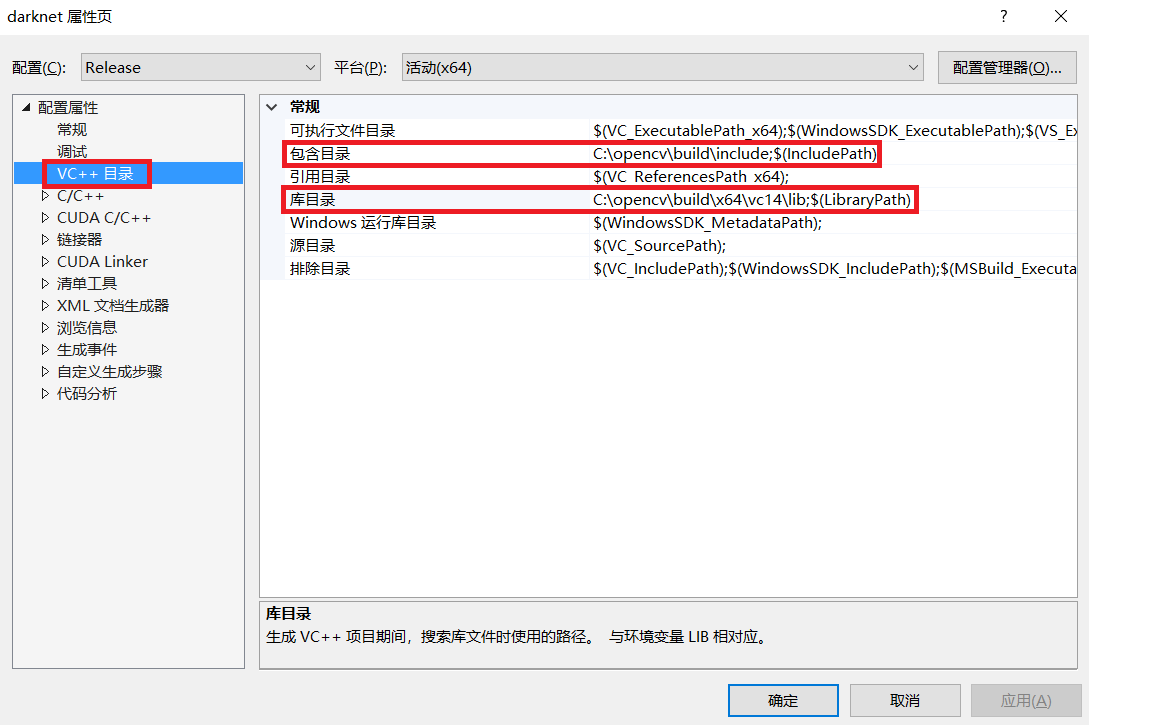
图4.2 设置属性窗口(1)
在“链接器—>输入—>附加依赖项”中添加“opencv_world340.lib”。(说明:opencv_world340.lib是位于“opencvbuildx64vc14lib”目录下的一个库)如下图所示。
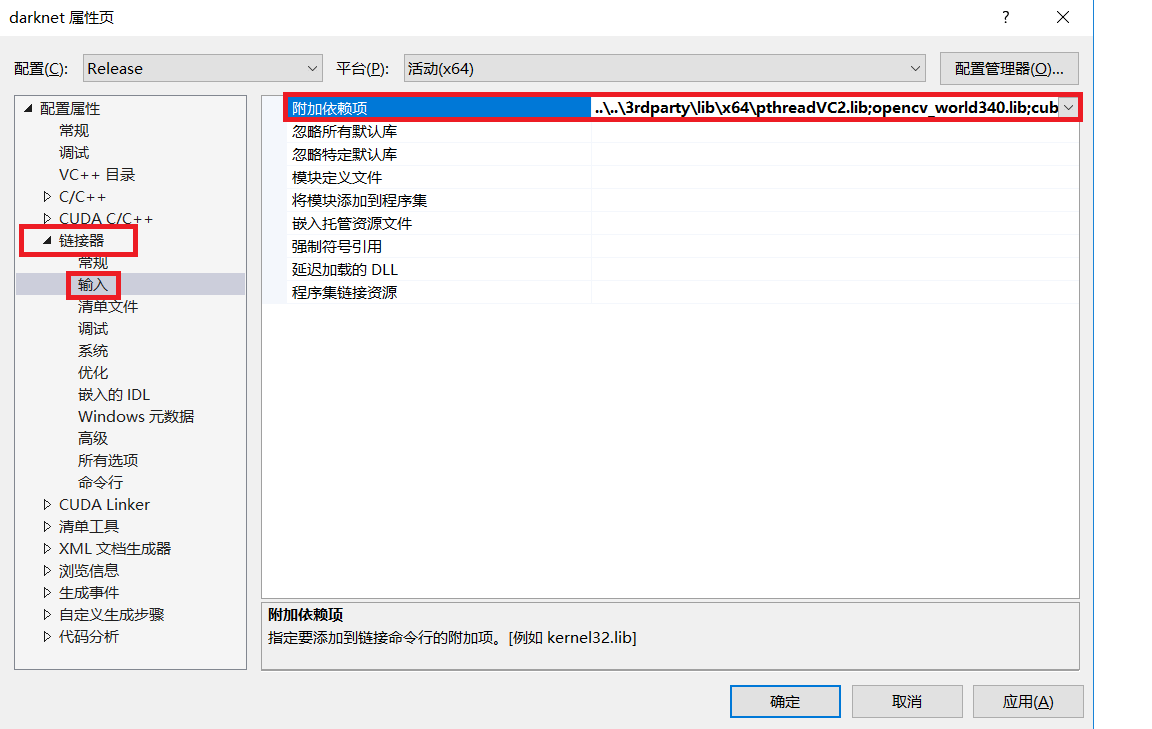
图4.3 设置属性窗口(2)
将“C:Program FilesNVIDIA GPU Computing Toolkit CUDAv9.1extras visual_studio_integrationMSBuildExtensions”中的所有文件拷贝到
“C:Program Files(x86)MSBuildMicrosoft.Cppv4.0v140BuildCustomizations”。
右键项目—>生成。成功后会在“darknet-masterbuilddarknetx64”目录下生成一个“darknet.exe”文件,然后将“opencvbuildx64vc14bin”下的“opencv_world340.dll”和“opencv_ffmpeg340_64.dll”复制到 “darknet.exe”的同级别目录下。
(5)检验配置是否成功。
从GitHub上下载已训练好的模型——yolov3.weights,点击超链接即可下载。
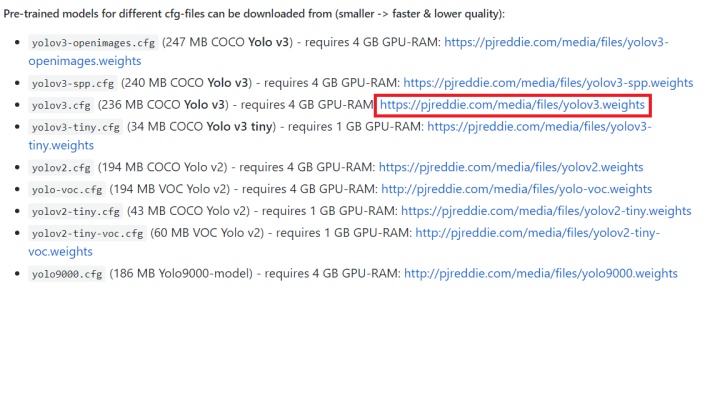
图4.4 yolov3.weights下载
下载后放在“darknet-masterbuilddarknetx64”下,双击该目录下的“darknet_yolo_v3.cmd”会出现下图结果,表明配置及编译工程项目成功。

图4.5 配置成功测试图
3.3 将目标检测集及配置文件移植到工程项目
(1)配置cfg文件
复制“darknet-mastercfg”目录下的“yolov3.cfg”并重命名为“yolov3-leaf.cfg”(或者其他名字,只要各处对应即可),复制到与“darknet.exe”同目录下(或者其他目录,输入命令时对应即可)。
打开“yolov3-leaf.cfg”文件(建议用VS打开,因为显示行数,而后面涉及到某些行参数的修改,方便查找)。然后进行以下修改。
①修改batch=64,subdivisions=8。
含义为每轮迭代训练会从所有训练集里随机抽取batch = 64个样本参与训练,所有这些batch个样本又被均分为subdivision = 8次送入网络参与训练,以减轻内存占用的压力。因此subdivision值小于等于batch。
②修改classes=10。
因为我们有10种所要图片,修改的行数为610、696、783。
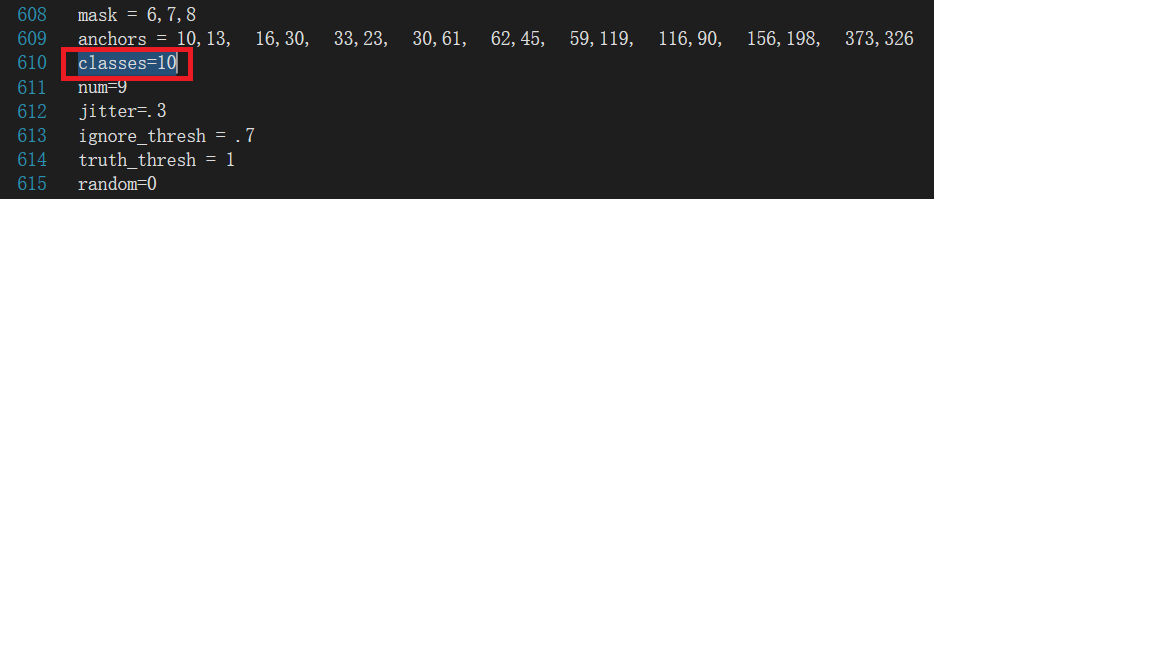
图4.6 修改classes
③修改filters=45。
计算filters=(classess+5)*3=(10+5)*3=45,修改行数为603、689、776。
(2)移植obj.names文件、obj.data文件和train.txt文件
将制作目标检测数据集时遇到的obj.names文件和obj.data文件及同目录的train.txt文件复制到“darknet-masterbuilddarknetx64data”路径下,并分别重命名为“obj-leaf.names”、“obj-leaf.data”和“train-leaf.txt”。
obj-leaf.names文件内容不需要修改。将train-leaf.txt文件中的“img”全部替换为“leaf”。obj-leaf.data文件内容修改如下图所示。

图4.7 修改obj-leaf.data文件
(3)移植目标检测数据集
在“darknet-masterbuilddarknetx64data”路径下新建一个“leaf”文件夹,将标注好的目标检测数据集全部复制到该文件夹。
(4)下载预训练模型
我们是在预训练模型上用自制数据集继续进行训练。从GitHub上下载预训练模型“darknet53.conv.74”并放到“darknet-masterbuilddarknetx64”路径下。

图4.8 GitHub上预训练模型下载链接
3.4 训练过程
(1)命令语句介绍
需要我们发出相关命令语句才能进行相关训练操作。发出命令语句的方式有两种,一是打开“命令提示符”窗口,进入darknet.exe同级目录,然后输入命令语句,“enter”键执行;二是直接在darknet.exe同级目录新建.cmd格式文件,然后在文件内写入希望执行的命令语句,保存后双击该.cmd格式文件便可执行命令。方法二可重复执行,因此一般我们采用方法二。
训练命令语句为:darknet.exe detector train data/obj-leaf.data yolov3-leaf.cfg darknet53.conv.74
解释:darknet.exe detector train:表示训练(train改为test为测试);data/obj-leaf.data:表示data文件路径;yolov3-leaf.cfg:表示cfg文件的路径;darknet53.conv.74:表示预训练模型路径。
(2)开始训练
①新建命令文件
新建.cmd格式文件并命名为“yolov3_leaf_train”,右键—>编辑,将训练命令语句复制进去并保存。
②排错调试
双击“yolov3_leaf_train.cmd”,开始训练。这时候,我出现了内存不足的错误。于是,我便开始以下调试。
a.修改cfg文件中subdivisions为16或32或64,还是内存不足。
b.三个修改classes的地方,下面几行都有一个random参数,默认是random=1,表示开启多尺度训练;这里我们可以把这三处都修改为random=0,即关闭多尺度训练。尝试之后,还是内存不足。
c.接下来我尝试减小batch值,当使batch=8,subdivisions=8时,便不再出现内存不足的错误了。
②正式训练
解决内存不足错误后,双击“yolov3_leaf_train.cmd”。便出现如下图所示的结果。一开始avg loss值比较大,在一千左右,不过开始时avg loss值衰减的也比较快。当avg loss值衰减到10以下后,衰减的就非常缓慢了。
本次训练用了将近一天一夜的时间在我电脑上迭代训练了两万六千多次。每迭代一百次会生成一个.weights格式的训练模型,可在“backup”文件夹下查看。由于一个模型将近240M大小,因此可以定期删除一些模型,以防止磁盘空间被用完。
在迭代到13900次时,由于要用电脑做些别的事情,我叉掉命令框中断了一下。后面我又在此基础上继续训练,只需将训练命令语句中的“darknet53.conv.74”修改为“yolov3-leaf_13900.weights”,保存后再双击“yolov3_leaf_train.cmd”文件即可。
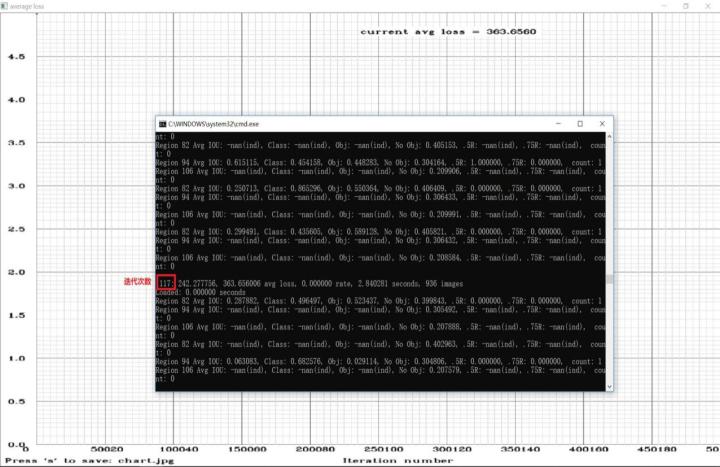
图4.9 训练截图(1)
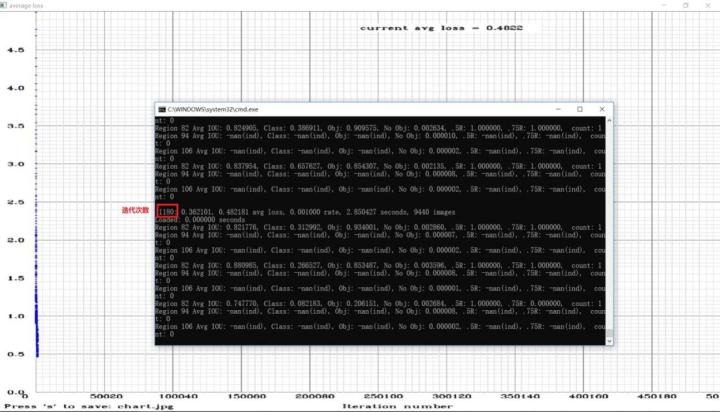
图4.10 训练截图(2)
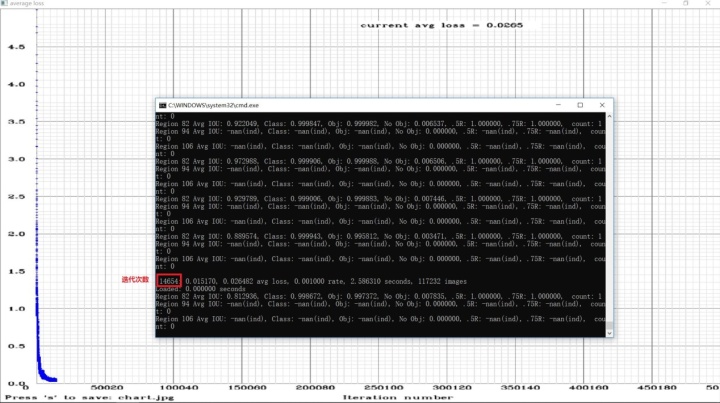
图4.11 训练截图(3)
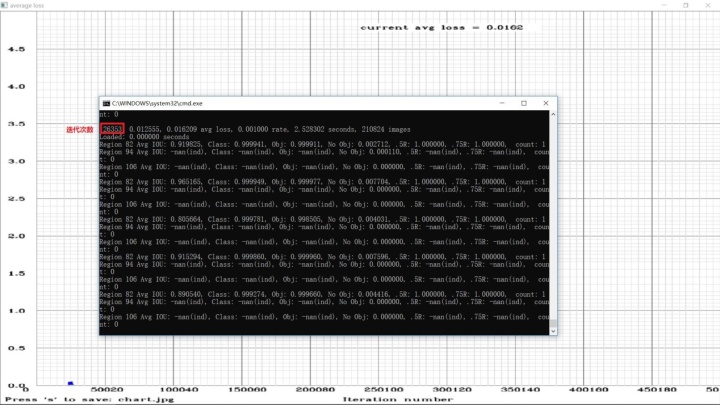
图4.12 训练截图(4)
4. 利用训练模型测试图片和视频
利用自己训练好的模型进行测试比较简单,把待测试文件放到指定路径下,再执行测试命令语句即可。由于可能出现过拟合的情况,所以最好的模型不一定在后边,可以多测试几组,选择一个性能较好的模型。
4.1 测试图片
(1)移植待测试图片
在“darknet-masterbuilddarknetx64”路径下新建一个“test”文件夹。将待测试图片放到该文件夹下。如下图所示,将图像t1.jpg、t2.jpg和t3.jpg放到test文件夹下。
(2)新建测试图片命令文件
新建.cmd格式文件并命名为“yolov3_leaf_test”,右键—>编辑,输入测试命令语句:
darknet.exe detector test data/obj-leaf.data yolov3-leaf.cfg backupyolov3-leaf_24000.weights testt1.jpg。
解释:darknet.exe detector test:表示测试图像;data/obj-leaf.data:表示.data文件路径;yolov3-leaf.cfg:表示.cfg文件路径,backupyolov3-leaf_24000.weights:表示使用的训练好的模型路径,这里我经过多次测试,发现迭代24000次后的模型识别效果最好;testt1.jpg:表示要测试的图像路径。
(3)图片测试结果
测试不同的图像,只需要修改“yolov3_leaf_test.cmd”文件中的图片名即可。测试结果如以下图片所示。
4.2 测试视频
(1)移植待测试视频
在“darknet-masterbuilddarknetx64”路径下新建一个“test”文件夹。将待测试视频放到该文件夹下。如下图所示,将视频test放到test文件夹下。
(2)新建测试图片命令文件
新建.cmd格式文件并命名为“yolov3_leaf_video_test”,右键—>编辑,输入测试命令语句:darknet.exe detector demo data/obj-leaf.data yolov3-leaf.cfg backupyolov3-leaf_24000.weights testtest3.mp4 -i 0 -out_filename res.avi
pause。
解释:darknet.exe detector demo:表示测试视频;data/obj-leaf.data:表示.data文件路径;yolov3-leaf.cfg:表示.cfg文件路径,backupyolov3-leaf_24000.weights:表示使用的训练好的模型路径;testtest3.mp4:表示要测试的视频路径;-i 0 -out_filename res.avi pause:表示保存输出结果在“darknet.exe”同目录下并命名为res.avi。
(3)视频测试结果
测试不同的视频,只需要修改“yolov3_leaf_video_test”文件中的视频名即可。测试结果见test_res.avi文件,视频播放截图如下。
参考资料
[1] AlexeyAB/darknet
https://github.com/AlexeyAB/darknet
[2] AlexeyAB/Yolo_mark
https://github.com/AlexeyAB/Yolo_mark
[2] YOLOv3训练自己的模型
https://blog.csdn.net/StrongerL/article/details/81023603
[3] YOLOv3训练过程中重要参数的理解和输出参数的含义
https://blog.csdn.net/maweifei/article/details/81148414
[4] 图解YOLO
https://zhuanlan.zhihu.com/p/24916786?refer=xiaoleimlnote
版权声明:本文为CSDN博主「陆贽」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_33130645/article/details/112369792






