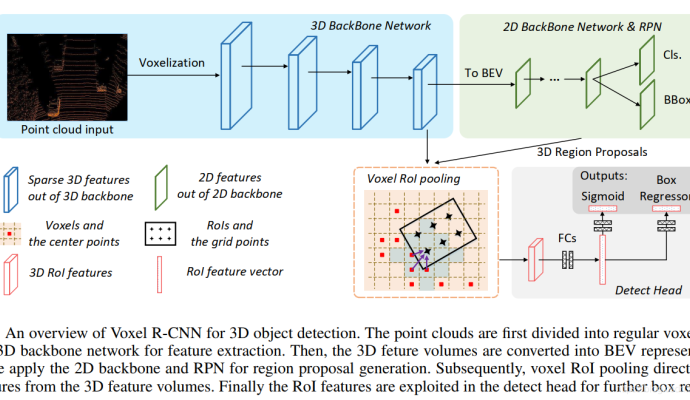
深度学习中制作数据集,并在项目中运行、预测
在这里介绍我们如何自定义数据集,并进行预测,可以关注我的博客,后续将会有更多的干货分享!
训练制作的(自定义)数据集
- 将train.py文件中的数据集设置为自己的yaml文件后。就可以开始训练了。

- 更换后,训练的结果保存在runs里面。

将运行结果(best.pt)进行预测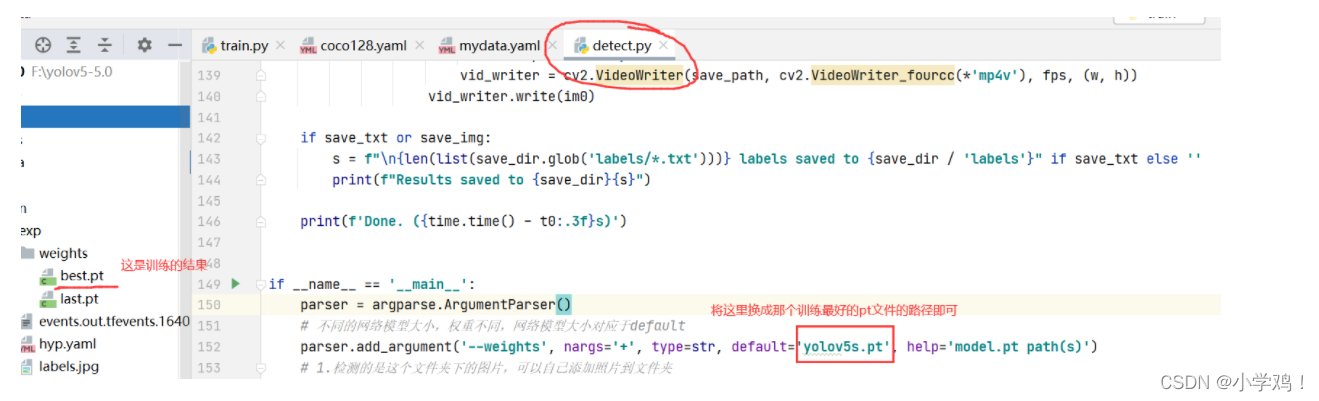
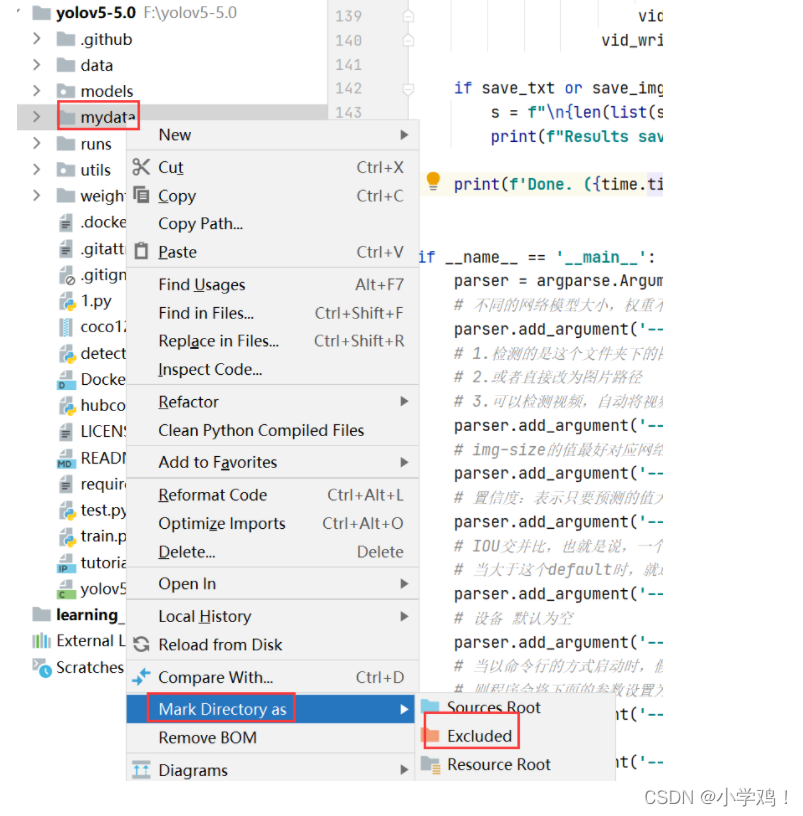
提示:数据集的放置位置 ----> 可以大大提升程序检索数据集的速度
由于数据集在实践中,内容多、数量大,一般不把数据集放到项目目录下(同级目录下,像coco128数据集一样),或者:
版权声明:本文为CSDN博主「小学鸡!」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/zhangfuping123456789/article/details/122194097