文章目录[隐藏]
Multiple Object Tracking with Correlation Learning
在去年年底,这篇文章的方法(Tracking Local Relation,TLR)就已经是MOT Challenge榜单上的新sota了,一致到现在也没有多少的算法超过它。最近,论文开放了,收录于CVPR2021,文章中将方法改名为CorrTracker,是目前已开放论文的方法中精度最高的。
论文PDF:https://arxiv.org/abs/2104.03541
代码:尚未开源
Abstract
卷积神经网络有个天然的特地就是其感受野是局部的,所以说在MOT任务中,普通的卷积操作很难捕获到长程的空间和时间信息。为了得到目标与周围空间信息之间的关系,作者设计了局部相关模块(the local correlation module)来对目标与周围环境之间的拓扑结构信息加以利用,能够使得模型在应对复杂场景时更具有辨别能力。关于时序信息,已有的方法大多采用双帧输入或者多针输入来弥补时序信息不足的问题,然而简单的输入多帧特征,很难通过卷积对动态场景的运动信息进行有效地捕获。所以作者将局部相关模块应用到了时序信息的提取上,在不同帧的卷积后的特征图上进行帧与帧(frame-to-frame)的匹配,以此来捕获时序信息。
Introduction
一开始作者依旧是介绍了tracking-by-detection(TBD)范式和joint-detection-and-tracking(JDT)范式(这里也不说了)。但如下图所示,如果存在相似的干扰选项,仅采用外貌embedding进行目标与轨迹之间的匹配是不够的。通过外貌特征得到的匹配置信度不够精确,导致跟踪关联部分的性能下降。这些方法之所以无法很好地区分相似的目标,是因为其受限于局部的感受野。下图(b)便是这篇文章提出的方法生成的热度图,很轻易地能够看出,CorrTracker可以很好地区分不同的目标。
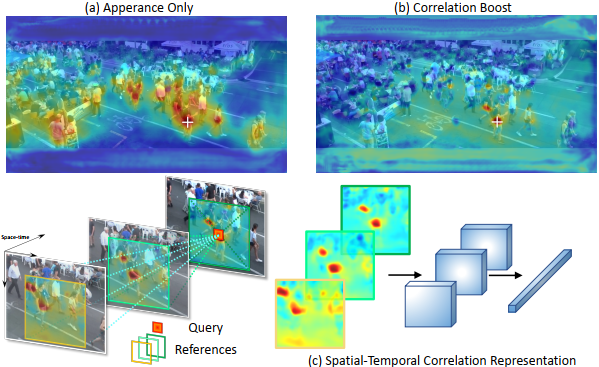
基于上述问题,作者设计了一个相关性网络来学习目标与周围环境之间的信息。具体来讲,作者设计了一个空间相关性层来捕获目标与周围空间位置之间的信息。如果像Non-local网络那样,对全局进行相关性建模,那计算代价对于实时性要求较高的MOT任务来说,太过昂贵,所以作者是提出了correlation volume来限制在每一个特征金字塔级别中的搜索范围。这里的correlation volume,作者说是光流法中的一个名词。(我的理解是,这里的correlation volume是一个三维张量,
(
x
,
y
,
d
)
(x,y,d)
(x,y,d)便存储着特征图中
(
x
,
y
)
(x,y)
(x,y)位置与
(
x
,
y
)
+
d
(x,y)+d
(x,y)+d位置之间的相关性信息。)除此之外,这种相关性学习关注的不仅只是目标之间的信息,背景信息也会被捕获来加强模型对目标的识别和判别能力。作者采用了自监督的方式来对correlation volume进行训练。
另一个问题是MOT中的检测器大多是单帧输入,所以无法很好地利用时序信息。使得算法在密集人群场景下的误检较多,加大了数据关联时的难度,降低了整体性能。最近,一些方法采用了两帧输入或者三帧输入的方式来对时序信息进利用。但由于只是输入的帧数较少,提取的时序信息也不太够。CenterTrack采用了一系列的数据增强方法,但由于卷及操作本身是局部感知的,所以作者认为提取的时序信息依旧不够。所以将提出的空间相关性模块拓展到时间维度,提取历史帧中的时序信息,来提高检测模块的准确度。
总结一下:(1)提出了CorrTracker,一个利用相关性的跟踪器,对目标极其周围环境之间的关系进行建模;(2)采用自监督学习的方法来训练局部相关性模块,使得模型对相似物体的判别能力更强;(3)拓展空间局部相关性模块到时间维度,提取时序信息;(4)CorrTracker达到了sota,在MOT17测试集上达到了76.5%的MOTA和73.6%的IDF1。
Methodology
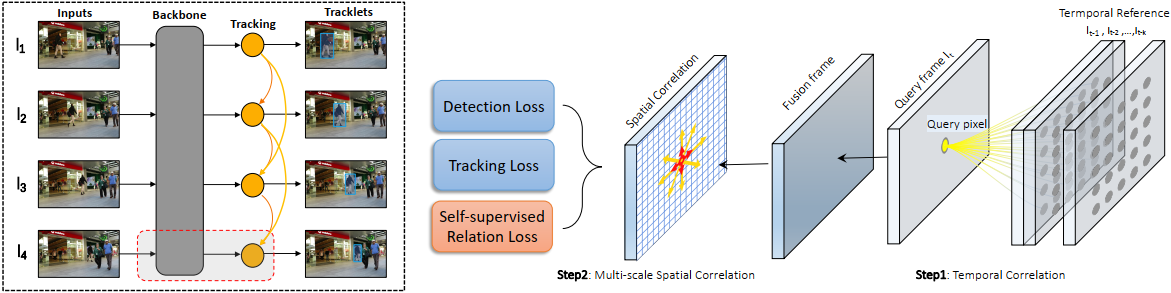
上图是CorrTracker的整体结构,主要分为三个步骤:(1)特征提取;(2)从时空信息中学习相关性并进行检测;(3)数据关联,进行跟踪。步骤(1)和步骤(2)是可以端到端进行训练的。主要的贡献在于对密集位置极其周围位置之间的信息的建模,帮助跟踪器在复杂的场景中抑制干扰。
1. Motivation
给定输入的图像为
I
t
∈
R
H
×
W
×
3
\mathbf{I}_{t} \in \mathbb{R}^{H \times W \times 3}
It∈RH×W×3,通过检测器检测出当前帧所有的候选检测框
D
t
=
{
d
t
i
}
i
=
1
N
\mathcal{D}_{t}=\left\{\mathbf{d}_{t}^{i}\right\}_{i=1}^{N}
Dt={dti}i=1N,
d
t
i
=
(
x
t
i
,
y
t
i
,
w
t
i
,
h
t
i
)
\mathbf{d}_{t}^{i}=\left(x_{t}^{i},y_{t}^{i}, w_{t}^{i}, h_{t}^{i}\right)
dti=(xti,yti,wti,hti),与已经存在的轨迹
T
t
−
1
=
{
T
t
−
1
j
}
j
=
1
M
\mathcal{T}_{t-1}=\left\{\mathbf{T}_{t-1}^{j}\right\}_{j=1}^{M}
Tt−1={Tt−1j}j=1M,
T
t
−
1
j
=
{
d
1
j
,
…
,
d
t
−
2
j
,
d
t
−
1
j
}
\mathbf{T}_{t-1}^{j}=\left\{\mathbf{d}_{1}^{j}, \ldots, \mathbf{d}_{t-2}^{j}, \mathbf{d}_{t-1}^{j}\right\}
Tt−1j={d1j,…,dt−2j,dt−1j}计算相似度矩阵
A
∈
R
N
×
M
\mathbf{A} \in \mathbb{R}^{N \times M}
A∈RN×M:
A
i
j
=
dist
(
f
(
d
t
i
)
,
f
^
(
T
t
−
1
j
)
)
+
α
IoU
(
d
t
i
,
d
^
t
j
)
\mathbf{A}_{i j}=\operatorname{dist}\left(\mathbf{f}\left(\mathbf{d}_{t}^{i}\right), \hat{\mathbf{f}}\left(\mathbf{T}_{t-1}^{j}\right)\right)+\alpha \operatorname{IoU}\left(\mathbf{d}_{t}^{i}, \hat{\mathbf{d}}_{t}^{j}\right)
Aij=dist(f(dti),f^(Tt−1j))+αIoU(dti,d^tj)其中,
f
(
⋅
)
∈
R
d
\mathbf{f}(\cdot) \in \mathbb{R}^{d}
f(⋅)∈Rd为外貌embedding,
f
^
(
T
t
−
1
j
)
\hat{\mathbf{f}}\left(\mathbf{T}_{t-1}^{j}\right)
f^(Tt−1j)为历史轨迹的embedding,通常随着帧数,进行常数加权的更新。然而,完全依赖于目标的相似度比较并不能够完全消除图像中多个相似区域的歧义。相似目标的出现可能会影响到数据关联模块的性能。由于在MOT中,相似目标同时出现是很普遍的,所以完全依赖目标进行相似度计算,进行匹配,是不够准确的,这就是关键问题所在。
像上述这种计算相似度的方式,可以称作patch based,根据检测的结果,对图像进行裁剪,那么裁剪的图像块之间的信息便被直接丢弃了。相邻的空间关系也只剩下了bbox的坐标。所以上述这种只使用目标外貌的匹配方法,容易引起较多的ID转换,使得跟踪鲁棒性降低。为了避免上述问题,作者提取了目标周围的局部信息,来区分干扰项。
2. Spatial Local Correlation Layers
作者设计了空间局部相关性层来建模目标和气周围环境之间的关系。在此相关性模块中,只计算目标与其坐标的“邻居”之间的特征相似度。假定
l
l
l为特征金字塔中的级别,那么
F
q
l
∈
R
H
l
×
W
l
×
d
l
\mathbf{F}_{q}^{l} \in \mathbb{R}^{H_{l} \times W_{l} \times d_{l}}
Fql∈RHl×Wl×dl和
F
r
l
∈
R
H
l
×
W
l
×
d
l
\mathbf{F}_{r}^{l} \in \mathbb{R}^{H_{l} \times W_{l} \times d_{l}}
Frl∈RHl×Wl×dl之间的correlation volume,
C
l
\mathbf{C}^{l}
Cl,计算如下:
C
l
(
F
q
,
F
r
,
x
,
d
)
=
F
q
l
(
x
)
T
F
r
l
(
x
+
d
)
,
∥
d
∥
∞
≤
R
\mathbf{C}^{l}\left(\mathbf{F}_{q}, \mathbf{F}_{r}, \mathbf{x}, \mathbf{d}\right)=\mathbf{F}_{q}^{l}(\mathbf{x})^{T} \mathbf{F}_{r}^{l}(\mathbf{x}+\mathbf{d}),\|\mathbf{d}\|_{\infty} \leq R
Cl(Fq,Fr,x,d)=Fql(x)TFrl(x+d),∥d∥∞≤R其中,
x
∈
Z
2
\mathbf{x} \in \mathbb{Z}^{2}
x∈Z2为query特征图的坐标,
d
∈
Z
2
\mathbf{d} \in \mathbb{Z}^{2}
d∈Z2是相对于当前坐标的位移,位移的约束为
∥
d
∥
∞
≤
R
\|\mathbf{d}\|_{\infty} \leq R
∥d∥∞≤R。作者用一维来表示两维的位移,所以最后的
C
l
\mathbf{C}^{l}
Cl为一个三维(
H
l
×
W
l
×
(
2
R
+
1
)
2
H^{l} \times W^l \times \left( 2R+1 \right)^2
Hl×Wl×(2R+1)2)的张量。作者也采用了膨胀卷积来扩大感受野。将
C
l
\mathbf{C}^{l}
Cl送入一个多层感知机,最后再与原特征图进行像素级别的相加,得到最终的特征:
F
C
l
=
F
t
l
+
M
L
P
l
(
C
l
(
F
t
l
,
F
t
l
)
)
\mathbf{F}_{\mathbf{C}}^{l}=\mathbf{F}_{t}^{l}+\mathbf{M L P}^{l}\left(\mathbf{C}^{l}\left(\mathbf{F}_{t}^{l}, \mathbf{F}_{t}^{l}\right)\right)
FCl=Ftl+MLPl(Cl(Ftl,Ftl))如果对特征图
F
t
l
∈
R
H
l
×
W
l
×
d
l
\mathbf{F}_{t}^{l} \in \mathbb{R}^{H^{l} \times W^{l} \times d^{l}}
Ftl∈RHl×Wl×dl采用non-local模块的话,最终生成的correlation volume为
N
L
(
F
t
l
)
∈
R
H
l
×
W
l
×
H
l
×
W
l
N L\left(\mathbf{F}_{t}^{l}\right) \in \mathbb{R}^{H^{l} \times W^{l} \times H^{l} \times W^{l}}
NL(Ftl)∈RHl×Wl×Hl×Wl,这对与计算代价和内存消耗均太高。相比较而已,作者提出的局部相关性模块,在效率和效果上均好于non-local模块。
3. Correlation at Multiple Pyramid Levels
为了尽可能的获得长程的空间相关性,作者在特征金字塔上做局部相关性操作,如下图: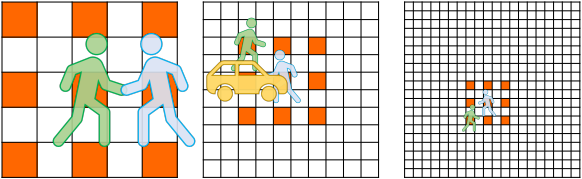
如果加大
R
R
R,那么计算和内存消耗便会急剧增长,所以作者在各个级别的金字塔特征上进行同样膨胀率的膨胀卷积,最后再将几层特征进行融合,这样感受也便能覆盖到
[
0
,
R
×
D
×
2
l
]
\left[0, R \times D \times 2^{l}\right]
[0,R×D×2l],
D
D
D为膨胀卷积的膨胀率。最后再将其融合:
F
^
C
l
−
1
=
C
o
n
v
(
U
p
s
a
m
p
l
e
(
F
C
l
)
)
+
F
C
l
−
1
\hat{\mathbf{F}}_{\mathbf{C}}^{l-1}=\mathbf{C o n v}\left(\mathbf{U p s a m p l e}\left(\mathbf{F}_{\mathbf{C}}^{l}\right)\right)+\mathbf{F}_{\mathbf{C}}^{l-1}
F^Cl−1=Conv(Upsample(FCl))+FCl−1这样以来,便能在保持紧凑和效率的前提下,得到当前位置与其周围尽可能大的范围内的特征之间的相关性。这种相关性利用了视频中自然的时空连贯性。MOT可以看成多个独立的SOT。作者这种方式相当于在特征金字塔上进行一个密集的孪生网络跟踪。另一方面,从匹配的角度来看,全局信息也是需要考虑的。作者的多尺度相关性考虑了信息传递的两个方面。
4. Temporal Correlation Learning
时序信息在MOT中通常容易被忽略,大多数方法通过数据关联来尽可能的解决遮挡之类的问题。但是单帧输入的检测器是很难有时序上的一致性的,使得跟踪器在遇到遮挡、模糊场景以及目标较小等情况时,性能下降。所以作者将2中的空间局部相关性模块拓展到了时间维度上,为不同帧的目标之间的相关性进行建模。两帧之间的相关性学习,可以看做运动信息学习的另一种形式。
具体来说,在不同的帧之间进行多尺度相关性学习,将之前帧保存下来同于加强当前帧的信息,可以帮助跟踪器克服目标遮挡和运动模糊等问题,并且增强了检测和识别特征的一致性。
F
^
q
(
x
)
=
∑
∀
∥
d
∥
∞
<
R
C
l
(
F
q
,
F
r
,
x
,
d
)
(
2
R
+
1
)
2
F
r
(
x
+
d
)
\hat{\mathbf{F}}_{q}(\mathbf{x})=\sum_{\forall\|\mathbf{d}\|_{\infty}<R} \frac{\mathbf{C}^{l}\left(\mathbf{F}_{q}, \mathbf{F}_{r}, \mathbf{x}, \mathbf{d}\right)}{(2 R+1)^{2}} \mathbf{F}_{r}(\mathbf{x}+\mathbf{d})
F^q(x)=∀∥d∥∞<R∑(2R+1)2Cl(Fq,Fr,x,d)Fr(x+d)
C
l
(
F
q
,
F
r
,
x
,
d
)
=
F
q
l
(
x
)
T
F
r
l
(
x
+
d
)
,
∥
d
∥
∞
≤
R
\mathbf{C}^{l}\left(\mathbf{F}_{q}, \mathbf{F}_{r}, \mathbf{x}, \mathbf{d}\right)=\mathbf{F}_{q}^{l}(\mathbf{x})^{T} \mathbf{F}_{r}^{l}(\mathbf{x}+\mathbf{d}),\|\mathbf{d}\|_{\infty} \leq R
Cl(Fq,Fr,x,d)=Fql(x)TFrl(x+d),∥d∥∞≤R和多头注意力类似,计算的是embedding之间的点积相似度。标准化因子设置为
(
2
R
+
1
)
2
(2 R+1)^{2}
(2R+1)2并且局部进行特征融合。在实验中,为了最小的内存和计算消耗,作者选择只保存上一帧,若是为了最高的准确度,作者选择保留了前五帧的图像。
5. Self-supervised Feature Learning
2和4中的空间局部相关性模块和时间相关性模块,和non-local一样,都是可以即插即用的。作者在这一节研究了一种多任务学习的方法,利用视频跟踪中分割级别的标注进行监督训练,以及基于correlation volume的自监督训练。
相关性模块具有可解释性,它评估了不同目标之间的相似度。实际上,作者认为这种方法相当于进行了
M
×
N
M \times N
M×N次孪生跟踪操作来提高模型的判别力。以这种角度来看,可以进行跟踪方面的监督训练,gt标签为:
C
~
l
(
F
q
,
F
r
,
x
,
d
)
=
{
1
if
y
q
(
x
)
=
y
r
(
x
+
d
)
0
if
y
q
(
x
)
!
=
y
r
(
x
+
d
)
−
1
if
y
q
(
x
)
<
0
\tilde{C}^{l}\left(\mathbf{F}_{q}, \mathbf{F}_{r}, \mathbf{x}, \mathbf{d}\right)=\left\{\begin{array}{c} 1 \text { if } \mathbf{y}_{q}(\mathbf{x})=\mathbf{y}_{r}(\mathbf{x}+\mathbf{d}) \\ 0 \text { if } \mathbf{y}_{q}(\mathbf{x}) !=\mathbf{y}_{r}(\mathbf{x}+\mathbf{d}) \\ -1 \text { if } \mathbf{y}_{q}(\mathbf{x})<0 \end{array}\right.
C~l(Fq,Fr,x,d)=⎩⎨⎧1 if yq(x)=yr(x+d)0 if yq(x)!=yr(x+d)−1 if yq(x)<0
y
y
y为对应位置的ID,背景的ID则小于0,并且使用类平衡交叉熵损失进行训练。
至于自监督训练的部分,作者采用了论文Tracking Emerges by Colorizing Videos中的着色任务来进行跟踪的方法。
I
^
q
(
x
)
=
∑
∀
∥
d
∥
∞
<
R
C
l
(
F
q
,
F
r
,
x
,
d
)
(
2
R
+
1
)
2
I
r
(
x
+
d
)
\hat{\mathbf{I}}_{q}(\mathbf{x})=\sum_{\forall\|\mathbf{d}\|_{\infty}<R} \frac{\mathbf{C}^{l}\left(\mathbf{F}_{q}, \mathbf{F}_{r}, \mathbf{x}, \mathbf{d}\right)}{(2 R+1)^{2}} \mathbf{I}_{r}(\mathbf{x}+\mathbf{d})
I^q(x)=∀∥d∥∞<R∑(2R+1)2Cl(Fq,Fr,x,d)Ir(x+d)将颜色空间量化为离散类别,相同颜色即为相同类别,使用交叉熵进行训练。
6. Tracking Framework
作者选用FairMOT的结构进行修改,在IDA模块前加入了相关性模块。模型保留了原来的检测和ReID分支,添加了相关性损失。对于跟踪推理,CorrTracker首先计算当前帧的检测目标和历史轨迹之间的相似度,再通过匈牙利算法找到最优匹配。未匹配到的检测结果初始化为新轨迹。为了减少假正例,这些新轨迹暂时设定“inactive”,若几帧之后,这些新轨迹匹配上了,则将其修改为“active”。未匹配上的轨迹,设为“loss”,当“loss”状态持续的帧数多于阈值时,则将其终结。和FairMOT中一样,CorrTracker也采用卡尔玛滤波对行人运动进行建模。
实验
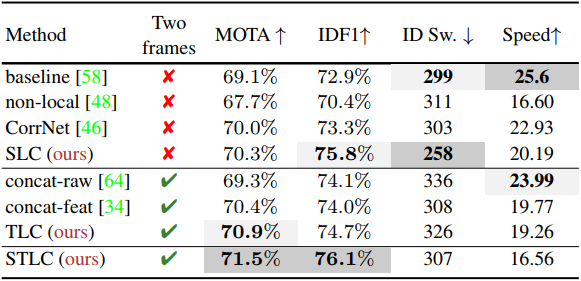
上表是在MOT17验证集上做的实验,可以看出空间相关性模块和时间相关性模块的有效性。
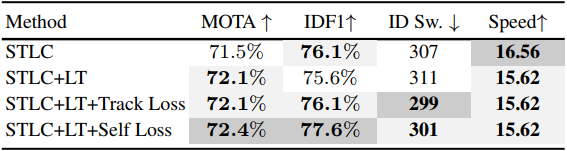
上表中的实验证明了作者添加的自监督损失对跟踪器整体性能是有提升效果的。
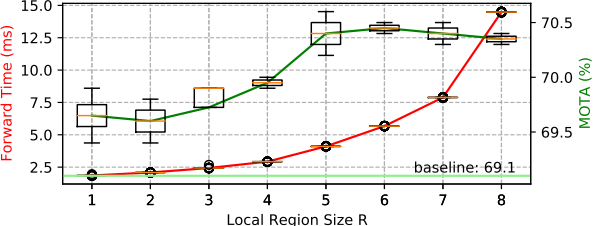
对于不同的
R
R
R对跟踪器效果的影响的实验。
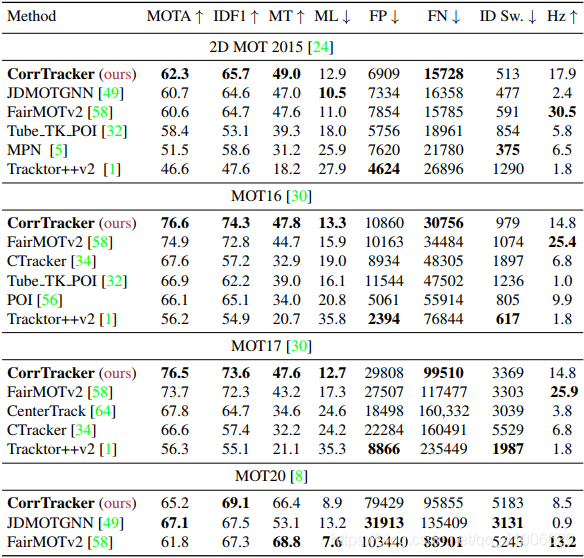
上表是CorrTracker在四个数据集上与sota之间的对比实验,可以看出,在MOT15、MOT16和MOT17上,均是最高的,可见其效果之好。此外,CorrTracker的速度也仅仅只低于FairMOT。
总结
总的俩说,这篇文章主要做了三点:(1)丰富了用于计算相似度的特征,认为仅仅是目标的特征并不足够,于是作者将目标周围的特征与目标之间的关系进行建模,融如到了最终的特征中;(2)时序信息的提取一直也是MOT中一个很受关注的问题,前几天的几篇基于transformer的文章基本都有针对与这个问题,本篇文章将相关性的计算扩展到时间维度,更有效地提取了时序信息,使模型在面对遮挡等问题时鲁棒性更好;(3)额外采用了自监督的损失来训练模型,也能使模型的效果提升一点。
版权声明:本文为CSDN博主「maplezys」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_41006629/article/details/115620660






