文章目录[隐藏]
之前在有位博主的DeblurGANv2教程的页面下留了言,很多小伙伴来私信我:
- config.yaml怎么调参数?
- predict.py和train.py需要怎么修改?
之前只跑了predict,有些问题也没办法解答。最近自己跑了一下train,大概的效果也有一点,写在这里和大家分享一下,不足之处也请大佬们指正!
【注释】:
本文不涉及具体的batch epoch lr 等参数如何调整,只介绍如何跑通predict和train
先放上论文和github:
DeblurGANv2的【predict】
总体介绍:
按照github教程里的操作,先下载作者的预训练模型fpn_inception.h5,fpn_mobilenet.h5,放在DeblurGANv2-master的根目录下;
进行去模糊测试只需要把模糊图片放在DeblurGANv2-master的根目录下,用下面的代码就可以输出去模糊的图片:
python predict.py image_example.jpg
运行如果出现有什么包没有安装,直接 pip install+ 包名 安装就可以。
运行结果默认存放在submit文件夹下。
使用fpn_inception作为主干网络
直接从github上下载的文件夹里默认就是fpn_inception,对应在“config.yaml”文件中的这一块:g_name: fpn_inception

在predict.py文件下,可以选择使用不同的训练结果,当然也可以使用作者提供的fpn_inception.h5,自己注释一下就好(best_fpn.h5是自己训练的结果,在下一部分再说)

其他就不需要修改什么了,直接运行吧,附上个人的运行效果:
模糊原图:

处理结果:

使用fpn_mobilenet作为主干网络
修改“config.yaml”文件中的模型名称为
g_name: fpn_mobilenet
修改 predict.py 中的训练文件
def main(img_pattern: str,
mask_pattern: Optional[str] = None,
#weights_path='best_fpn.h5',
#weights_path ='fpn_inception.h5',
weights_path ='fpn_mobilenet.h5',
DeblurGANv2的【train】
训练的过程主要涉及以下几个文件:
- config.yaml
- train.py
- 成对的“模糊——清晰”数据集
- 预训练模型(.h5文件)[根据是否需要加载预训练结果决定是否使用]
- models文件夹里的模型文件,eg:fpn_inception.py fpn_mobilenet.py
训练我只试了fpn_mobilenet主干网络,因为它的参数数量比fpn_inception少很多,训练时间也会短很多,测试起来比较便捷。
config.yaml
原始的config.yaml如下所示:
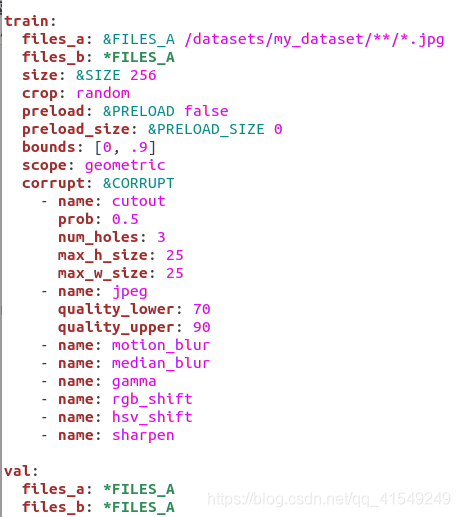
首先,需要准备好自己的数据集,成对的清晰——模糊图像命名相同,分别放入对应的模糊文件夹和清晰文件夹,文件夹结构如下:
DeblurGANv2-master
|________yourdataset
|___________blur【blur 文件夹里面放模糊图片】
|___________sharp【里面放清晰图片】
对应config文件改成:
train:
file_a: &FILES_A ./yourdataset/blur/*.jpg
file_b: &FILES_B ./yourdataset/sharp/*.jpg
......
val:
files_a: &FILES_A
files_b: &FILES_B
......
model:
g_name: fpn_mobilenet【根据你自己的需要选择主干网络】
train.py
根据是否需要预训练模型,确定是否注释下面这句代码,其他的代码都不需要调整
def _init_params(self):
self.criterionG, criterionD = get_loss(self.config['model'])
self.netG, netD = get_nets(self.config['model'])
#加载预训练模型(注释本句即从头开始训练)
self.netG.load_state_dict(torch.load("fpn_mobilenet.h5", map_location='cpu')['model'])
fpn_mobilenet.py
我测试train.py的时候报错说找不到mobilenet_v2.pth.tar,这个问题我也不知道怎么解决,猜测是mobilenet_v2的预训练模型。
按照这个博主的方法:
mobilenet_v2.pth.tar模型的url:http://sceneparsing.csail.mit.edu/model/pretrained_resnet/mobilenet_v2.pth.tar
这个网址进不去,如果有大神知道,求解惑。
我根据报错位置,找到了fpn_mobilenet.py的这一段:
class FPN(nn.Module):
def __init__(self, norm_layer, num_filters=128, pretrained=True):
"""Creates an `FPN` instance for feature extraction.
Args:
num_filters: the number of filters in each output pyramid level
pretrained: use ImageNet pre-trained backbone feature extractor
"""
super().__init__()
net = MobileNetV2(n_class=1000)
#注释掉下面这段代码
if pretrained:
#Load weights into the project directory
state_dict = torch.load('mobilenetv2.pth.tar') # add map_location='cpu' if no gpu
net.load_state_dict(state_dict)
解决报错问题,注释掉if pretrained这段代码,不加载mobilenet v2的预训练不就行了吗?
我一试,还真行了…
训练过程
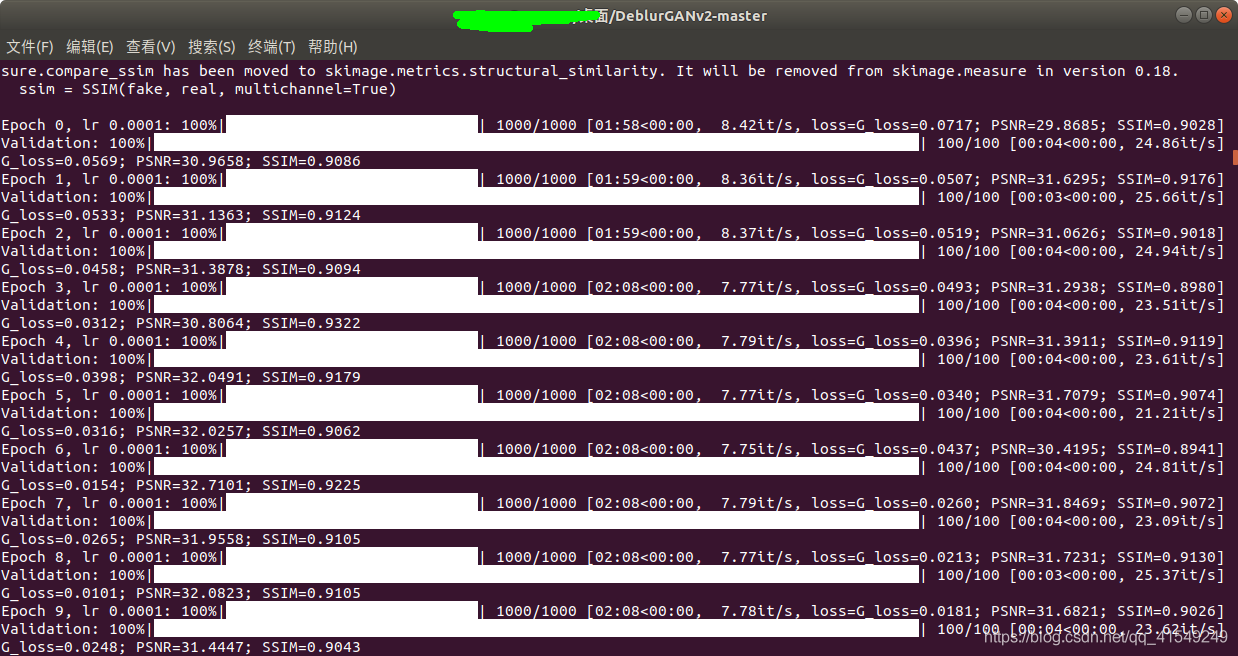
不断交替更新显示训练和验证的两个进度条,以及生成损失loss,峰值信噪比PSNR,结构相似度SSIM,在DeblurGANv2-master文件夹中生成两个文件:
- best_fpn.h5
- last_fpn.h5
这就是训练的结果,best_fpn是最好的训练结果,last_fpn是当前最后一次训练的结果,两个文件在训练过程中不断更新。我在RTX3070上训练了12个小时,3000多对图,300个epoch。用训练的best_fpn进行predict,去模糊的效果有一些,但是不如fpn_inception好。
目前介绍的就是这么多,本人也是小白,很多东西也不懂,希望得到大家的批评指正!
版权声明:本文为CSDN博主「qq_41549249」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_41549249/article/details/110232442






