整体来说,Backbone、RPN和Fast RCNN是三个相对独立的模块。Backbone对每张图片产生5 level的特征,并送入RPN。
RPN对送入的特征,首先经过3x3卷积,随后用sibling 1x1卷积产生分类和bbox信息,分类是指该anchor是否包含Object,bbox信息为四维,包括(dx, dy, dw, dh)。初始anchor加上偏移量后用于判断正负或忽略样本,并确定归属的gt instance。然后从中采样256个anchor(正负样本各一半)用于计算损失。最后,通过cls_score排序和NMS筛选出1000个样本,送入Fast RCNN。
Fast RCNN对送入样本重新确定正负样本,并确定归属的gt instance。然后从中采样512个proposals(正负样本比为1:3),送入RoIAlign,根据proposal的w,h确定在哪一层(注意这里不包含P5采样得到的P6层),用对应层的比例缩放proposal,切出ROI。其中包括设置采样点(论文中采样点设4最好,设1效果差不多),双线性插值(根据落在的坐标方格进行插值,双线性就是线性插值两次,第一次先对x坐标插值,第二次对y坐标插值),maxpooling。
用ROI计算classificaiton和bbox regression:和gt计算 softmax cross entropy loss和smooth L1 loss。
需要注意的是,只有在测试时,会在Fast RCNN中使用NMS的选取最后的结果。
如果不选择用cfg初始化模型,则Mask RCNN的初始化代码如下:可以简单的分为三个部分:(1) backbone = FPN(), (2) proposal_generator = RPN(); (3) roi_heads=StandardROIHeads()。
model = GeneralizedRCNN(
backbone=FPN(
ResNet(
BasicStem(3, 64, norm="FrozenBN"),
ResNet.make_default_stages(50, stride_in_1x1=True, norm="FrozenBN"),
out_features=["res2", "res3", "res4", "res5"],
).freeze(2),
["res2", "res3", "res4", "res5"],
256,
top_block=LastLevelMaxPool(),
),
proposal_generator=RPN(
in_features=["p2", "p3", "p4", "p5", "p6"],
head=StandardRPNHead(in_channels=256, num_anchors=3),
anchor_generator=DefaultAnchorGenerator(
sizes=[[32], [64], [128], [256], [512]],
aspect_ratios=[0.5, 1.0, 2.0],
strides=[4, 8, 16, 32, 64],
offset=0.0,
),
anchor_matcher=Matcher([0.3, 0.7], [0, -1, 1], allow_low_quality_matches=True),
box2box_transform=Box2BoxTransform([1.0, 1.0, 1.0, 1.0]),
batch_size_per_image=256,
positive_fraction=0.5,
pre_nms_topk=(2000, 1000),
post_nms_topk=(1000, 1000),
nms_thresh=0.7,
),
roi_heads=StandardROIHeads(
num_classes=80,
batch_size_per_image=512,
positive_fraction=0.25,
proposal_matcher=Matcher([0.5], [0, 1], allow_low_quality_matches=False),
box_in_features=["p2", "p3", "p4", "p5"],
box_pooler=ROIPooler(7, (1.0 / 4, 1.0 / 8, 1.0 / 16, 1.0 / 32), 0, "ROIAlignV2"),
box_head=FastRCNNConvFCHead(
ShapeSpec(channels=256, height=7, width=7), conv_dims=[], fc_dims=[1024, 1024]
),
box_predictor=FastRCNNOutputLayers(
ShapeSpec(channels=1024),
test_score_thresh=0.05,
box2box_transform=Box2BoxTransform((10, 10, 5, 5)),
num_classes=80,
),
mask_in_features=["p2", "p3", "p4", "p5"],
mask_pooler=ROIPooler(14, (1.0 / 4, 1.0 / 8, 1.0 / 16, 1.0 / 32), 0, "ROIAlignV2"),
mask_head=MaskRCNNConvUpsampleHead(
ShapeSpec(channels=256, width=14, height=14),
num_classes=80,
conv_dims=[256, 256, 256, 256, 256],
),
),
pixel_mean=[103.530, 116.280, 123.675],
pixel_std=[1.0, 1.0, 1.0],
input_format="BGR",
)以下涉及的符号表示:
- N: number of images in the minibatch
- L: number of feature maps per image on which RPN is run
- A: number of cell anchors (must be the same for all feature maps),指feature map上的每个点产生3种aspect_ratios的anchors
- Hi, Wi: height and width of the i-th feature map
- B: size of the box parameterization,指bbox的参数量4
1. Backbone
backbone使用ResNet-FPN,产生["p2", "p3", "p4", "p5", "p6"],共5层特征,每层特征的维度为:[N, C, Hi, Wi]。输出为一个dict,dict的keys是in_features的五个元素。
2. RPN
用于初筛anchors,并产生Fast RCNN中使用的proposals。
proposal_generator=RPN(
in_features=["p2", "p3", "p4", "p5", "p6"],
head=StandardRPNHead(in_channels=256, num_anchors=3),
anchor_generator=DefaultAnchorGenerator(
sizes=[[32], [64], [128], [256], [512]],
aspect_ratios=[0.5, 1.0, 2.0],
strides=[4, 8, 16, 32, 64],
offset=0.0,
),
anchor_matcher=Matcher([0.3, 0.7], [0, -1, 1], allow_low_quality_matches=True),
box2box_transform=Box2BoxTransform([1.0, 1.0, 1.0, 1.0]),
batch_size_per_image=256,
positive_fraction=0.5,
pre_nms_topk=(2000, 1000),
post_nms_topk=(1000, 1000),
nms_thresh=0.7,对应RPN forward()的代码如下:
features = [features[f] for f in self.in_features]
anchors = self.anchor_generator(features)
pred_objectness_logits, pred_anchor_deltas = self.rpn_head(features)
# Transpose the Hi*Wi*A dimension to the middle:
pred_objectness_logits = [
# (N, A, Hi, Wi) -> (N, Hi, Wi, A) -> (N, Hi*Wi*A)
score.permute(0, 2, 3, 1).flatten(1)
for score in pred_objectness_logits
]
pred_anchor_deltas = [
# (N, A*B, Hi, Wi) -> (N, A, B, Hi, Wi) -> (N, Hi, Wi, A, B) -> (N, Hi*Wi*A, B)
x.view(x.shape[0], -1, self.anchor_generator.box_dim, x.shape[-2], x.shape[-1])
.permute(0, 3, 4, 1, 2)
.flatten(1, -2)
.float() # ensure fp32 for decoding precision
for x in pred_anchor_deltas
]
if self.training:
assert gt_instances is not None, "RPN requires gt_instances in training!"
gt_labels, gt_boxes = self.label_and_sample_anchors(anchors, gt_instances)
losses = self.losses(
anchors, pred_objectness_logits, gt_labels, pred_anchor_deltas, gt_boxes
)
else:
losses = {}
proposals = self.predict_proposals(
anchors, pred_objectness_logits, pred_anchor_deltas, images.image_sizes
)可以提炼为以下几个部分:
- features = [features[f] for f in self.in_features]: 从backbone取得的图片特征,共有5 level,每个level的特征为[batch_size, channel, w, h]
- anchors = self.anchor_generator(features) -> DefaultAnchorGenerator():每个level的feature map对应一种anchor sizes,feature map上的每个点对应三种aspect_ratios。该函数旨在生成所有的anchors。
- anchors pred_objectness_logits, pred_anchor_deltas = self.rpn_head(features) -> StandardRPNHead():送入特征,算出是否是目标和(dx, dy, dw, dh)。pred_objectness_logits[in_features] = [N, A, Hi, Wi],pred_objectness_logits[in_features] = [N, A*B, Hi, Wi]
- reshape
- gt_labels, gt_boxes = self.label_and_sample_anchors(anchors, gt_instances):其中包括self.anchor_matcher(),通过预设的ROI_THRESHOLDS=[0.3, 0.7],会将每个anchors分为正负样本,并返回每个anchors对应的gt_instances。
- losses = self.losses() : 随机选取batch_size_per_image=256个anchors,其中positive_fraction=0.5为正样本,0.5为负样本,用作训练
- proposals = predict_proposals(anchors, pred_objectness_logits, pred_anchor_deltas, images.image_sizes)->find_top_rpn_proposals(),该函数用于产生proposals,执行流程包括,根据cls_score选取pre_nms_topk个anchors,根据rpn_bbpx_pred对anchors的location进行微调,获得调整后的bbox,随后根据nms_thresh=0.7执行NMS,然后去除超过边界和过小的anchors,最后根据cls_score选取post_nms_topk个样本
- return proposals, losses
3. roi_heads = StandardROIHeads()。
roi_heads=StandardROIHeads(
num_classes=80,
batch_size_per_image=512,
positive_fraction=0.25,
proposal_matcher=Matcher([0.5], [0, 1], allow_low_quality_matches=False),
box_in_features=["p2", "p3", "p4", "p5"],
box_pooler=ROIPooler(7, (1.0 / 4, 1.0 / 8, 1.0 / 16, 1.0 / 32), 0, "ROIAlignV2"),
box_head=FastRCNNConvFCHead(
ShapeSpec(channels=256, height=7, width=7), conv_dims=[], fc_dims=[1024, 1024]
),
box_predictor=FastRCNNOutputLayers(
ShapeSpec(channels=1024),
test_score_thresh=0.05,
box2box_transform=Box2BoxTransform((10, 10, 5, 5)),
num_classes=80,
),
mask_in_features=["p2", "p3", "p4", "p5"],
mask_pooler=ROIPooler(14, (1.0 / 4, 1.0 / 8, 1.0 / 16, 1.0 / 32), 0, "ROIAlignV2"),
mask_head=MaskRCNNConvUpsampleHead(
ShapeSpec(channels=256, width=14, height=14),
num_classes=80,
conv_dims=[256, 256, 256, 256, 256],
),
),1. proposal_matcher = Matcher(),会根据ROI_HEADS.IOU_THRESHOLDS来筛选正负样本,并重新指定GT bbox,Fast RCNN从每张图片种选择512个proposals用于训练,其中0.25是正样本,其余为负样本。
2. 在训练时,Fast RCNN不会使用NMS,只有在测试时,会先通过score筛选掉部分结果后,再用NMS输出结果。
对于任意大小的图像,缩放至固定大小后送入网络
对VGG16,所有的conv层都是kernel_size=3, pad=1, stride=1;所有的pooling层都是kernel_size=2, pad=0, stride=2。conv层保持矩阵长宽,pooling层使长宽变为输入的1/2。
# N = Floor((width - kernel_size + 2 * pad) / stride) + 1:可以理解为(边长 + 2倍pad - 一个卷积核)/ 步长,减去的卷积核是最后一个,拿出去了,最后再加一。
RPN:3x3卷积接两个1x1的分支卷积,其目的是将256维的特征图转换为2 * k scores用于判断k个anchor的positive和negative(二分类问题);以及 4 * k coordinates代表k个anchor的变换(用于修正anchor的位置,回归问题)。训练:选取128个正/负anchor用于训练。正样本:(1)和GT有最大重叠区域;(2)IOU > 0.7;负样本:IOU < 0.3
回归涉及到的四个参数:先做平移,即对原始中心点x, y做位移,作者认为位移是和宽/高相关的一个参数;再做缩放:Gw = Aw * exp(dw(A))。训练时:输入正样本和GT之间变换:
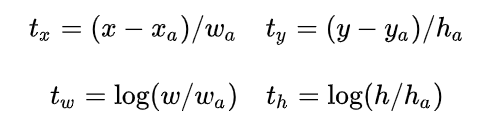
Proposal layer: (1)生成anchors,利用变换对bbox做回归;(2)根据分数从大到小排序anchors,提取前pre_nms_topN个anchors;(3)限定图像边界;(4)剔除尺寸非常小的;(5)做NMS;(6)生成Proposals(对应MxN尺度的)。
# NMS:大致算法流程为:1.对所有预测框的置信度降序排序;2.选出置信度最高的预测框,确认其为正确预测,并计算他与其他预测框的IOU; 3.根据2中计算的IOU去除重叠度高的,IOU>threshold阈值就删除; 4.剩下的预测框返回第1步,直到没有剩下的为止。
(需要注意的是:Non-Maximum Suppression一次处理一个类别,如果有N个类别,Non-Maximum Suppression就需要执行N次。)
# Soft-NMS: soft-nms的核心就是降低置信度。比如一张人脸上有3个重叠的bounding box, 置信度分别为0.9, 0.7, 0.85 。选择得分最高的建议框,经过第一次处理过后,得分变成了0.9, 065, 0.55(此时将得分最高的保存在D中)。这时候再选择第二个bounding box作为得分最高的,处理后置信度分别为0.65, 0.45(这时候3个框也都还在),最后选择第三个,处理后得分不改变。最终经过soft-nms抑制后的三个框的置信度分别为0.9, 0.65, 0.45。最后设置阈值,将得分si小于阈值的去掉。
ROI Pooling:(1)使用spatial_scale参数将proposal映射回feature map尺度;(2)切割
解决正负样本不平衡的问题:在Faster RCNN中是强制正负样本比例为1:1,如果正样本不足,就用负样本补充。后面的工作主要是修改loss weight,例如:OHEM、OHNM、Focal loss
# Focal Loss: 交叉熵是 ylogy‘ + (1-y)log(1-y’)。为了解决正负样本不平衡的问题,通常会在交叉熵损失的前面加上一个参数 α:
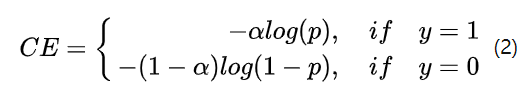
把高置信度(p)样本的损失再降低一些:
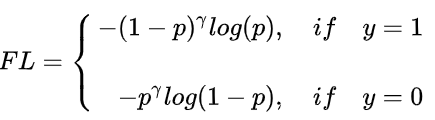
两者融合就是Focal Loss:
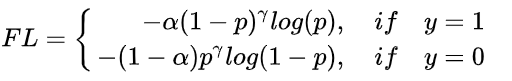
γ=2,α=0.25效果最好。后面对Focal Loss的改进,认为极端困难样本中存在离群点,强行拟合他们是无意义的,进而提出GHM (Gradient Harmonized Single-stage Detector, AAAI-19)。
总共有三个creator
(1)AnchorTargetCreator : 负责在训练RPN的时候,从上万个anchor中选择一些(比如256)进行训练,以使得正负样本比例大概是1:1. 同时给出训练的位置参数目标。 即返回gt_rpn_loc和gt_rpn_label。
(2)ProposalTargetCreator: 负责在训练RoIHead/Fast R-CNN的时候,从RoIs选择一部分(比如128个)用以训练。同时给定训练目标, 返回(sample_RoI, gt_RoI_loc, gt_RoI_label)
(3)ProposalCreator: 在RPN中,从上万个anchor中,选择一定数目(2000或者300),调整大小和位置,生成RoIs,用以Fast R-CNN训练或者测试。
其中AnchorTargetCreator和ProposalTargetCreator是为了生成训练的目标,只在训练阶段用到,ProposalCreator是RPN为Fast R-CNN生成RoIs,在训练和测试阶段都会用到。三个共同点在于他们都不需要考虑反向传播(因此不同框架间可以共享numpy实现)
Faster RCNN训练步骤:
参考:https://www.cnblogs.com/WSX1994/p/11131148.html
第一步:用 Imagenet 初始化共享cov 部分初始化RPN网络,然后训练RPN,在训练后,共享cov以及RPN的特有部分参数会被更新。
第二步:用Imagenet 初始化共享cov 部分初始化Fast-rcnn网络,这里是重新初始化。然后使用训练过的RPN来计算proposal,再将proposal给予Fast-rcnn网络。接着训练Fast-rcnn。训练完以后,共享cov 以及Fast-rcnn的特有部分都会被更新。
说明:第一和第二步,用同样的COV初始化RPN网络和Fast-rcnn网络,然后各自独立地进行训练,所以训练后,各自对cov的更新一定是不一样的(论文中的different ways),因此就意味着model是不共享的(论文中的dont share convolution layers)。
第三步:使用第二步训练完成的 共享cov 来初始化RPN网络,第二次训练RPN网络。但是这次要把 共享cov 锁定,训练过程中,model始终保持不变,而RPN的unique会被改变。
说明:因为这一次的训练过程中, 共享cov始终保持和上一步Fast-rcnn中共享cov一致,所以就称之为着共享。
第四步:仍然保持第三步的 共享cov不变,初始化Fast-rcnn,第二次训练Fast-rcnn网络。其实就是对其特有部分进行finetune,训练完毕,得到一个文中所说的unified network。
IOU代码
有两个框,设第一个框的两个关键点坐标:(x1,y1)(X1,Y1),第二个框的两个关键点坐标:(x2,y2)(X2,Y2)。以大小写来区分左上角坐标和右下角坐标。首先,要知道两个框如果有交集,一定满足下面这个公式:max(x1,x2)<=min(X1,X2) && max(y1,y2)<=min(Y1,Y2)
Batch Normalization:深层神经网络在做非线性变换前的激活输入随着网络变深,其分布逐渐发生偏移和变动(internal covariate shift),之所以训练收敛慢,通常是整体分布逐渐往非线性函数的取值区间的上下限两端靠近,这导致后向传播时,底层神经网络的梯度消失,这是训练深层神经网络收敛越来越慢的本质原因。BN通过一定的规范化手段,把变换后满足均值为0方差为1的x,又进行了scale加上shift操作(y = scale * x + shift)

测试时,均值和方差是在整个数据集上通过移动平均法求得的,也是减均值除方差,然后乘以方差,加均值。Batchnorm可以放心的使用大学习率,可以替代其他正则方法如dropout。BatchNorm降低了数据之间的绝对差异,考虑相关差异。Dropout在训练时,是让某个神经元以概率p停止工作,测试时,每一个神经元的权重参数要乘以p。使用顺序:CONV/FC -> BatchNorm -> ReLu(or other activation) -> Dropout -> CONV/FC。也有一篇论文指出可以BN-Dropout
版权声明:本文为CSDN博主「zzl_1998」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_40731332/article/details/114991010






