文章目录[隐藏]
Learning to Rank Proposals for Object Detection
学习为目标检测排列提议
Zhiyu Tan,Xuecheng Nie, Qi Qian,Nan Li,Hao Li
Alibaba Group,Beijing,China
Department of Electrical and Computer Engineering,National University of Singapore,Singapore
发表于: ICCV,2019
一、 研究动机
现有的目标检测模型严重的依赖非最大抑制 (NMS) 算法,通过抑制标准去除重复的边界框,抑制标准的定义来自于分类得出的客观性或回归产生的定位,这两者都是启发式设计的,NMS的功效严重的影响着最终的检测结果。 然而,这些现有的抑制标准无法与消除这些候选框过程中的候选框的等级明确关联,如下图所示。候选等级不准确将导致错误的消除并降低目标检测器的性能。 仍然需要改进抑制标准以促进目标检测器的性能。

为了解决上述问题,在本文中,我们提出了一种新颖的学习排序(LTR)模型,通过学习过程中产生抑制排序,从而促进候选生成并提高检测性能。 特别地,我们定义了一个基于 IoU 的排名分数来表示 NMS 步骤中候选框的排名,其中排名高的候选框将被保留,排名分数低的将被淘汰。 我们设计了一个轻量级网络来预测排名分数。我们引入了排名损失来监督这些排名分数的生成,这使得与真实框有更相近的 IoU 的候选框的排名更高。 为了促进训练过程,我们还设计了一种新颖的抽样策略,通过将候选框分为不同级别并选择要在训练中使用的候选框的对(这里的候选框对可类比于常规NMS中的具有高IOU的候选框与其他候选框进行比较筛选的过程)。在推理阶段,该模块可以用作当前对象检测器的插件。整个框架的训练和推理是端到端的。
二、 论文创新点
候选等级不准确将导致错误的消除并降低目标检测器的性能。 仍然需要改进抑制标准以促进目标检测器的性能。作者提出在目标检测器的训练和推理阶段增强抑制标准,现有标准要么以启发式方式设计,要么以隐式方式产生。 明确的排名分数定义和生成可以成功地消除抑制标准和候选框保留之间的差距。 受此启发,作者提出了一种 Learning-To-Rank (LTR) 模型来预测学习过程中候选者的排名分数,从而克服现有方法的局限性并改进目标检测。
所以,我们定义了一个基于 IoU 的排名分数来表示 NMS 步骤中候选框的排名,其中排名高的候选框将被保留,排名分数低的将被淘汰。 我们设计了一个轻量级网络来预测排名分数。 我们引入了ranking loss 来监督训练这些排名分数的生成,这使得与真实框具有 相近 IoU 的候选框排名更高。
为了促进训练过程,我们设计了一种新颖的抽样策略,通过将候选者分为不同级别并选择在训练中采用的固定的配对。 在推理阶段,该模块可以用作当前对象检测器的插件。
我们的贡献可以总结为三个方面:
- 我们提出了一种新颖的 Learning-To-Rank 模型,以在目标检测的训练和推理阶段改进 NMS 算法。
- 我们提出了一种新颖的配对采样策略来提高学习速度。
- 我们的 LTR 模型普遍提高了多目标检测器的性能,并在多个基准上设置了新的最先进的精度。
三、 相关工作
现有的基于 CNN 的方法可以分为两类:基于单阶段的检测器和基于双阶段的检测器。单阶段检测器,例如 SSD、Retinanet 和 YOLO,主要关注计算效率,从而实现快速目标检测。 在准确性方面,双阶段检测器占主导地位,并且通常优于单阶段检测器。
在本文中,我们旨在改进双阶段检测器,从而进一步推动目标检测前沿的发展。当前双阶段的目标检测器涉及两个步骤:(1)生成目标提议(2)目标分类和边界框校正。在这种模式中,非极大值抑制 (NMS) 在产生高质量的候选框方面起着关键作用,这显著影响了最终的检测结果。然而,大多数现有作品都忽略了这个重要的后处理步骤。在这里,我们提议改进 NMS,从而提升双阶段检测器的性能。
下面,我们回顾现有的 NMS 算法。
为了去除大量重复的边界框,NMS 被用作主流检测网络中的后处理程序。 NMS 选择具有最大分类置信度的边界框,并使用预定义的 IoU 阈值迭代地消除其附近的框。 NMS 对于基于 CNN 的检测器至关重要,它通过删除重复结果来提高性能。尽管检测器可以在 NMS 之前生成许多具有准确位置的候选边界框,但由于 NMS 期间预测置信度较低,这些边界框可能会被删除。最近,提出了许多有效的技术来改进 NMS。 Soft-NMS是一种无参数算法,其中重复边界框去除被替换为用连续函数衰减边界框分数。现有一种 learning-based 的算法作为无参数 NMS 和 Soft-NMS 的替代方案。 Softer NMS 以更柔和的方式平均选定的框。Learning NMS 使用复杂的神经网络仅通过使用框及其分数来执行 NMS。 Fitness NMS 将边界框的定位信息引入到排名置信度中。关系网络使用子网络通过挖掘 object-object 交互的视觉信息来学习 NMS。
四、 主要内容
LTR模型的总览:
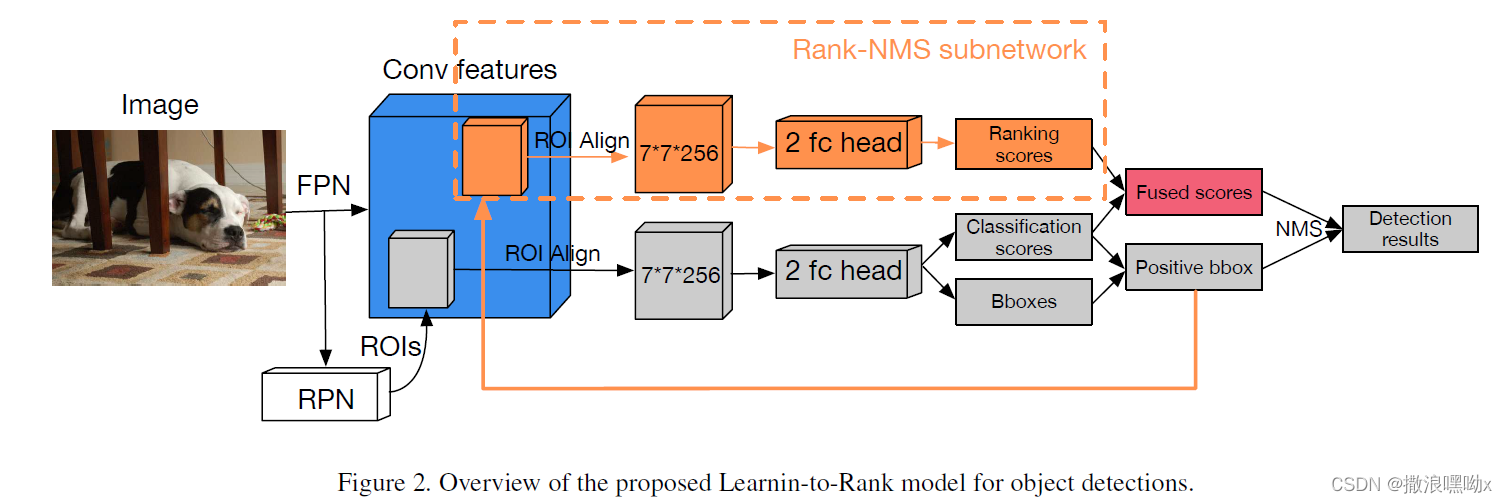
LTR 的核心是 Rank-NMS 子网络,它可以插入到传统的两阶段目标检测器中。Rank-NMS 子网络将来自对象检测器的正 bbox 候选框的 ROI-Aligned 特征作为输入,并根据真实情况的 Intersectionover-Union (IoU) 值预测它们的排名分数。然后,LTR 将排名分数与分类分数融合以产生最终的排名置信度,作为 NMS 算法的抑制标准。通过这种方式,LTR 克服了现有的 NMS 启发式设计标准的局限性,并保留与真实框有更高 IoU 的 bbox 候选框,从而提高目标检测的准确性。为了训练 Rank-NMS 子网络,我们设计了一个排序损失作为监督,并提出了一个样本对选择策略来加速收敛,其细节如下所示。
Ranking Loss
一般来说,bbox与真实框的 IoU 值越高,定位越好。因此,Rank-NMS 子网络,表示为 R(·),旨在为具有较高 IoU 值的 bbox 预测更高的排名分数,反之亦然。 为了实现这一目标,我们将基于 IoU 的排名定义如下:(我认为该式主要是为了表示 IoU 较小的候选框经过Rank-NMS子网络得出的排名分数也较小)
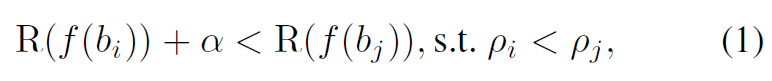
bi和bj表示不同的候选框,ρi和ρj表示他们和真实框之间的IoU. f(·) 表示为 bbox 提取特征的 ROI-Aligned 操作。α 是一个控制排名差距的常数。ranking loss 定义为:
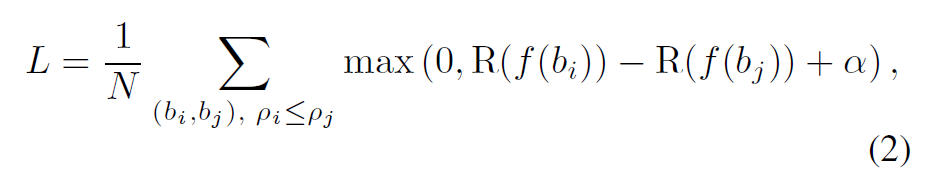
其中 N 是满足第一个式子中定义的排名条件的 bbox 对的总数。我们通过最小化损失来训练 Rank-NMS 子网络。实际上,N 总是非常大,可能的 bbox 对包含许多容易排序的。 为了加速训练,我们提出了一种有效的样本对选择策略。
样本对的选择 Pair Selection
样本对的选择策略对于 Rank-NMS 网络模型至关重要。 为了减少冗余并消除第一个式子中的无信息的 bbox paris。我们提出了一种分裂后采样策略来有效地选择有价值的样本对。 特别地,我们首先根据它们的 q 值将所有bbox分成子集,这些子集由量化函数计算:
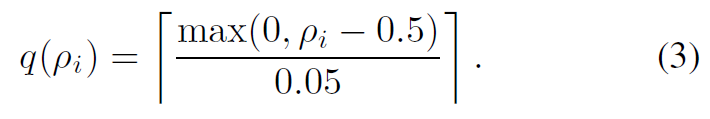
公式(3)基于真实情况的 IoU 值量化 bbox 候选框,并强制使更大的 IoU 值产生更大的量化结果。基于公式(3),我们将生成 11 个子集,其索引范围为0 ~ 10。 然后,我们按照相同的规则分别对每个量化子集的正样本和负样本进行采样——将具有较高的IoU值的候选框定义为正样本,而将较低的IoU值的候选框定义为负样本。对于第 i 个量化子集,它的正样本就是它本身的。而它的负样本是列表中的 top-h 元素,它根据排名分数以降序对量化值小于 i 的量化子集的并集的边界框进行排名。 然后,该量化子集的样本对集由其正负样本之间的卡特尔积导出。 我们重复上述过程为所有量化子集生成样本对集。

Score Fusion
先前的工作总是利用 bbox 候选框的分类分数作为 NMS 算法的抑制标准,它考虑了客观性并很好地过滤了 negative 候选框。 不同的是,排名分数考虑了 bbox 候选框和 groudtruth 之间的重叠,擅长保留准确的 positive 候选框。 为了获得更可靠的抑制标准,我们通过加权和来融合分类和排名分数:
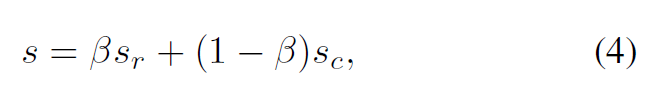
sr 和 sc 分别表示排名和分类分数。β 是平衡因子,通常取0.15。 s 是在训练和推理阶段用作 NMS 算法抑制标准的最终分数。
五、 实验设置
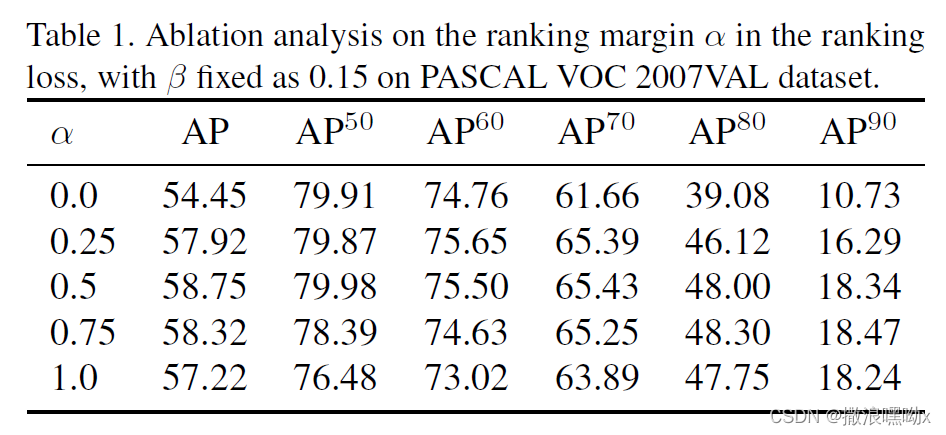
参数 α 在不同数据集中的设置:
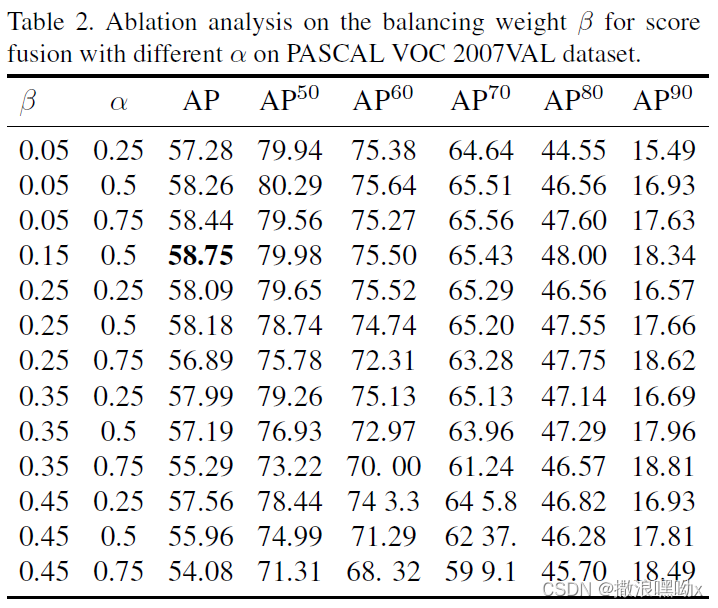
平衡权重 β 与 不同的 α 的选择:
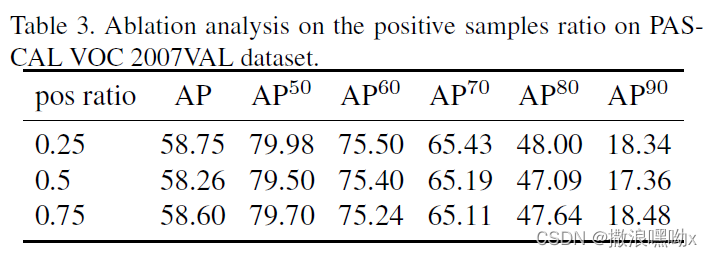
正负样本对的比例选择:
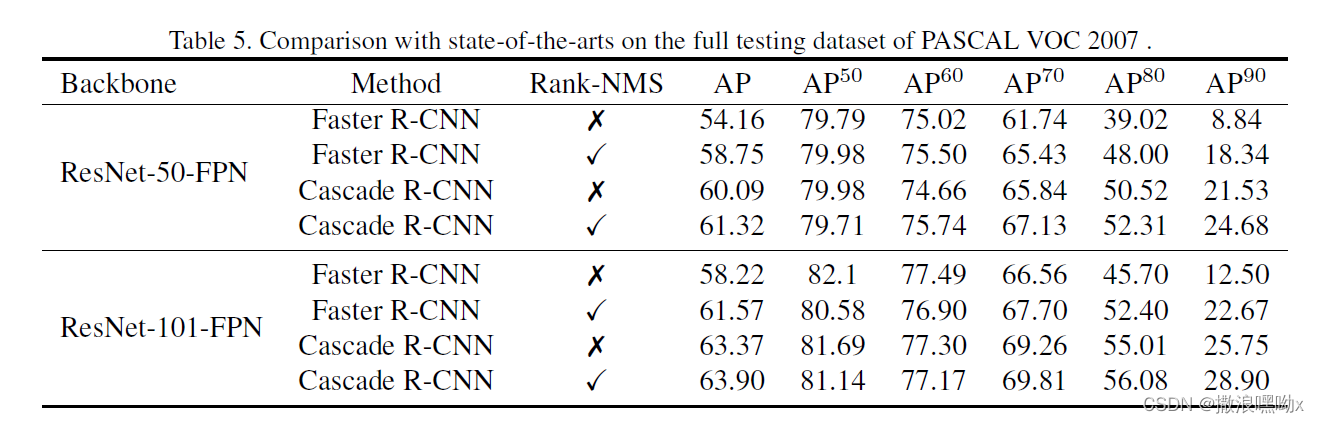
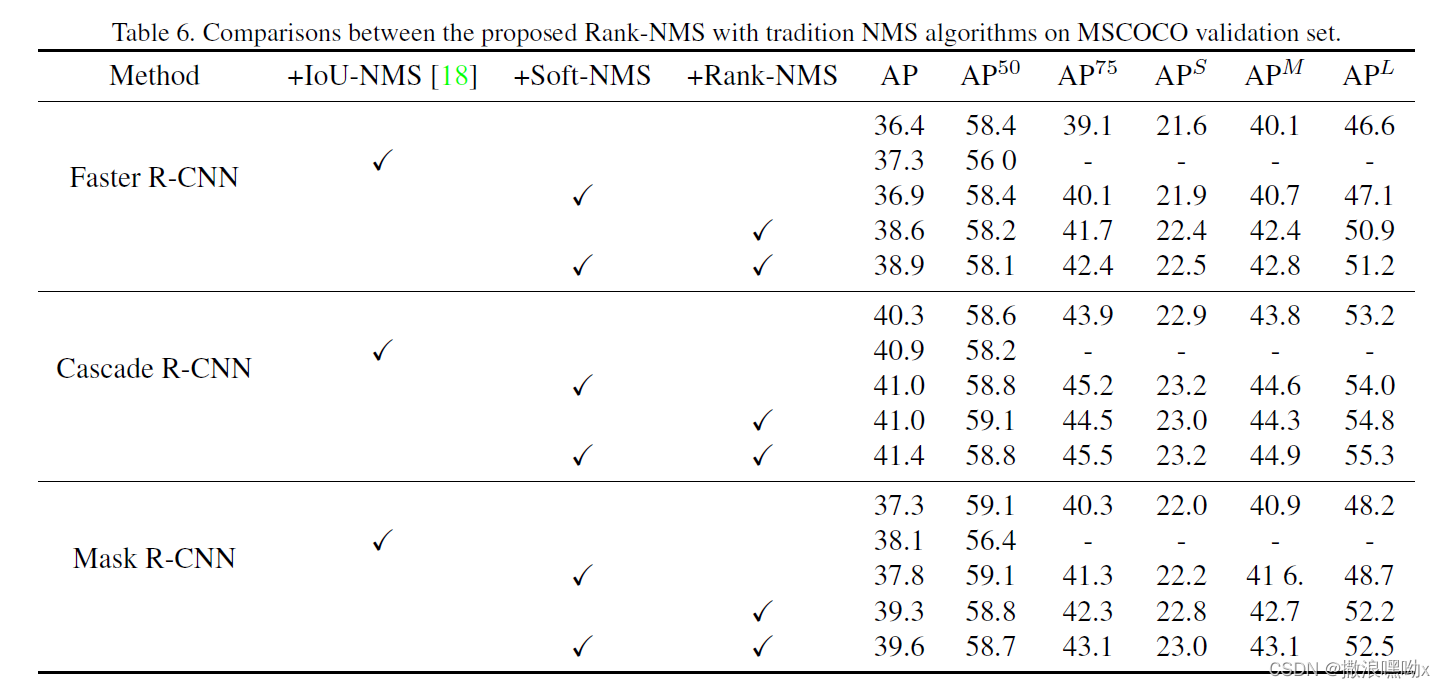
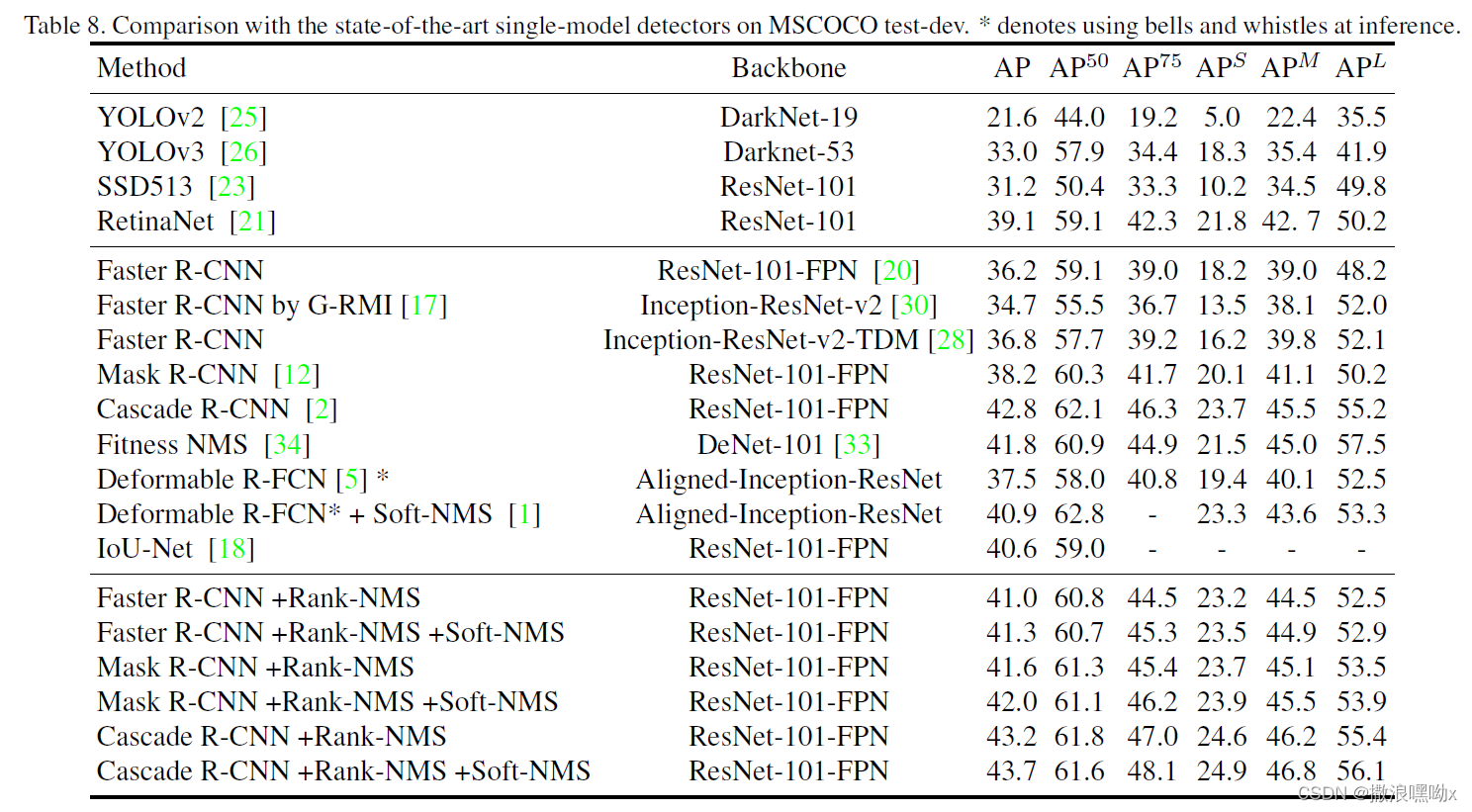
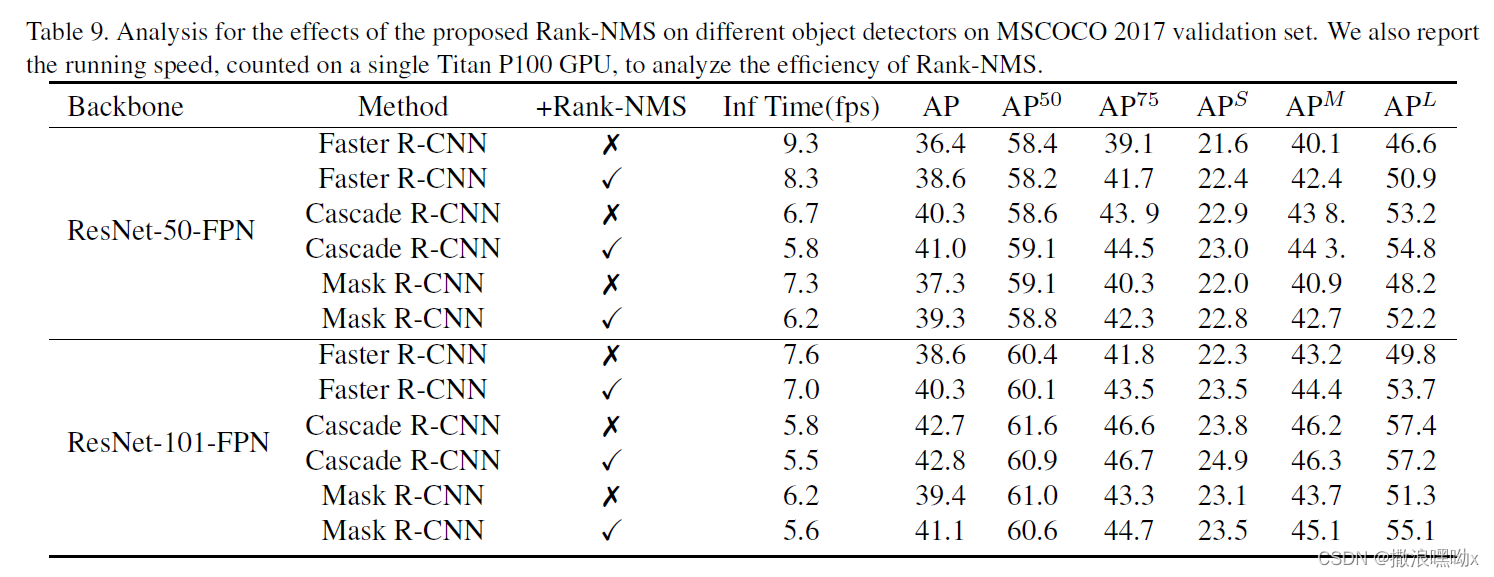
六、 实验结果
版权声明:本文为CSDN博主「撒浪嘿呦x」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_45806470/article/details/122154258





