介绍
这次介绍的是Facebook AI的一篇文章“End-to-End Object Detection with Transformers”
恰好最近Transformer也比较热门,这里就介绍一下如何利用Transformer来进行目标检测以及语义分割。
关于Transformer,可以参考我的这篇文章。
这里我简要地介绍一下Transformer,这是一个用于序列到序列建模的模型架构,被广泛应用于自然语言翻译等领域。Transformer抛弃了以往对序列建模的RNN形式的网络架构,引入了注意力机制,实现了不错的序列建模以及变换能力。
大致架构以及流程
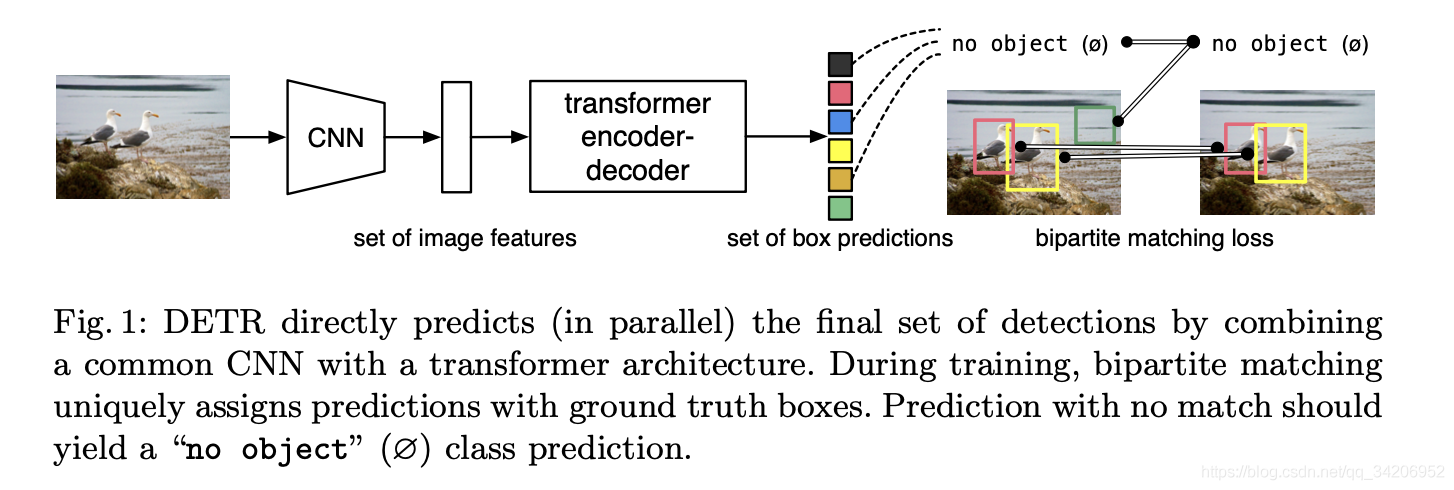
如上图所示,这里面主要分为两个部分:
- Backbone:主要是CNN,用来抽取高级语义特征的
- Encoder-Decoder:将高级语义特征利用并给出目标预测
更为细节地,给出如下的架构
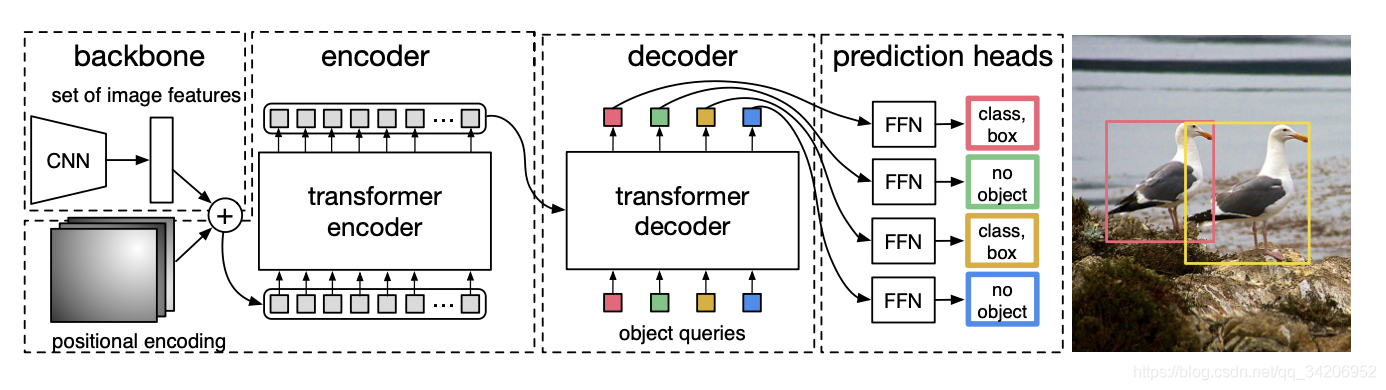
我们按顺序地给出流程:
- 输入图片,形状为
(
C
0
,
H
0
,
W
0
)
(C_0, H_0,W_0)
(C0,H0,W0), 其中C
0
=
3
C_0 = 3
C0=3代表通道数量 - CNN抽取特征之后,得到
(
C
,
H
,
W
)
(C,H,W)
(C,H,W)形状的张量,其中C
=
2048
,
H
=
H
0
32
,
W
=
W
0
32
C=2048, H=\frac{H_0}{32}, W=\frac{W_0}{32}
C=2048,H=32H0,W=32W0 - 利用1x1的卷积,对特征的大小进行约减,得到
(
d
,
H
,
W
)
(d, H, W)
(d,H,W)的张量, 其中d
<
<
C
d<< C
d<<C - 将张量进行压缩(squeeze),形状变为
(
d
,
H
W
)
(d, HW)
(d,HW) - 得到了
d
d
d个向量序列,作为序列输入到Encoder之中 - Decoder得到输出的向量序列,通过FFN(Feed Forward Network)得到边界框预测以及类别预测,其中FFN就是简单的3层的感知机,边界框预测包括归一化后的中心坐标以及宽高。
目标检测的效果
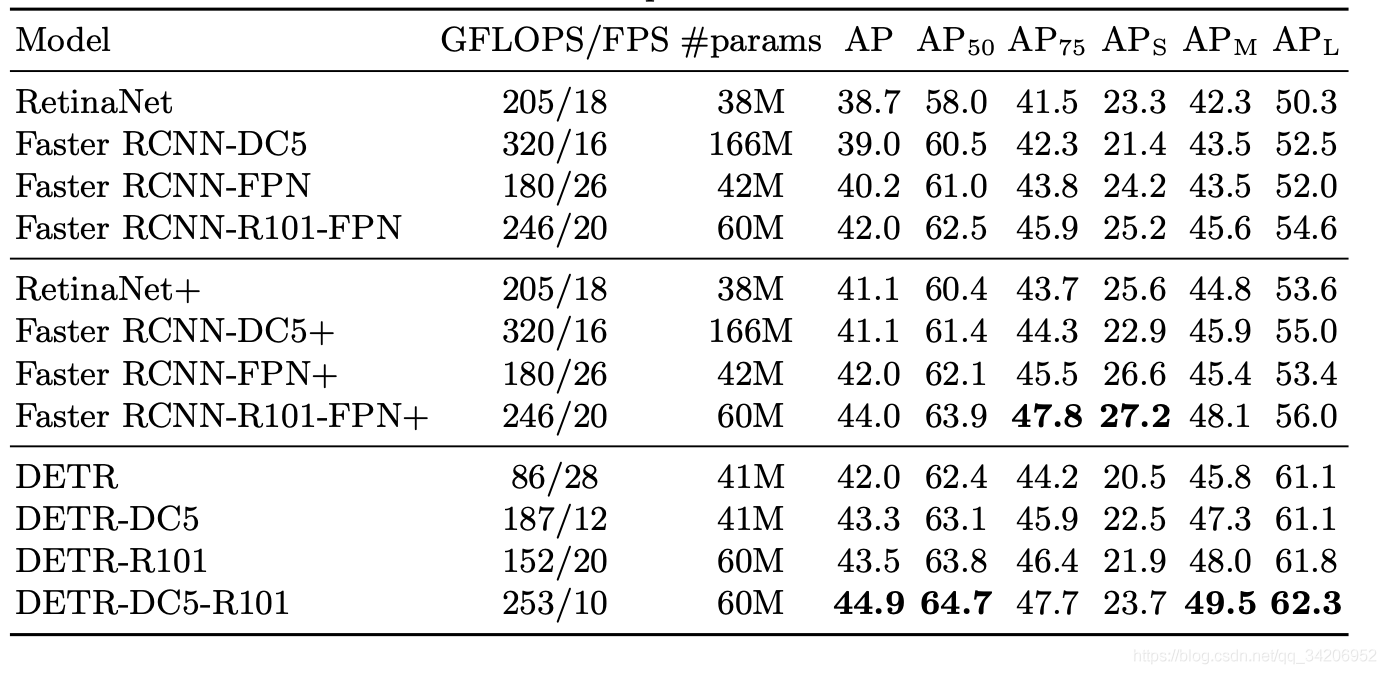
如上图所示,可以看到DETR的计算次数不算多,但是FPS也不算高,只能算中规中矩。
那么语义分割呢?
这里给出关于语义分割的大致架构,如下图所示:
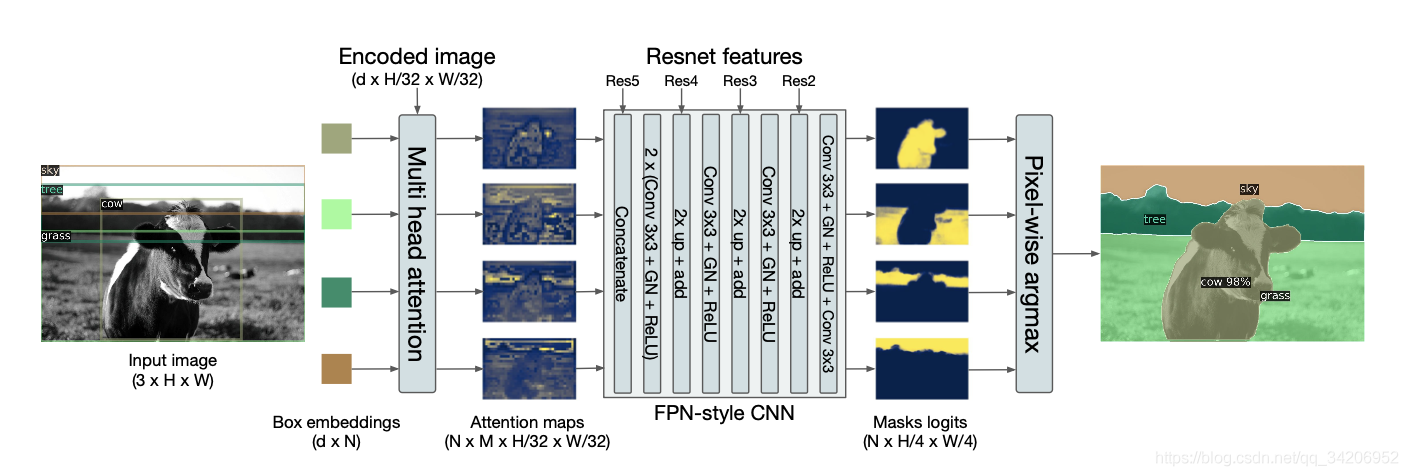
注意到,图中所描述的,边界框嵌入(Box Embedding)实质上就是decoder的输出(在FFN之前)。
然后使用一个多头部注意力的机制,这个机制实质上是对Q,K,V进行多次的线性变换,在这里面,K和V是Encoder的输入,Q是decoder的输出。
其中M是多头部注意力的头部数量。
之后,通过一个简单的CNN,得到一个Mask矩阵,用来生成语义分割的结果。
语义分割结果分析
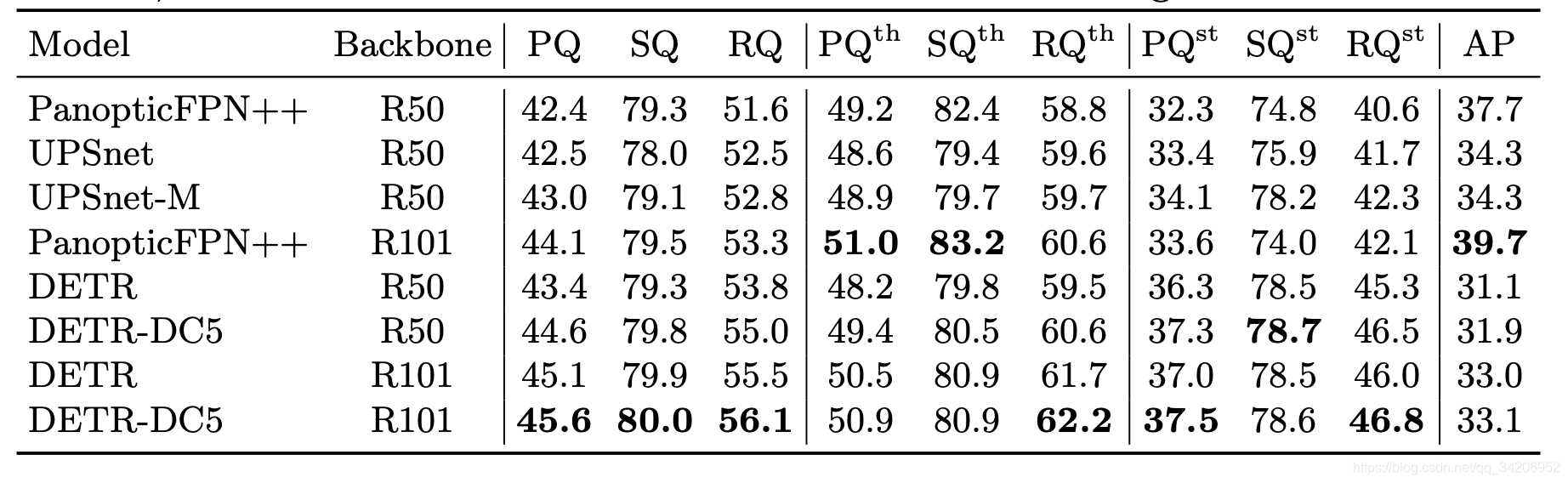
可以看到比起PanopticFPN++来说,效果的提升有限,特别是AP并不佳,表现一般。
结论
文章将Transformer应用到了目标检测以及语义分割的领域,取得了不错的效果,但是性能上相较于FastRCNN类似架构的方法,并没有明显的提升,但显现出这种序列模型不错的扩展能力。用一个架构解决多种问题,统一化模型的目标指日可待。
版权声明:本文为CSDN博主「MezereonXP」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_34206952/article/details/115379074






