开始
内容参考:Datawhale Task02: 练死劲儿-网络设计
一· 先验框
关于先验框,有的paper(如Faster RCNN)中称之为anchor(锚点),有的paper(如SSD)称之为prior bounding box(先验框),实际上是一个概念。通常,为了覆盖更多可能的情况,在图中的同一个位置,我们会设置几个不同尺度的先验框。这里所说的不同尺度,不单单指大小,还有长宽比。
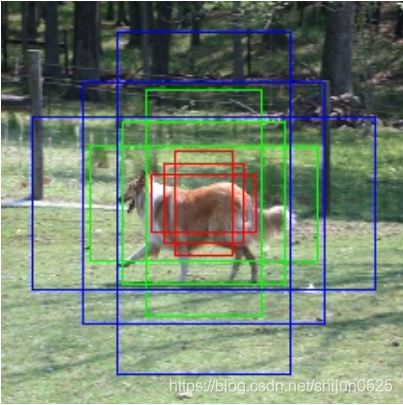
二· 生成先验框
我们铺设了很多的先验框,我们先要给出这些先验框的类别信息,才能让模型学着去预测每个先验框是否对应着一个目标物体。这些先验框中有很多是和图片中我们要检测的目标完全没有交集或者有很小的交集,我们的做法是,设定一个IoU阈值,例如iou=0.5,与图片中目标的iou<0.5的先验框,这些框我们将其划分为背景,Iou>=0.5的被归到目标先验框,通过这样划分,得到供模型学习的ground truth信息
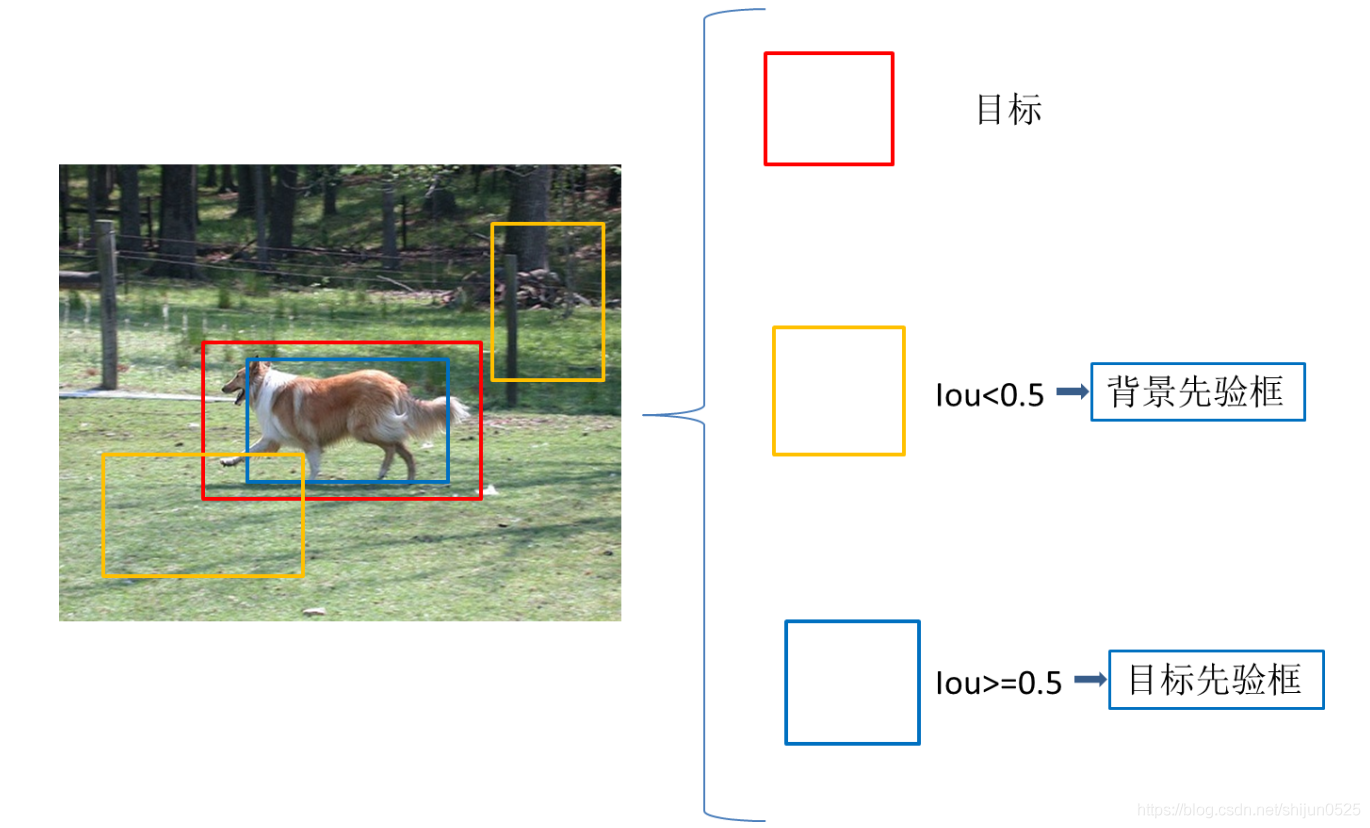
"""
设置细节介绍:
1. 离散程度 fmap_dims = 7: VGG16最后的特征图尺寸为 7*7
2. 在上面的举例中我们是假设了三种尺寸的先验框,然后遍历坐标。在先验框生成过程中,先验框的尺寸是提前设置好的,
本教程为特征图上每一个cell定义了共9种不同大小和形状的候选框(3种尺度*3种长宽比=9)
生成过程:
0. cx, cy表示中心点坐标
1. 遍历特征图上每一个cell,i+0.5是为了从坐标点移动至cell中心,/fmap_dims目的是将坐标在特征图上归一化
2. 这个时候我们已经可以在每个cell上各生成一个框了,但是这个不是我们需要的,我们称之为base_prior_bbox基准框。
3. 根据我们在每个cell上得到的长宽比1:1的基准框,结合我们设置的3种尺度obj_scales和3种长宽比aspect_ratios就得到了每个cell的9个先验框。
4. 最终结果保存在prior_boxes中并返回。
需要注意的是,这个时候我们的到的先验框是针对特征图的尺寸并归一化的,因此要映射到原图计算IOU或者展示,需要:
img_prior_boxes = prior_boxes * 图像尺寸
"""
def create_prior_boxes():
"""
Create the 441 prior (default) boxes for the network, as described in the tutorial.
VGG16最后的特征图尺寸为 7*7
我们为特征图上每一个cell定义了共9种不同大小和形状的候选框(3种尺度*3种长宽比=9)
因此总的候选框个数 = 7 * 7 * 9 = 441
:return: prior boxes in center-size coordinates, a tensor of dimensions (441, 4)
"""
fmap_dims = 7
obj_scales = [0.2, 0.4, 0.6]
aspect_ratios = [1., 2., 0.5]
prior_boxes = []
for i in range(fmap_dims):
for j in range(fmap_dims):
cx = (j + 0.5) / fmap_dims
cy = (i + 0.5) / fmap_dims
for obj_scale in obj_scales:
for ratio in aspect_ratios:
prior_boxes.append([cx, cy, obj_scale * sqrt(ratio), obj_scale / sqrt(ratio)])
prior_boxes = torch.FloatTensor(prior_boxes).to(device) # (441, 4)
prior_boxes.clamp_(0, 1) # (441, 4)
return prior_boxes
总结
由于现在只能做到读懂代码,代码段来源于Datawhale教程,对锚框有了一定的理解,之后有了新的理解再补充
版权声明:本文为CSDN博主「shijun0525」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/shijun0525/article/details/111409909





