文章目录[隐藏]
我最近对很火的元宇宙及其衍生概念进行了思考,虽然现在谈元宇宙落地还为时尚早,但是根据这个愿景反推回来很多的技术趋势和未来的发展方向还是值得关注的。下面是我的公众号原文:【AI行业进展研究与商业价值分析】系列之2021.12.04第一期|(元宇宙以及其中的AI可能性)
【AI行业进展研究与商业价值分析】系列之2021.12.04第一期|(元宇宙以及其中的AI可能性)
也欢迎大家关注我的公众号,我也运营了一个技术群,欢迎大家一起交流技术~

YOLOv5初理解
YOLOv5可以方便的进行工程化部署:
Y
O
L
O
v
5
(
P
y
T
o
r
c
h
)
−
>
O
N
N
X
−
>
C
o
r
e
M
L
−
>
i
o
s
YOLOv5(PyTorch) -> ONNX -> CoreML -> ios
YOLOv5(PyTorch)−>ONNX−>CoreML−>ios
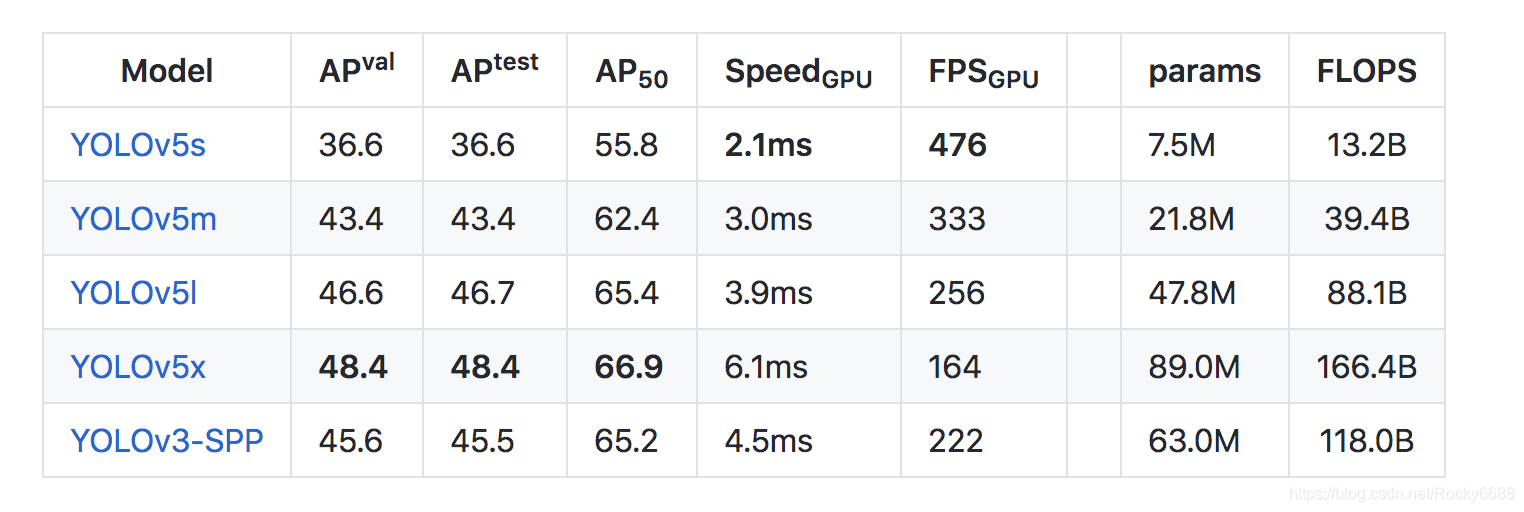
YOLOv5家族:
- YOLOv5x(最大的模型)
- YOLOv5l
- YOLOv5m
- YOLOv5s(最小的模型)
YOLOv5的优势:
- 使用PyTorch进行编写。
- 可以轻松编译成ONNX和CoreML。
- 速度极快,每秒140FPS。
- 精度超高,可以达到0.895mAP。
- 体积很小:27M。
- 集成了YOLOv3-spp和YOLOv4部分特性。
YOLOv5的网络模型
YOLOv5的官方代码中,给出了四种版本的目标检测网络,分别是YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x四个模型。
我们首先以YOLOv5s的网络结构为主线,讲解与其他三个模型(YOLOv5m、YOLOv5
l、YOLOv5x)的不同点。
YOLOv5s网络是YOLOv5系列中深度最小,特征图的宽度最小的网络。后面的3种网络都是在此基础上不断加深,不断加宽。
YOLOv5s网络最小,速度最快,AP精度也最低。但如果检测的大目标为主的场景,追求速度,那么这个模型也是一个很好的选择。
其他的三种网络,在此基础上不断的加深加宽网络,AP精度也不断提升,但速度的消耗也在不断增加。
YOLOv5的结构和YOLOv4很相似,但是也存在很多不同。
我们分输入端、Backbone、Neck和Prediction四个部分进行介绍。
输入端
Mosaic数据增强
YOLOv5的输入端采用了和YOLOv4一样的Mosaic数据增强的方式。
对多个图像进行随机缩放、随机裁剪、随机排布的方式进行拼接,这种方法对于小目标的检测效果还是很好的。
自适应锚框计算
在YOLO模型中,针对不同的数据集,都会有初始设定长宽的锚框。
在网络训练中,网络在初始锚框的基础上输出预测框,进而和真实框GroundTruth进行对比,计算两者差距,再反向更新,迭代网络参数。
可见初始锚框是非常重要的一部分,在YOLOv3、YOLOv4中,训练不同的数据集时,计算初始锚框的值是通过单独的程序运行的。
但是YOLOv5中将此功能嵌入到代码中,每次训练时,自适应的计算不同训练集中的最佳锚框值。
代码如下所示:
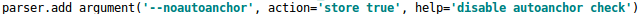
自适应图片缩放
在常用的目标检测算法中,不同的图片长宽都不相同,因此常用的方式是将原始图片统一缩放到一个标准尺寸,再送入检测网络中。
比如YOLO模型中常用的
416
×
416
416\times 416
416×416,
608
×
608
608\times 608
608×608等尺寸,比如对下面
800
×
600
800\times 600
800×600的图像进行缩放。

但YOLOv5代码中对此进行了改进,也是YOLOv5推理速度能够很快的一个重要的trick。
作者认为,在项目实际使用时,很多图片的长宽比不同,因此缩放填充后,两端的黑边大小都不同,而如果填充的比较多,则存在信息冗余,影响推理速度。
因此在YOLOv5的代码中datasets.py的letterbox函数中进行了修改,对原始图像自适应的添加最少的黑边。

图像高度上两端的黑边变少了,在推理时,计算量也会减少,即目标检测速度会得到提升。
这种简单的改进可以提升37%的推理速度。
注意:训练时没有采用缩减黑边的方式,还是采用传统填充的方式,即缩放到
416
×
416
416\times 416
416×416大小。只是在测试,使用模型推理时,才采用缩减黑边的方式,提高目标检测的推理速度。
版权声明:本文为CSDN博主「【WeThinkIn】的主理人」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/Rocky6688/article/details/107199675






