目录
Tensorflow Lite模型部署实战教程是一系列嵌入式Linux平台上的模型部署教程。
🌲基于的硬件平台:i.MX8MPlus EVK
🌟BSP版本:L5.10.52_2.1.0
🌞Tensorflow Lite版本:2.5.0
数据集
- 每个类的图像:每类≥1.5万张图片
- 每个类的实例。每类总数≥10k个实例(标记对象)
- 图像多样性。必须代表已部署的环境。对于现实世界的用例,我们推荐来自一天中不同时间、不同季节、不同天气、不同灯光、不同角度、不同来源(在线刮擦、本地收集、不同相机)等的图像。
- 标签一致性。所有图像中所有类的所有实例都必须标记。只有部分标签不起作用。
- 标签准确性。标签必须紧紧包裹每个对象。对象和它的边界框之间不应该存在空格。任何对象都不应该缺少标签。
- 背景图像。背景图像是没有对象的图像,这些对象被添加到数据集中以减少假阳性(FP)。我们建议使用约0-10%的背景图像来帮助减少FP(COCO有1000张背景图像供参考,占总数的1%)。
模型选择
如果是移动端部署,可以选择YOLOv5n/s/m。
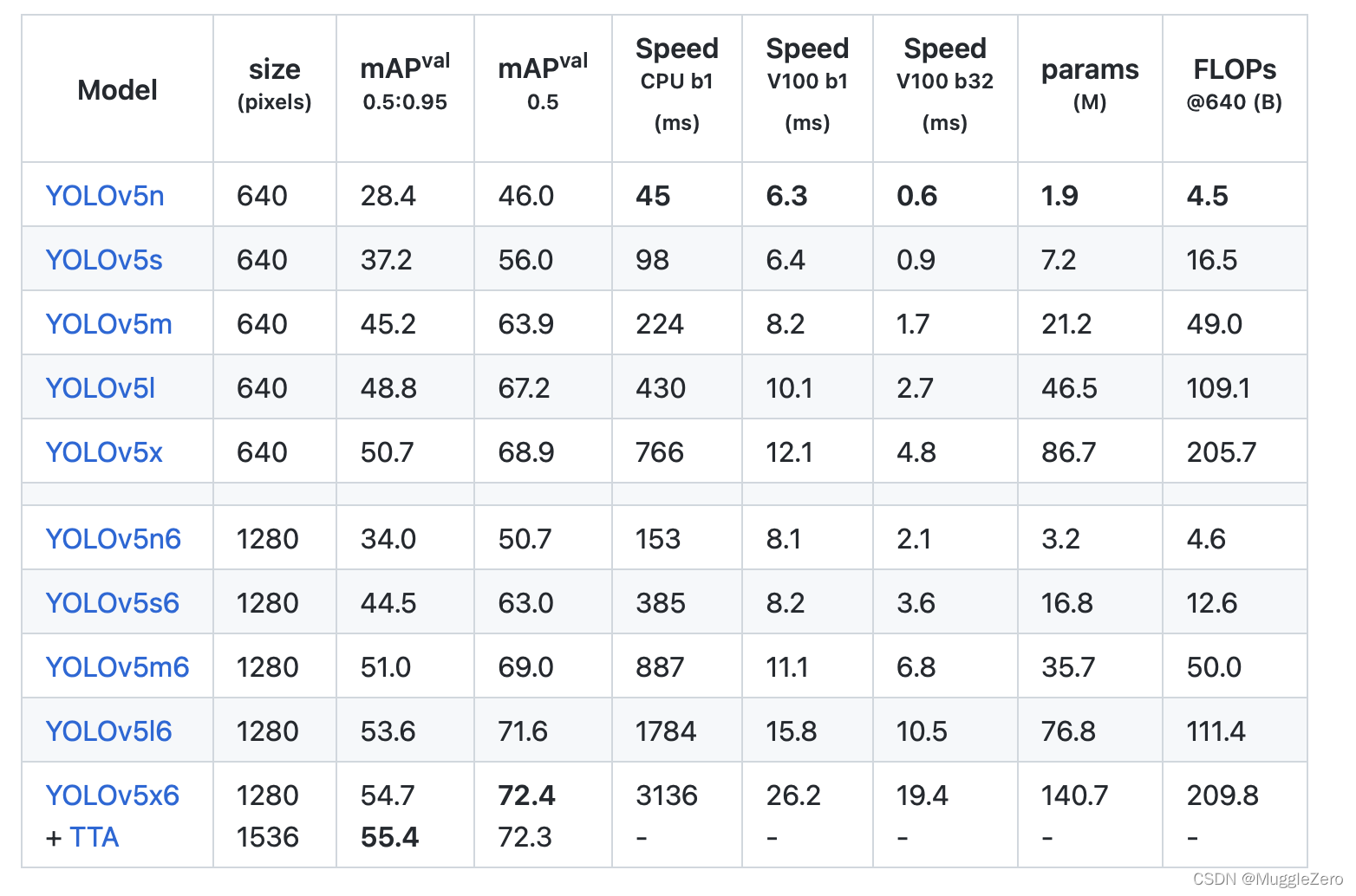
使用预训练权重
建议用于中小型数据集(即VOC、VisDrone、GlobalWheat)。将模型的名称传递给--weights参数。模型会自动从最新的YOLOv5版本下载。
python train.py --data custom.yaml --weights yolov5s.pt
yolov5m.pt
yolov5l.pt
yolov5x.pt
custom_pretrained.pt建议大型数据集使用空权重(即COCO,Objects365,OIv6)。传递模型的yaml,以及一个空的--weights ''参数。
python train.py --data custom.yaml --weights '' --cfg yolov5s.yaml
yolov5m.yaml
yolov5l.yaml
yolov5x.yaml训练设置
训练周期
从300个epoch开始。如果这很早就过合时宜,那么你可以缩短epoch。如果在300个epoch后没有出现过拟合,则训练时间更长,即600、1200个epoch等。
图像大小
COCO以--img 640的原生分辨率进行培训,但由于数据集中大量小对象,它可以从--img 1280等更高分辨率的培训中受益。如果有很多小对象,那么自定义数据集将受益于原生或更高分辨率的培训。最佳推理结果是同时获得的--img与训练一样,即如果在--img 1280训练,还应该在--img 1280进行测试和检测。
批处理大小
使用硬件允许的最大--batch-size。
超参数
超参数。默认超参数在hyp.scratch.yaml中。在考虑修改任何超参数之前,先使用默认超参数进行训练。一般来说,增加增强超参数将减少和延迟过度拟合,从而延长训练时间并提高最终mAP。减少损失成分增益超参数,如hyp['obj'],将有助于减少这些特定损失组件的过度拟合。
版权声明:本文为CSDN博主「MuggleZero」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_38131812/article/details/121802283






