文章目录[隐藏]
文末有代码
VOC数据集音速下载教程
你还在苦苦地寻找voc数据集的资源吗,你还在骂骂咧咧地到别人博客里付费下载voc数据集吗?看了这篇,妈妈再也不用担心你下载voc数据集了!
这种方式不局限于下载数据集哦,我用来下CUDA的时候也挺管用,虽然没有下voc数据集那么快,但是至少比直接在官网上下载快得多,我想应该也适用于下载其他东西
对准要下载的数据集右击–>复制链接

如果你迅雷已经打开了它会自动弹出下载界面,下载即可。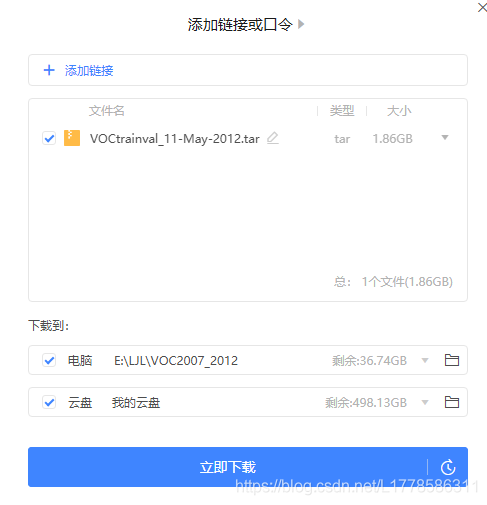
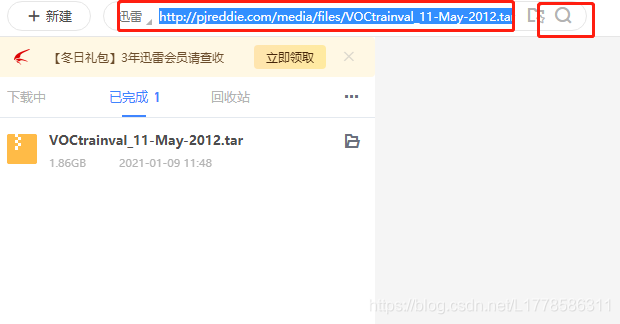
如果下载界面没有打开…
把刚才复制的链接手动粘贴到迅雷里,然后搜索,下载即可。
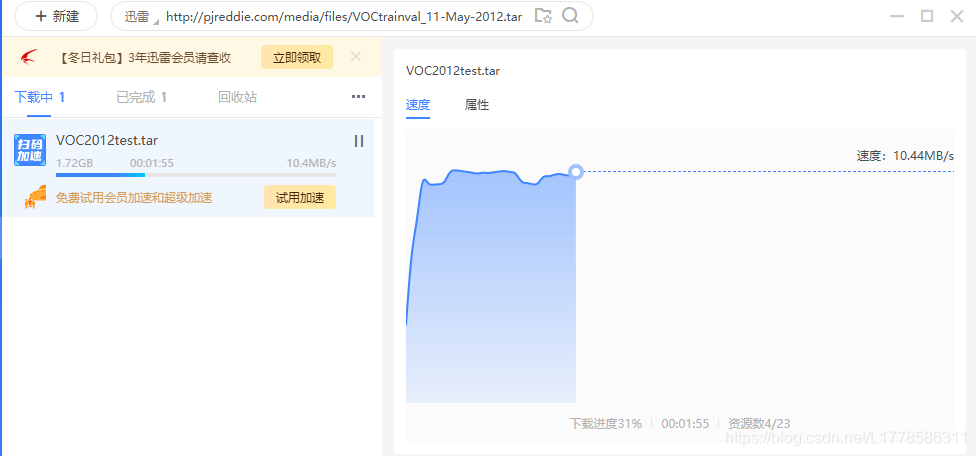
音速下载中,速度不会降…
训练、验证、测试集的划分使用
在这里我只是大致地介绍下voc2007数据集里面与目标检测任务相关的内容(2012一样),重点是划分。
下载完的数据集下压有如下内容,其中Annotations存放的XML文件,即框的信息,物体类别等。ImageSets里面的Main存放着txt文件,即图片的id,这个很重要!JPEGImages里面就是图片了。

这些大家都应该有所了解了。
剩下来就是扔进网络训练了,扔之前得有训练和验证集,测试集预测阶段才用。很多博客都是用一段的代码先给数据集生成存放id的txt文件(Main文件夹里),然后再把整合标签信息(XML文件),最后生成一个train.txt、val.txt如下图:

前面是图片的绝对路径,后面是框的信息以及分类,框的信息和分类为一组,一组5个数字,几个框就几个数字。
其实,VOC数据集已经帮我们把训练、验证、测试集分好了,就在Main文件夹里面,我们不要,不要自行分类,虽然说是打乱再随机分,但是万一运气不好把某一类的图片全放到验证、测试集里面去呢,虽然概率不大,但是训练效果总不会很好。
如下图所示,作者已经在ImageSets/Main里面给我们划分好了训练、验证集了,也就是说ID有了,我们只需要生成图片路径+标签信息那个文件夹就行了。
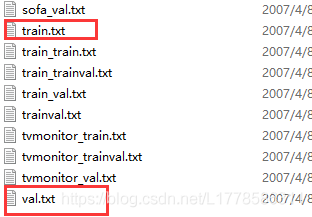
如果是自己制作数据集的话就要生成包含id的txt文本,然后整合标签信息生成最终的文件拿去训练、验证和测试。
大家训练voc数据集可以把2007、2012两个合并起来,因为它们数量不多。在Windows系统里如果想把两个txt文件合起来可以用这行python代码,使用type关键字
import os
os.system("type 2007_train.txt 2012_train.txt > train.txt")
在Linux系统下则执行下面代码,使用cat关键字
import os
os.system("cat 2007_train.txt 2012_train.txt > train.txt")
voc数据集使用代码提取码:djqx
这两个代码不长,自己读一遍会对它的作用更深刻,以后就难忘了。相信对于作为程序员的你来说这都不算事儿~~~
觉得有用的话点个赞呗。
版权声明:本文为CSDN博主「识久」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/L1778586311/article/details/112389785






