文章目录[隐藏]
目录
0.引言
本人配置:win10,python3.6、 torch1.7+cu110 、cuda11.0、 cudnn8.0.4.30、 TensorRT-7.1、 vs2019,cmake3.15.5
整篇博客包括以下几个方面
1)基于python的yolov5实现火焰烟雾模型的训练
2)将训练好的模型转为tensorrt所需要的engine文件
3)基于c++实现模型推理与动态库打包
1.yolov5模型训练
yolov5代码采用这里的yolov5源码。我们只需要把数据放进去,点击train.py即可,步骤如下:
1.1 数据准备
数据采用labelimg进行标注,标注的时候选择yolo格式,由于烟雾比较分散,因此标注的时候可以分块标注,如图1所示。

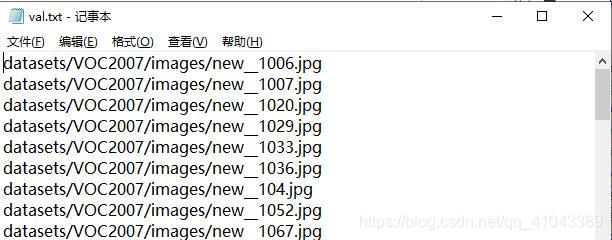
标注完后,会在源码中新建文件夹datasets/VOC2007/images,用于存放图片;新建文件夹datasets/VOC2007/labels,用于存放标注好的txt文件。新建文件夹datasets/VOC2007/Main,运行下面这个程序,生成train.txt 与val.txt,这是将数据集以9:1划分训练集与测试集,txt文件中内容如下图2。
# -*- coding: utf-8 -*-
import os
import random
imgfilepath=r'images/'
saveBasePath=r'Main/'
train_percent=0.9
total_file = os.listdir(imgfilepath)
num=len(total_file)
list=range(num)
tr=int(num*train_percent)
train=random.sample(list,tr)
ftrain = open(os.path.join(saveBasePath,'train.txt'), 'w')
fval = open(os.path.join(saveBasePath,'val.txt'), 'w')
for i in list:
name=total_file[i]+'\n'
if i in train:
ftrain.write('datasets/VOC2007/images/'+name)
else:
fval.write('datasets/VOC2007/images/'+name)
ftrain.close()
fval.close() 1.2 模型训练
训练的时候改一下自己的数据集路径即可,我们在data文件夹创建一个自己的self.yaml文件,内容如下
# train and val datasets (image directory or *.txt file with image paths)
train: ./datasets/VOC2007/Main/train.txt
val: ./datasets/VOC2007/Main/val.txt
# number of classes
nc: 2
# class names
names: ['fire','smoke']
再改一下train.py中的配置即可,如图3所示。

然后就可以开始训练了,出现图4所示的东西就代表开始训练了

1.3 模型测试
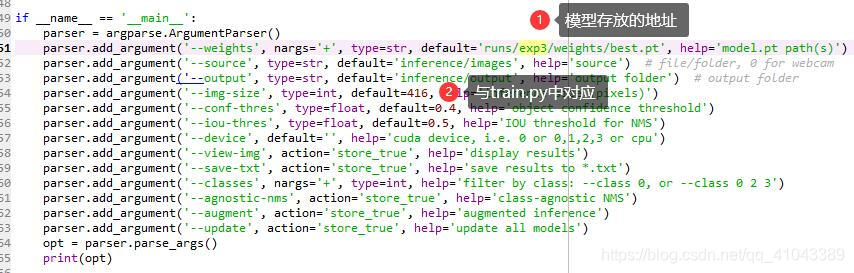
训练完成之后,将会在runs/exp[看你情况]/weights文件夹产生best.pt文件,我们用这个模型进行测试。首先在inference/images文件夹下放几张测试图片,然后修改detect.py文件,如图5所示,置信度与iou阈值根据一般不用改,想改也行。
然后运行detect.py ,结果保存在inference/output文件夹下,检测结果如图6,上面是smoke,下面是fire。

运行detect.py还会计算出每个图片的运行时间,如下图:可以看出每张图片的运行时间在16ms左右。这里记下来,因为要和下面tensorrt时间进行对比。

2 模型转换
tensorrt加速需要把模型转为engine文件,这里有两种转换方式。这也意味着坑最多的地方来了
2.1 pt→wts→engine
2.1.1 pt转wts
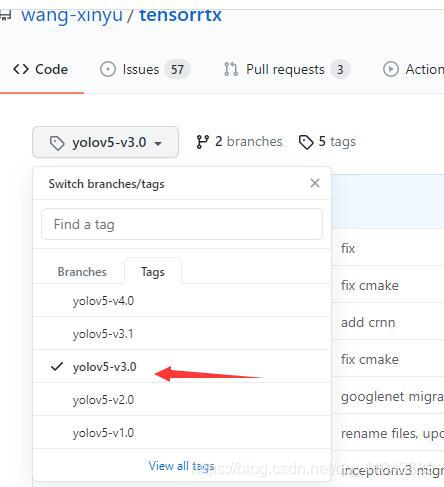
首先去这里下载大佬写好的转换程序(注:我们用的是yolov5-3.0版本,因此tensorrtx这个包也要下载对应的,如图7所示)。把yolov5里面的gen_wts.py和刚才训练模型的train.py放在同一个目录下。
修改一下gen_wts.py中的模型路径,然后运行,就能得到yolov5s.wts文件,这个文件里面存放的就是权重,正常的大小应该和best.pt文件差不多。
import torch
import struct
from utils.torch_utils import select_device
# Initialize
device = select_device('0')
# Load model
model = torch.load('runs/exp3/weights/best.pt', map_location=device)['model']#.float()#.fuse() # load to FP32
model.to(device).eval()
print(model)
f = open('yolov5s.wts', 'w')
f.write('{}\n'.format(len(model.state_dict().keys())))
for k, v in model.state_dict().items():
vr = v.reshape(-1).cpu().numpy()
f.write('{} {} '.format(k, len(vr)))
for vv in vr:
f.write(' ')
f.write(struct.pack('>f',float(vv)).hex())
f.write('\n')
2.1.2 wts转engine
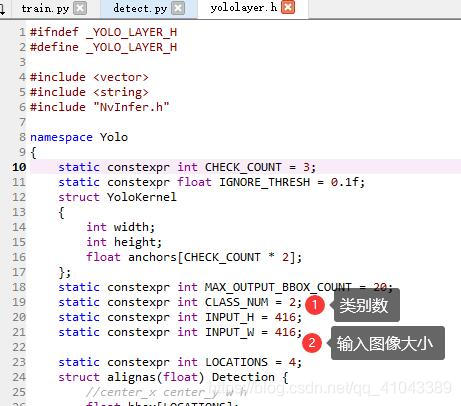
回到刚才下载的tensortx里面,我们进入yolov5这个文件夹,我们主要需要修改yololayer.h部分参数,即如图8所示的类别数与输入图像的大小。
然后修改CMakeLists.txt如下,我们是windows系统,这个文件是linux系统下的,所以我们要把cuda和tensorrt的路径注释掉(前提是已经安装好cuda,tensorrt,opencv,并且把opencv的路径添加到系统环境变量中了,这样就可以让cmake自己去找路径),如下
cmake_minimum_required(VERSION 2.6)
project(yolov5)
add_definitions(-std=c++11)
option(CUDA_USE_STATIC_CUDA_RUNTIME OFF)
set(CMAKE_CXX_STANDARD 11)
set(CMAKE_BUILD_TYPE Debug)
find_package(CUDA REQUIRED)
include_directories(${PROJECT_SOURCE_DIR}/include)
# include and link dirs of cuda and tensorrt, you need adapt them if yours are different
# cuda
#include_directories(/usr/local/cuda/include)
#link_directories(/usr/local/cuda/lib64)
# tensorrt
#include_directories(/usr/include/x86_64-linux-gnu/)
#link_directories(/usr/lib/x86_64-linux-gnu/)
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -std=c++11 -Wall -Ofast -D_MWAITXINTRIN_H_INCLUDED")#-Wfatal-errors
cuda_add_library(myplugins SHARED ${PROJECT_SOURCE_DIR}/yololayer.cu)
target_link_libraries(myplugins nvinfer cudart)
find_package(OpenCV)
include_directories(OpenCV_INCLUDE_DIRS)
add_executable(yolov5 ${PROJECT_SOURCE_DIR}/yolov5.cpp)
target_link_libraries(yolov5 nvinfer)
target_link_libraries(yolov5 cudart)
target_link_libraries(yolov5 myplugins)
target_link_libraries(yolov5 ${OpenCV_LIBS})
add_definitions(-O2 )#-pthread
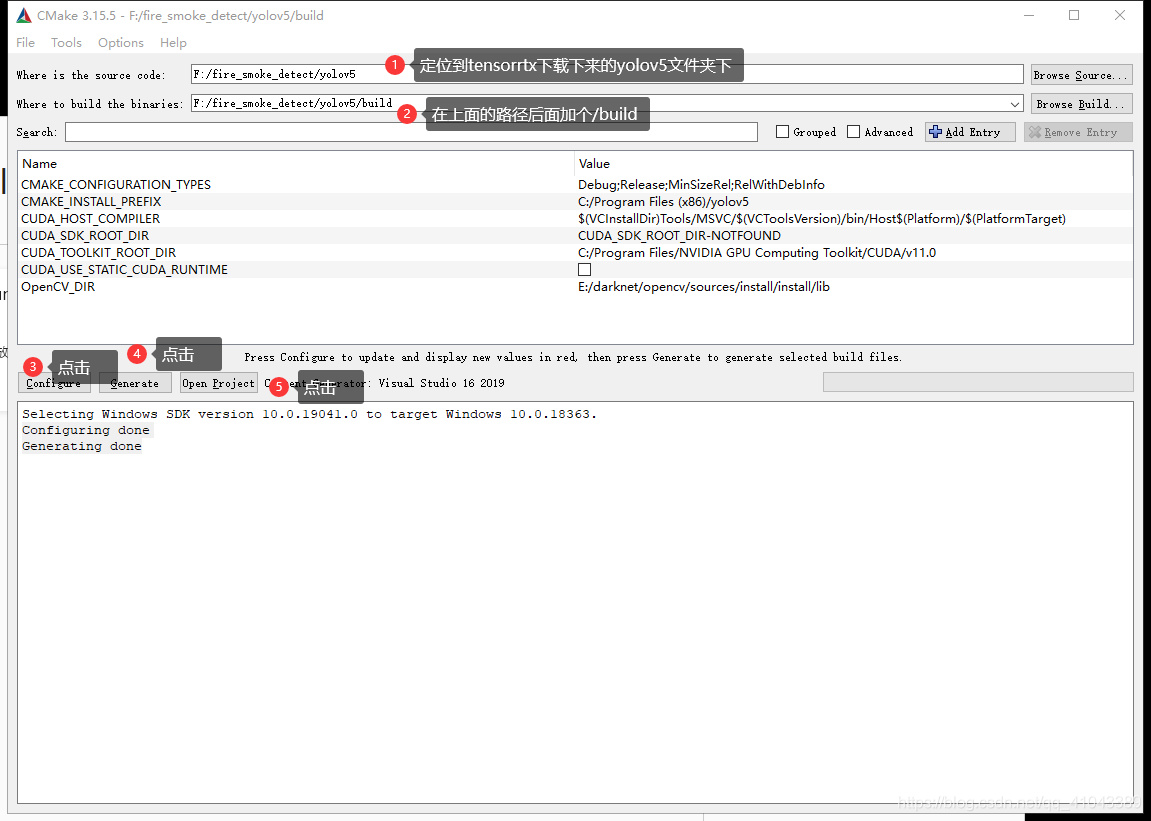
然后打开安装好的cmake-gui软件,source code定位到tensorrtx的yolov5文件夹下,具体目录根据自己存放的路径进行修改(比如我是在F盘新建了一个fire_smoke_detect的文件夹,然后把yolov5这个文件夹幅值过来了),build目录就在上面的目录添加/build,如图9,然后点击configure→generate。只要显示Configuring done和Generating done就代表这一步成功了。然后点击open project进入visual studio 2019主界面。
进来之后首先打开common.hpp,把文件中的9行的#include<dirent.h>注释掉,把278-300行改成如图所示,这是因为这里调用的dirent.h是linux系统的,我们windows有这个会报错,这个作用实际上是读取文件夹下所有图片的路径。

由于上面把读取路径的程序注释掉,所以我们要自己写一个,就写在yolov5.cpp里面。同时注意#define NET s // s m l x 改成s,因为我们是yolov5s模型。
#include <iostream>
#include <chrono>
#include "cuda_runtime_api.h"
#include "logging.h"
#include "common.hpp"
#include <io.h>
#include <string>
#include <vector>
#include <fstream>
#include <iostream>
#include <string>
using namespace std;
char *trtModelStream{ nullptr };
size_t size_e{0};
#define USE_FP16 // comment out this if want to use FP32
#define DEVICE 0 // GPU id
#define NMS_THRESH 0.4
#define CONF_THRESH 0.5
#define BATCH_SIZE 1
#define NET s // s m l x
#define NETSTRUCT(str) createEngine_##str
#define CREATENET(net) NETSTRUCT(net)
#define STR1(x) #x
#define STR2(x) STR1(x)
// stuff we know about the network and the input/output blobs
static const int INPUT_H = Yolo::INPUT_H;
static const int INPUT_W = Yolo::INPUT_W;
static const int CLASS_NUM = Yolo::CLASS_NUM;
static const int OUTPUT_SIZE = Yolo::MAX_OUTPUT_BBOX_COUNT * sizeof(Yolo::Detection) / sizeof(float) + 1; // we assume the yololayer outputs no more than MAX_OUTPUT_BBOX_COUNT boxes that conf >= 0.1
const char* INPUT_BLOB_NAME = "data";
const char* OUTPUT_BLOB_NAME = "prob";
static Logger gLogger;
void getAllFiles(string path, vector<string>& files, string fileType) {
//文件句柄
intptr_t hFile = 0;
struct _finddata_t fileInfo;
string p;
if ((hFile = _findfirst(p.assign(path).append("\\*" + fileType).c_str(), &fileInfo)) != -1) {
do {
files.push_back(fileInfo.name);
} while (_findnext(hFile, &fileInfo) == 0);
_findclose(hFile);//关闭句柄
}
}然后在477行左右的读取文件图片路径的地方替换成我们的程序,477-481是他自己的,我们改成485-486换成我们的读取方法

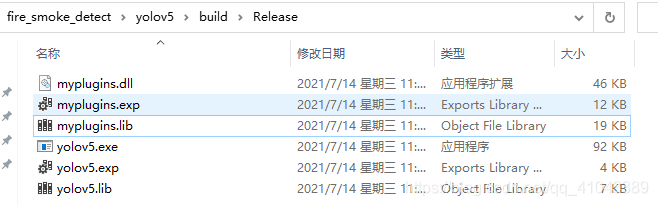
接下来。到解决方案资源管理器里面,找到myplugins,右键→生成,然后Release文件夹下生成myplugins.lib,然后找到yolov5,右键→生成,在Release文件夹下生成yolov5.exe,完成后如下图10所示
接下来就是正式将2.1.1生成的yolov5s.wts转为engine文件,步骤如下:
1)将yolov5.wts复制到build文件夹中,如下:

2)接着就是打开cmd,定位到build/Release目录下,输入yolov5 -s,如下

这样就代表成功了!!!
3)测试刚才的yolov5s.engine文件,首先在build目录下新建一个samples文件夹,并放几张测试图片进去,如图

然后在刚才的cmd中运行yolov5 -d ../samples,结果如下图所示,第一张因为要先加载模型,所以比较慢,后续的图片都在9ms左右完成检测。对比1.3可知,没有加速的图检测时间在15ms左右,转tensort进行加速之后,速度稳定在9ms。十分有效。

result文件夹下产生的都是带检测框的图片,如图

3 动态库打包
如果软件组的同事要将我们的模型拿去用,那么我们还需要将上述程序打包成动态库文件,方便他们用cpp、java、c#进行调用。步骤如下:
1,修改我们的yolov5.cpp程序,其实就是从main里面加载模型和检测模型的程序拿出来。这样生成动态库的时候,同事只需要我们加载模型的接口和检测的接口即可。
代码在这里:
程序改好后,我们在右边解决方法中找到yolov5,右键→属性→配置类型改成动态库(.dll)→目标文件扩展名改成.dll。然后保存,出来找到yolov5,右键→生成,完毕之后在Release文件夹会产生yolov5.dll和yolov5.lib。就OK了。
2,测试我们打包好的动态库是否正确。
我们在桌面新建一个空的工程,然后新建一个.cpp文件,输入下面的程序。

#include <opencv2/opencv.hpp>
#include<iostream>
using namespace cv;
using namespace std;
extern "C" __declspec(dllexport) void Init();
extern "C" __declspec(dllexport) void Detect(cv::Mat & img);
int main()
{
// 返回1则整齐 返回0就是穿戴整齐
Init();
Mat frame = imread("./test.jpg");
Mat frame1;
for (int i = 1; i < 10; i++)
{
//frame.copyTo(frame1);
frame1 = frame.clone();
Detect(frame1);
}
system("pause");
return 0;
}然后去属性里面,把opencv,cuda,tensort的路径,链接器的lib文件配置好。如下:

 然后就可以运行了,运行之后会产生X64/Release的文件夹,然后报错。说找不到函数init和detec函数,这是因为没有我们的dll文件放进来(因为刚才没有这个文件夹)。接着我们把myplugins.dll和yolov5.dll放进来,再运行就行了。
然后就可以运行了,运行之后会产生X64/Release的文件夹,然后报错。说找不到函数init和detec函数,这是因为没有我们的dll文件放进来(因为刚才没有这个文件夹)。接着我们把myplugins.dll和yolov5.dll放进来,再运行就行了。
这里有个问题还没解决,上面的程序中,我们把test.jpg循环测试了10次。后面几次的结果比前面几次多输出了一个0(我们是2类,0是fire,1是smoke,有几个数就代表检测到了几个目标),这个问题后面看看怎么解决。

上面用于动态库打包的修改了的yolov5.cpp的detect这个函数还有很多地方可以优化,后面有空的时候会再改改。
版权声明:本文为CSDN博主「机器鱼」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_41043389/article/details/118713218





