原文:Deep high-resolution representation learning for visual recognition
论文链接: https://arxiv.org/abs/1908.07919v2
pytorch official code: https://github.com/HRNet
笔记时间:2020.11.22
文章最早发表在了CVRP2019,后面被顶刊TPAMI录用。
之所以要看这篇文章,是先看了OCR,看代码的过程中碰到backbone是HRNet,HRNet搭配OCR达到了很好的结果。
对目前所看到的语义分割相关的文章中可以发现,对于一个语义分割任务,首先会通过一个backbone获得一个分辨率较小的图(很多论文都会提到output stride,即输入图像尺寸经过一个网络后的尺寸的大小的比例),再对这个分辨率较小的图进行一些利用上下文语义信息的处理。
backbone的任务不仅仅适用于语义分割,最早适用于分类网路的,同时在各种计算机视觉的任务中都是基本操作。由此,诞生了一些重要的网络,例如残差的resnet,轻量级的googlenet,vgg等等,同时也包括这篇HRNet。对于上下文语义处理的步骤,最早也是出现了包括deeplab和pspnet两个经典的方法,后面也有利用注意力机制的no-local和ccnet等等。包括和HRNet搭配使用的这个OCR。
HRNet这是一篇SOTA的文章。对于视觉识别任务,包括姿态估计,语义分割等。一般的方法都是使用卷积神经网络进行不断地降采样,包括resnet和vggnet等,然后再恢复高分辨率。而HRnet的特点在于把串行的结构做成并行的,把降低分辨率的操作改成保持分辨率的操作。
Abstract
两个关键特点:
1.高分辨率和低分辨率并行连接,同步推进。
2.高低分辨率图之间不断地交换信息
高分辨率图的存在使得空间上更加精准,低分辨率图的存在使得语义上更充分。
Introduction
对于一般的分类网络来讲,通过卷积逐渐缩小图像的空间尺寸,进一步用于分类。

对于位置敏感的计算机视觉任务是需要高分辨率表示的。hrnet在整个过程中保持高分辨率的表示。
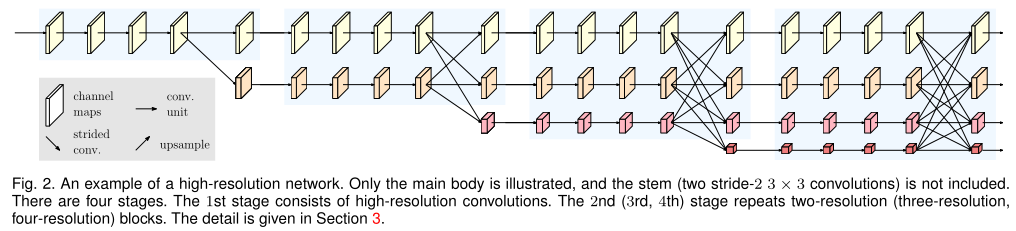
网络由四个阶段组成。第n个阶段包含对应于n个分辨率的n个流。通过反复的交换平行流中的信息来进行重复进行多分辨率的融合。
其他的高低分辨率融合都是通过融合low_level的高分率和低分辨率上采用获得的high_level高分辨率。而hrnet是在低分辨率的帮助下,多次融合高分辨率。
HRNetV1:只输出从高分辨率卷积流计算的高分辨率表示。
HRNetV2:结合了所有从高到底分辨率的并行流的表示。
HRNetV2p:从HRNetV2的高分辨率输出构建出multi-level representation。
Related work
学习低分辨表示:以FCN为代表,移除分类网络的全连接层。得到的低分辨率表示来获得粗略估计图,通过结合low_level的中分辨率层来达到相对精细的分割。之后的改进包括deeplab和pspnet。
恢复高分辨率表示:通过上采用过程来恢复高分辨率表示,segnet,unet,encoder-decoder,不对称上采样等等。
保持高分辨率表示
多尺度融合
Model
先通过2个3*3卷积降到1/4的resolution。
由几部分组成:
- parallel multi-resolution convolutions
- repeated multi-resolution fusions
- representation head
1.parallel multi-resolution convolutions
用一个并行卷积流的方法,从第一阶段开始,逐步逐个添加高分辨到低分辨率的流。后一个阶段的并行流的分辨率由前一个阶段的分辨率和更低分辨率组成。
看论文这段话说的感觉复杂,其实看图可能更好理解一点。说白了就是有很多个阶段,越往后面,不同分辨的数量越多。在第一阶段就只有原尺寸的图,第二阶段就有两个不同分辨率图的并行继续,以此类推。
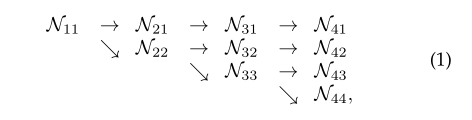
上图中N32表示的就是第三阶段的第二个流的表示。
2.repeated multi-resolution fusions
重复融合多分辨率的模块,跨分辨率交换信息。
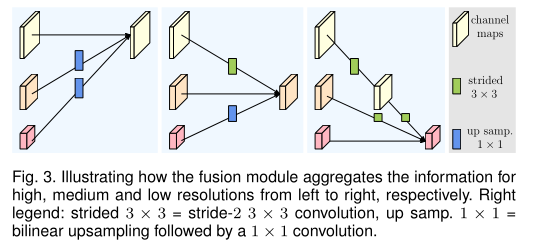
这是一个融合三分辨率的例子。可以看出三个输出中的每一个输出都是与三个输入相关的,即
R
r
o
=
f
1
r
(
R
1
i
)
+
f
2
r
(
R
2
i
)
+
f
3
r
(
R
3
i
)
R^o_r= f_{1r}(R^i_1)+f_{2r}(R^i_2)+f_{3r}(R^i_3)
Rro=f1r(R1i)+f2r(R2i)+f3r(R3i)
同时也会得到一个额外的输出,
R
4
o
=
f
14
(
R
1
i
)
+
f
24
(
R
2
i
)
+
f
34
(
R
3
i
)
R^o_4= f_{14}(R^i_1) + f_{24}(R^i_2) + f_{34}(R^i_3)
R4o=f14(R1i)+f24(R2i)+f34(R3i)
这些个f就是一系列操作,也就是图中所示的卷积上采样等操作。对高分辨率到低分辨率,低分辨率到高分辨率,同分辨率到同分辨率,操作均不同,具体可见上图。
3.representation head
有三种不同的输出表示:
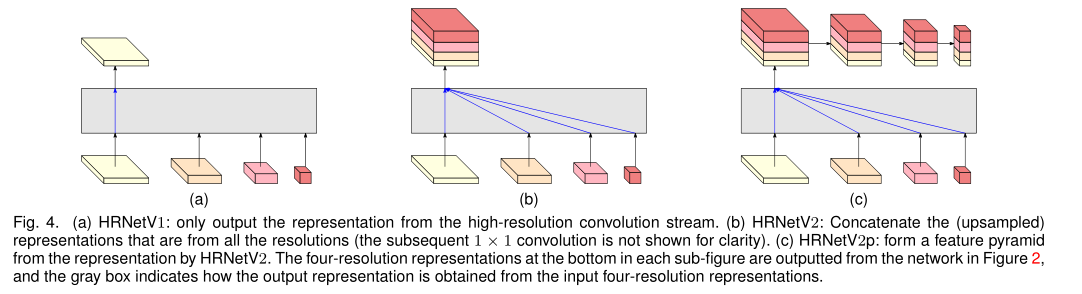
对于最后的结果的四分辨率流,根据如何去利用这个流分成了三种不同的方式。
(a):只输出高分辨率 (人体姿态估计)
(b):拼接四个流的输出 (语义分割)
©:在b的基础上形成特征金字塔表示(对象检测)
4.组装起来
再次回过头以完整和组装的视角来看这张图的时候,会更清晰一些。网络的机构体现了最初摘要中所说的并行的意思。有并行卷积流同步的向前推进。上图结构分为4个stage,每个stage的每个分辨率都要先经过四次残差卷积。一个stage中,通过3*3的卷积操作使得从高分辨率到低分辨率。分辨率越小越宽(channel数越多)。呈现2的指倍数增长,最小的分辨率的宽度是最大的八倍。
在语义分割中的应用
这个方法可以用在很多计算机视觉领域,我只看了语义分割的部分。
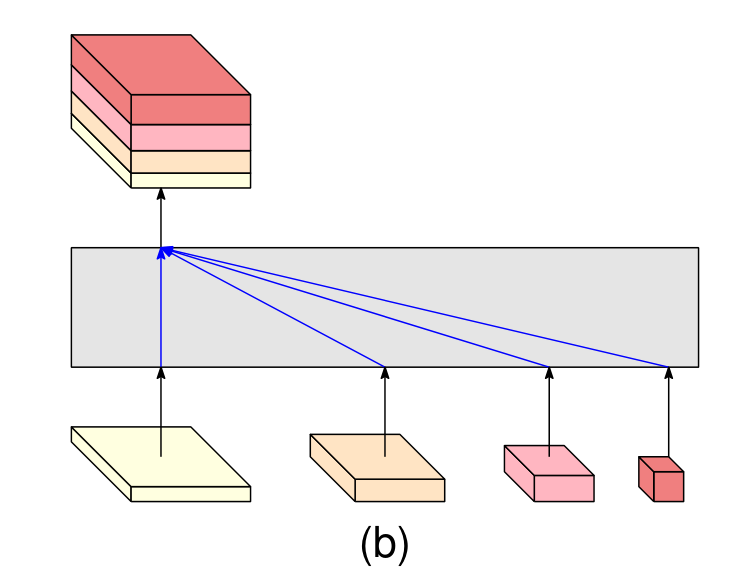
就像上图所示,对四个分辨率的输出进行拼接。这就是就一个维度为15C(C是最大的那个分辨率的channel数,1+2+4+8=15)
对其进行softmax再上采样四倍得到与原图一样大小的分割图。
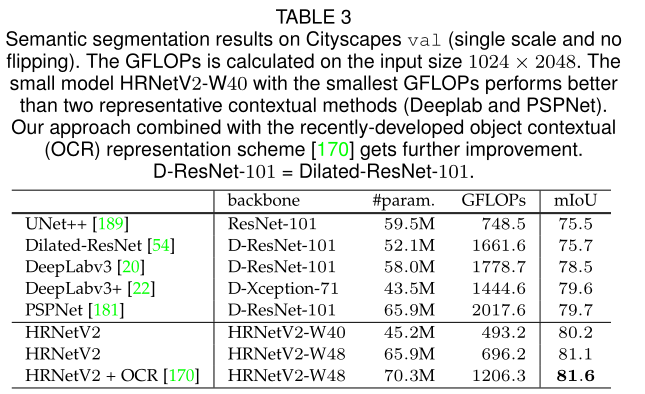
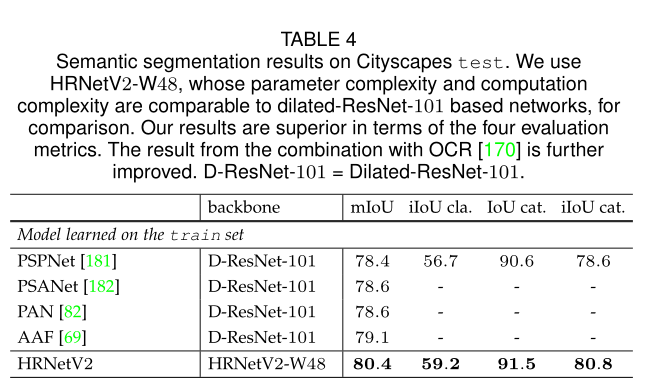
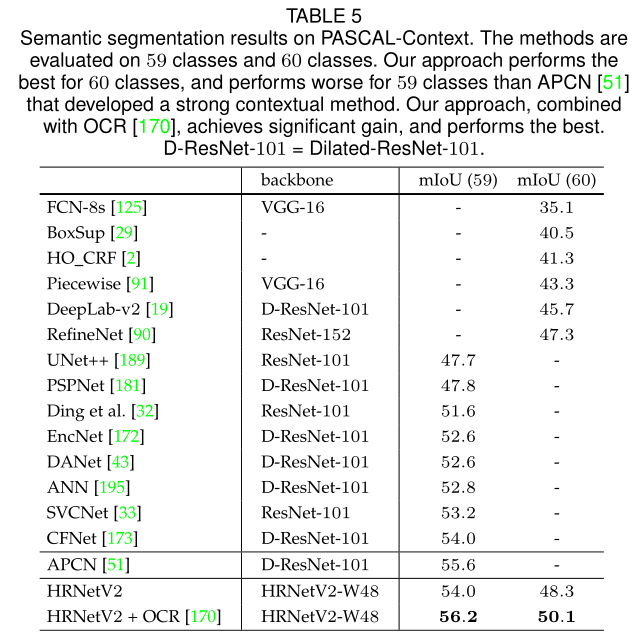
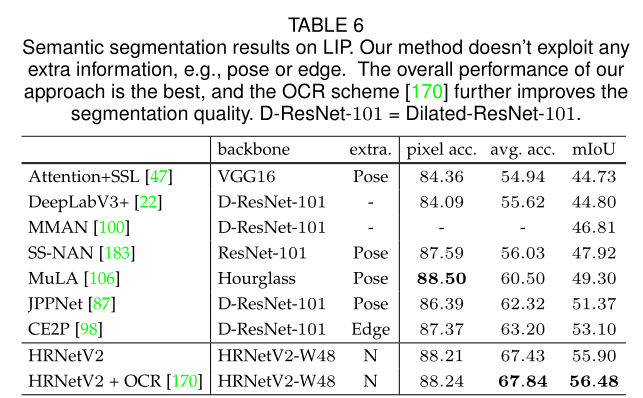
可见,在各大主流的数据集上都体现了HRNet+ORC的强势
Conclusions
作者总结了HRNet和其他的不同。高低分辨率是并联而不是串联,高分辨率是remain的而不是recover的,具有 strong position sensitivity(对位置敏感的任务好)。
将来的主要工作是希望将HRNet运用到各个计算机视觉的任务中。
关于代码
github中给出了HRNet+OCR相应的代码。我是直接看的HRNet-OCR分支下的这个文件。
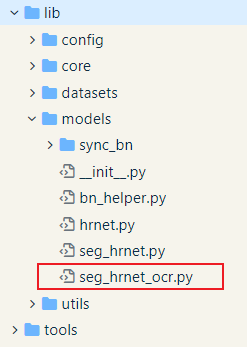
对于HRNet而言,代码中有四个比较重要的类,BasicBlock、Bottleneck、HighResolutionModule、HighResolutionNet四个类。BasicBlock和Bottleneck是残差块,在resnet中也是能看到的。HighResolutionModule是进行多分辨率融合的模块,HighResolutionNet是HRNetv2。
1.残差块BasicBlock和Bottleneck
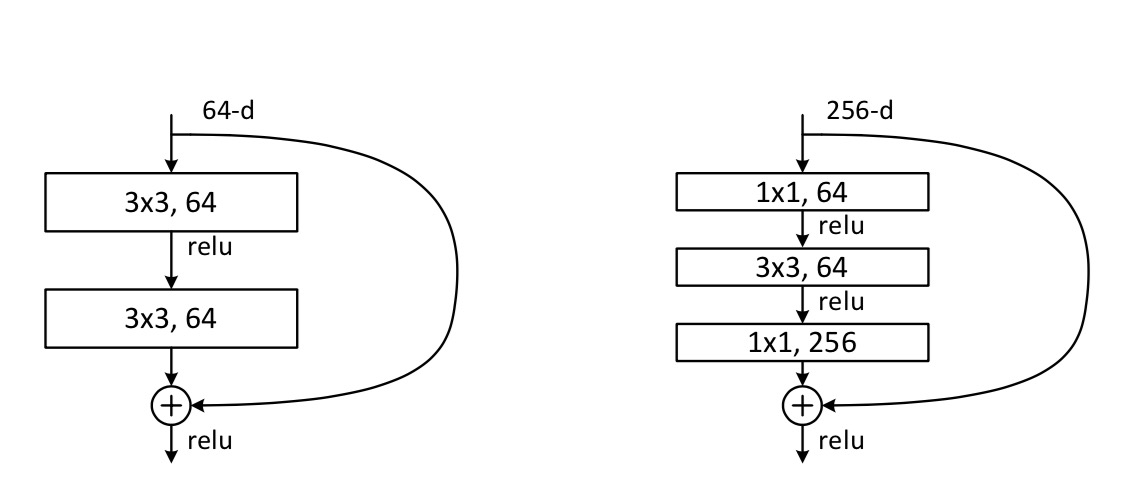
左边是BasicBlock,右边是Bottleneck。在resnet中,左图是resnet-18/34使用的,右图是resnet50/101/152使用的。
2.BasicBlock(左图)
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = BatchNorm2d(planes, momentum=BN_MOMENTUM)
self.relu = nn.ReLU(inplace=relu_inplace)
self.conv2 = conv3x3(planes, planes)
self.bn2 = BatchNorm2d(planes, momentum=BN_MOMENTUM)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
residual = self.downsample(x)
out = out + residual
out = self.relu(out)
return out
基本结构就是对应着左图来看
- 对于输入的参数,inplanes是输入维度, planes是第一个卷积的输出维度, stride和downsample来看resolution要不要下降。
- 跳层连接:当模块输入的分辨率与经过卷积处理的分辨率一致时,直接相加;当不一致时(stride!=1)需要使用downsample降低输入的分辨率再相加。
3.Bottleneck(右图)
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
self.bn1 = BatchNorm2d(planes, momentum=BN_MOMENTUM)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,
padding=1, bias=False)
self.bn2 = BatchNorm2d(planes, momentum=BN_MOMENTUM)
self.conv3 = nn.Conv2d(planes, planes * self.expansion, kernel_size=1,
bias=False)
self.bn3 = BatchNorm2d(planes * self.expansion,
momentum=BN_MOMENTUM)
self.relu = nn.ReLU(inplace=relu_inplace)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out = out + residual
out = self.relu(out)
return out
与BasicBlock基本相似,深度更深一些。
4.HighResolutionModule
这个类的功能是对每一个分辨率表示的分支进行特征提取。当只有一个分辨率分支时,就没有融合模块,直接返回结果。当有多个分支流的时候就需要先对各个分支进行计算,最后执行融合过程。
代码有点长,分解各个def来分析:
4.1 _check_branches
用来检查
4.2 _make_one_branch
对一个分支进行特征提取(对应下图中一个红框的部分)。在单个分支中,特征提取使用到数目为num_blocks的basicblock或者bottleblock(实际在开源代码中stage1是bottleblock,satge2-stage是basicblock)
- 先判断是否会downsample,写downsample模块(用在basicblock中)
- 搭建4个block,第一个block有可能会降维,后面3个block完全一致。
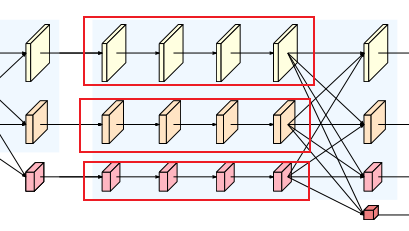
4.3 _make_branches
循环调用上面说的_make_one_branch函数,比如并行三列的话,就要调用三次。
4.4 _make_fuse_layers
进行低分辨率和高分辨率的融合。
- 如果只有一行,那就不用融合。
- 如果有并行结构,就要进行特征融合,以论文中给出的结构为例,这是要一个三分辨率融合至三分辨率的过程。
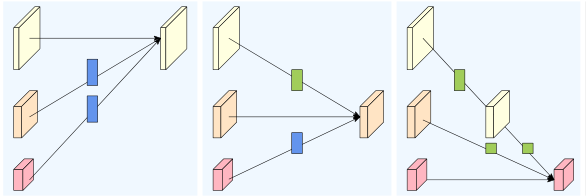
函数中嵌入了一个双层循环:一个变量i,一个变量j
如果i<j:那么,所有j分支都要上采样到和i分支一样分辨率。上采样的倍数即为:2^(j-i)倍
如果i=j:就是他本身
如果i>j:那么高分辨率的分支要到卷积下采样和i一样分辨率大小。这里又嵌套了一个循环k,是因为跨层下采样经过的卷积次数不一样,最后一次卷积不能加rule。
class HighResolutionModule(nn.Module):
def __init__(self, num_branches, blocks, num_blocks, num_inchannels,
num_channels, fuse_method, multi_scale_output=True):
super(HighResolutionModule, self).__init__()
self._check_branches(
num_branches, blocks, num_blocks, num_inchannels, num_channels)
self.num_inchannels = num_inchannels
self.fuse_method = fuse_method
self.num_branches = num_branches
self.multi_scale_output = multi_scale_output
self.branches = self._make_branches(
num_branches, blocks, num_blocks, num_channels)
self.fuse_layers = self._make_fuse_layers()
self.relu = nn.ReLU(inplace=relu_inplace)
def _check_branches(self, num_branches, blocks, num_blocks,
num_inchannels, num_channels):
if num_branches != len(num_blocks):
error_msg = 'NUM_BRANCHES({}) <> NUM_BLOCKS({})'.format(
num_branches, len(num_blocks))
logger.error(error_msg)
raise ValueError(error_msg)
if num_branches != len(num_channels):
error_msg = 'NUM_BRANCHES({}) <> NUM_CHANNELS({})'.format(
num_branches, len(num_channels))
logger.error(error_msg)
raise ValueError(error_msg)
if num_branches != len(num_inchannels):
error_msg = 'NUM_BRANCHES({}) <> NUM_INCHANNELS({})'.format(
num_branches, len(num_inchannels))
logger.error(error_msg)
raise ValueError(error_msg)
def _make_one_branch(self, branch_index, block, num_blocks, num_channels,
stride=1):
downsample = None
if stride != 1 or \
self.num_inchannels[branch_index] != num_channels[branch_index] * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.num_inchannels[branch_index],
num_channels[branch_index] * block.expansion,
kernel_size=1, stride=stride, bias=False),
BatchNorm2d(num_channels[branch_index] * block.expansion,
momentum=BN_MOMENTUM),
)
layers = []
layers.append(block(self.num_inchannels[branch_index],
num_channels[branch_index], stride, downsample))
self.num_inchannels[branch_index] = \
num_channels[branch_index] * block.expansion
for i in range(1, num_blocks[branch_index]):
layers.append(block(self.num_inchannels[branch_index],
num_channels[branch_index]))
return nn.Sequential(*layers)
def _make_branches(self, num_branches, block, num_blocks, num_channels):
branches = []
for i in range(num_branches):
branches.append(
self._make_one_branch(i, block, num_blocks, num_channels))
return nn.ModuleList(branches)
def _make_fuse_layers(self):
if self.num_branches == 1:
return None
num_branches = self.num_branches
num_inchannels = self.num_inchannels
fuse_layers = []
for i in range(num_branches if self.multi_scale_output else 1):
fuse_layer = []
for j in range(num_branches):
if j > i:
fuse_layer.append(nn.Sequential(
nn.Conv2d(num_inchannels[j],
num_inchannels[i],
1,
1,
0,
bias=False),
BatchNorm2d(num_inchannels[i], momentum=BN_MOMENTUM)))
elif j == i:
fuse_layer.append(None)
else:
conv3x3s = []
for k in range(i-j):
if k == i - j - 1:
num_outchannels_conv3x3 = num_inchannels[i]
conv3x3s.append(nn.Sequential(
nn.Conv2d(num_inchannels[j],
num_outchannels_conv3x3,
3, 2, 1, bias=False),
BatchNorm2d(num_outchannels_conv3x3,
momentum=BN_MOMENTUM)))
else:
num_outchannels_conv3x3 = num_inchannels[j]
conv3x3s.append(nn.Sequential(
nn.Conv2d(num_inchannels[j],
num_outchannels_conv3x3,
3, 2, 1, bias=False),
BatchNorm2d(num_outchannels_conv3x3,
momentum=BN_MOMENTUM),
nn.ReLU(inplace=relu_inplace)))
fuse_layer.append(nn.Sequential(*conv3x3s))
fuse_layers.append(nn.ModuleList(fuse_layer))
return nn.ModuleList(fuse_layers)
def get_num_inchannels(self):
return self.num_inchannels
def forward(self, x):
if self.num_branches == 1:
return [self.branches[0](x[0])]
for i in range(self.num_branches):
x[i] = self.branches[i](x[i])
x_fuse = []
for i in range(len(self.fuse_layers)):
y = x[0] if i == 0 else self.fuse_layers[i][0](x[0])
for j in range(1, self.num_branches):
if i == j:
y = y + x[j]
elif j > i:
width_output = x[i].shape[-1]
height_output = x[i].shape[-2]
y = y + F.interpolate(
self.fuse_layers[i][j](x[j]),
size=[height_output, width_output],
mode='bilinear', align_corners=ALIGN_CORNERS)
else:
y = y + self.fuse_layers[i][j](x[j])
x_fuse.append(self.relu(y))
return x_fuse
5.HighResolutionNet
这就是最后执行网络的地方。
这里同时也包括了OCR的内容。
就HRNet而言,具体过程可如下:
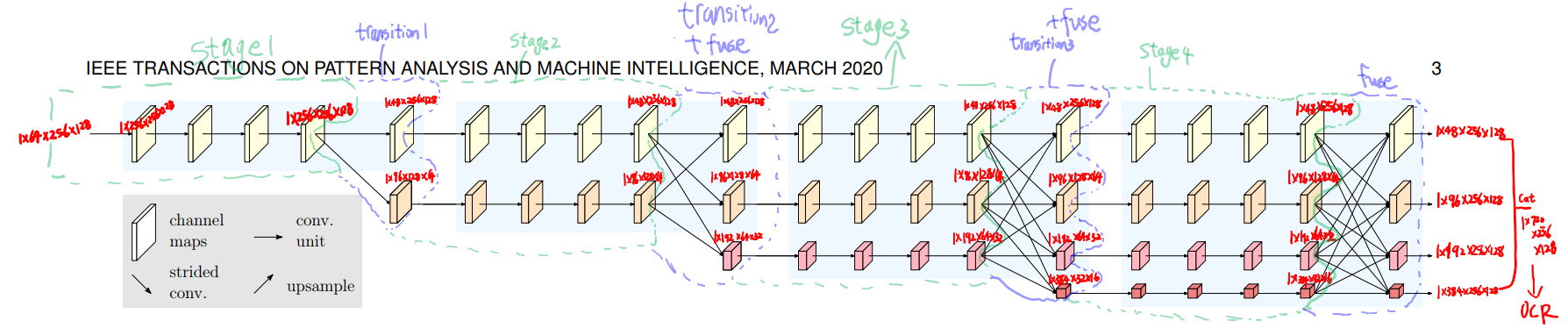
- 原图先降成1/4大小
- 执行1个stage1(4个block)
- 通过卷积生成1/2分辨率的流(现在有两条流)
- 执行1个stage2(两个流的4个block以及两个流之间交融)
- 通过卷积生成1/4分辨率的流(现在有三条流)
- 执行4个stage3(三个流的4个block以及三个流之间交融)
- 通过卷积生成1/8分辨率的流(现在有四条流)
- 执行3个stage4(四个流的4个block以及四个流之间交融)
- 上采样下面三条流,使之大小变回原大小,在concat拼接channel用于后续分割任务
class HighResolutionNet(nn.Module):
def __init__(self, config, **kwargs):
global ALIGN_CORNERS
extra = config.MODEL.EXTRA
super(HighResolutionNet, self).__init__()
ALIGN_CORNERS = config.MODEL.ALIGN_CORNERS
# stem net
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=2, padding=1,
bias=False)
self.bn1 = BatchNorm2d(64, momentum=BN_MOMENTUM)
self.conv2 = nn.Conv2d(64, 64, kernel_size=3, stride=2, padding=1,
bias=False)
self.bn2 = BatchNorm2d(64, momentum=BN_MOMENTUM)
self.relu = nn.ReLU(inplace=relu_inplace)
self.stage1_cfg = extra['STAGE1']
num_channels = self.stage1_cfg['NUM_CHANNELS'][0]
block = blocks_dict[self.stage1_cfg['BLOCK']]
num_blocks = self.stage1_cfg['NUM_BLOCKS'][0]
self.layer1 = self._make_layer(block, 64, num_channels, num_blocks)
stage1_out_channel = block.expansion*num_channels
self.stage2_cfg = extra['STAGE2']
num_channels = self.stage2_cfg['NUM_CHANNELS']
block = blocks_dict[self.stage2_cfg['BLOCK']]
num_channels = [
num_channels[i] * block.expansion for i in range(len(num_channels))]
self.transition1 = self._make_transition_layer(
[stage1_out_channel], num_channels)
self.stage2, pre_stage_channels = self._make_stage(
self.stage2_cfg, num_channels)
self.stage3_cfg = extra['STAGE3']
num_channels = self.stage3_cfg['NUM_CHANNELS']
block = blocks_dict[self.stage3_cfg['BLOCK']]
num_channels = [
num_channels[i] * block.expansion for i in range(len(num_channels))]
self.transition2 = self._make_transition_layer(
pre_stage_channels, num_channels)
self.stage3, pre_stage_channels = self._make_stage(
self.stage3_cfg, num_channels)
self.stage4_cfg = extra['STAGE4']
num_channels = self.stage4_cfg['NUM_CHANNELS']
block = blocks_dict[self.stage4_cfg['BLOCK']]
num_channels = [
num_channels[i] * block.expansion for i in range(len(num_channels))]
self.transition3 = self._make_transition_layer(
pre_stage_channels, num_channels)
self.stage4, pre_stage_channels = self._make_stage(
self.stage4_cfg, num_channels, multi_scale_output=True)
last_inp_channels = np.int(np.sum(pre_stage_channels))
ocr_mid_channels = config.MODEL.OCR.MID_CHANNELS
ocr_key_channels = config.MODEL.OCR.KEY_CHANNELS
self.conv3x3_ocr = nn.Sequential(
nn.Conv2d(last_inp_channels, ocr_mid_channels,
kernel_size=3, stride=1, padding=1),
BatchNorm2d(ocr_mid_channels),
nn.ReLU(inplace=relu_inplace),
)
self.ocr_gather_head = SpatialGather_Module(config.DATASET.NUM_CLASSES)
self.ocr_distri_head = SpatialOCR_Module(in_channels=ocr_mid_channels,
key_channels=ocr_key_channels,
out_channels=ocr_mid_channels,
scale=1,
dropout=0.05,
)
self.cls_head = nn.Conv2d(
ocr_mid_channels, config.DATASET.NUM_CLASSES, kernel_size=1, stride=1, padding=0, bias=True)
self.aux_head = nn.Sequential(
nn.Conv2d(last_inp_channels, last_inp_channels,
kernel_size=1, stride=1, padding=0),
BatchNorm2d(last_inp_channels),
nn.ReLU(inplace=relu_inplace),
nn.Conv2d(last_inp_channels, config.DATASET.NUM_CLASSES,
kernel_size=1, stride=1, padding=0, bias=True)
)
def _make_transition_layer(
self, num_channels_pre_layer, num_channels_cur_layer):
num_branches_cur = len(num_channels_cur_layer)
num_branches_pre = len(num_channels_pre_layer)
transition_layers = []
for i in range(num_branches_cur):
if i < num_branches_pre:
if num_channels_cur_layer[i] != num_channels_pre_layer[i]:
transition_layers.append(nn.Sequential(
nn.Conv2d(num_channels_pre_layer[i],
num_channels_cur_layer[i],
3,
1,
1,
bias=False),
BatchNorm2d(
num_channels_cur_layer[i], momentum=BN_MOMENTUM),
nn.ReLU(inplace=relu_inplace)))
else:
transition_layers.append(None)
else:
conv3x3s = []
for j in range(i+1-num_branches_pre):
inchannels = num_channels_pre_layer[-1]
outchannels = num_channels_cur_layer[i] \
if j == i-num_branches_pre else inchannels
conv3x3s.append(nn.Sequential(
nn.Conv2d(
inchannels, outchannels, 3, 2, 1, bias=False),
BatchNorm2d(outchannels, momentum=BN_MOMENTUM),
nn.ReLU(inplace=relu_inplace)))
transition_layers.append(nn.Sequential(*conv3x3s))
return nn.ModuleList(transition_layers)
def _make_layer(self, block, inplanes, planes, blocks, stride=1):
downsample = None
if stride != 1 or inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
BatchNorm2d(planes * block.expansion, momentum=BN_MOMENTUM),
)
layers = []
layers.append(block(inplanes, planes, stride, downsample))
inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(inplanes, planes))
return nn.Sequential(*layers)
def _make_stage(self, layer_config, num_inchannels,
multi_scale_output=True):
num_modules = layer_config['NUM_MODULES']
num_branches = layer_config['NUM_BRANCHES']
num_blocks = layer_config['NUM_BLOCKS']
num_channels = layer_config['NUM_CHANNELS']
block = blocks_dict[layer_config['BLOCK']]
fuse_method = layer_config['FUSE_METHOD']
modules = []
for i in range(num_modules):
# multi_scale_output is only used last module
if not multi_scale_output and i == num_modules - 1:
reset_multi_scale_output = False
else:
reset_multi_scale_output = True
modules.append(
HighResolutionModule(num_branches,
block,
num_blocks,
num_inchannels,
num_channels,
fuse_method,
reset_multi_scale_output)
)
num_inchannels = modules[-1].get_num_inchannels()
return nn.Sequential(*modules), num_inchannels
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.bn2(x)
x = self.relu(x)
x = self.layer1(x)
x_list = []
for i in range(self.stage2_cfg['NUM_BRANCHES']):
if self.transition1[i] is not None:
x_list.append(self.transition1[i](x))
else:
x_list.append(x)
y_list = self.stage2(x_list)
x_list = []
for i in range(self.stage3_cfg['NUM_BRANCHES']):
if self.transition2[i] is not None:
if i < self.stage2_cfg['NUM_BRANCHES']:
x_list.append(self.transition2[i](y_list[i]))
else:
x_list.append(self.transition2[i](y_list[-1]))
else:
x_list.append(y_list[i])
y_list = self.stage3(x_list)
x_list = []
for i in range(self.stage4_cfg['NUM_BRANCHES']):
if self.transition3[i] is not None:
if i < self.stage3_cfg['NUM_BRANCHES']:
x_list.append(self.transition3[i](y_list[i]))
else:
x_list.append(self.transition3[i](y_list[-1]))
else:
x_list.append(y_list[i])
x = self.stage4(x_list)
# Upsampling
x0_h, x0_w = x[0].size(2), x[0].size(3)
x1 = F.interpolate(x[1], size=(x0_h, x0_w),
mode='bilinear', align_corners=ALIGN_CORNERS)
x2 = F.interpolate(x[2], size=(x0_h, x0_w),
mode='bilinear', align_corners=ALIGN_CORNERS)
x3 = F.interpolate(x[3], size=(x0_h, x0_w),
mode='bilinear', align_corners=ALIGN_CORNERS)
feats = torch.cat([x[0], x1, x2, x3], 1)
out_aux_seg = []
# ocr
out_aux = self.aux_head(feats)
# compute contrast feature
feats = self.conv3x3_ocr(feats)
context = self.ocr_gather_head(feats, out_aux)
feats = self.ocr_distri_head(feats, context)
out = self.cls_head(feats)
out_aux_seg.append(out_aux)
out_aux_seg.append(out)
return out_aux_seg
手绘流程图:
1.原图先进去,先降成1/4大小。
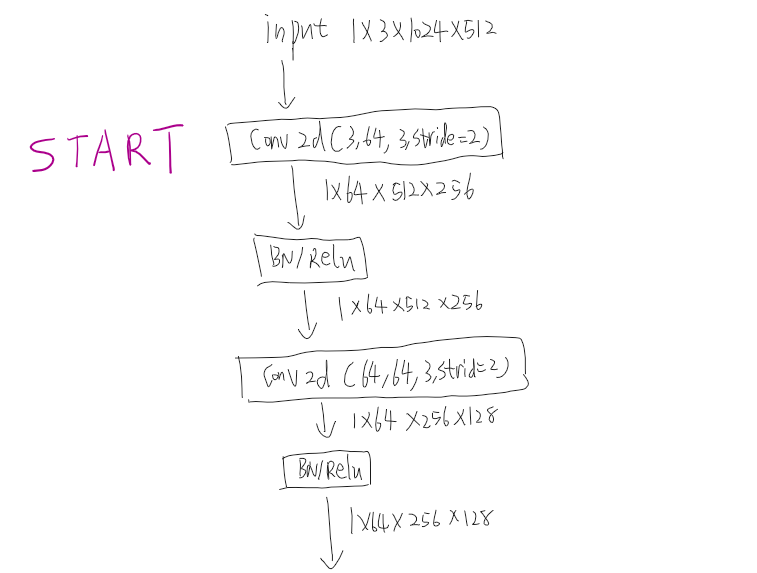
2.执行1个stage1(4个block)
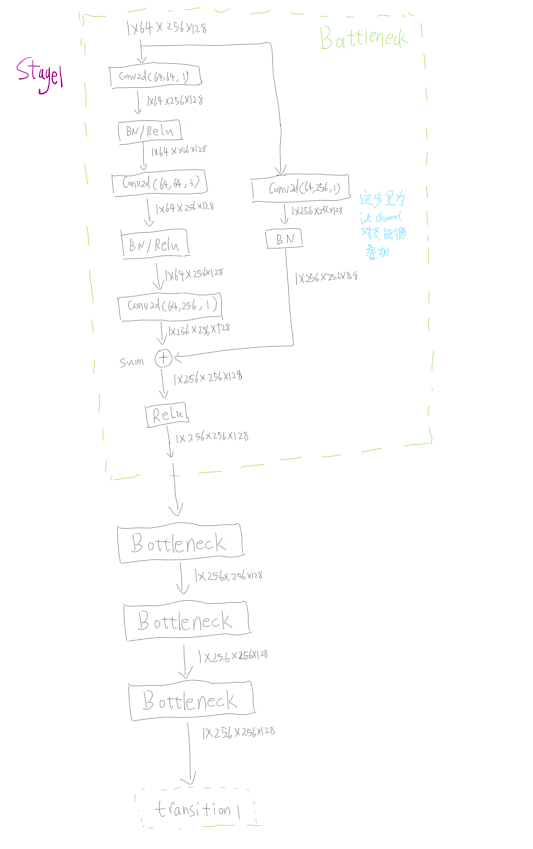
3.分支到两个流
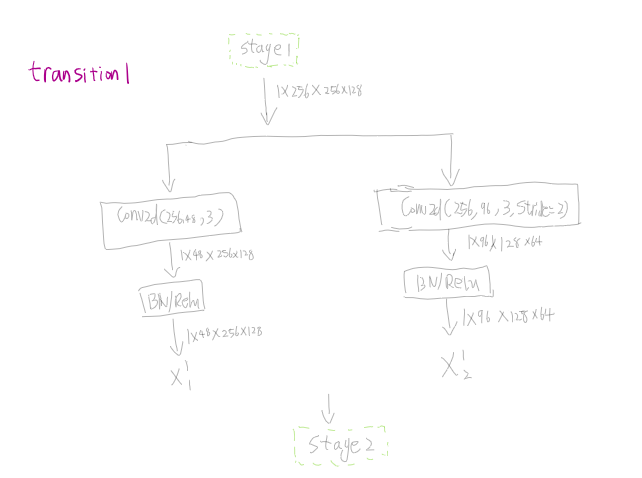
4.执行1个stage2(两个流的4个block以及两个流之间交融)
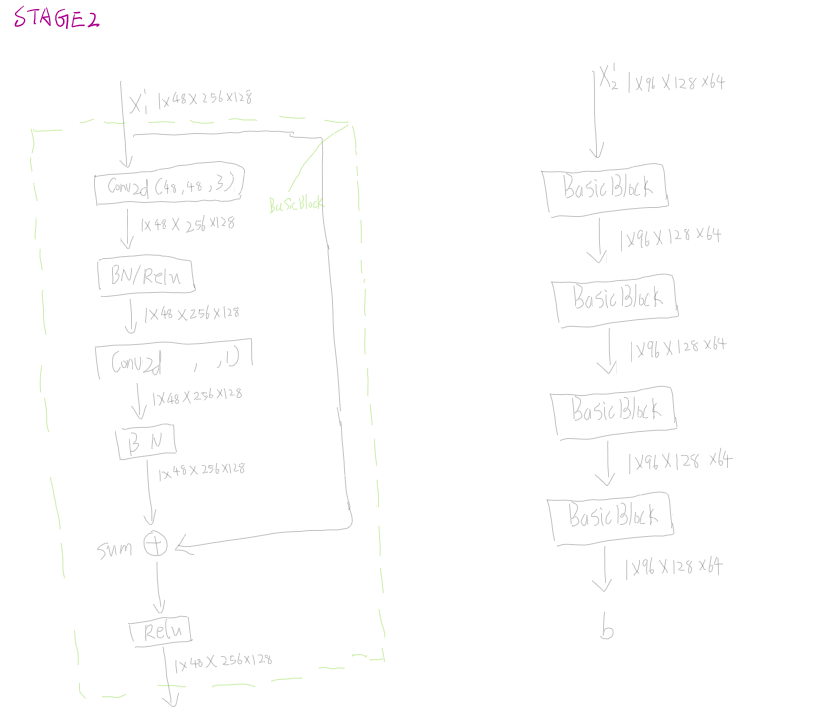

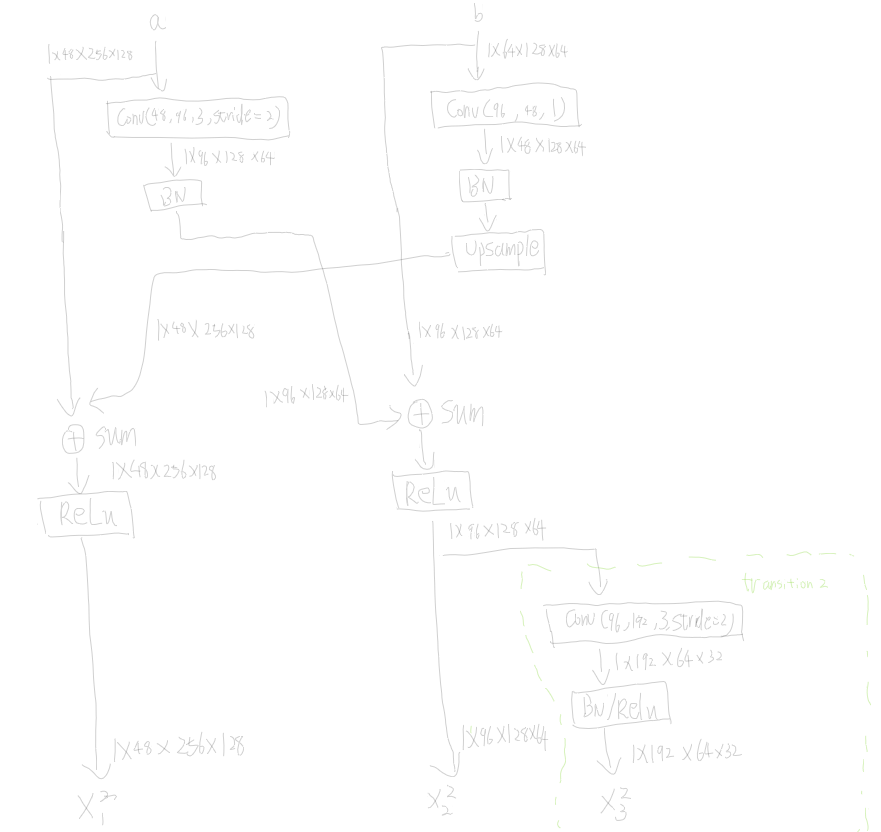
后面其实都很类似,就不放上来了。
版权声明:本文为CSDN博主「jqc8438」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/jqc8438/article/details/109984113






