文章目录[隐藏]
- 视觉招聘小黑板
- 行业资讯
- 奥普特获得实用新型专利授权:“一种检测光源及检测装置”--机器视觉网 2024-01-03 13:47:13
- 菲特技术汽车垫片自动检测方案--机器视觉网 2024-01-03 15:46:00
- 埃科万兆网相机与图像采集卡的卓越组合,助力轨道交通--机器视觉网 2024-01-03 15:29:13
- 中科行智3D飞点分光干涉仪,推动偏光片薄膜沟槽深度检测发展--机器视觉网 2024-01-03 15:11:53
- 嘉铭科技深度学习+缺陷检测,研发汽车发动机曲轴外观缺陷检测工作站--机器视觉网 2024-01-03 14:45:17
- 先临天远FreeScan UE获得海外用户青睐,高效助力半自磨机设备维修--机器视觉网 2024-01-03 14:27:34
- 光学系统的像质评价--机器视觉网 2024-01-03 14:05:53
- 安森美先进图像传感器如何提升行车安全--机器视觉网 2024-01-03 10:51:32
- 工业机器视觉/3D视觉行业分析和企业汇总-电子发烧友网 2024-01-03 16:23
- 捕捉“五彩斑斓的黑”:锗基短波红外相机的多种成像应用-电子发烧友网 2024-01-03 15:11
- 2024年中国锂电池行业十大预测-电子发烧友网 2024-01-02 11:48
- FLIR红外热像仪模块Lepton用于EOC早期火灾探测摄像机―新闻频道- 视觉系统设计 2024/1/3 9:14:25
- 赛恩领动融资研发4D成像雷达感知方案―新闻频道- 视觉系统设计 2024/1/3 9:05:21
- 搭载索尼IMX992的500万像素可见光至短波红外相机―产品聚焦频道- 视觉系统设计 2024/1/3 15:04:18
- 3CMOS棱镜式彩色面阵相机―产品聚焦频道- 视觉系统设计 2024/1/3 14:55:22
- 深入理解MVC-面向对象/设计原则/设计模式/代码重构-少有人走的路 2024-01-03 15:32:58
- CV不存在了?Meta出品!Segment Anything 2024-01-03 08:46
- 顶刊TNNLS!基于深度学习的SLAM最新最全综述! 2024-01-02 14:02
- CV计算机视觉每日开源代码Paper with code速览-2024.1.2 2024-01-03 00:32
- 助力自动驾驶下游任务!VehicleMAE:融合结构信息的预训练框架 2024-01-02 11:47
- 无痛涨点神器!谷歌和MIT最新提出SynCLR:视觉表示新方法 2024-01-02 22:52
- 学习单目视觉定姿原理 2024-01-02 23:06
- CVPR2023 | DynStF:一种用于激光雷达三维目标检测的高效特征融合策略 2024-01-03 08:32
- 清华大学最新NeuSurf,从稀疏输入视图重建高质量表面的深度学习方法 2024-01-02 14:04
- 首篇!浙大和理想汽车提出Street Gaussians:用于动态城市场景建模 2024-01-03 17:44
- 封神榜团队提出首个引入视觉细化器的多模态大模型Ziya-Visual-Lyrics,多个任务SOTA 2024-01-02 10:09
- 开源!FPN助力脉冲式ToF相机MPI校正精度突破5%! 2024-01-02 11:20
- 300+参考文献!清华&蔚来最新综述:单目重定位看这一篇就够了! 2024-01-02 14:01
- 训练难度降低!首次使用2D标签训练多视图3D Occupancy模型! 2024-01-02 14:10
- 左旺孟团队新作:将图像复原和增强任务与多重曝光图像相结合 2024-01-03 09:40
- By Jove, It’s No Myth: NVIDIA Triton Speeds Inference on Oracle Cloud: 2024-01-02T16:00:52+00:00
- Integrating ADAS with Keypoint Feature Pyramid Network for 3D LiDAR Object Detection: 2024-01-02T14:00:00+00:00
- 最新目标检测综述!参考文献103篇!浙江大学《深度学习低样本目标检测》少样本+零样本全面阐述! 2021-12-14 10:01
- 挑战和机遇!综述!微软等对《大规模深度学习服务系统》深度思考! 2021-12-07 10:26
- 重磅!中科大、微软亚研院提出PeCo: 视觉Transformer BERT新范式!性能超强! 2021-12-06 12:35
- 太强了!可实时、超分最新SOTA!自动搜索超神框架AutoML!入选顶会ICCV2021! 2021-12-01 14:52
- 厉害了!“人工智能”正名!人社部发布国家职业标准! 2021-11-29 18:48
- 完爆!北大、微软亚研院提出最强NÜWA(女娲)大统一模型!可同时应用于图像、视频、语义等!SOTA! 2021-11-26 12:38
- 颜水成博士最新论文简化Transformer!超简单的视觉模型PoolFormer!MetaFormer is Actually What You Need for Vision 2021-11-25 16:35
- 超神!一统天下!Florence算法创下40个SOTA记录!微软出品! 2021-11-24 16:51
- 总结更新Github!NeurlPS2021论文pdf和代码总结!NeurIPS2021pdf下载 2021-11-24 13:34
视觉招聘小黑板
欲了解详情,请在公众号后台回复:240103
行业资讯
奥普特获得实用新型专利授权:“一种检测光源及检测装置”--机器视觉网 2024-01-03 13:47:13
2024-01-03 13:47:13 来源: 中国机器视觉网
根据数据显示奥普特新获得一项实用新型专利授权,专利名为“一种AOI光源”,专利申请号为CN202321804498.8,授权日为2024年1月2日。
专利摘要:本实用新型公开了一种AOI光源,包括底座,所述底座上设有第一灯座,所述第一灯座包括第一安装面和第二安装面,所述第二安装面与所述第一安装面之间具有第一夹角,所述第一安装面上设有第一灯板,所述第二安装面上设有第二灯板;所述第一灯板和所述第二灯板的出射光线共同照射于一聚光区域。通过在具有夹角的第一安装面和第二安装面上分别装设第一灯板和第二灯板,使AOI光源同时具备不同角度的光线,能够实现不同类型的缺陷检测,提高检测的准确性。
今年以来奥普特新获得专利授权9个。结合公司2023年中报财务数据,
......长按二维码访问原文

菲特技术汽车垫片自动检测方案--机器视觉网 2024-01-03 15:46:00
2024-01-03 15:46:00 来源: 中国机器视觉网
前言
在汽车生产制造中,有很大一部分金属零件采用冲压加工成型的方法得到,冲压工艺是汽车生产的一种重要工艺方法。冲压加工具有生产效率高、成本低、精度一致性好和材料利用率高等特点。车身上的各类覆盖件,支撑件,紧固件等大量的汽车零部件都采用冲压工艺加工制造,冲压件在汽车零部件中占有很大比例,所以冲压加工方式的水平和能力,在很大程度上决定着我国汽车制造的成本和质量,也影响着其他包含冲压加工生产的行业的技术进步。
紧固件在日常生活中应用频繁,如常见的汽车垫片、平面轴承垫、金属薄片等。在冲压生产过程中因模具配合和振动等原因,不可避免的会产生一些瑕疵,如锈蚀、毛刺、缺料、多料、压伤等外观瑕疵;内径不圆、外径不圆、厚度不均等尺寸缺陷;若垫片带齿,还将产生
......长按二维码访问原文

埃科万兆网相机与图像采集卡的卓越组合,助力轨道交通--机器视觉网 2024-01-03 15:29:13
埃科万兆网相机与图像采集卡的卓越组合,助力轨道交通
2024-01-03 15:29:13 来源: 中国机器视觉网
作为机器视觉领域先锋企业,埃科光电精准把握市场需求,不断完善产品矩阵,相机接口涵盖GigE Vision、USB 3.0、Camera Link、CoaXPress、10GigE Vision等多种类型,为客户提供更多高性价比选择。
为何选择万兆网
万兆网产品具备数据带宽高、传输距离长、兼容性灵活等优势,其衍生的多种搭配方案可高效应对各类复杂的工业应用场景。
数据带宽高:相较于传统千兆网产品,万兆网数据带宽从1Gbps提升至10Gbps,在处理大量图像数据时,提供更快传输速率。
传输距离长:采用GigE、USB 3.0、Camera Link、CoaXPress等接口的工业相机,传输距
......长按二维码访问原文

中科行智3D飞点分光干涉仪,推动偏光片薄膜沟槽深度检测发展--机器视觉网 2024-01-03 15:11:53
2024-01-03 15:11:53 来源: 中国机器视觉网
液晶屏能够显示各种信息给人类,是现代电子技术、人工智能的重要基础单位,是人机交互的重要通道,具有十分重要的价值。液晶屏中最新的是源矩阵有机发光二级面板显示屏(amoled),因其特性受到了业界的广泛关注,其中偏光片是它的重要组成部分。偏光片分别由保护膜、三醋酸纤维素膜(TAC)、聚乙烯醇膜(PVA)、离型膜和压敏胶等结构层组成。在生产过程中,将原材料的膜通过拉伸、扩大等制作工艺,最终使偏光片整体透光效果均匀,从而为amoled的均匀发光效果提供保障。
偏光片是一种常见的偏振光学元件,应用非常广泛,在薄膜电晶体液体显示器(Thin Film Transistor Liquid Crystal Display,TFT-LCD)型液晶显示面板中,必有
......长按二维码访问原文

嘉铭科技深度学习+缺陷检测,研发汽车发动机曲轴外观缺陷检测工作站--机器视觉网 2024-01-03 14:45:17
2024-01-03 14:45:17 来源: 中国机器视觉网
曲轴是汽车发动机中一个重要的组成部分,它起着转换活塞运动为旋转动力的关键作用。因此曲轴的质量检查就显得尤为重要。嘉铭科技采用20多年来做缺陷检查经验,结合厂家的质量检测要求,研发出汽车发动机曲轴外观缺陷检测工作站。
工作站优点
· 自主研发检测系统:采用人工智能深度学习技术来解决汽车发动机曲轴外观缺陷检测,对汽车发动机曲轴的表面缺陷、定位孔、螺纹孔、法兰定位销等各个加工面进行检查分析,检测结果稳定可靠,维护简单。
· 智能识别加工件缺陷:对不同缺陷采用不同的算法进行识别,能实现汽车曲轴外加工面各种外观缺陷检测(淬火痕迹、毛刺、多肉、划伤、刮伤、污迹、铁粉残留、异物、铁锈、烧伤等)、尺寸测量、表面异物识别等,能全方位实现高效稳定的视觉
......长按二维码访问原文

先临天远FreeScan UE获得海外用户青睐,高效助力半自磨机设备维修--机器视觉网 2024-01-03 14:27:34
2024-01-03 14:27:34 来源: 中国机器视觉网
随着先临天远高精度三维扫描技术在工业制造中的不断普及,其也成为了全球各地制造企业中尺寸三维检测、产品维修维护的重要工具。本期,我们的案例,将讲述哥伦比亚用户使用FreeScan UE蓝色激光手持三维扫描仪进行大型半自磨机维修的应用。半自磨机或常被称为SAG半自磨机,常用于现代选矿厂的磨矿作业,可直接产出成品粒度或为下游磨矿段制备给料物料。
在本案例中,用户在使用半自磨机时发现,其在研磨过程中出现漏料的情况,这种情况存在员工的人身安全隐患,并且影响生产效率以及生产品质。经过进一步排查,用户发现半自磨机的出料口和入料口的耳轴出现了损坏,这也是可能导致漏料的主要原因。在此情况下,需要进行设备维修。
维修方案的核心技术之一,高精度三维扫描
一直以来
......长按二维码访问原文

光学系统的像质评价--机器视觉网 2024-01-03 14:05:53
2024-01-03 14:05:53 来源: 中国机器视觉网
在远心镜头、FA镜头等光学系统从设计到投入使用前,至少有两个阶段需要对工业镜头光学系统的成像质量进行客观评价。第一阶段,是指设计过程中,通过大量的光线追迹和衍射分析,对系统的成像情况进行仿真模拟;第二个阶段,是指工业镜头加工装配后,投入大批量生产之前,需要通过严格的实验来检测其实际成像效果。
因此往往需要多种的评价方法,才能客观全面地反映其实际性能。我们将要介绍五种传统的像质评价方法。
一、瑞利判断与波前图
瑞利判断与波前图都是根据波像差的大小来判断镜头光学系统的成像质量,即实际成像波面与理想波面在出瞳处相切时,两波面之间的光程差就是波像差。波像差越小,成像质量越好。
瑞利判断认为:”实际波面和理想球面波之间的最大波像差不超过λ/4时
......长按二维码访问原文

安森美先进图像传感器如何提升行车安全--机器视觉网 2024-01-03 10:51:32
2024-01-03 10:51:32 来源: 中国机器视觉网
尽管包括碰撞结构、安全气囊、刹车和轮胎在内的汽车技术不断进步,帮助提高了车辆安全性,但我们仍然面临着各种道路风险。而且,这些风险是不断变化的。低光照度等驾驶条件会显著增加道路危险性,而此类驾驶条件不仅给驾驶员带来挑战,同时也对车辆先进驾驶辅助系统 (ADAS) 中的传感器带来考验。在严苛的夜间和低光环境中,需要高性能汽车传感器来确保行车安全。
显而易见,在低光条件下,道路存在更大的风险。低光环境增加驾驶危险性的主要原因之一是人类视力的局限性。在黑暗条件下,驾驶员往往无法及时察觉风险,或者完全注意不到风险。而且,对向车灯会让驾驶员眩目,使问题变得更加严重。此外,驾驶员打瞌睡或酒后驾驶等因素,也会进一步增加风险。面对这些因素和环境条件,ADAS
......长按二维码访问原文

工业机器视觉/3D视觉行业分析和企业汇总-电子发烧友网 2024-01-03 16:23
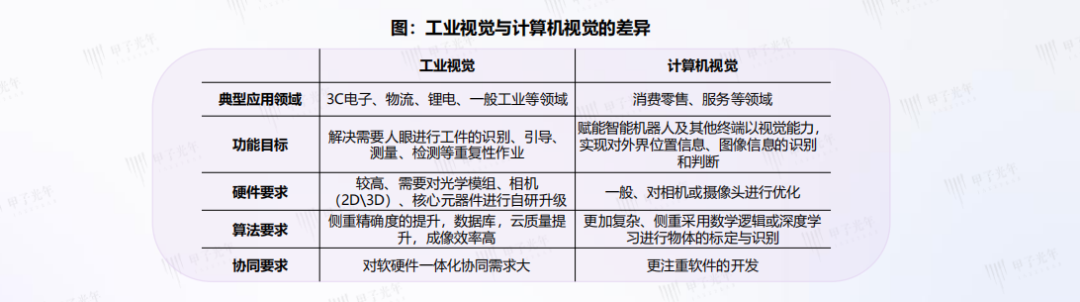
正文:
人工智能 的分支主要包括语音类技术、视觉类技术、自然语言处理技术和基础 硬件 等。视觉类技术在中国人工智能市场中占据最大的市场份额。
视觉类技术包含 机器视觉 和 计算机视觉 两个既有区别又有联系的概念。
资料 来源:甲子光年整理
计算机视觉(compu te r vision)是采用图像处理、模式识别、人工智能技术相结合的手段,实现一幅或多幅图像的计算机分析,而机器视觉(machinevision)偏重于计算机视觉技术工程化,旨在自动获取和分析特定的图像,以控制相应的行为。
具体来说,计算机视觉为机器视觉提供图像和景物分析的理论及 算法 基础,机器视觉为计算视觉的实现提供 传感器 、系统构造和实现手段。通俗地说,机器视觉就是用机器代替人眼。机器视觉 模拟 眼睛进行图像采集,经过图像识别和处理
......长按二维码访问原文

捕捉“五彩斑斓的黑”:锗基短波红外相机的多种成像应用-电子发烧友网 2024-01-03 15:11
红外 处于人眼可观察范围以外,为我们了解未知领域提供了新的途径。红外又可以根据波段范围,分为短波红外、中波红外与长波红外。较短的SWIR波长——大约900nm-1700nm——与可见光范围内的光子表现相似。虽然在SWIR中目标的光谱含量不同,但所产生的图像在其特征上仍然更加直观,而不像中红外和低红外波段的低分辨率热行为,这一优势更符合许多 工业 机器视觉 应用的需求。
与MWIR和LWIR相比,SWIR波长更短,可以获得更高的分辨率和更强的对比度,这两者都是检查和分选的重要标准。此外,虽然在SWIR运行的相机与可见光相机使用类似的光捕获技术,但它们收集的图像看起来与硅 传感器 捕获的图像非常不同——即使是在成像同一物体时。
通过SWIR相机,我们可以获取可见光范围内看不到的 信息 ,使其在机器视觉中的应用越
......长按二维码访问原文

2024年中国锂电池行业十大预测-电子发烧友网 2024-01-02 11:48
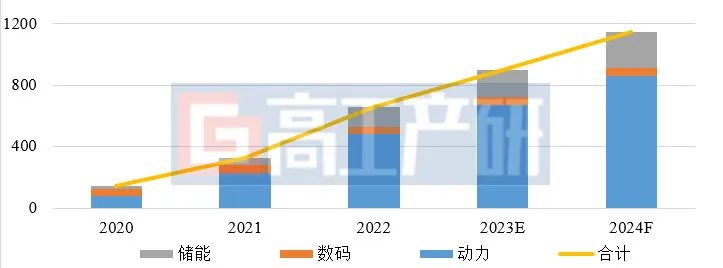
摘要
2024年 锂电池 产业链企业的机遇与挑战。
锂电产业链经过2020-2022年的急速扩张,2023年市场渐显“疲态”。市场疲态主要体现在三个方面:
1)新招标项目大幅减少;
2)企业目标完成率低;
3) 产品 价格腰斩。
从新招标项目来看,GGII调研数据显示,2023年锂电产业链全行业招标量较2022年下降5成左右。
从预定目标完成情况看,结合公开 资料 ,除少数企业外,2023年主机厂与电池厂年初设定的目标均未实现,产销量较好的企业能完成年初预定目标的60%以上,多数企业完成率在40-55%。其中,部分三线及以下企业已开始因产能过剩/客户缺乏/成本劣势等问题出现经营困难。
从产品价格来看,产业链各环节产品价格较年初已腰斩,锂盐等材料甚至降幅超过70%,导致产业链企业盈利能力大幅下降,
......长按二维码访问原文

FLIR红外热像仪模块Lepton用于EOC早期火灾探测摄像机―新闻频道- 视觉系统设计 2024/1/3 9:14:25
FLIR Lepton可为建筑环境和电动汽车充电站提供超灵敏的24/7早期火灾探测功能。
近期,Teledyne Technologies旗下的Teledyne FLIR宣布,韩国视频安全和热成像IP摄像机公司Eye on Cloud(EOC)将在其早期火灾探测(EFD)系列IP摄像机中采用Teledyne FLIR红外热成像仪模块Lepton。EOC推出的早期火灾探测系列产品,是“Thermal by FLIR”合作的一部分。
Teledyne FLIR红外热像仪模块Lepton在美国制造,并且不受《国际武器贸易条例》(ITAR)约束,是世界上产量甚高的长波红外(8 µm至14 µm)热成像模块。Lepton结构紧凑、经济高效,实现了各种热成像创新应用,已被数百万客户采用。Lepton提供多种分辨
......长按二维码访问原文

赛恩领动融资研发4D成像雷达感知方案―新闻频道- 视觉系统设计 2024/1/3 9:05:21
近日,赛恩领动完成亿元A+轮融资,由金浦投资、华强资本联合领投,A轮老股东蔚来资本与小米产投追加投资,资金将用于增加研发投入及持续推进产品工业化进程。
赛恩领动成立于2021年,是一家4D成像雷达感知方案研发商,业务范围包括研发4D成像雷达智能硬件、传感器算法及软件,以及基于人工智能的感知产品等。
赛恩领动消息显示,成立不到一年即完成两款S系列高性能雷达SIR-4K与SFR-2K的产品开发。今年3月斩获头部新能源车企全平台量产项目定点,凭借研发实力在市场行业密切关注下交出漂亮答卷。
4D成像雷达具备弥补图像传感器无法解决典型场景痛点的能力。如摄像头在雾天场景下,无法看清道路上障碍物;遇到侧翻车、异形车等无法正确识别;当物体的颜色与背景非常相似或对比度很低的情况下,图像传感器都会出现“看不清
......长按二维码访问原文

搭载索尼IMX992的500万像素可见光至短波红外相机―产品聚焦频道- 视觉系统设计 2024/1/3 15:04:18
AVAL DATA最近推出搭载索尼IMX992、IMX993图像传感器的500万像素相机,感光范围覆盖可见光到短波红外波段,是目前分辨率最高的相机之一。
......长按二维码访问原文

3CMOS棱镜式彩色面阵相机―产品聚焦频道- 视觉系统设计 2024/1/3 14:55:22
AP-3200T系列是3-CMOS棱镜式工业面阵扫描相机,具有3 x 320万像素。它可提供比传统拜耳彩色相机更佳的色彩保真度和空间分辨率,并专为机器视觉、生命科学和显微镜应用中的精准色彩成像和检查任务而设计。
棱镜式成像技术 vs 传统拜耳彩色成像技术
十分精准的彩色图像数据
借助特殊的棱镜式成像技术,入射光线被分为红色、绿色和蓝色波长,由三个精确对准的CMOS传感器捕捉。与使用拜耳马赛克技术的传统彩色相机相比,其色彩精确度和空间精度更高。
高分辨率与高帧速率结合
AP-3200T-10GE 围绕三个Sony Pregius IMX252传感器进行构建。此机器视觉相机与 GigE Vision 接口结合,可在全分辨率下以12帧/秒的速度输出高达3 x 320万像素。
灵活的颜色空间转换
AP-3
......长按二维码访问原文

深入理解MVC-面向对象/设计原则/设计模式/代码重构-少有人走的路 2024-01-03 15:32:58
勇哥注:
此为引用文章,见:https://zhuanlan.zhihu.com/p/35680070
文章尾有勇哥的阅读注释。
MVC无人不知,可很多程序员对MVC的概念的理解似乎有误,换言之他们一直在错用MVC,尽管即使如此软件也能被写出来,然而软件内部代码的组织方式却是不科学的,这会影响到软件的可维护性、可移植性,代码的可重用性。
MVC即Model、View、Controller即模型、视图、控制器。我在和同行讨论技术,阅读别人的代码时发现,很多程序员倾向于将软件的业务逻辑放在Controller里,将数据库访问操作的代码放在Model里。
最终软件(网站)的代码结构是,View层是界面,Controller层是业务逻辑,Model层是数据库访问。
不知道大家知不知道
......长按二维码访问原文

CV不存在了?Meta出品!Segment Anything 2024-01-03 08:46
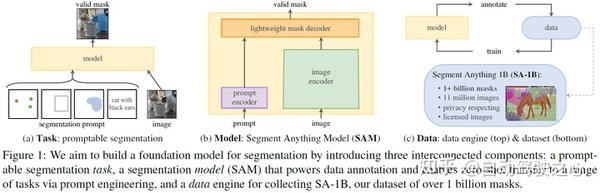
摘要
本文介绍了Segment Anything(SA)项目:一个用于图像分割的新任务、模型和数据集。在数据收集循环中使用论文的高效模型,本文建立了迄今为止最大的分割数据集(到目前为止),在1100万张许可和尊重隐私的图像上有超过10亿个mask。该模型被设计和训练为可提示的,因此它可以将零样本转换为新的图像分布和任务。作者评估了其在许多任务上的能力,发现其零样本性能令人印象深刻,通常与之前的完全监督结果相竞争,甚至优于这些结果。开源地址:https://segment-anything.com/
关注知乎@自动驾驶之心,第一时间获取自动驾驶感知/定位/融合/规控等行业最新内容
简介
在网络规模数据集上预先训练的大型语言模型正以强大的零样本和较少的样本泛化革新NLP[10]。这些“基础模型”[8]可以推
......长按二维码访问原文

顶刊TNNLS!基于深度学习的SLAM最新最全综述! 2024-01-02 14:02
1. 笔者个人体会
现在SLAM无论在学术界还是工业界或多或少都要结合深度学习,以数据驱动的方式提供了手工算法的替代方案。今天笔者为大家分享一篇基于深度学习的SLAM综述,引用了256篇参考文献,总结的非常全面!
下面一起来阅读一下这项工作~
2. 文章结构
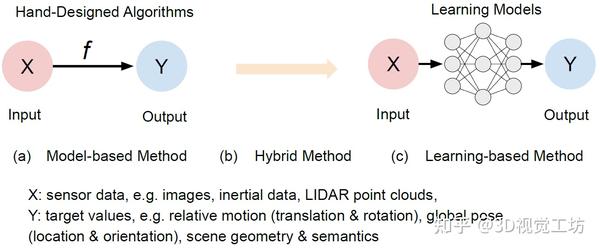
这篇文章提出了使用深度学习的SLAM方法的分类法,讨论了两个基本问题:深度学习是否有望用于定位和建图、应该如何应用深度学习来解决这个问题。包括基于学习的视觉里程计、全局重定位、地图创建以及SLAM几大主题。
基于深度学习的SLAM分类,每个单独的模块可以集成到一个完整的基于深度学习的SLAM系统中。在发愁创新点的同学可以逐一参考。
基于深度学习的视觉里程计(增量运动估计)方法列举:
基于深度学习的2D地图重定位方法总结:
基于深度学习的三维
......长按二维码访问原文

CV计算机视觉每日开源代码Paper with code速览-2024.1.2 2024-01-03 00:32
精华置顶
墙裂推荐!小白如何1个月系统学习CV核心知识:链接
点击@CV计算机视觉,关注更多CV干货
论文已打包,点击进入—>下载界面
点击加入—>CV计算机视觉交流群
1.【医学图像分割】Narrowing the semantic gaps in U-Net with learnable skip connections: The case of medical image segmentation
2.【超分辨率重建】Perception-Distortion Balanced Super-Resolution: A Multi-Objective Optimization Perspective
3.【多模态】Gemini vs GPT-4V: A Preliminary Comparis
......长按二维码访问原文

助力自动驾驶下游任务!VehicleMAE:融合结构信息的预训练框架 2024-01-02 11:47

1.写在前面
了解图像中的车辆对于自动驾驶系统来说非常重要。但现有的以车辆为中心的工作通常在大规模分类数据集上预训练模型,然后针对特定的下游任务进行微调。然而,它们忽略了不同任务中车辆感知的特定特征,因此可能导致次优性能。
为了解决这个问题,VehicleMAE提出了一种新的以车辆为中心的预训练框架,该框架结合了结构信息,包括来自车辆轮廓信息的空间结构和来自信息丰富的高级自然语言描述的语义结构,用于有效的掩码车辆外观重建。这项工作也被AAAI 2024录用。
下面一起来阅读一下这项工作~
2.效果展示
车辆外观重建效果对比:
这篇文章也建立了一个大规模的数据集Autobot1M,包含约100万张车辆图像和12693条文本信息。但是似乎暂时没有开源数据集。
3.具体原理是什么?
VehicleMA
......长按二维码访问原文

无痛涨点神器!谷歌和MIT最新提出SynCLR:视觉表示新方法 2024-01-02 22:52
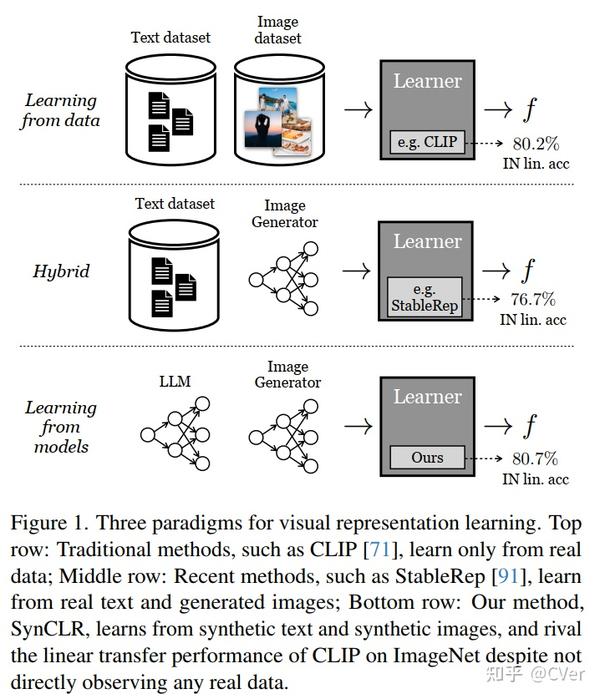
2024年,合成数据依然是顶流!本文提出SynCLR:一种新的视觉表征学习范式——从生成模型中学习。在不使用任何真实数据的情况下,SynCLR学习的视觉表示与最先进的通用视觉表示学习者(如DINOv2、OpenCLIP)所获得的视觉表示相当。代码刚刚开源!
点击关注 @CVer官方知乎账号,可以第一时间看到最优质、最前沿的CV、AI工作~
SynCLR
Learning Vision from Models Rivals Learning Vision from Data
单位:谷歌, MIT
代码:https://github.com/google-research/syn-rep-learn
论文:https://arxiv.org/abs/2312.17742
SynCLR:一种专门从合成图
......长按二维码访问原文

学习单目视觉定姿原理 2024-01-02 23:06
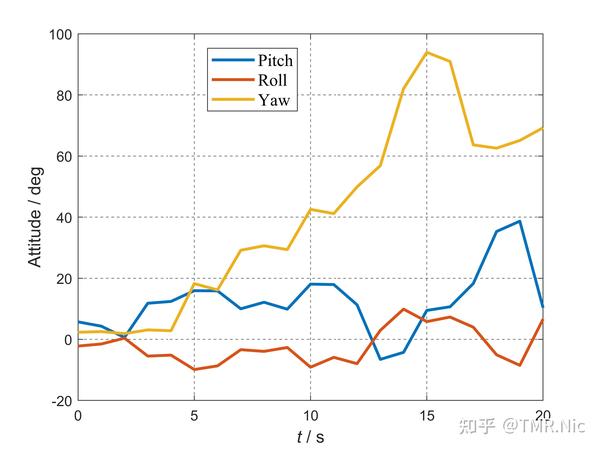
问题和思考
自己采集了一些数据,然后找网上的代码实现了单目视觉定姿。只是把基本流程过了一遍,了解以下单目视觉定姿是什么,没有处理细节问题。如果是想要开始视觉导航学习,或者像我一样,单纯是闲下来玩点不一样的东西,可以看看我的学习过程。
但是在玩单目视觉导航的过程中,发现了一些问题:
相机和IMU的时间同步问题(数据量大,传输存储都比较费时,同步不好做)
相机数据处理/传输问题,一般的MCU或者DSP可以正常处理图像数据吗?
分辨率和帧率问题,分辨率高时,定姿数据处理结果会好一些,更加准确而且稳定,低分辨率更加适合实时数据处理,但是处理结果会差一些
我目前是1s采集一次,视觉数据1Hz的频率可能无法应用于实际系统,还是计算能力有限和实时性需要之间的矛盾
单目视觉定姿的误差比较随机,有时候会存在零偏,可
......长按二维码访问原文

CVPR2023 | DynStF:一种用于激光雷达三维目标检测的高效特征融合策略 2024-01-03 08:32
原文-- DynStatF: An Efficient Feature Fusion Strategy for LiDAR 3D Object Detection
为什么提出这个方法?
早期工作一般用多个先前帧增强激光雷达输入提供了更丰富的语义信息,从而提高了3D目标检测的性能。然而,由于运动模糊和不准确的点投影,多帧中拥挤的点云可能会损害精确的位置信息。这篇工作作者提出了一种新的特征融合策略DynSTF(动态-静态融合),它利用当前单帧(静态分支)的准确位置信息增强了多帧(动态分支)提供的丰富语义信息。为了有效地提取和聚合互补功能,DynSTF包含两个模块,即Neighborhood 交叉关注(NCA)和动态静态交互(DSI),通过双路径架构运行。NCA将静态分支中的特征作为查询,将动态分
......长按二维码访问原文

清华大学最新NeuSurf,从稀疏输入视图重建高质量表面的深度学习方法 2024-01-02 14:04
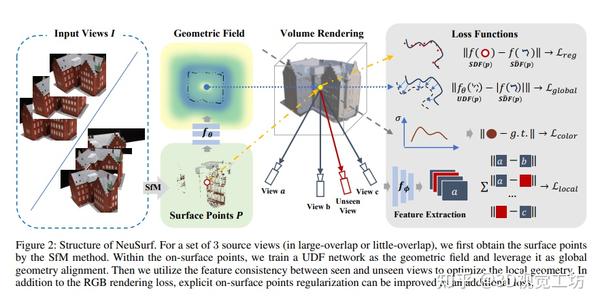
本文涉及的研究探讨了神经隐式函数在稀疏视角重建中的应用。提出了一种新的稀疏视角重建框架,利用表面先验信息来实现高度准确的表面重建。该框架设计了全局几何对齐和局部几何细化的约束条件,共同优化粗略形状和精细细节。采用神经网络学习全局隐式场,并将其作为粗略几何约束,同时利用局部几何一致性,将表面点投影到不同视角上,以捕捉精细几何约束。实验结果表明,该方法在两种常见的稀疏设置下,使用DTU和BlendedMVS数据集,相比现有最先进的方法,取得了显著的改进。
读者理解
该篇文章提出了一种新的神经网络方法,用于从稀疏输入的视图中重建表面。该方法结合了表面的先验知识和深度学习技术。
先验知识涵盖了表面的平滑性、连续性和光滑性等特征。这些知识是通过训练神经网络从大量数据中学习得到的,这种学习使得模型能够理解并利用这些特
......长按二维码访问原文

首篇!浙大和理想汽车提出Street Gaussians:用于动态城市场景建模 2024-01-03 17:44

3D GS将在2024年大杀四方!冲啊!把NeRF应用的领域再用3DGS刷一遍,前期篇篇都是First!然后后面还可以继续优化,"大坑"可踩!
本文提出了Street Gaussians:一种用于动态城市街景建模的新显式场景表示,可以解决大量现有限制(训练、渲染速度慢、高精度需求等),允许在训练半小时内以 133 FPS(1066×1600 分辨率)进行场景编辑操作和渲染,性能表现出色!代码即将开源!
点击关注 @CVer官方知乎账号,可以第一时间看到最优质、最前沿的CV、AI工作~
Street Gaussians
Street Gaussians for Modeling Dynamic Urban Scenes
单位:浙江大学, 理想汽车
主页:https://zju3dv.github.io
......长按二维码访问原文

封神榜团队提出首个引入视觉细化器的多模态大模型Ziya-Visual-Lyrics,多个任务SOTA 2024-01-02 10:09
多模态大模型在输入输出上涵盖了图像、音频、视频等模态,让大模型超越了大语言模型的范畴,为大模型赋予了更强大的功能。如最近引起广泛关注的GPT4V、Gemini等,就让人们看到了多模态大模型的更多价值和可能性。在此背景下,业界对多模态大模型的研究不断深入,多模态大模型相关技术也随之不断发展突破。
封神榜大模型团队基于在多模态领域积累的先进技术,首次在多模态大模型上加入图像标记、目标检测、语义分割模块,推出了多模态大模型Ziya-Visual-Lyrics。评测结果显示,Ziya-Visual-Lyrics在跟开源多模态大模型的对比中取得多个零样本任务SOTA,模型效果亮眼。
欢迎大家点击下方链接下载,也可通过魔搭创空间、HuggingfaceSpace体验我们的模型,与我们分享你的使用感受!
......长按二维码访问原文

开源!FPN助力脉冲式ToF相机MPI校正精度突破5%! 2024-01-02 11:20
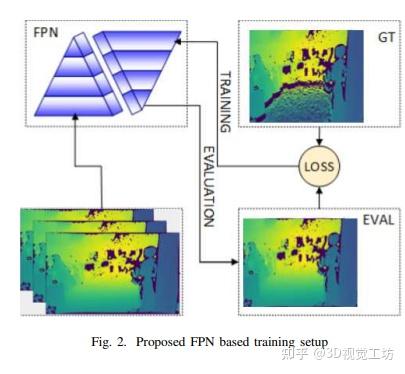
本文主要研究了时间飞行(ToF)摄像头的多径推断(MPI)问题,并使用特征金字塔网络(FPN)进行了解决。ToF摄像头因其高帧率、相对良好的精度和降低的成本而在不同领域得到广泛应用。然而,其面临着包括杂散噪声和MPI在内的问题。MPI可能导致在曲面上表现出变形表面,而不是平面表面,给标准的空间数据预处理带来了困难。本文通过设计端到端网络,成功利用基于真实ToF数据的学习方法减弱了MPI对平面表面的影响,为解决这一问题提供了一种新的途径。
读者理解:
我认为这篇文章的研究工作很有意义,提出的基于FPN的MPI校正方法具有以下优点:
够有效地校正MPI误差。文章的实验结果表明,该方法能够将MPI误差降低到5%以下,这是一个非常可观的效果。
具有很强的鲁棒性。文章采用了FPN来提取图像特征,FPN能够在不同尺
......长按二维码访问原文

300+参考文献!清华&蔚来最新综述:单目重定位看这一篇就够了! 2024-01-02 14:01
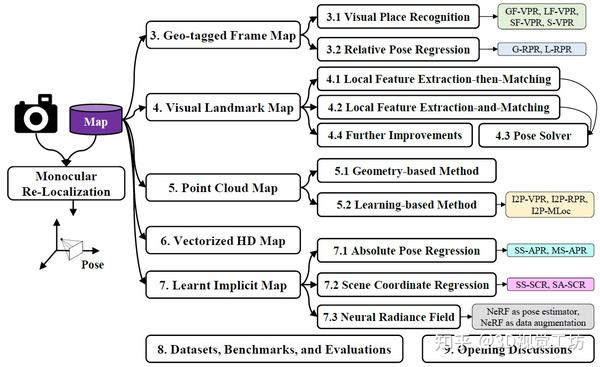
0. 这篇综述希望解决什么问题?
单目重定位(MRL)基于单目图像估计场景地图的6自由度姿态,许多地标算法在定位精度和抗视觉干扰的鲁棒性方面取得了相当大的进展。在MRL研究中,场景地图以各种形式呈现,决定了MRL方法如何工作,甚至MRL方法如何执行。
然而现有综述并没有从地图的角度对MRL进行系统的回顾,因此这篇综述填补了这一空白。最重要的是,这篇综述还挂上了github来提供相应的论文和数据集,并且会持续更新。
下面一起来阅读一下这项工作,文末附论文和Github链接~
1. 这篇综述的框架结构是什么样的?
这篇文章的框架结构是:
(1)首先深入研究MRL的问题定义,探索当前的挑战,同时将这篇文章与之前发表的文章进行比较;
(2)根据所用地图的形式,将MRL方法分成5类,包括地理标记框架、视觉地
......长按二维码访问原文

训练难度降低!首次使用2D标签训练多视图3D Occupancy模型! 2024-01-02 14:10
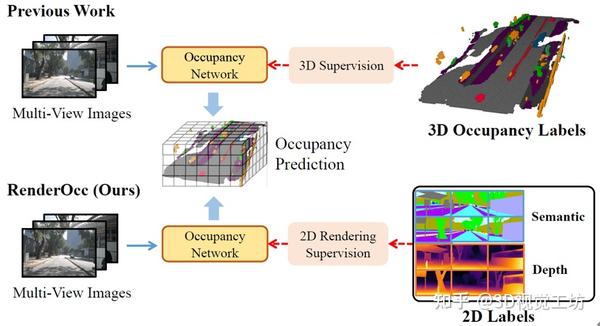
0. 笔者个人体会
3D占用预测将3D场景量化为带有语义标签的网格单元,但是3D标签的注释非常繁琐,而且很多标签类别并不明确,所以很难去训练3D Occupancy的大模型。
今天笔者为大家分享一项工作RenderOcc,仅使用2D标签就可以训练3D占用模型,算是提供了一种新范式!
下面一起来阅读一下这项工作,文末附论文和代码链接~
1. 这篇文章希望解决什么问题?
以前方法使用昂贵的3D占用标签进行监督,而RenderOcc使用2D标签来训练3D占用网络,实际使用的是细粒度的2D像素级语义和深度监督。
2. 具体原理是什么?
RenderOcc从多视图图像中提取NeRF风格的3D体素表示,建立每个体素的密度和语义信息,并采用体渲染技术来建立2D渲染,从而实现从2D语义和深度标签的直接3D监督。
......长按二维码访问原文

左旺孟团队新作:将图像复原和增强任务与多重曝光图像相结合 2024-01-03 09:40

本文使用bracketing摄影来统一图像恢复和增强任务,包括图像去噪、去模糊、高动态范围重建和超分辨率等,性能表现出色!并构建了一个数据模拟pipeline来合成成对的图像,代码即将开源!
点击关注 @CVer官方知乎账号,可以第一时间看到最优质、最前沿的CV、AI工作~
Bracketing is All You Need: Unifying Image Restoration and Enhancement Tasks with Multi-Exposure Images
单位:哈工大(左旺孟团队)
代码:https://github.com/cszhilu1998/BracketIRE
论文:https://arxiv.org/abs/2401.00766
在弱光环境中获取具有清晰内容的高质
......长按二维码访问原文

By Jove, It’s No Myth: NVIDIA Triton Speeds Inference on Oracle Cloud: 2024-01-02T16:00:52+00:00
An avid cyclist, Thomas Park knows the value of having lots of gears to maintain a smooth, fast ride.
So, when the software architect designed an AI inference platform to serve predictions for Oracle Cloud Infrastructure’s (OCI) Vision AI service, he picked NVIDIA Triton Inference Server. That’s because it can shift up, down or sideways to handle virtually
......长按二维码访问原文

Integrating ADAS with Keypoint Feature Pyramid Network for 3D LiDAR Object Detection: 2024-01-02T14:00:00+00:00
3D LiDAR object detection is a process that assists with identifying and localizing objects of interest in a 3-dimensional space. In autonomous systems and advanced spatial analysis, the evolution of object detection methodologies has been pivotal. Among these technologies, 3D LiDAR object detection is a transformative approach, offering unprecedented accura
......长按二维码访问原文

最新目标检测综述!参考文献103篇!浙江大学《深度学习低样本目标检测》少样本+零样本全面阐述! 2021-12-14 10:01
哈喽,我是 @Sophia ,刚刚看到一篇综述,是2021年12月刚出来的《A Survey of Deep Learning for Low-Shot Object Detection》,参考文献103篇,浙江大学出品!低样本目标检测(Low-Shot Object Detection, LSOD)旨在从少量甚至零标记数据中检测目标,可分为少样本目标检测(few-shot Object Detection, FSOD)和零样本目标检测(zero-shot Object Detection, ZSD)。本文对基于FSOD和ZSD的深度学习进行了全面的研究。
论文链接:https://arxiv.org/pdf/2112.02814.pdf
摘要:
本文整体框架
One-shot 目标检测
two-st
......长按二维码访问原文

挑战和机遇!综述!微软等对《大规模深度学习服务系统》深度思考! 2021-12-07 10:26
哈喽,我是 @Sophia ,看到一篇好文章,《A Survey of Large-Scale Deep Learning Serving System Optimization: Challenges and Opportunities》本综述旨在总结和分类大规模深度学习服务系统出现的挑战和优化机会。通过提供一种新颖的分类方法,总结计算范式,阐述最新的技术进展!文章2021年11月刚出来!
文章链接:https://arxiv.org/pdf/2111.14247v1.pdf
摘要:
总结:
这做的太好了,我都想放PPT了
文章的图表太丰富了,真是好文章,值得好好学习
我是 @Sophia ,一起学习进步!
往期论文推荐学习:
重磅!中科大、微软亚研院提出PeCo: 视觉Transformer
......长按二维码访问原文

重磅!中科大、微软亚研院提出PeCo: 视觉Transformer BERT新范式!性能超强! 2021-12-06 12:35
哈喽,我是 @Sophia ,今天推荐一篇重量级文章!来自中国科学技术大学、微软亚研等机构的研究者提出了学习感知 codebook( perceptual codebook ,PeCo),用于视觉 transformer 的 BERT 预训练!使用 ViT-B 主干在 ImageNet-1K 上实现了 84.5% 的 Top-1 准确率,在相同的预训练 epoch 下比 BEiT 高 1.3。此外,该方法还可以将 COCO val 上的目标检测和分割任务性能分别提高 +1.3 box AP 和 +1.0 mask AP,并且将 ADE20k 上的语义分割任务提高 +1.0 mIoU。效果强悍!文章刚出来!
论文链接:https://arxiv.org/pdf/2111.12710v1.pdf
开源地址:ht
......长按二维码访问原文

太强了!可实时、超分最新SOTA!自动搜索超神框架AutoML!入选顶会ICCV2021! 2021-12-01 14:52
哈喽,我是 @Sophia ,刚刚发现一篇重量级文章!作者将网络结构搜索与剪枝搜索相结合,提出了全新的自动搜索框架。该稀疏模型能够在移动设备上实时且高质量地处理视频超分辨率任务!实验实现了在移动端(三星Galaxy S20)部署720p实时超清(每帧仅需数十毫秒)!文章入选ICCV2021,刚刚出来!
论文链接:https://arxiv.org/pdf/2108.08910.pdf
摘要:
权重剪枝:
a)非结构化的权重剪枝;(b)粗粒度的结构化权重剪枝;(c)细粒度的结构化权重剪枝-基于块;(d)细粒度的结构化权重剪枝-基于模式
整体框架:
(a)超级网络构建;(b)编译器感知的结构和剪枝搜索;(c)编译器感知的压缩倍率的搜索
算法流程
效果对比:
文章附录补充说明
这篇文章真是很厉害,
......长按二维码访问原文

厉害了!“人工智能”正名!人社部发布国家职业标准! 2021-11-29 18:48
哈喽,我是 @Sophia ,看新闻竟然看到了《国家职业技能标准》,有关咱们“人工智能训练师”!看来国家已经开始布局了,慢慢就有高级工程师,中级工程师等级别了!真是秀啊!
国家人力资源社会保障部(以下简称人社部)发布了《人工智能训练师》国家职业技能标准。
人社部发布《人工智能训练师》国家职业技能标准
本次发布的「人工智能训练师」职业技能标准也分为五个等级:从数据采集和处理、数据标注、智能系统运维、业务分析、智能训练、智能系统设计等维度,划分出 L5-L1 五个等级,并对各个等级的职业能力给出了具体的描述和要求。
从「五级 / 初级工」到「一级 / 高级技师」,人工智能训练师的职业技能要求依次递进。
在理论知识考试中,不同技能等级在理论知识上的要求是不同的,五级和四级制涵盖「数据
......长按二维码访问原文

完爆!北大、微软亚研院提出最强NÜWA(女娲)大统一模型!可同时应用于图像、视频、语义等!SOTA! 2021-11-26 12:38
大家好,我是 @Sophia ,刚刚发现一篇特别厉害的文章!“女娲”模型!MSRA和北京大学共同出品!该模型在多个训练集上SOTA!该模型可以应用于计算机视觉和自然语言处理!已经开源!!!是2021年11月刚更新的!标题有亮点,竟然是彩色的,哈哈哈
论文链接:https://arxiv.org/abs/2111.12417
代码地址:https://github.com/microsoft/NUWA
摘要:
8种典型应用场景!
女娲模型架构!
与最先进的模型进行对比!
效果统计
做了太多实验了!图表也太太太丰富了!真是值得好好学习!
我是 @Sophia ,关注我一起学习进步!
往期论文推荐学习:
颜水成博士最新论文简化Transformer!超简单的视觉模型PoolFormer!
超神
......长按二维码访问原文

颜水成博士最新论文简化Transformer!超简单的视觉模型PoolFormer!MetaFormer is Actually What You Need for Vision 2021-11-25 16:35
大家好,我是 @Sophia ,刚刚逛的时候发现颜水成老师刚刚更新了一篇论文《MetaFormer is Actually What You Need for Vision》,题目很有意思,一看就知道和Transformer有关了!他们团队将注意力机制模块进行替换,间接证明了Transformer其实优势在于其架构!这点很新颖了!文章2021年11月刚出来!
论文链接: https://arxiv.org/abs/2111.11418
代码链接: https://github.com/sail-sg/poolformer
摘要:
替换结构和效果:
伪代码
PoolFormer架构
参数信息
对比效果
文章思路说简单也简单,就是一个替换
但是实验做的还是很详尽的,并且证明了我们一直疑惑的内容,
......长按二维码访问原文

超神!一统天下!Florence算法创下40个SOTA记录!微软出品! 2021-11-24 16:51

大家好,我是 @Sophia ,刚刚发现了一个超牛的算法,能够应用于计算机视觉,目标检测,图像文本等等等,并且在多个数据集刷新了记录!文章是最新出来的!
论文链接:https://arxiv.org/pdf/2111.11432.pdf
摘要:
多模态探索
Florence框架
效果:
真是看了以后就知道为什么有这么多作者了,做的实验太多了,并且效果太好了!
真是一篇好文章,值得好好学习!
我是 @Sophia ,一起学习进步!
往期论文推荐学习:
视觉Transformer综述!中科院、东南大学出品!超强总结!最新版本137篇参考文献!
计算机视觉Attention注意力机制综述!清华、南开出品!共27页185篇参考文献!
目标检测综述!蒙特利尔最新系统性少样本自监督的目标检测研究!
......长按二维码访问原文

总结更新Github!NeurlPS2021论文pdf和代码总结!NeurIPS2021pdf下载 2021-11-24 13:34
最近NeurlPS2021论文已经放出来了,并且已经开始总结
@Sophia 将能下载的开放的论文已经下载大家一起学习,我已经更新到我的Github上了!
对论文相关的代码什么的也进行了总结,
详细内容还是看Github吧!
往期论文推荐学习:
计算机视觉Attention注意力机制综述!清华、南开出品!共27页185篇参考文献!
目标检测综述!蒙特利尔最新系统性少样本自监督的目标检测研究!
HRFormer:多分辨率Transformer!
改进YOLO神操作!YOLO-ReT可在边缘端实时目标检测!已经开源!
复旦与华为出品:一种去除softmax的线性复杂度Transformer!
Micro-YOLO:一种新的基于轻量级CNN的目标检测模型
ByteTrack:多目标跟踪算法!华科
......长按二维码访问原文







