文章目录[隐藏]
- 方案运行平台:
- 方案软件架构:
- 方案软件设计:
- 方案数据通路:
- 方案调试以及问题记录:
- 帧延迟
- 坐标处理
- MPP Tina调试方案:
- 如何有效提高NPU检测帧率
- 一个库串用问题的澄清过程:
- V831上的移植问题:
- OSD显示:
- Buffer共享:
- 线程/进程退出:
- 添加自启动:
- 优化效果,不同场景下的检测帧率统计:
- 优化方法总结:
随着社会的发展人工智能已经逐渐走进并融入我们的生活,且应用在各个行业领域,AI不仅给许多行业带来了巨大的经济效益,同时也为我们的生活带来了许多改变和便利.在AI技术的加持下,传统消费电子产品向智能化转变,本篇就以V833为例,介绍在其上开发物体检测应用的具体步骤。
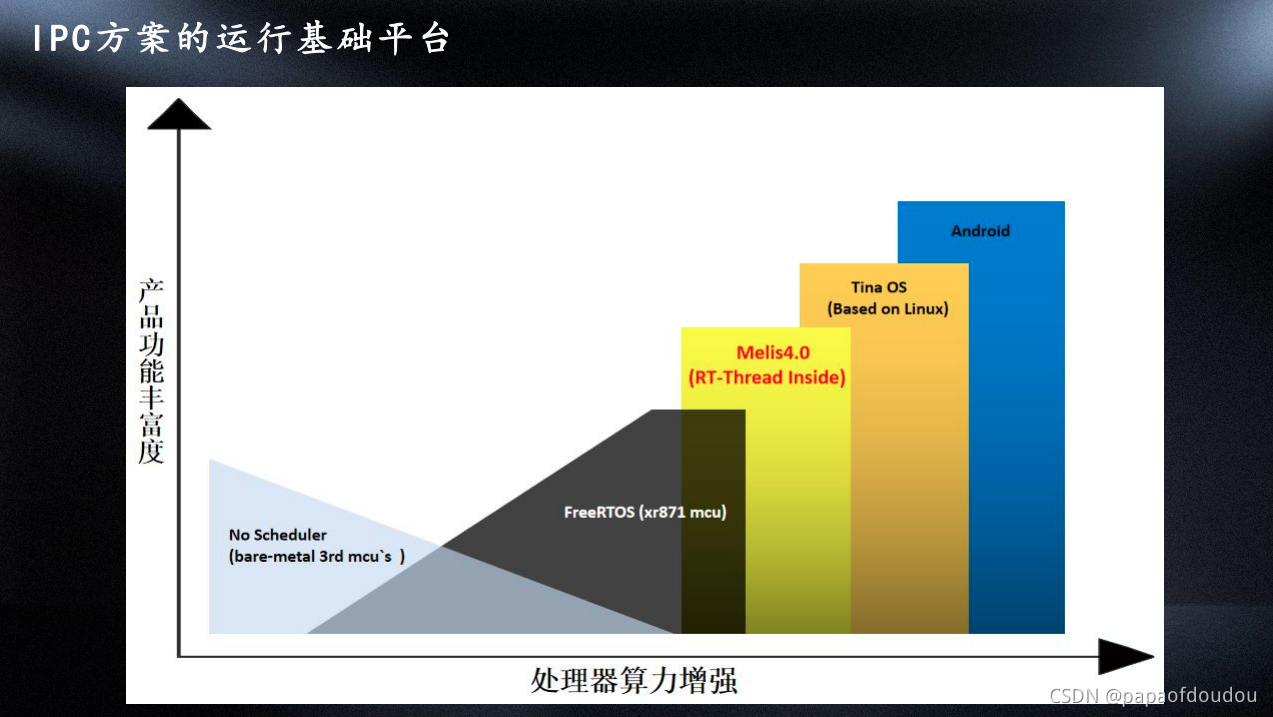
方案运行平台:
支持IPC开发的平台有Melis和Tina,过程是类似的,这里以Tina为例介绍。
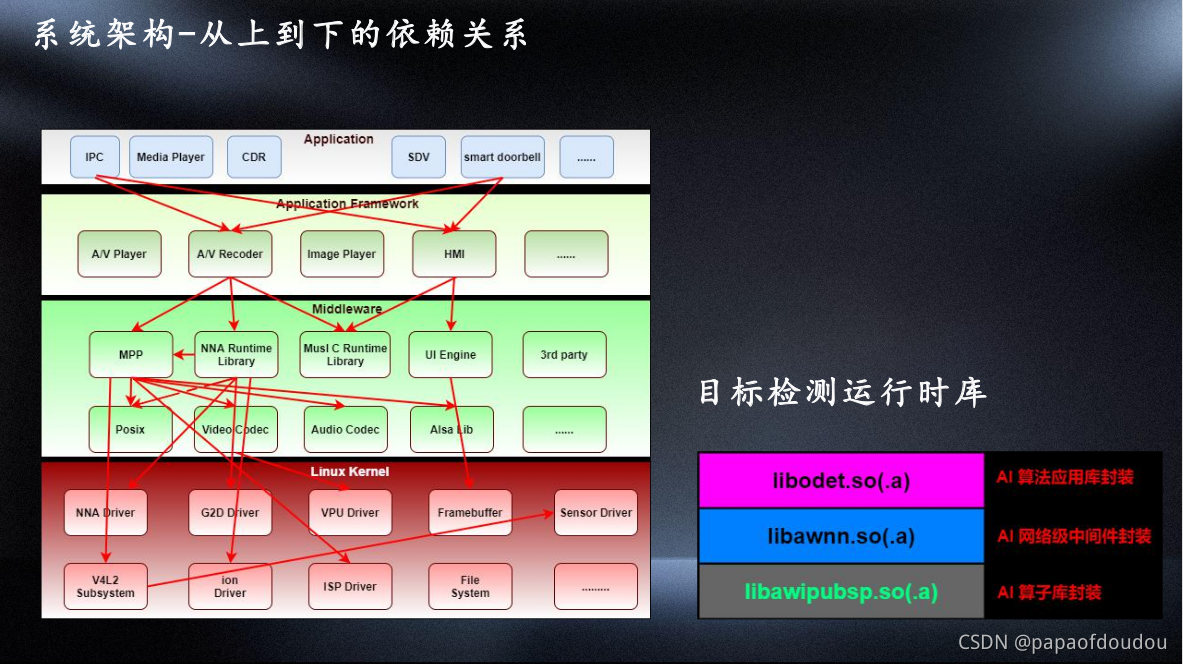
方案软件架构:
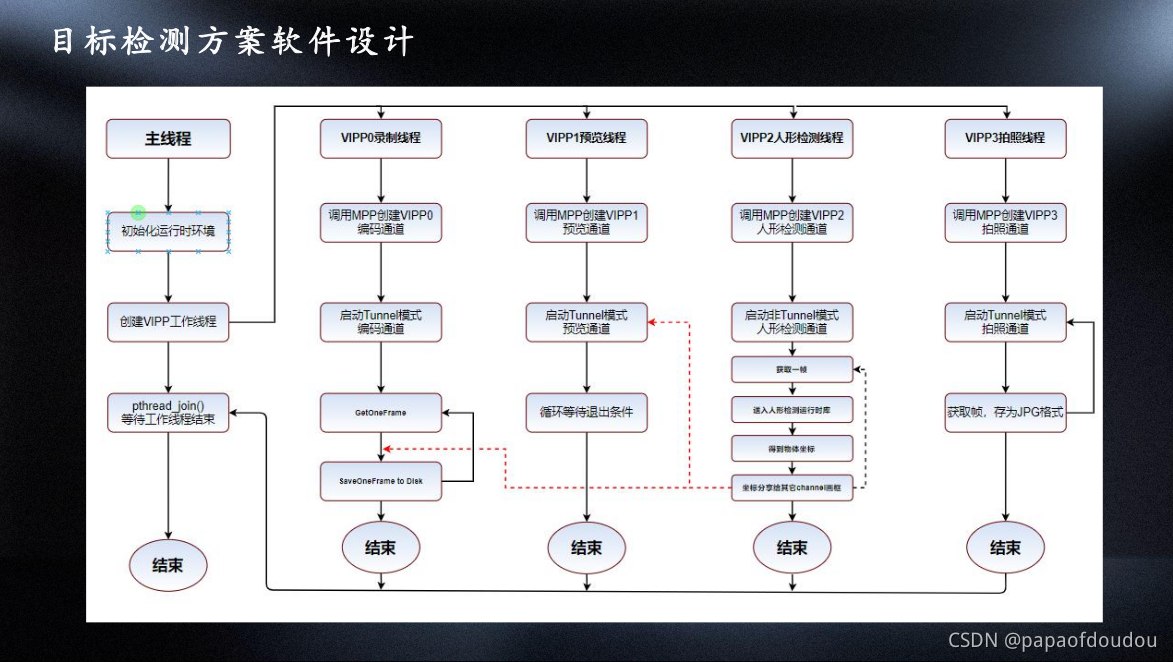
方案软件设计:
方案数据通路:
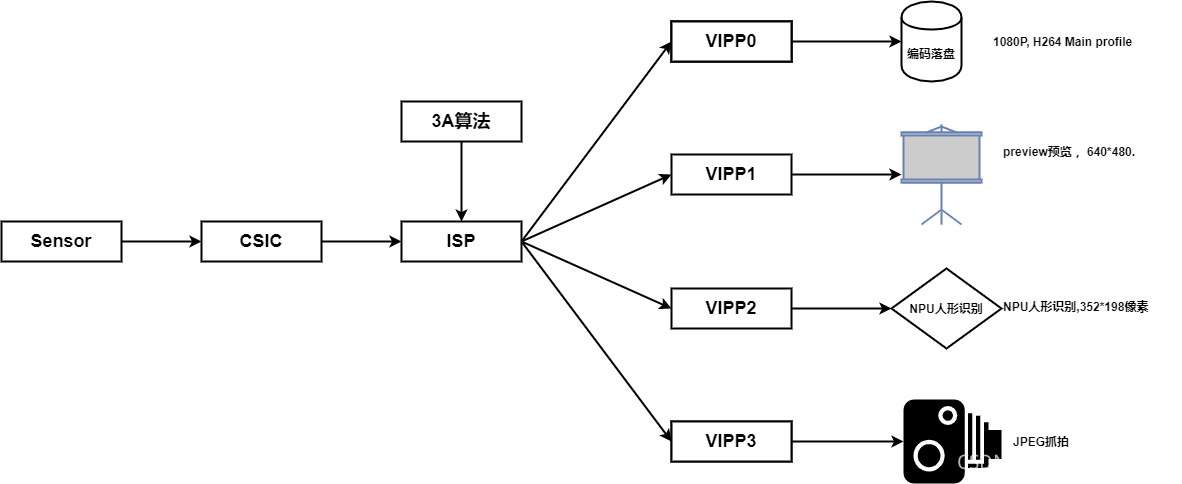
一路sensor图像经过四路VIPP缩放操作后,送给四个不同应用,分别是H265编码存盘,LCD预览以及以及NPU人形检测,还有一路照片抓拍。
NPU人形检测原理如下:
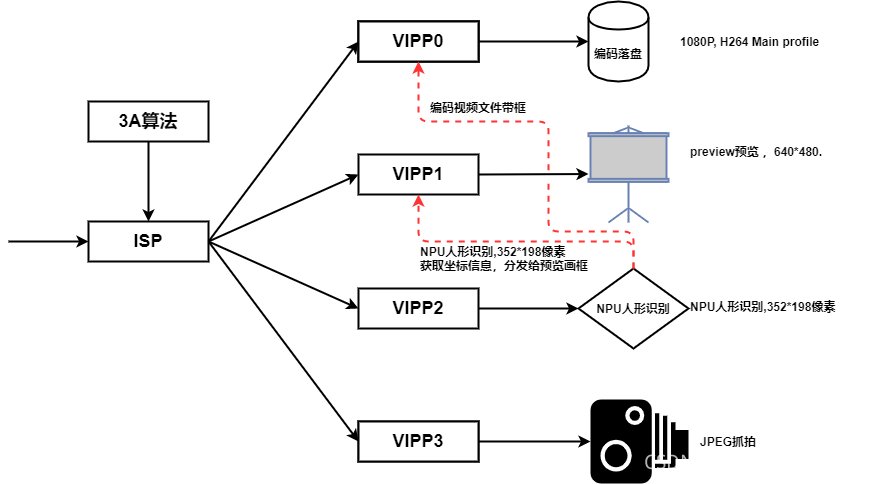
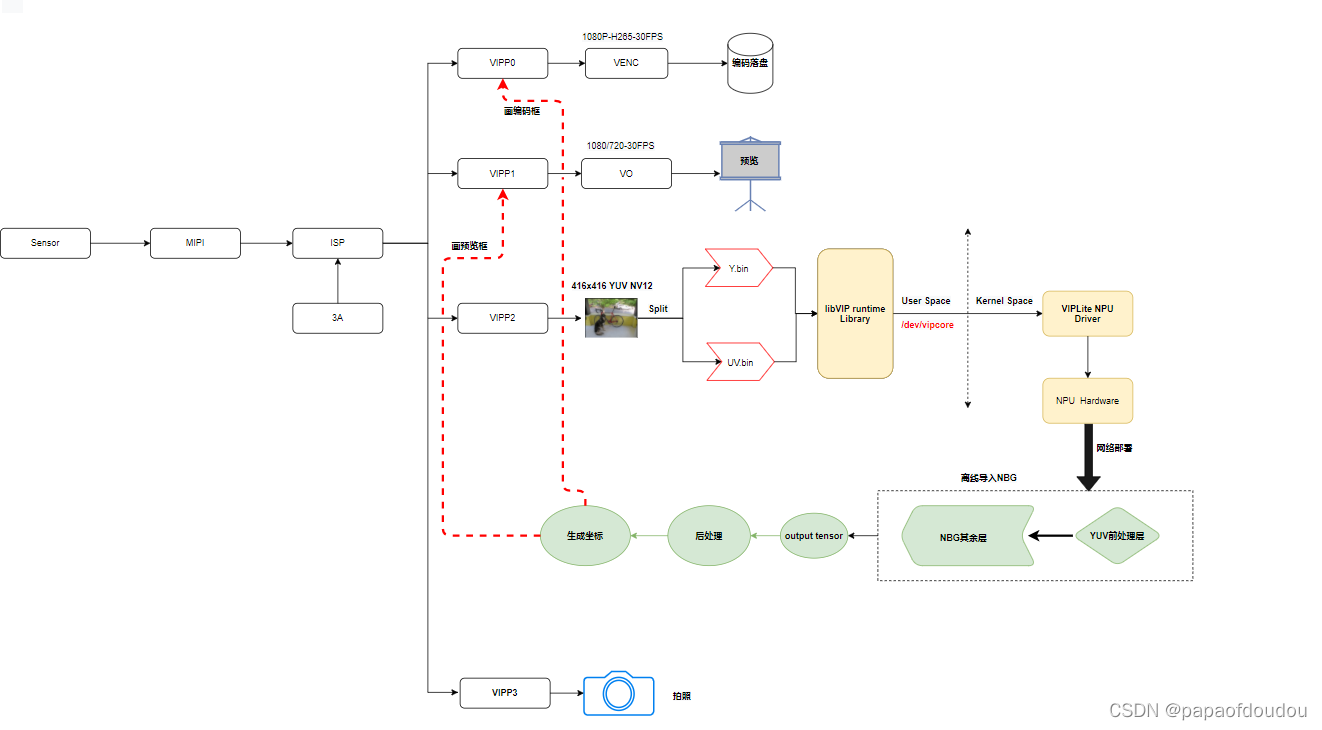
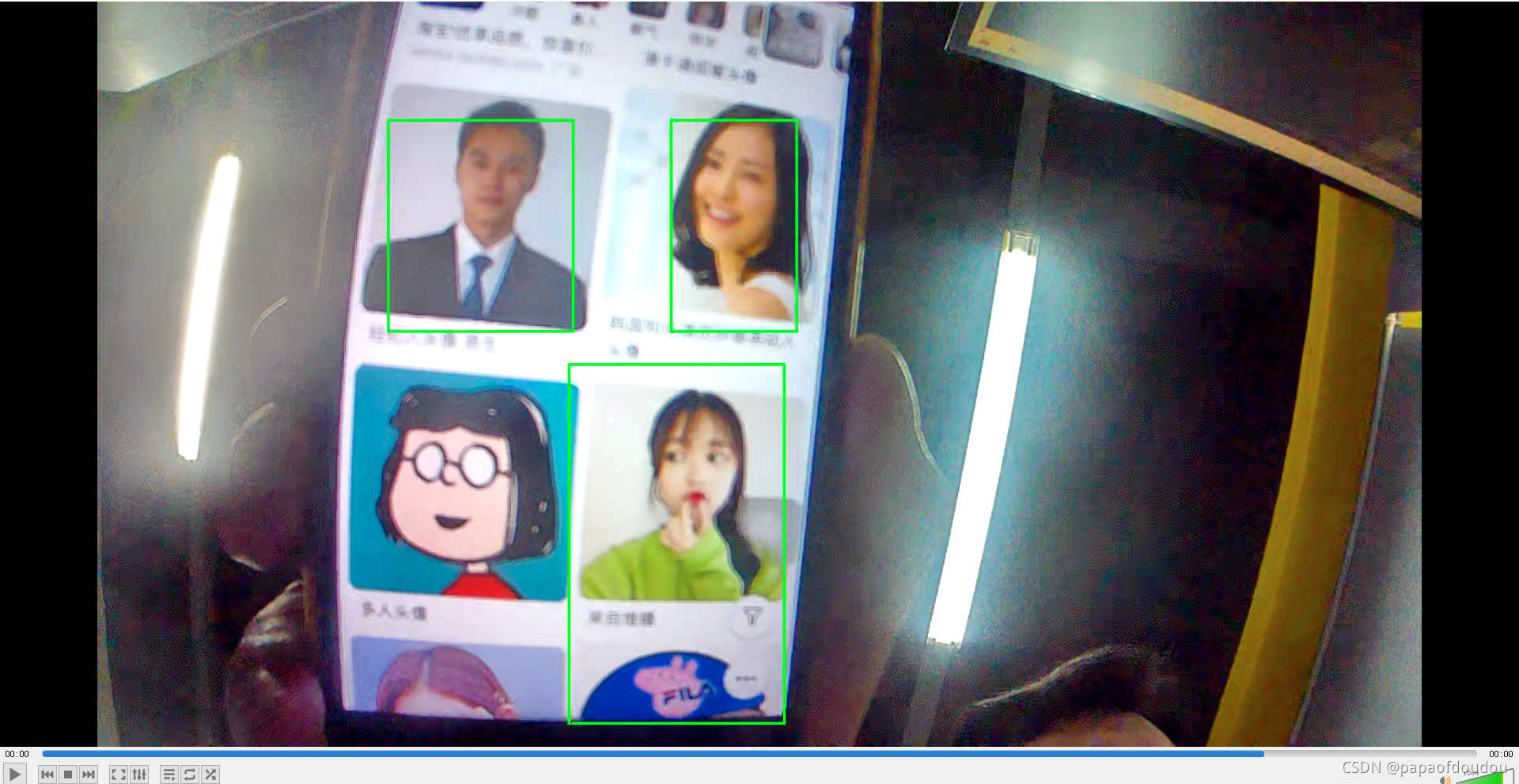
NPU线程抓取352*198(VIPP支持的输出大小)像素,格式为NV21的YUV原始帧数据,喂给人形检测算法网络,得到类别和坐标数据后,反馈给VIPP1 预览通道画框。
最后,将模型文件和模型数据放到路径/mnt/sdcard/object_det/model/下,因为程序会固定的到这个位置读取网络结构文件和网络数据文件。
模型是基于darknet yolov4-tiny.cfg的基础上优化得到的。

方案调试以及问题记录:
运行过程中,利用如下命令查看数据通路:

cat /sys/kernel/debug/mpp/viroot@(none):/# cat /sys/kernel/debug/mpp/vi
*****************************************************
VIN hardware feature list:
mcsi 1, ncsi 1, parser 2, isp 1, vipp 4, dma 4
CSI_VERSION: CSI230_200, ISP_VERSION: ISP521_100
CSI_CLK: 336000000, ISP_CLK: 300000000
*****************************************************
vi0:
imx386_mipi => mipi0 => csi0 => isp0 => vipp0
input => hoff: 0, voff: 2, w: 1920, h: 1080, fmt: RGGB10
output => width: 1920, height: 1080, fmt: NV21M
interface: MIPI, isp_mode: NORMAL, hflip: 0, vflip: 0
prs_in => x: 1920, y: 1082, hb: 397, hs: 2183
buf => cnt: 5 size: 3133440 rest: 5, mode: software_update
frame => cnt: 1033, lost_cnt: 1, error_cnt: 1
internal => avg: 16(ms), max: 30(ms), min: 1(ms)
*****************************************************
vi1:
imx386_mipi => mipi0 => csi0 => isp0 => vipp1
input => hoff: 0, voff: 2, w: 1920, h: 1080, fmt: RGGB10
output => width: 1080, height: 720, fmt: NV21M
interface: MIPI, isp_mode: NORMAL, hflip: 0, vflip: 0
prs_in => x: 1920, y: 1082, hb: 397, hs: 2183
buf => cnt: 5 size: 1179648 rest: 3, mode: software_update
frame => cnt: 4369922, lost_cnt: 2643, error_cnt: 0
internal => avg: 16(ms), max: 24(ms), min: 2(ms)
*****************************************************
vi2:
imx386_mipi => mipi0 => csi0 => isp0 => vipp2
input => hoff: 0, voff: 2, w: 1920, h: 1080, fmt: RGGB10
output => width: 352, height: 198, fmt: NV21M
interface: MIPI, isp_mode: NORMAL, hflip: 0, vflip: 0
prs_in => x: 1920, y: 1082, hb: 401, hs: 2183
buf => cnt: 5 size: 110592 rest: 2, mode: software_update
frame => cnt: 4369922, lost_cnt: 3963615, error_cnt: 0
internal => avg: 16(ms), max: 24(ms), min: 8(ms)
*****************************************************
vi3:
(null) => csi1 => isp1 => vipp3
input => hoff: 0, voff: 0, w: 0, h: 0, fmt: NULL
output => width: 0, height: 0, fmt: NULL
interface: PARALLEL, isp_mode: NORMAL, hflip: 0, vflip: 0
prs_in => x: 0, y: 0, hb: 0, hs: 0
buf => cnt: 0 size: 0 rest: 0, mode: software_update
frame => cnt: 0, lost_cnt: 0, error_cnt: 0
internal => avg: 0(ms), max: 0(ms), min: 0(ms)
*****************************************************
root@(none):/# cat /sys/kernel/debug/mpp/vi
cat /sys/kernel/debug/mpp/vi
*****************************************************
VIN hardware feature list:
mcsi 1, ncsi 1, parser 2, isp 1, vipp 4, dma 4
CSI_VERSION: CSI230_200, ISP_VERSION: ISP521_100
CSI_CLK: 336000000, ISP_CLK: 300000000
*****************************************************
vi0:
imx386_mipi => mipi0 => csi0 => isp0 => vipp0
input => hoff: 0, voff: 2, w: 1920, h: 1080, fmt: RGGB10
output => width: 1920, height: 1080, fmt: NV21M
interface: MIPI, isp_mode: NORMAL, hflip: 0, vflip: 0
prs_in => x: 1920, y: 1082, hb: 397, hs: 2183
buf => cnt: 5 size: 3133440 rest: 5, mode: software_update
frame => cnt: 1033, lost_cnt: 1, error_cnt: 1
internal => avg: 16(ms), max: 30(ms), min: 1(ms)
*****************************************************
vi1:
imx386_mipi => mipi0 => csi0 => isp0 => vipp1
input => hoff: 0, voff: 2, w: 1920, h: 1080, fmt: RGGB10
output => width: 1080, height: 720, fmt: NV21M
interface: MIPI, isp_mode: NORMAL, hflip: 0, vflip: 0
prs_in => x: 1920, y: 1082, hb: 398, hs: 2183
buf => cnt: 5 size: 1179648 rest: 3, mode: software_update
frame => cnt: 4370069, lost_cnt: 2643, error_cnt: 0
internal => avg: 16(ms), max: 24(ms), min: 2(ms)
*****************************************************
vi2:
imx386_mipi => mipi0 => csi0 => isp0 => vipp2
input => hoff: 0, voff: 2, w: 1920, h: 1080, fmt: RGGB10
output => width: 352, height: 198, fmt: NV21M
interface: MIPI, isp_mode: NORMAL, hflip: 0, vflip: 0
prs_in => x: 1920, y: 1082, hb: 398, hs: 2182
buf => cnt: 5 size: 110592 rest: 2, mode: software_update
frame => cnt: 4370069, lost_cnt: 3963749, error_cnt: 0
internal => avg: 18(ms), max: 24(ms), min: 8(ms)
*****************************************************
vi3:
(null) => csi1 => isp1 => vipp3
input => hoff: 0, voff: 0, w: 0, h: 0, fmt: NULL
output => width: 0, height: 0, fmt: NULL
interface: PARALLEL, isp_mode: NORMAL, hflip: 0, vflip: 0
prs_in => x: 0, y: 0, hb: 0, hs: 0
buf => cnt: 0 size: 0 rest: 0, mode: software_update
frame => cnt: 0, lost_cnt: 0, error_cnt: 0
internal => avg: 0(ms), max: 0(ms), min: 0(ms)
*****************************************************
root@(none):/#
帧延迟
这样的设计方案包含一个问题,NPU这边获得帧并进行网络推理得到坐标结果并反馈给VIPP1通道是需要时间的,这段时间物体有可能已经发生移动,所以画框的图像帧并非是和原始检测帧同一个场景,所以绘的框可能不太准确,不过如果物体运动速度不太快的话,误差也不会太大,消费类设备是可以接受的。这个原理有点类似于游戏设计中的三帧延迟,以吃鸡游戏为例,当你按下趴键准备做个老阴逼的时候,下趴指令实际上是先发送给CPU做解码,之后在给GPU做帧合成,最后才送给DPU做现实,这中间的误差一般有三帧,原理类似,用VIPP的数据去给VIPP画框,就像揪着自己的头发把自己提起来一样,被你画框的图永远不会是你检测的那张. 🙂
坐标处理
这里遇到的问题是,在开发画框流程的时候,发现对设置的框坐标无法和LCD显示器上的框坐标对应上,例如,box的坐标有四个参数来描述,定义如下:

当设置x,y坐标为0,0时,发现绘出来的框缺失这个点,显示在屏幕上就是框不完整,缺失了一部分。经过不断尝试,标定,最终发现了屏幕大小的矩形框对应的box的坐标,x,y,width,height的关系,下面是分析过程:
VIPP1的原图格式设置的是1280 * 720, 但是LCD的显示分辨率是 480 * 640,无论怎么算,aspect ratio都不相同,如下图:



由于显示前,DE如果发现源分辨率和目标分辨率不同,会自动做scale操作,而我们设置的BOX坐标是按照源图给的,所以如果scale过程中发生裁剪,那么最终会出来的矩形框肯定是不对的,经过分析,这恰恰是遇到的情况。
经过反复调试,得到的坐标原点和屏幕宽高给

大概的处理过程如下: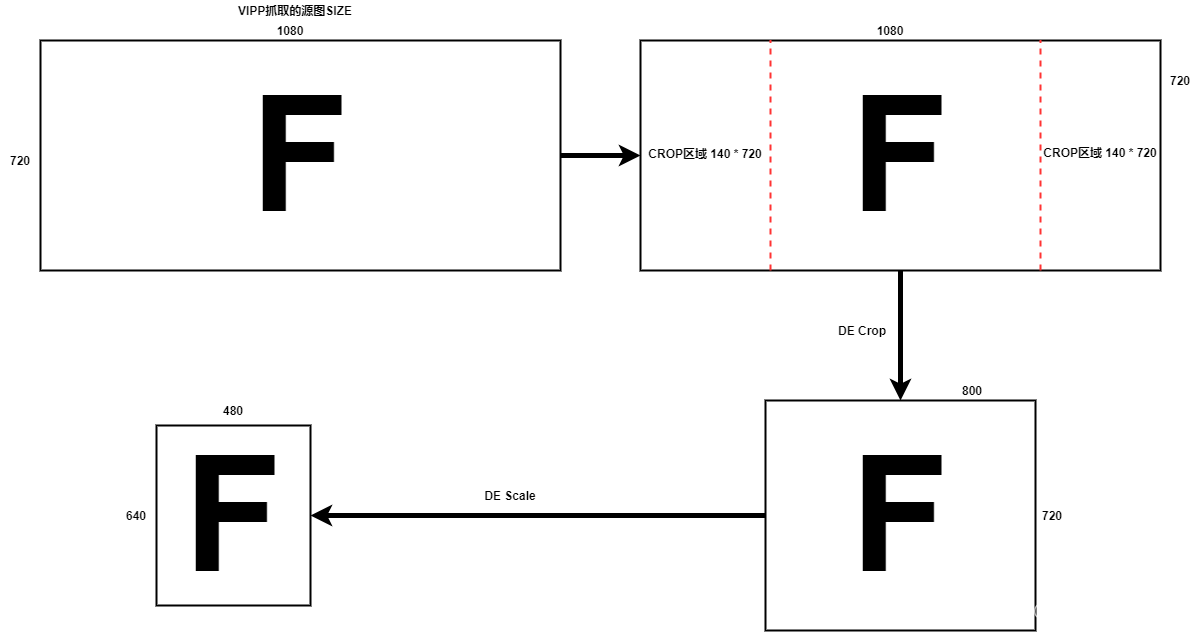
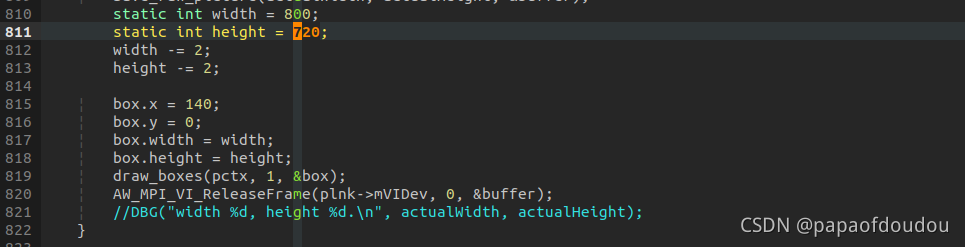
当x,y,width,height分别为140,0,800,720时的框图像:

对照录制的视频文件和预览的文件显示区域范围的区别,可以发现如上规律:

宽高的大小关系发生了易位!
一个框从最大逐渐缩小的例子:
效果是这个样子的,可以看到框在逐渐缩小:

有些网络的输入图是正方形的,比如YOLOV4默认的416*416,这个时候,为了保证图像不裁切(darknet前处理对图像做了临近域挤压和压缩,所以没有裁切),可以参考下面的流程补黑边处理。

MPP Tina调试方案:
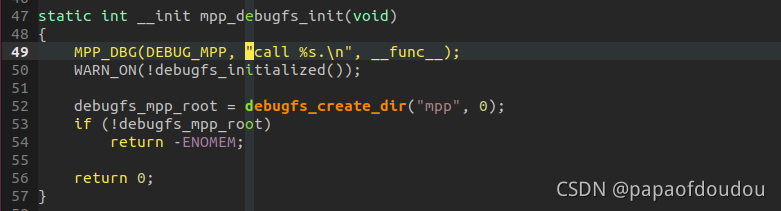
VE会在下面注册:
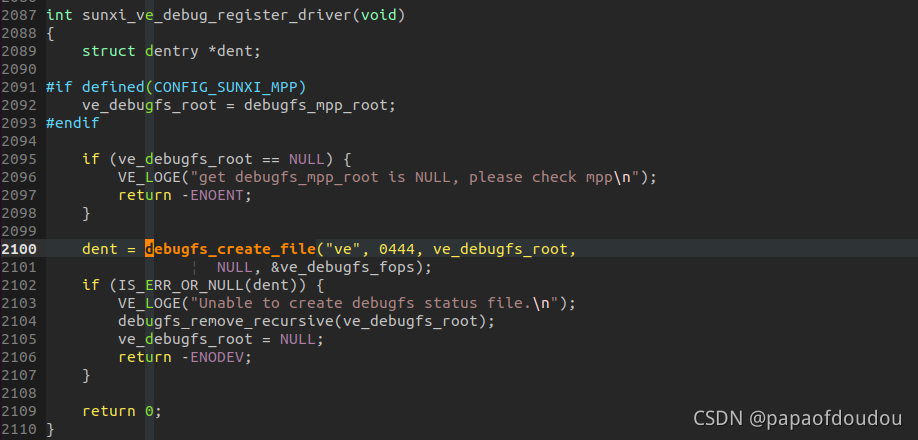
VO也在下面注册:

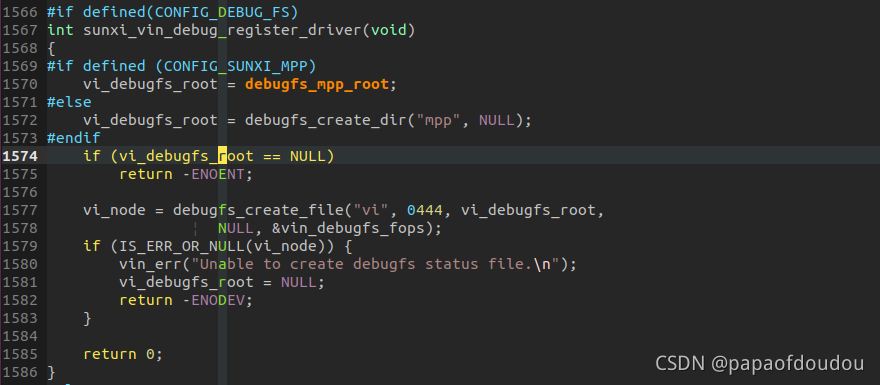
当然还有VI
如何有效提高NPU检测帧率
NPU检测帧率是测量NPU性能的关键指标,检测帧率越大,画框表现的越流畅,越自然,用户体验越好,当然,技术发展也是符合辩证法的,多快好省只是某些不切实际的狂人喊出的口号,实际中不能既要,又要,还要。达到这种流畅检测的代价就是你需要更好的硬件,更高的算力,但是如何在给定的硬件,给定的系统上尽可能大的压榨NPU的性能呢?这里记录一些最最佳实践。
1.关闭动态调压调频,参考.
Tina关闭动态调压调频_tugouxp的专栏-CSDN博客
2.提高NPU检测线程的优先级.
这里主要记录这种方式:
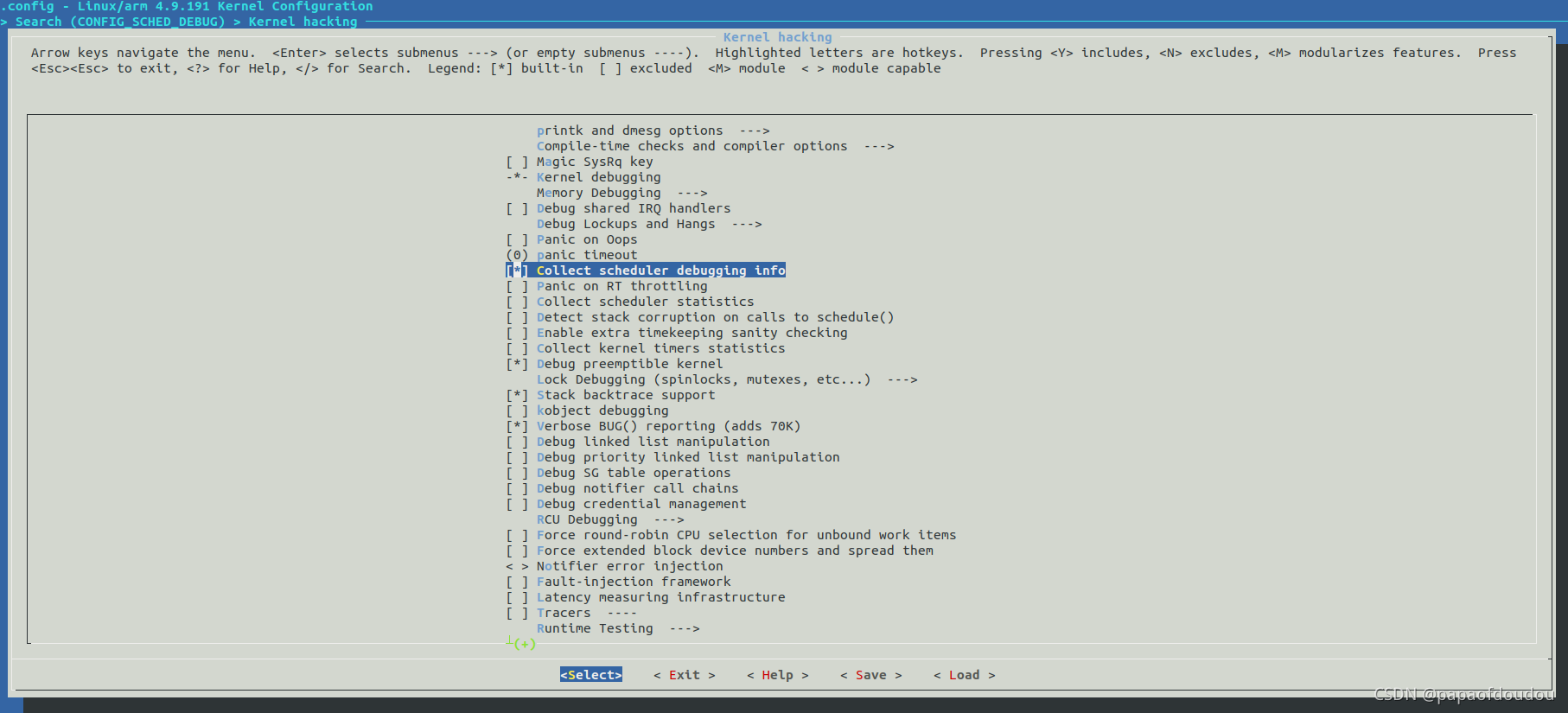
打开CONFIG_SCHED_DEBUG的主要目的是确认优先级改成功了,policy为0表示默认的CFS调度器,默认优先级为120.
0:SCHED_OTHER(内核态叫SCHED_NORMAL)
1: SCHED_FIFO
2: SCHED_RR
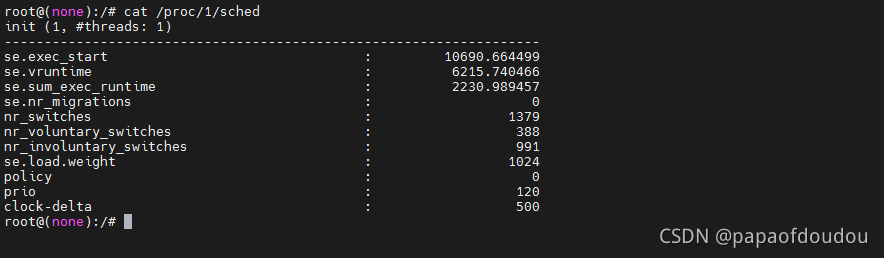
提升 优先级的代码,采用继承策略,所有被主动提升优先级创建的新线程都会提升到相同的优先级和调度策略.
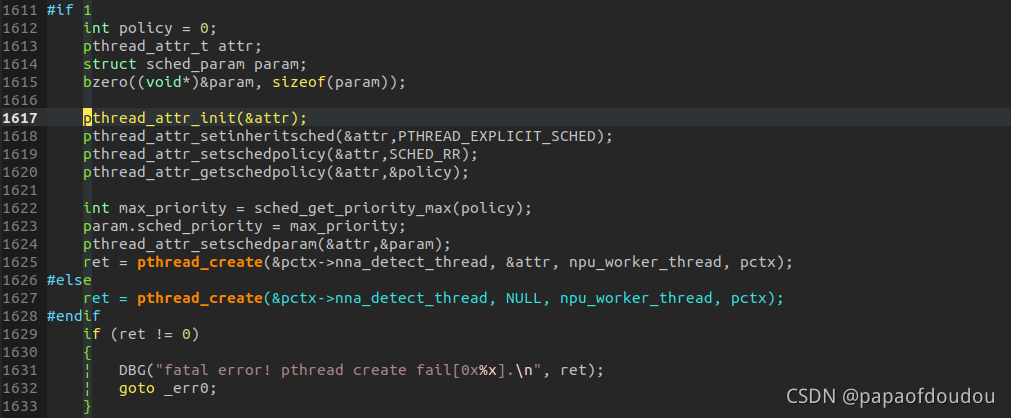
在提优先级之前的任务状态:
root@(none):/mnt/sdcard# pidof sample_run_nna
924
root@(none):/mnt/sdcard# cd /proc/924/task/
root@(none):/proc/924/task# cat ./9
924/ 931/ 932/ 933/ 934/ 935/ 936/ 937/ 938/ 939/ 940/ 941/ 942/
root@(none):/proc/924/task# cat ./*/sched
sample_run_nna (924, #threads: 13)
-------------------------------------------------------------------
se.exec_start : 97028.161170
se.vruntime : 9498.540895
se.sum_exec_runtime : 322.772674
se.nr_migrations : 0
nr_switches : 325
nr_voluntary_switches : 161
nr_involuntary_switches : 164
se.load.weight : 1024
policy : 0
prio : 120
clock-delta : 625
isp_thread (931, #threads: 13)
-------------------------------------------------------------------
se.exec_start : 105481.353013
se.vruntime : 10706.565309
se.sum_exec_runtime : 1614.484623
se.nr_migrations : 0
nr_switches : 1626
nr_voluntary_switches : 1007
nr_involuntary_switches : 619
se.load.weight : 1024
policy : 0
prio : 120
clock-delta : 125
ViComponentThre (932, #threads: 13)
-------------------------------------------------------------------
se.exec_start : 105500.862346
se.vruntime : 10706.495724
se.sum_exec_runtime : 14.819088
se.nr_migrations : 0
nr_switches : 550
nr_voluntary_switches : 548
nr_involuntary_switches : 2
se.load.weight : 1024
policy : 0
prio : 120
clock-delta : 125
VICaptureThread (933, #threads: 13)
-------------------------------------------------------------------
se.exec_start : 105500.748138
se.vruntime : 10706.530808
se.sum_exec_runtime : 35.223204
se.nr_migrations : 0
nr_switches : 546
nr_voluntary_switches : 546
nr_involuntary_switches : 0
se.load.weight : 1024
policy : 0
prio : 120
clock-delta : 84
CDX_VRender (934, #threads: 13)
-------------------------------------------------------------------
se.exec_start : 105501.137846
se.vruntime : 10706.651099
se.sum_exec_runtime : 110.490325
se.nr_migrations : 0
nr_switches : 551
nr_voluntary_switches : 547
nr_involuntary_switches : 4
se.load.weight : 1024
policy : 0
prio : 120
clock-delta : 292
sample_run_nna (935, #threads: 13)
-------------------------------------------------------------------
se.exec_start : 105801.617512
se.vruntime : 10756.689146
se.sum_exec_runtime : 65.801465
se.nr_migrations : 0
nr_switches : 589
nr_voluntary_switches : 584
nr_involuntary_switches : 5
se.load.weight : 1024
policy : 0
prio : 120
clock-delta : 375
sample_run_nna (936, #threads: 13)
-------------------------------------------------------------------
se.exec_start : 105818.973803
se.vruntime : 10760.648644
se.sum_exec_runtime : 313.491813
se.nr_migrations : 0
nr_switches : 1676
nr_voluntary_switches : 1649
nr_involuntary_switches : 27
se.load.weight : 1024
policy : 0
prio : 120
clock-delta : 83
ViComponentThre (937, #threads: 13)
-------------------------------------------------------------------
se.exec_start : 105801.500345
se.vruntime : 10756.642146
se.sum_exec_runtime : 25.299997
se.nr_migrations : 0
nr_switches : 544
nr_voluntary_switches : 542
nr_involuntary_switches : 2
se.load.weight : 1024
policy : 0
prio : 120
clock-delta : 250
ViComponentThre (938, #threads: 13)
-------------------------------------------------------------------
se.exec_start : 87057.498791
se.vruntime : 8002.817188
se.sum_exec_runtime : 0.055333
se.nr_migrations : 0
nr_switches : 4
nr_voluntary_switches : 2
nr_involuntary_switches : 2
se.load.weight : 1024
policy : 0
prio : 120
clock-delta : 208
VICaptureThread (939, #threads: 13)
-------------------------------------------------------------------
se.exec_start : 105801.454803
se.vruntime : 10756.644229
se.sum_exec_runtime : 29.591133
se.nr_migrations : 0
nr_switches : 560
nr_voluntary_switches : 560
nr_involuntary_switches : 0
se.load.weight : 1024
policy : 0
prio : 120
clock-delta : 250
CDX_VRender (940, #threads: 13)
-------------------------------------------------------------------
se.exec_start : 87057.579416
se.vruntime : 8005.820814
se.sum_exec_runtime : 0.056417
se.nr_migrations : 0
nr_switches : 5
nr_voluntary_switches : 1
nr_involuntary_switches : 4
se.load.weight : 1024
policy : 0
prio : 120
clock-delta : 375
VICaptureThread (941, #threads: 13)
-------------------------------------------------------------------
se.exec_start : 106135.636594
se.vruntime : 10802.278307
se.sum_exec_runtime : 90.035334
se.nr_migrations : 0
nr_switches : 570
nr_voluntary_switches : 570
nr_involuntary_switches : 0
se.load.weight : 1024
policy : 0
prio : 120
clock-delta : 125
VEncComp (942, #threads: 13)
-------------------------------------------------------------------
se.exec_start : 106151.919010
se.vruntime : 10805.540306
se.sum_exec_runtime : 1871.900509
se.nr_migrations : 0
nr_switches : 2988
nr_voluntary_switches : 1102
nr_involuntary_switches : 1886
se.load.weight : 1024
policy : 0
prio : 120
clock-delta : 125
root@(none):/proc/924/task#NPU优先级提升后的线程状态:
root@(none):/mnt/sdcard# pidof sample_run_nna
923
root@(none):/mnt/sdcard# cd /proc/923
root@(none):/proc/923# ls
auxv limits oom_adj status
cmdline map_files oom_score syscall
comm maps oom_score_adj task
coredump_filter mem personality time_in_state
cwd mountinfo root timerslack_ns
environ mounts sched wchan
exe mountstats stack
fd net stat
fdinfo ns statm
root@(none):/proc/923# cd task/9
-/bin/sh: cd: can't cd to task/9
root@(none):/proc/923# cd task/
root@(none):/proc/923/task# cat ./*/sched
sample_run_nna (923, #threads: 13)
-------------------------------------------------------------------
se.exec_start : 81454.674063
se.vruntime : 9205.329910
se.sum_exec_runtime : 328.087841
se.nr_migrations : 0
nr_switches : 334
nr_voluntary_switches : 155
nr_involuntary_switches : 179
se.load.weight : 1024
policy : 0
prio : 120
clock-delta : 500
isp_thread (929, #threads: 13)
-------------------------------------------------------------------
se.exec_start : 89798.691073
se.vruntime : 10412.040559
se.sum_exec_runtime : 1604.900473
se.nr_migrations : 0
nr_switches : 1552
nr_voluntary_switches : 971
nr_involuntary_switches : 581
se.load.weight : 1024
policy : 0
prio : 120
clock-delta : 125
ViComponentThre (930, #threads: 13)
-------------------------------------------------------------------
se.exec_start : 89788.183281
se.vruntime : 10405.992058
se.sum_exec_runtime : 14.439583
se.nr_migrations : 0
nr_switches : 546
nr_voluntary_switches : 544
nr_involuntary_switches : 2
se.load.weight : 1024
policy : 0
prio : 120
clock-delta : 125
VICaptureThread (931, #threads: 13)
-------------------------------------------------------------------
se.exec_start : 89821.514281
se.vruntime : 10417.390891
se.sum_exec_runtime : 30.870623
se.nr_migrations : 0
nr_switches : 544
nr_voluntary_switches : 544
nr_involuntary_switches : 0
se.load.weight : 1024
policy : 0
prio : 120
clock-delta : 709
CDX_VRender (932, #threads: 13)
-------------------------------------------------------------------
se.exec_start : 89822.039656
se.vruntime : 10417.633141
se.sum_exec_runtime : 112.393517
se.nr_migrations : 0
nr_switches : 545
nr_voluntary_switches : 543
nr_involuntary_switches : 2
se.load.weight : 1024
policy : 0
prio : 120
clock-delta : 334
sample_run_nna (933, #threads: 13)
-------------------------------------------------------------------
se.exec_start : 90122.059697
se.vruntime : 1.999999
se.sum_exec_runtime : 74.959755
se.nr_migrations : 0
nr_switches : 570
nr_voluntary_switches : 570
nr_involuntary_switches : 0
se.load.weight : 1024
policy : 2
prio : 0
clock-delta : 250
sample_run_nna (934, #threads: 13)
-------------------------------------------------------------------
se.exec_start : 90139.016030
se.vruntime : 10461.141308
se.sum_exec_runtime : 308.006983
se.nr_migrations : 0
nr_switches : 1702
nr_voluntary_switches : 1660
nr_involuntary_switches : 42
se.load.weight : 1024
policy : 0
prio : 120
clock-delta : 250
ViComponentThre (935, #threads: 13)
-------------------------------------------------------------------
se.exec_start : 71440.589685
se.vruntime : 0.000000
se.sum_exec_runtime : 0.049709
se.nr_migrations : 0
nr_switches : 2
nr_voluntary_switches : 2
nr_involuntary_switches : 0
se.load.weight : 1024
policy : 2
prio : 0
clock-delta : 209
VICaptureThread (936, #threads: 13)
-------------------------------------------------------------------
se.exec_start : 90121.954780
se.vruntime : 0.000000
se.sum_exec_runtime : 86.315416
se.nr_migrations : 0
nr_switches : 557
nr_voluntary_switches : 557
nr_involuntary_switches : 0
se.load.weight : 1024
policy : 2
prio : 0
clock-delta : 125
CDX_VRender (937, #threads: 13)
-------------------------------------------------------------------
se.exec_start : 71440.608226
se.vruntime : 0.000000
se.sum_exec_runtime : 0.044791
se.nr_migrations : 0
nr_switches : 2
nr_voluntary_switches : 2
nr_involuntary_switches : 0
se.load.weight : 1024
policy : 2
prio : 0
clock-delta : 125
ViComponentThre (938, #threads: 13)
-------------------------------------------------------------------
se.exec_start : 90456.480320
se.vruntime : 10502.731807
se.sum_exec_runtime : 22.858504
se.nr_migrations : 0
nr_switches : 553
nr_voluntary_switches : 550
nr_involuntary_switches : 3
se.load.weight : 1024
policy : 0
prio : 120
clock-delta : 375
VICaptureThread (939, #threads: 13)
-------------------------------------------------------------------
se.exec_start : 90456.263862
se.vruntime : 10502.758224
se.sum_exec_runtime : 42.512623
se.nr_migrations : 0
nr_switches : 567
nr_voluntary_switches : 567
nr_involuntary_switches : 0
se.load.weight : 1024
policy : 0
prio : 120
clock-delta : 292
VEncComp (940, #threads: 13)
-------------------------------------------------------------------
se.exec_start : 90470.809987
se.vruntime : 10509.307349
se.sum_exec_runtime : 1860.196328
se.nr_migrations : 0
nr_switches : 2982
nr_voluntary_switches : 1098
nr_involuntary_switches : 1884
se.load.weight : 1024
policy : 0
prio : 120
clock-delta : 250
root@(none):/proc/923/task#
可以看到,有多个线程的调度策略被设置为2(SCHED_RR),优先级为0,为最高. 另外,从这个设置中我们可以看出,在Linux中,优先级调节是以线程为单位,同一个进程中的不同线程,可以设置为不同的调度策略,比如这里,就是把NPU线程的优先级设置为实时调度类(policy 2),而其它线程的调度策略仍然是CFS公平调度类(policy 为0).
我们再来看看检测帧率的变化,可以清楚的看到OSD图层和视频图层双图层显示:
ffmpeg -ss 00:00:13 -t 5 -i 11.mp4 -s 360x640 -r 15 dongtu.gif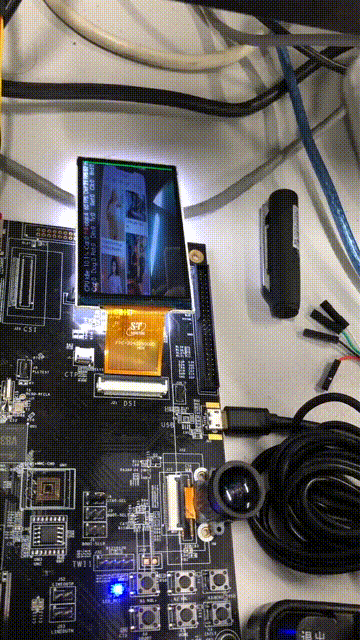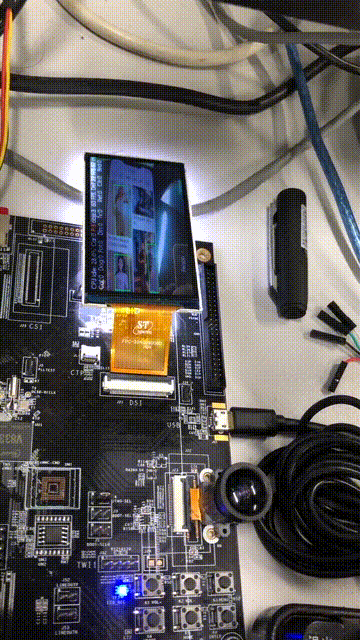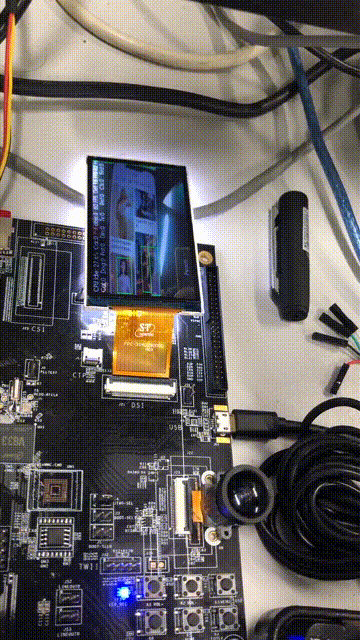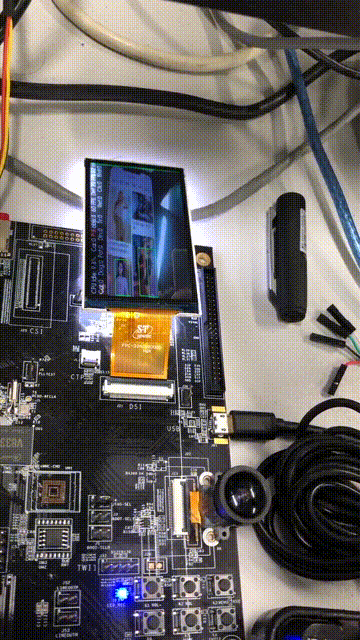
最后看一下编码路的输出,使用的工具是potplayer.
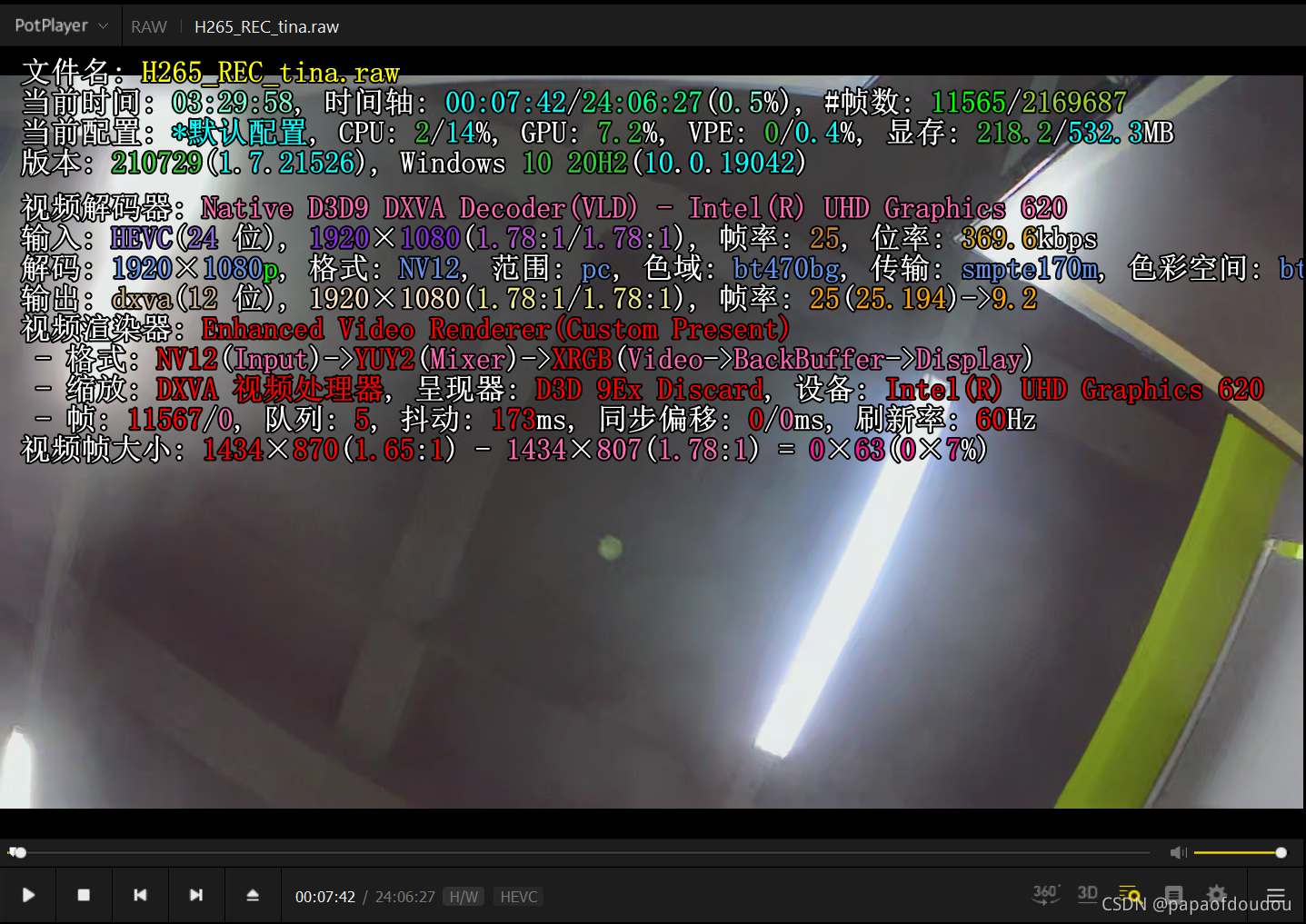
在实际测试中发现,提高检测线程优先级这个方式对增加帧率的贡献是最大的,直接将帧率从13帧提高到了20帧,增加了7帧左右。
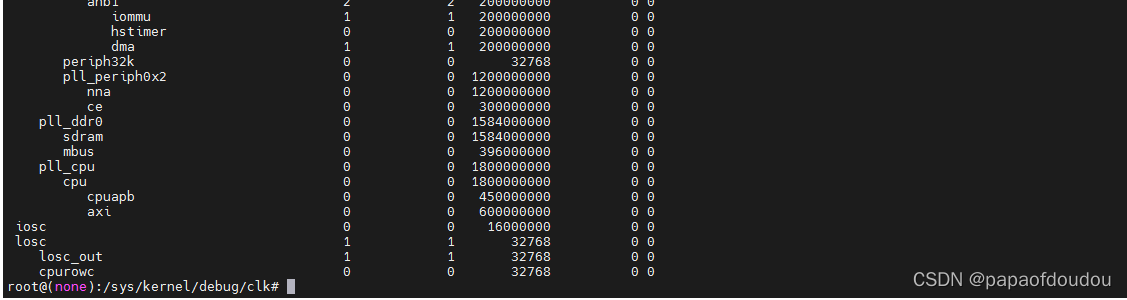
提高帧率的另外一个措施是提高CPU主频,也就是超频,手操超频原理请参考博客:
Tina&Melis时钟树分析_tugouxp的专栏-CSDN博客root@(none):/sys/kernel/debug/clk# cat clk_summary clock enable_cnt prepare_cnt rate accuracy phase----------------------------------------------------------------------------------------osc48m ...
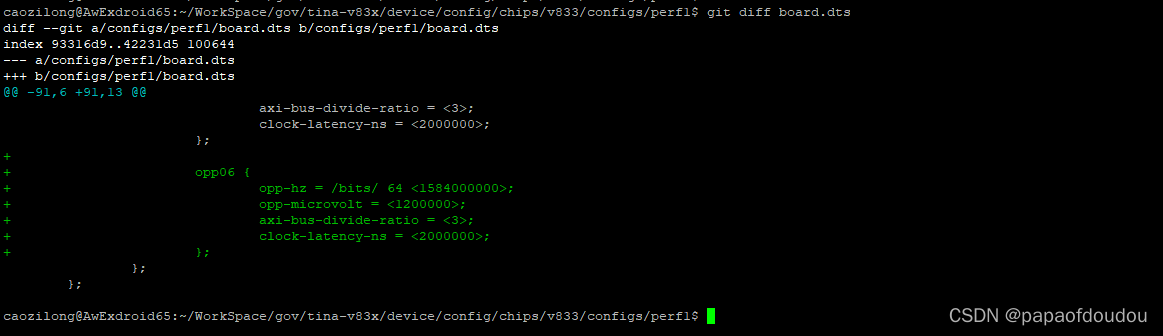
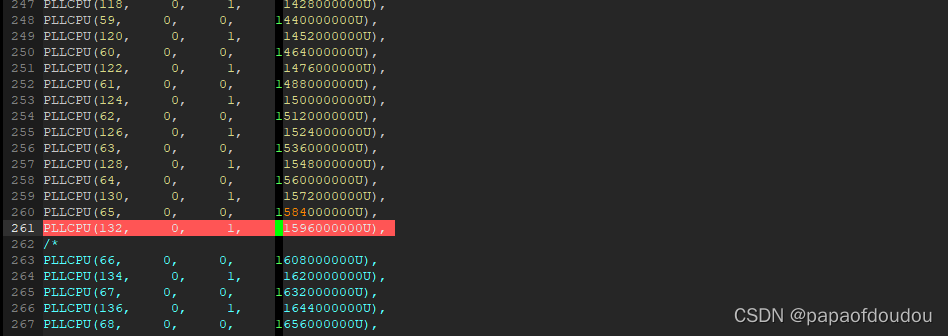
内核动态调压调频机制中,设置了调频上限为1296MHZ,这里需要将其打开:
之后重新编译,打包,烧录,查看/sys/kernel/debug/clk/clk_summary信息,修改成功了,FPS为23.

再次提频到1.8G,这么高的频率对应电压用1.2v.
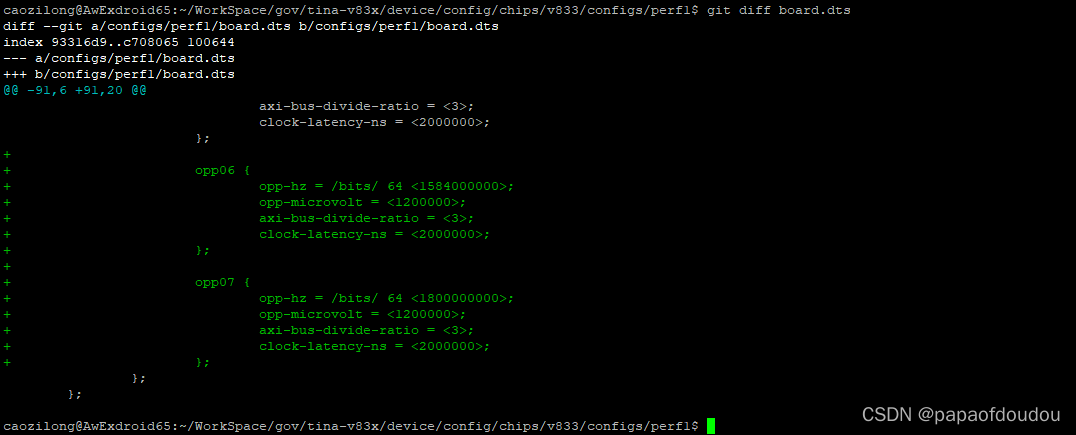
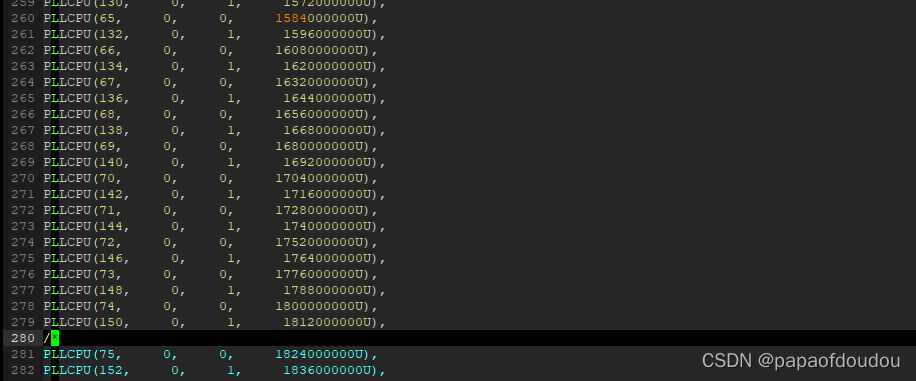
重新编译,打包烧录,查看频点,可以看到,CPU确实运行于1.8G,此时的帧率为:24FPS.
上面超频的操作是在DTS中增加一个新的,更高的频点,但是为什么系统会选择这个最高的频点我们不得而知,实际上,这是和方案的调频策略有关的.
无论在V831还是在V833上,默认启动是boot设置为1008M,但是,由于V833开启了动态调频调压,然后到了内核就有cpufreq控制,cpufreq会有多个策略
- powersave;最低频
- performance;最高频
- userspace;用户态自己设置
- schedutil ;根据调度任务
- ondemond;根据负载,对应如下的几个CONFIG.
android一般schedutil, linux一般用ondemond,tina的默认设置就是ondemond,我们要全速跑,所以这里设置为performance.
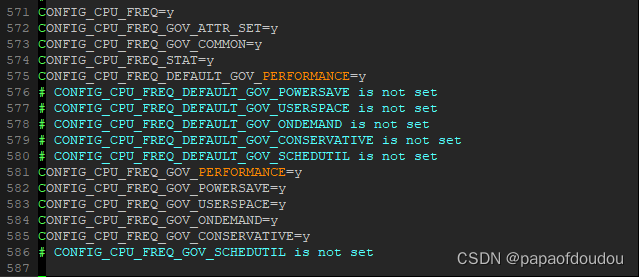

我们选择的是performance,所以以最大频率运行。
1.8G已经很高了,再提下去害怕板子被烧掉祭天,提频操作到此为止吧。
最后一个手段就是关闭动态调压调频了,方法请参考:
Tina关闭动态调压调频_tugouxp的专栏-CSDN博客结束!
一个库串用问题的澄清过程:
开发是基于一个旧一些的SDK上进行的,完成后,测试10类物体检测都很正常,识别率也比较高,后面将整个demo方案移植到比较新的SDK上的时候,遇到了一个困扰我半天的问题,问题大概表现是,移植后的demo只能检测到人形,其它9类目标均无法检测。针对此问题做过的试验包括:
1.用原版的算法库离线包(构建环境不是基于tina,而是离线的绿色版)算法库环境编译的测试程序,在新的SDK上可以正确完成10类目标的识别. --------说明模型文件和权重没有问题,SDK也没问题。
2.同样的测试用例,将其移植到Tina构建环境中,使用同样的测试图片,测试发现只能识别人形,原来离线方式用例能检测出的其它物体钧检测不到了。
3.测试用新SDK的工具链编译绿色版算法程序,编译出来的程序仍然能检测10类物体,说明不是工具链的问题。
4.这就奇怪了,排除了系统问题,模型问题程序逻辑问题,和工具链的问题之后,就只剩下运行时环境问题了。但是对比绿色版算法包和Tina环境中的三个运行库是binary identical的,这点希望也破灭了。
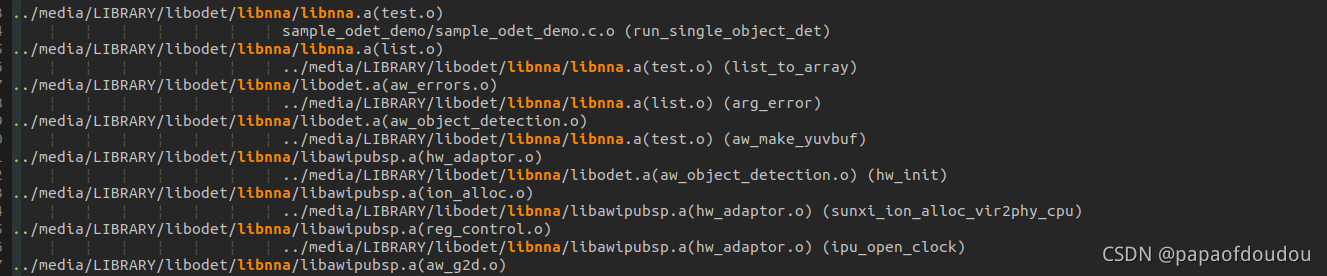
5.经过反复排查,终于通过查看链接map文件找到线索,原来,新的SDK增加了一个测试用例,也是用于人形检测的,这个用例的运行库和ai demo的运行库名称相同,目录不同,查看map文件,发现在编译的时候,两笔运行库之间都有用到。
找到了问题根源,就是运行时库的串扰引起的这个问题,解决方法就很简单了,直接关闭人形检测的用例,这样构建系统就不会找人形库去链接,而是清一色的我们预期的libnna目录中的库。
关闭body detect function,因为它只有body detection 功能。
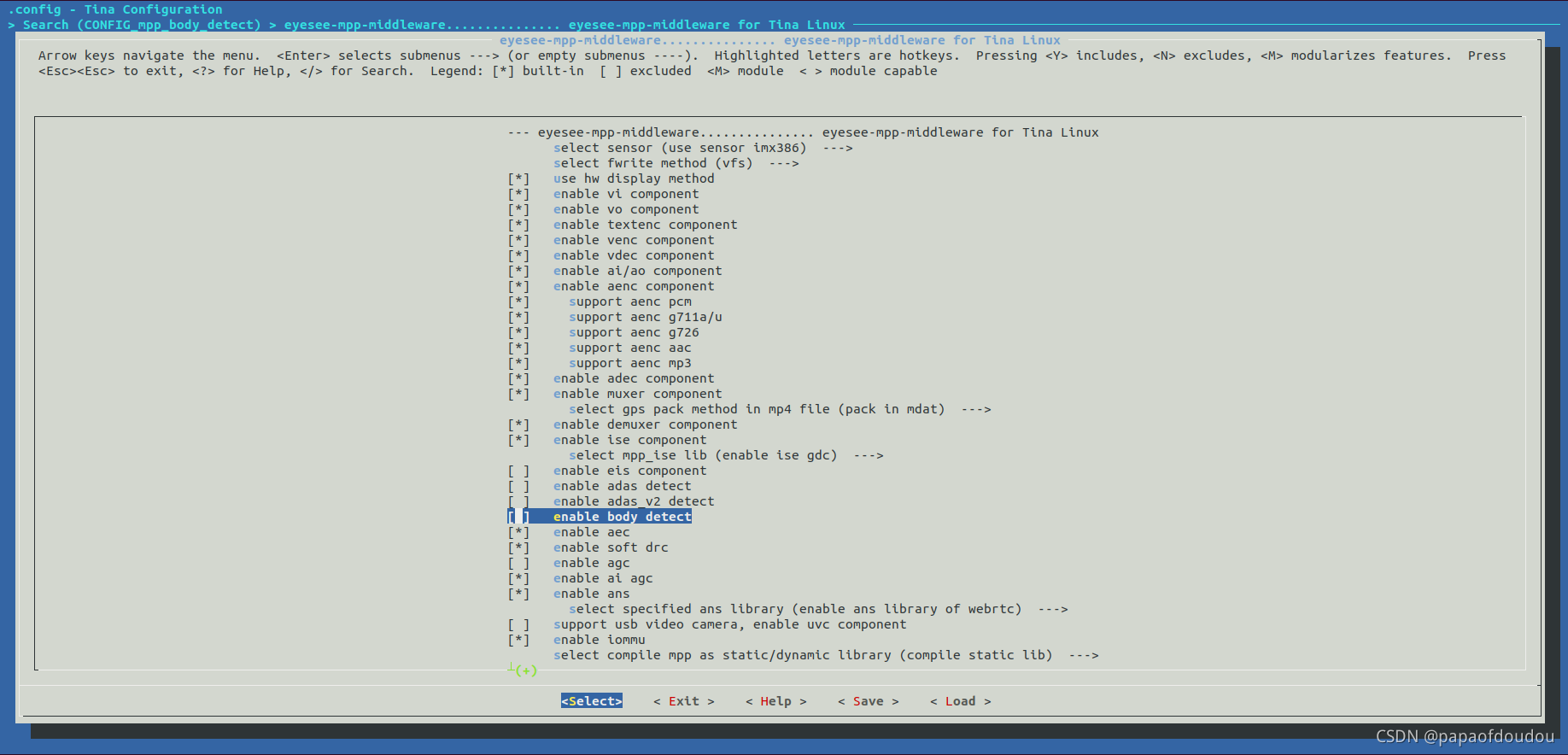
可见人方案的人形检测和目标检测还是不同的,人形检测被训练用来只检测人形轮廓的问题,但是目标检测的话,任何具有几何形状的目标都可能被见得到,之后再进行分类。
至于为何决定检测多少类的不是通过模型,而是通过运行库有所区别,还不清楚为何?
V831上的移植问题:
v831上的开发和V833基本一样,需要注意的只有预览这一路,LCD的分辨率和V833不同,V833是640*480,而V831上是其1/4,为320*240,基本上软甲软件只要配套改VO预览这一路的输出分辨率就可以了,NPU,编码的分辨率,由于是软件内部行为,和输出LCD分辨率无关,所以可以不用动。
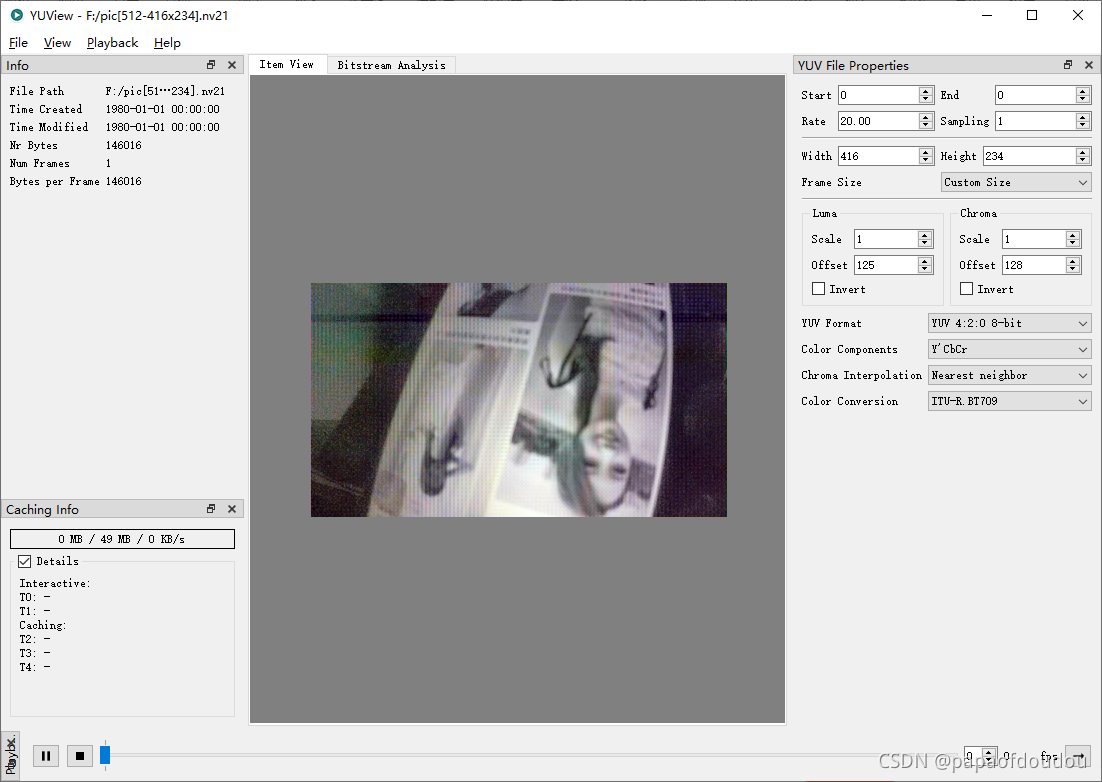
这里遇到的一个主要问题是,开发完成后,用手机百度的人物头像图片进行检测,无论怎样都没有框画出来,试了很多办法,包括尝试对显示的图像做旋转都无效,后面讲NPU这一路的图像看才找到问题原因,原来平台摄像头和LCD都是挂载裸板上,没有整机外壳,无法分摄像头的坐标系在是怎样的,导致送给NPU这一路的图像是头朝下的,当然无法检测出来 :(, 如下图所示:
OSD显示:
OSD显示使用基于DirectFB的多进程方式,用例将坐标数据发送给独立的进程,此进程再调用DirectFB将信息输出在屏幕上,如下图所示:


从串口打印端得到的检测目标品类信息:
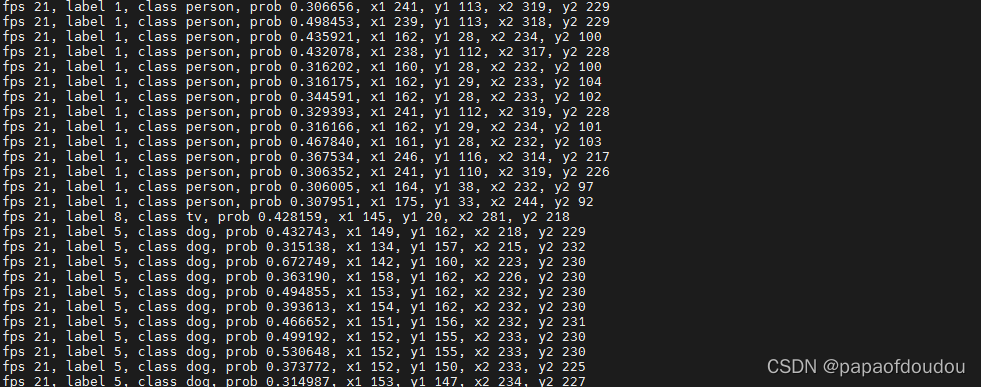
目标检测的种类依赖于数据集,比如训练的盆景的的算法,会支持花盆的识别。

Buffer共享:
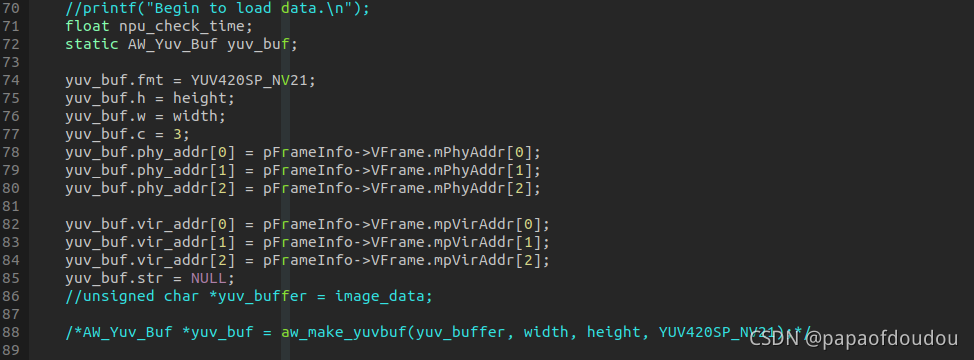
为了避免在目标检测库内分配内存,可以直接将从MPP获取到的planer布局的YUV数据三成员直接赋值给人形库的输入数据结构体,这样避免了调用目标检测库的makebuf函数重复申请结构图,毕竟NPU物体检测和还帧的动作是同步进行的,一帧不会二用,所以这样做是完全安全的。
线程/进程退出:
Linux平台下可以通过/dev/input/eventX设备节点读取到板端的按键信息,用以控制应用的启停。另外关于进程的启停,posix下要注意,主线程和子线程的地位是不同的,主线程如果通过return退出,或者走到末尾退出,会导致包括子线程在内的所有资源被内核释放,整个进程就会退出。但是也有一个办法可以让主线程退出而子县城以及资源不变,就是在主线程 (main上下文)将事情做完之后,主动调用pthread_exit(NULL)完成退出。这个时候子线程和资源不受影响。
原因如下,线程不像进程,一个进程中的线程之间是没有父子之分的,都是平级关系。即线程都是一样的, 退出了一个不会影响另外一个。
但是所谓的"主线程"main,其入口代码是类似这样的方式调用main的:exit(main(...)),以musl 为例,下图可以看到,如果从main中返回,直接就exit掉整个进程了,片甲不留。main执行完之后, 会调用exit(),exit() 会让整个进程over终止,那所有线程自然都会退出。

主线程退出后,让子线程继续运行的办法就是,在进程主函数(main())中调用pthread_exit(),只会使主函数所在的线程(可以说是进程的主线程)退出;而如果是return,则会调用exit(), 从而导致进程及其所有线程结束运行.
main()中调用了pthread_exit后,导致住线程提前退出,其后的exit()无法执行了,所以要到其他线程全部执行完了,整个进程才会退出。
证据是Posix官方文档的定义:
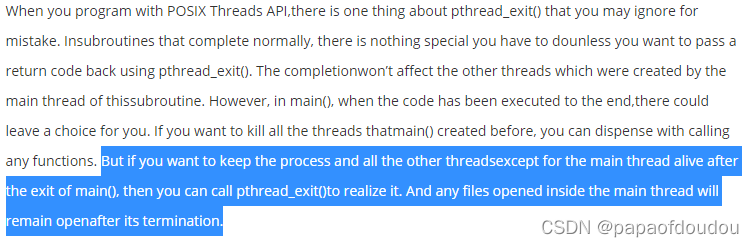
按照POSIX标准定义,当主线程在子线程终止之前调用pthread_exit()时,子线程是不会退出的。在程序中,如果这样修改,不影响ai-demo的正常功能:

添加自启动:
tina使用busybox初始化方式,所以如果想做开机启动,需要将启动脚本挂接到busybox init流程中间,cdevice进入平台配置目录,接着进入busybox-init-base-files/etc/init.d/,在S00mpp start函数中添加如下代码:
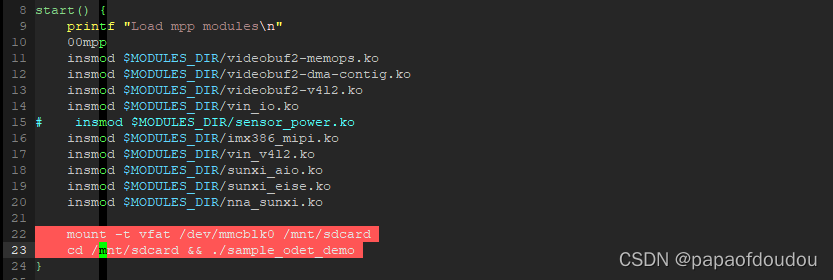
之后重新编译打包烧录,就可以实现开机自动挂载并且启动ai应用了。
优化效果,不同场景下的检测帧率统计:

优化方法总结:
个人看法,如果是从算力角度不是存储角度,感觉方案功能定义不变的话,可能的思路有:
- 从算法角度优化,流程上避免不必要的CPU计算和循环,优化计算密集模块的算法,减少占用率.
- 内存够用的话,针对个别场景,空间换时间,用多一点的内存减少计算上的辗转。
- 适当提高算法密集模块的优先级,减少计算过程中不必要的系统调度,把算力用在刀刃上。
- 充分利用硬件,超频,加速,一起上.
关于SDK的环境配置,可参考:
Tina SDK 使用V833/V831 NPU跑YOLO网络_tugouxp的专栏-CSDN博客1.Tina SDK打开内核NNA驱动支持make kernel_menuconfig->打开 CONFIG_SUNXI_NNA这样,内核才会出现/dev/nna设备节点2.编译YOLO算法用例库算法用例库的布局如下图所示,编译前,需要调整Makefile中默认的编译器路径未正确路径:编译过程:编译生成了可执行测试文件yolo3将整个目录拷贝到TF卡上,卡挂载到V833平台上,输出警告不用管.2.运行测试用例首次执行yolo3用...https://blog.csdn.net/tugouxp/article/details/120013337
编码路的调试:
编码路无疑非常重要,它既是”证据“,也是“美好生活”的记录,在Tina框架内,可以通过设备节点
/sys/kernel/debug/mpp/ve进行分析,例如,下面显示了当前编码路H265的编码参数。

全文总结:
在目标检测方案应用中,检测帧率非常的重要,衡量最终产品综合质量的一个重要指标就是在给定的资源和算力的情况下,能否达到最大的检测帧率,对于IPC,考勤机等对检测时效性没有太高要求的应用还好,但如果是对于自动驾驶中的目标检测来说,帧率真的就是关系非常大了,你可以想象一下,如果检测一帧需要200MS,也就是每秒检测5帧尚能接受,但是对于快速行使的汽车来说,200MS可能已经跑了几十米了。
为了达到要求的检测帧率,模型端可以通过优化模型的方式进行优化,并且很多的算法已经这么做了,模型端算法端已经做了最大努力,设备端也要不甘示弱努力加油,整合各类算力资源实现检测帧率的提升。
结束!
版权声明:本文为CSDN博主「papaofdoudou」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/tugouxp/article/details/120328633




![[detr] End-to-End Object Detection with Transformers的github源码运行](https://sup.51qudong.com/wp-content/uploads/2022/05/unnamed-file-6460.png?imageMogr2/thumbnail/!300x300r|imageMogr2/gravity/Center/crop/300x300)

