1 简介目标检测中的集合预测
常见的目标检测方法如Faster-RCNN,RetinaNet等都是通过预设anchor的方式进行预测,这种方式本质上就是类似滑动窗口的一种模式。而使用这种滑动窗口的方式其实是人为地给检测任务降低难度,这也确实是早期的传统方式做模式识别的一种主流方式。
而基于集合预测的方式就显得更简单粗暴了,输入一副图像,网络的输出就是最终的预测的集合(也不需要任何后处理)能够直接得到预测的集合就已经达到了检测的目的了。但这种方式从直觉上看会比基于滑动窗口的方式更难。基于滑窗的方式就像人为地给了一个梯子,帮助网络去越过障碍,而集合预测就更需要网络真正懂得图像的语义而直接越过障碍。
集合预测带来的最大好处就是训练与预测变成真正的端到端,无需NMS的后处理,十分方便。同时,也不用人为地预设anchor size/ratio 了。坏处就是这玩意儿能收敛吗?
2 非极大值抑制(NMS)
先简单介绍下NMS吧,一句话解释就是常见的检测方法会产生大量的冗余框,常用的去掉冗余框的方法就是NMS。如下图所示
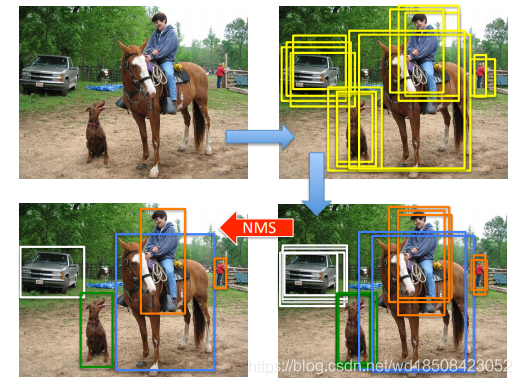
每个框有一个分类置信度分数以及框的坐标。算法思路如下,每次从剩下的框中选择分数最大的框作为最终的一个输出并移除它,与该框IoU大于给定阈值的都从剩下的框中移除,一直重复此操作直到剩下的框全被移除。那么每次中间选择的最大分数的框就是最终结果。如果有多个类的话,每个类分开计算。
3 Relation Network
之前试图直接移除NMS的工作也有很多,这里选一个比较有代表性的简单说一下。Relation Network 结构如下
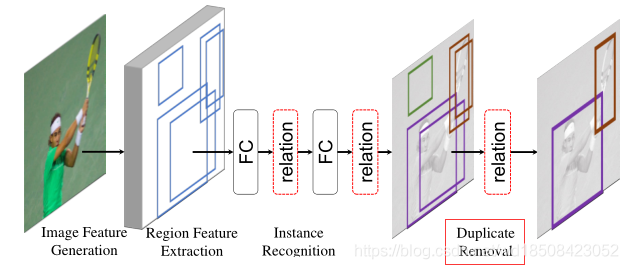
该文有两个点,一是使用relation模块来建模实例之间的关系,其实也就是类似Non-Local那一套。二是使用relation模块来消除NMS。这里仔细说下第二点吧。
仔细分析NMS算法的过程可以得到,NMS的过程其实用到了两个信息,一个是不同框之间的分数关系,二是不同框之间的几何关系。也就是说如果现在有个万能黑盒,给它输入分数关系与几何关系,那它也就应该可以有NMS的效果。因此作者在这里设计了一个二分网络,用来预测每个框它是否是重复框。输入有分数信息,该框的特征向量,以及该框的实际位置信息,输出就是该框是否为重复框的分数
∈
[
0
,
1
]
\in[0,1]
∈[0,1]。网络结构如下
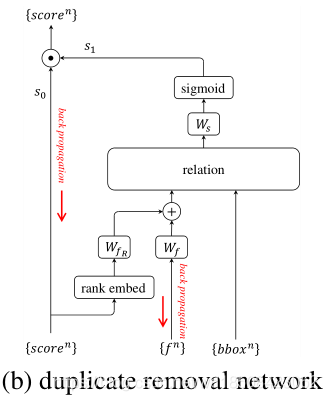
那训练的时候怎么决定谁才是非重复框,谁是重复框,也就是怎么给这个二分类网络分配GT呢?
这里是采用的动态分配的方式,过程如下:将所有预测框与所有GT框算IoU,对每个GT框选择IoU大于阈值的一些预测框,相当于根据IoU将预测框分为GT框数量个组,然后在每个组中选择预测分数最大的那个框为非重复框,其余全都为重复框。
在预测时需要将
s
0
s_0
s0,
s
1
s_1
s1乘起来作为该框的分数,一个质量好的框应该是
s
0
s_0
s0,
s
1
s_1
s1都要大。如果
s
0
s_0
s0较大,
s
1
s_1
s1较小,说明这很可能就是一个重复框,它们的乘积就很小,在输出最终结果的时候就会被排除,达到了NMS相同的作用。
4 DETR
DETR虽然不是最早预测集合的方式来检测,但应该是很有影响力的一篇文章了。介绍它之前先明确两中GT分配的方式,静态分配与动态分配
静态分配就是常见的FasterRCNN,RetinaNet,FCOS等这些方法中分配的方式,即GT的分配不依赖于网络的输出。相反,依赖于网络的输出就是动态分配,像Relation Network中二分类网络那里的分配,以及DETR中的分配方式。
下面简单介绍下DETR,下面是DETR的结构图

transformer的后面的输出就是最终预测的结果,固定为100个预测结果也就说网络输出就是
100
×
4
100\times 4
100×4和
100
×
(
C
+
1
)
100\times (C+1)
100×(C+1)的两个tensor,分别对应框的预测和类别的预测,C表示总共的类别数,+1是背景类。那怎么分配GT呢?强制让每个预测对应一个GT,多余的都对应到背景,这样就形成了一对一的对应关系,如果去枚举这个一一对应的关系,那么一定可以找到一个一种对应关系使得它们一一对应之后计算的loss最小。而求这个一一对应的方式可以不用枚举所有排列,而使用Hungarian算法高效得到。
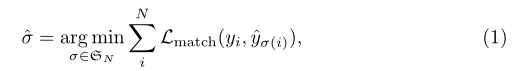
其中的loss是三部分loss,分别是类别损失
L
c
l
s
L_{cls}
Lcls, 框的L1损失
L
b
b
o
x
L_{bbox}
Lbbox,框的IoU损失
L
g
i
o
u
L_{giou}
Lgiou.
这种动态分配的方式可以说是集合类预测方法的核心。
DETR的缺点,也是原作者在论文总结过,(1)收敛速度慢,需要很长时间训练(2)没有多尺度信息,小目标检测效果差。
5 最近的基于集合预测的方法
5.1 Deformable DETR
Deformable DETR我认为是直接正面解决DETR作者提出的问题的方法,借鉴了Deformable Convolution的思想应用到Attention中来。整体结构如下
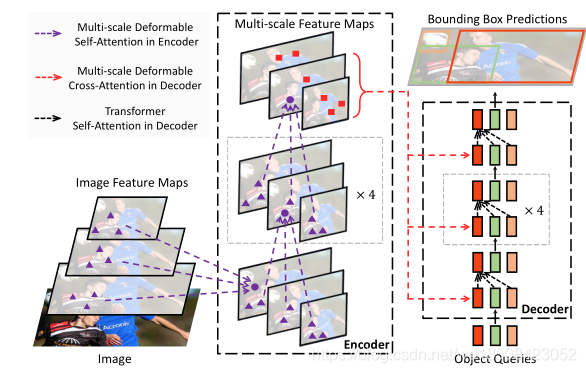
最核心的改变就是改变了算Attention的方式,即文中提出的Deformable Attention Module。介绍这个之前看下原本Transformer中的Attention计算方式,如下式所示
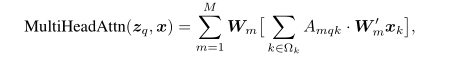
z
q
z_q
zq对应query的向量,
q
q
q是个index,表示第
q
q
q个query,
x
k
x_k
xk是key的向量,
k
k
k也是index.在self-attention中的一般
z
=
x
z=x
z=x的,
M
M
M是多头attention的head数,
Ω
k
\Omega_k
Ωk是key的集合,对于图像特征来说它的大小就
H
W
HW
HW。
W
m
′
x
k
W^{'}_{m}x_k
Wm′xk就是相应的value了.
A
m
q
k
A_{mqk}
Amqk就是第
q
q
q个query对应的第
k
k
k个key的score
∈
[
0
,
1
]
\in[0,1]
∈[0,1].而Deformable Attention计算如下
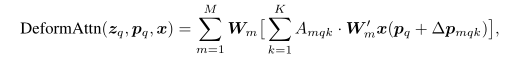
可以看到不同点每个query只会attend到
K
K
K个key了。由原本的attention计算公式可以知道,每个位置计算的结果其实就是对
W
m
′
x
W^{'}_{m}x
Wm′x重新加权的结果,这其实就包括两个部分,一是权值,即query看到的位置相应权重是多少,也对应着Attention score map,二是需要对哪些位置加权,原本的Attention是对所有位置进行加权,但是,无论从最终attention score map的结果来看还是直觉上都说明每个位置需要看到的数量是很有限的,大部分的attention score map的值都是0。基于这两点呢,作者就设计一个网络去预测这两个部分,于是上式中的
A
m
q
k
,
Δ
p
m
q
k
A_{mqk},\Delta p_{mqk}
Amqk,Δpmqk都是通过网络学出来的,其中的
p
q
p_q
pq表示
z
q
z_q
zq对应位置坐标,是二维的,也就说
Δ
p
m
q
k
\Delta p_{mqk}
Δpmqk是相对
p
q
p_q
pq的offset,从直觉上来看也一个query往往也更可能看到离自己不太远的key。上式的实现过程图大致如下
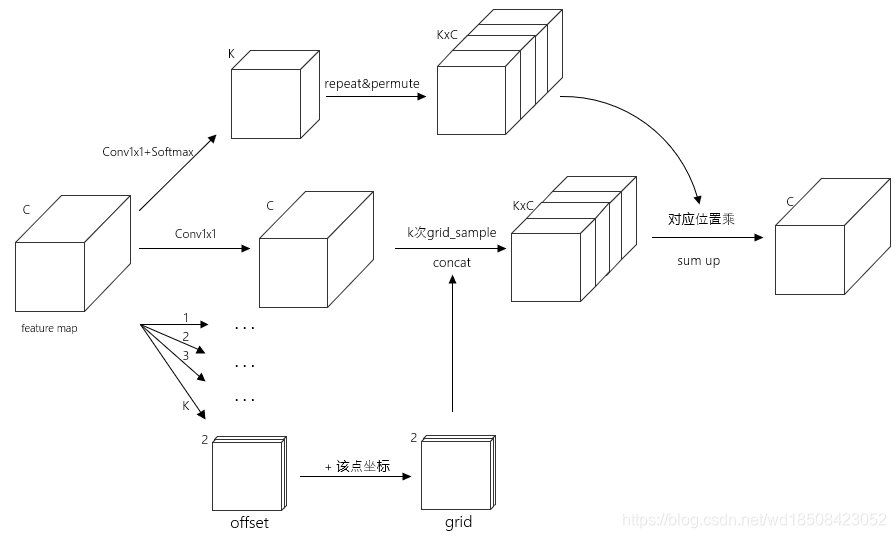
论文中K设的4,所以
K
<
<
H
W
K << HW
K<<HW,这样自然就可以将多尺度加进来,公式如下
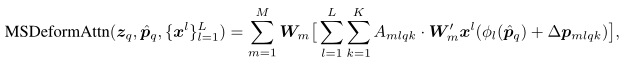
与单尺度相比就是使得每个query能够看到不同scale下的key,总共就是
L
K
LK
LK个。比起
H
W
HW
HW还是小很多的。从总体结构图中也可以看到每个点信息都是来自不同尺度的特征图。
在decoder中的attention有一些不同。
decoder中的self-attention保持不变,cross-attention将采用上式的多尺度attention,但是这里的query有些不一样,是没有坐标的,所以对应的位置用一个全连接层去预测出来。其余就与上式一样的了。另外,由于deformable attention module 是根据参考点来选择对应的key的,作者认为在预测的时候预测相对位置偏移会加速收敛。也就是相对decoder的
p
q
p_q
pq.最终的框计算如下
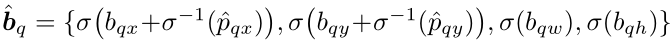
其中
b
q
x
,
b
q
y
,
b
q
w
,
b
q
h
b_{qx},b_{qy},b_{qw},b_{qh}
bqx,bqy,bqw,bqh是网络的输出,它是相对于位置
p
^
q
x
,
p
^
q
y
\hat{p}_{qx},\hat{p}_{qy}
p^qx,p^qy的,
σ
=
s
i
g
m
o
i
d
(
x
)
\sigma=sigmoid(x)
σ=sigmoid(x).以上就该文的核心内容。文章中还有两个进一步地改进版本,这里简单说下
Iterative Bounding Box Refinement:由于decoder一般有多层,而输入的
p
^
q
\hat{p}_{q}
p^q是个参考位置,因此这里可以迭代的去使用上一层decoder预测出的位置。
Two-Stage Deformable DETR:第一阶段是使用transformer的encoder每个位置都去预测一个位置,也同样使用Hungarian算法去分配GT。第二阶段就可以选择Top score的位置作为一个proposal,并作为decoder的输入。同时也应用上上面的Iterative Bounding Box Refinement。
主要结果如下
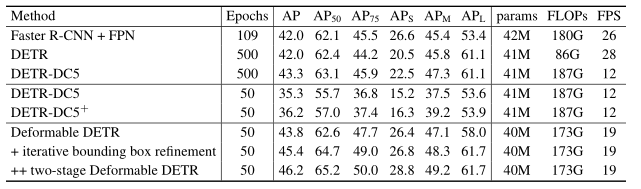
很好的解决的DETR作者提出的两个问题,同时也基本保持的原DETR的结构,所以说是直接正面解决DETR作者的两个问题的很好的方法。
5.2 Rethink Transformer-based Set Prediction for Object Detection
这篇也是作者相应的实验分析DETR模型的不足而做出对应的改进。主要有两点造成了模型的优化问题:(1)Hungarian算法分配的loss (2)Transformer中的cross-attention的瓶颈。
针对第一点作者做的如下实验:使用已经训练好的模型去指导GT的分配与原本的模型进行比较,结果如下图
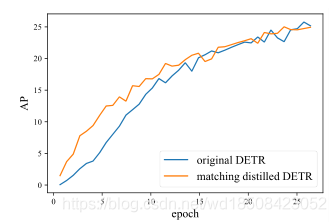
在模型早期,原本的模型的GT分配就是约等于随机分配的,这确实造成了早期训练时的不稳定性。(我觉得动态分配的GT都有早期不稳定的问题。)
针对第二点做的实验就是计算cross-attention map的负熵(用来表示attention map 的稀疏性)的变化,结果如下
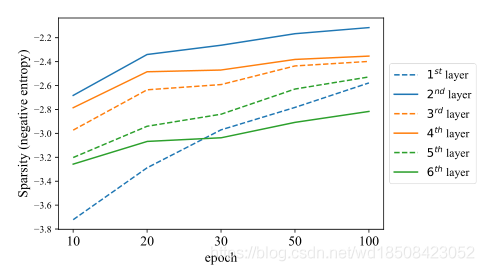
可以看到,在整个过程不论是那个layer的稀疏性都是在一直变化的,所以作者认为cross-attention部分是影响DETR模型优化的主要原因。
针对第二点作者直接去掉Transformer的Decoder部分,并在FCOS的网络上加以改进,总体结果图如下,TSP-FCOS、TSP-RCNN分别对应两个模型
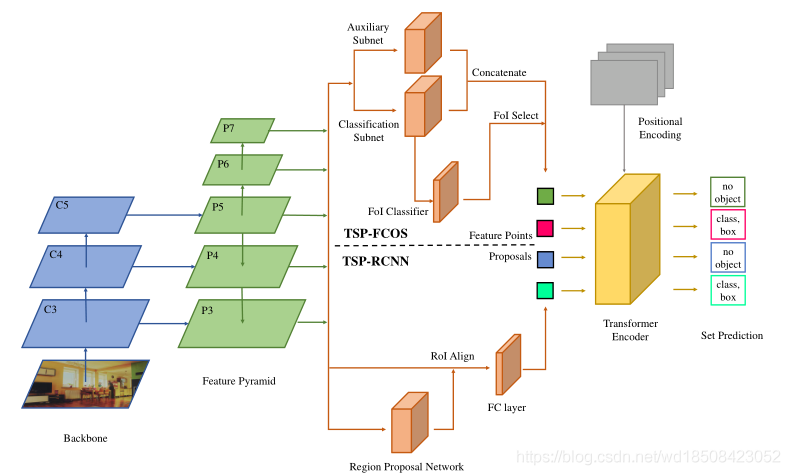
输入给Encoder的是什么呢?对于TSP-FCOS是一系列的FoI(Feature of Interest)就是些特征向量,这里的Classification有个监督信息,使用的是FCOS中的GT分配策略,即该点如果落在了正确feature level的GT框内则为正样本,FoI Select会选择出预测分数最高的前700个feature作为feature points。而相应 的TSP-RCNN则使用的FasterRCNN中的RPN分配GT的策略,然后也选前700个proposals作为feature points.
对应的最后面的set prediction的loss有些不一样,对于TSP-RCNN模型仍然沿用Faster-RCNN中的GT分配策略。对于TSP-FCOS使用改进的Hungarian loss分配,即在原来的Hungarian loss上添加约束,一个GT要分配给该点的前提是该点必须在正确的feature level上且该点必须在GT内,然后再在这个前提下利用Hungarian loss进行分配。(相当于添加了一个局部的先验约束)。
主要实验结果如下
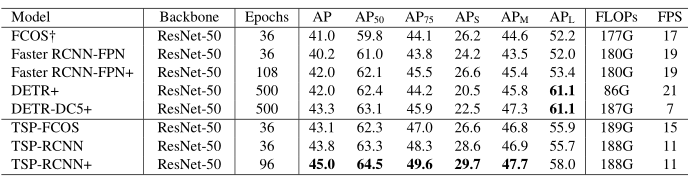
作者对cross-attention是主要瓶颈的结论还是很有道理的。
5.3 SparseRCNN
5.4 OneNet
5.5 End-to-End Object Detection with Fully Convolutional Network
5.6 UP-DETR
5.7 End-to-End Object Detection with Adaptive Clustering Transformer
参考文献
[1] Relation Networks for Object Detection
[2] End-to-End Object Detection with Transformers
[3] DEFORMABLE DETR: DEFORMABLE TRANSFORMERS FOR END-TO-END OBJECT DETECTION
[4] Rethinking Transformer-based Set Prediction for Object Detection
[5] Sparse R-CNN: End-to-End Object Detection with Learnable Proposals
[6] OneNet: End-to-End One-Stage Object Detection by Classificaion Cost
[7] End-to-End Object Detection with Fully Convolutional Network
[8] UP-DETR: Unsupervised Pre-training for Object Detection with Transformers
[9] End-to-End Object Detection with Adaptive Clustering Transformer
版权声明:本文为CSDN博主「请痛捶我」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/wd18508423052/article/details/111686666






