最近在梳理目标检测的YOLO系列相关算法,写此博客作为记录
YOLOV1
一. 简介
You Only Look Once: Unified, Real-Time Object Detection
论文地址:https://arxiv.org/abs/1506.02640
代码地址: https://github.com/pjreddie/darknet
发表:CVPR2016
整体思路是基于一个end-to-end的网络,将原始图像,只过一遍网络,就能得到物体的位置以及类别(即You Only Look Once之意)。
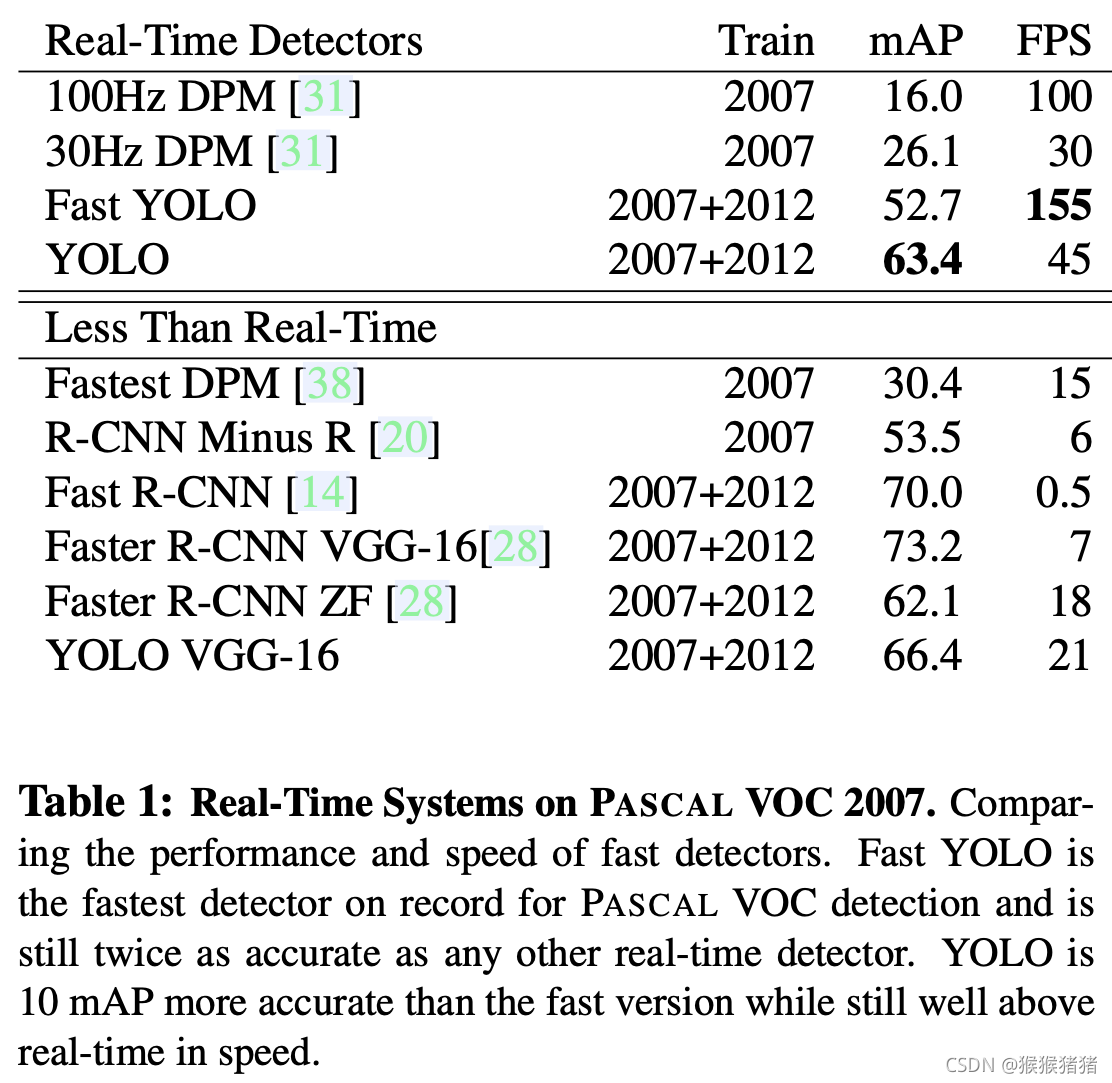
速度上:相较Faster RCNN 利用位置回归+类别分类实现目标检测,YOLO将目标检测转化为单纯的回归问题,故检测速度也可大大加
快。YOLO是45fps,精简版Fast YOLO可达155 fps。
效果上:整体精度(map@57.9 in pascal)不如Fast R-CNN(map@68.4 in pascal)以及Faster R-CNN(map@70.4 in pascal),localization error 会增多,但是背景里面的误召回会减少,但与Fast R-CNN互补后,能显著提升后者的精度(map@70.7 in pascal);且能从自然图像generalize到其他domain,泛化性强。
二. 网络结构
1. 问题定义
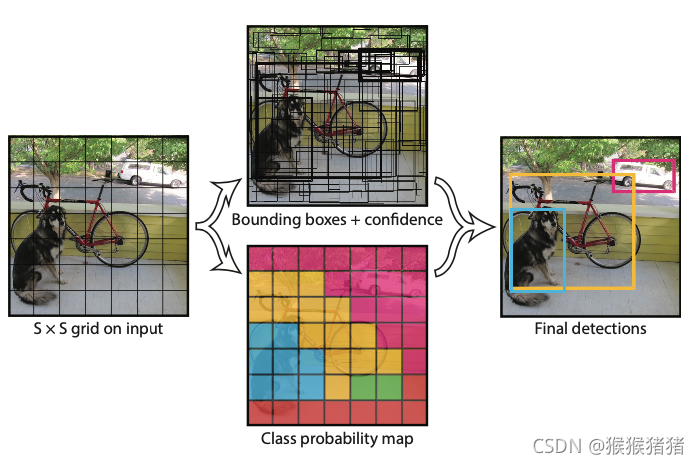 对于输入的图像 I,将其分割为S * S 个网格,如果物体的中心落在这个网格里面,则这个网格就负责对该物体进行预测,每一个 网格预测B个bounding box。
对于输入的图像 I,将其分割为S * S 个网格,如果物体的中心落在这个网格里面,则这个网格就负责对该物体进行预测,每一个 网格预测B个bounding box。
整个回归预测的内容包含如下两个部分:
【1】Bounding box + confidence: 每一个bouding box包含
x
,
y
,
w
,
h
x,y,w,h
x,y,w,h, 其中
(
x
,
y
)
(x,y)
(x,y)表示目标中心点相对于网格中心点(或者边界)的相对归一化距离。宽高
w
,
h
w,h
w,h是相对图像而言的归一化宽高。置信度指的是模型认为该box包含目标的信心,以及包含的准确程度,形式化表示为
P
r
(
O
b
j
e
c
t
)
∗
I
O
U
p
r
e
d
t
r
u
t
h
Pr(Object) * IOU^{truth}_{pred}
Pr(Object)∗IOUpredtruth,即预测的box与groudtruth box之间的IOU。如果没有物体存在与这个网格里面,则confidence为0。
【2】Class probability map:如果任务需要预测
C
C
C个类别,那么每个网格会得到一个
C
C
C维的条件概率,其中每一个值表示为
P
r
(
C
l
a
s
s
i
∣
O
b
j
e
c
t
)
Pr(Class_i |Object)
Pr(Classi∣Object),在实际测试过程中,还要乘以该box的置信度(虽然每个网格预测
B
B
B个bounding box,但是类别概率只预测一套),取argmax可得上图的类别map。
因此整个网络的输出为
S
×
S
×
(
B
×
5
+
C
)
S \times S \times (B\times5 + C)
S×S×(B×5+C)维度的tensor。对于Pacal VOC而言,
S
=
7
,
B
=
2
,
C
=
20
S = 7,B = 2,C = 20
S=7,B=2,C=20,即预测
7
×
7
×
30
7 \times 7 \times 30
7×7×30的tensor。
2. 网络结构

整体网络结构如上图所示,受GoogleNet启发,包含24层卷积层以及两层全连接层,没有完全用inception module而是用
1
×
1
1 \times 1
1×1卷积接
3
×
3
3 \times 3
3×3卷积取而代之。同时提出更精简的Fast YOLO来提升速度,除了卷积层数目由24缩为9之外,其他设置不变。
三. 训练细节
论文框架:Darknet
输入尺度:
448
×
448
448 \times 448
448×448
激活函数:Leaky ReLU
损失函数:
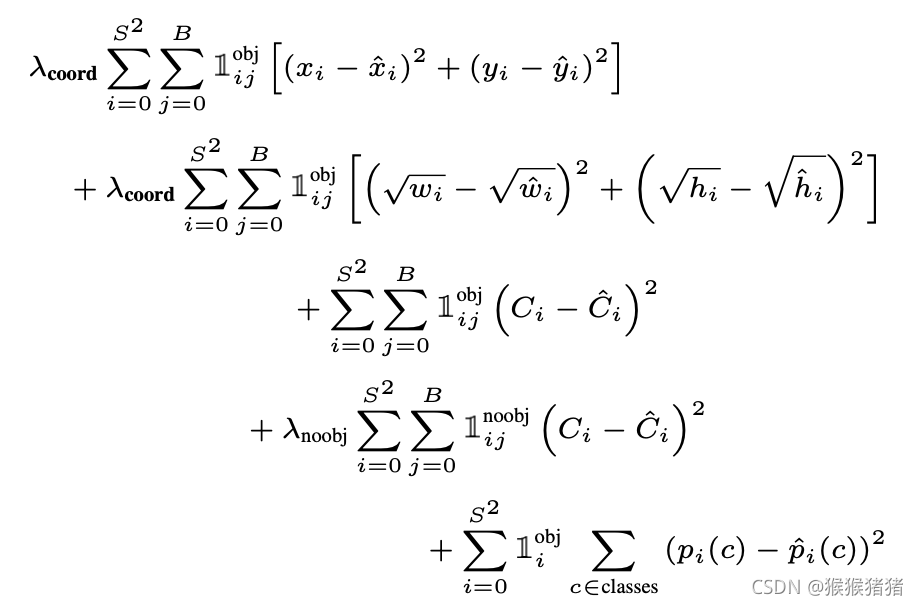
对损失函数的一些说明:
【1】
1
i
o
b
j
\mathbb{1_i^{obj}}
1iobj表示目标是否出现在第
i
i
i个网格,
1
i
j
n
o
o
b
j
1^{noobj}_{ij}
1ijnoobj表示第
i
i
i个网格中的第
j
j
j个bounding box负责对该目标进行预测。
【2】因为在图像中许多位置的网格是背景区域而没有包含目标物体,因此这些网格预测的confidence趋向于0,因此相对于有物体的单元格而言,前者的梯度往往占主导地位,因此可能会导致模型不稳定。因此
λ
c
o
o
r
d
=
5
\lambda_{coord}=5
λcoord=5与
λ
n
o
o
b
j
=
0.5
\lambda_{noobj}=0.5
λnoobj=0.5来增加拥有目标的网格的coodinate预测损失,而减少没有目标的网格的类别概率预测损失。
【3】大目标与小目标对宽高预测的精度容忍程度是不一样的,相同的偏差可能对大目标无关痛痒,但是对小目标而言,却影响很大,因此损失中并不是直接对归一化的长宽做MSE,而是开方(squre root)之后再算。
【4】只有当网格中有目标的时候,才对分类的损失进行惩罚。只有当某个box predictor对某个ground truth box负责的时候,才会对该box的coordinate error进行惩罚,所谓的负责,指的是一个网格预测多个box,但是希望,每个box专门负责一个目标,因此看该box与groudtruth中哪个box的IOU最高,就负责哪一个。
四. 实验结果
YOLO的一些先天不足,每一个网格预测两个bounding box,而且只能有一个类别,因此这种很强的空间约束,对于部分case会表现不佳,比如鸟群中的鸟(小目标),且容易导致错误的目标定位。
1. 速度对比
2. VOC 2007 Error Analysis
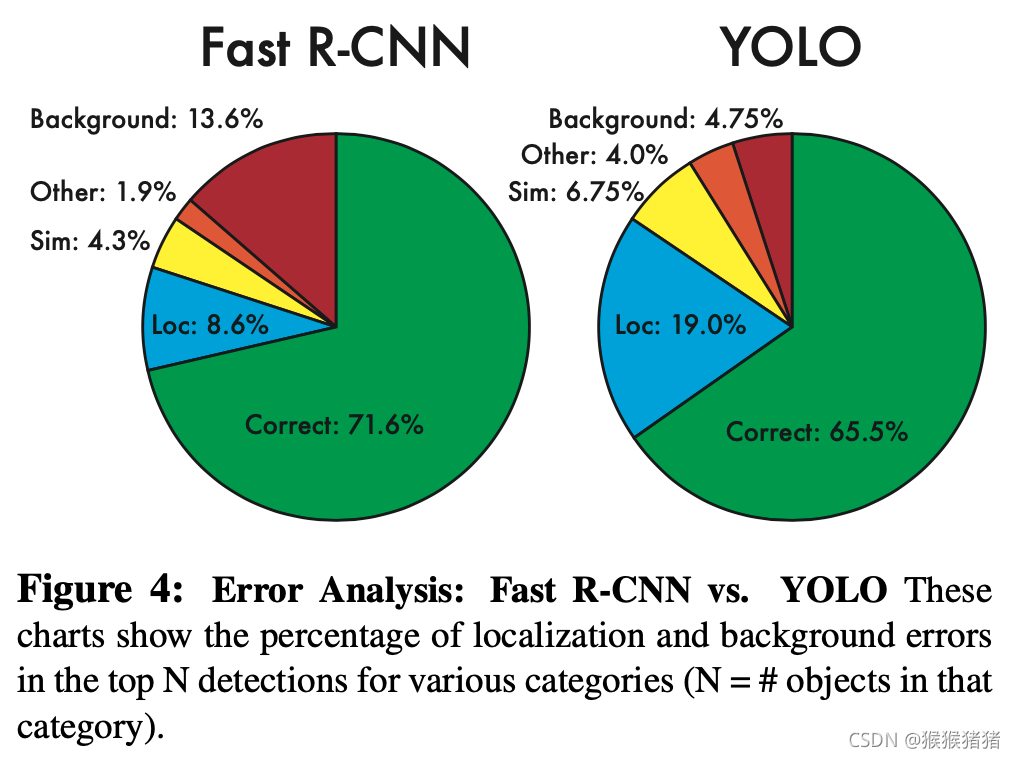
其中:
- Correct: correct class and IOU > 0.5
- Localization: correct class, 0.1 < IOU < 0.5
- Similar: class is similar, IOU > 0.1
- Other: class is wrong, IOU > 0.1
- Background: IOU < 0.1 for any object
3. Combining Fast R-CNN and YOLO
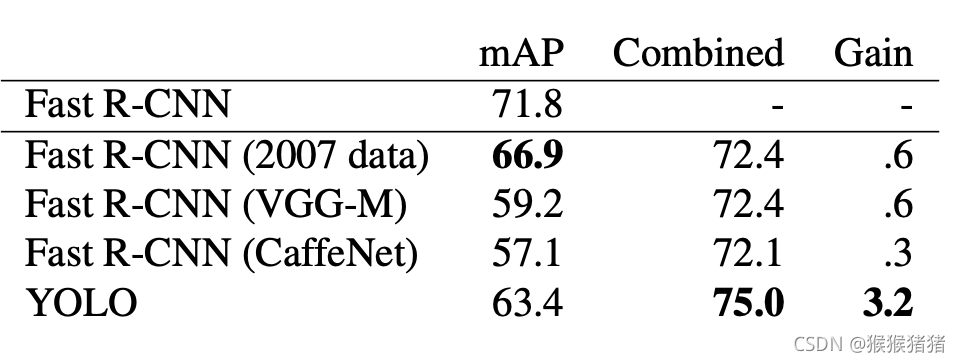
4. VOC 2012 Results
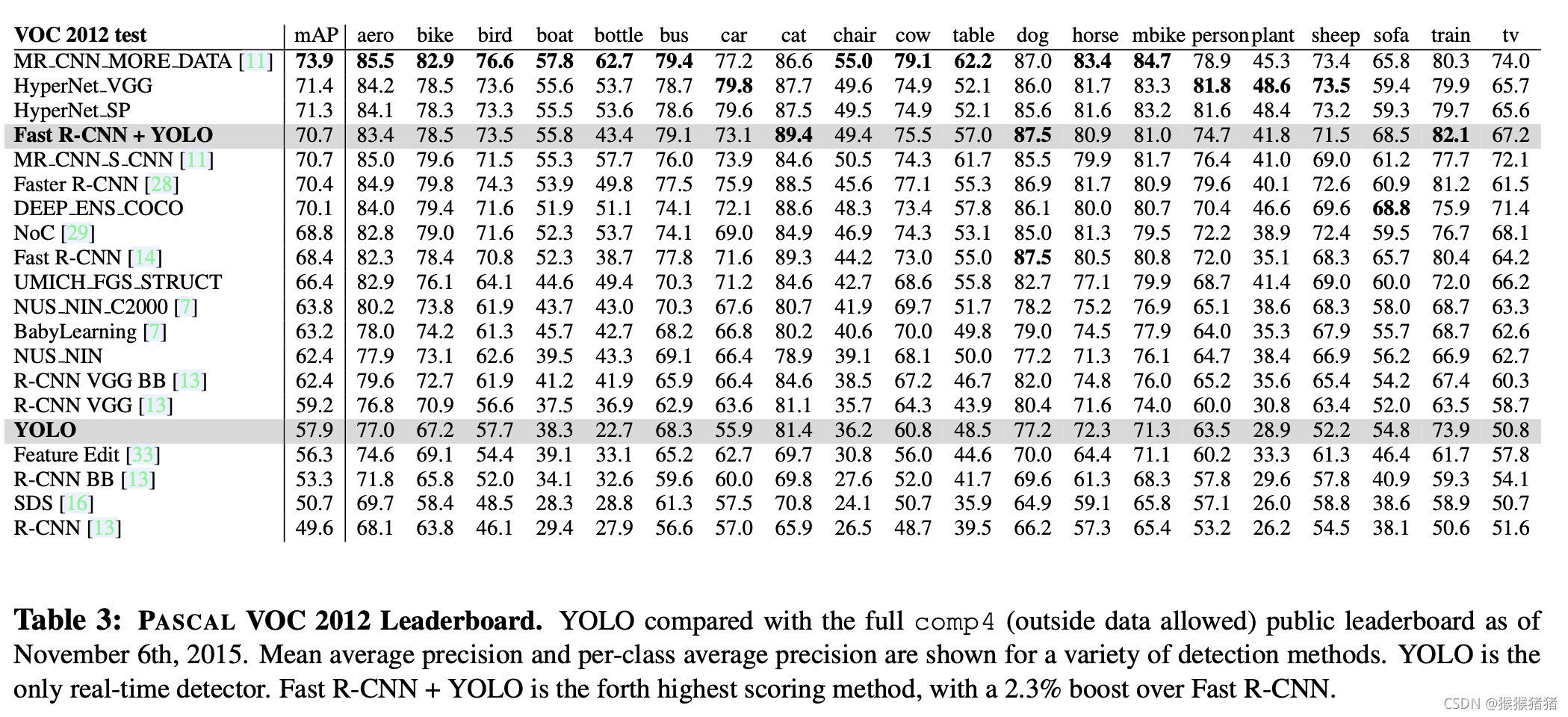
更多讲解可参考:
https://docs.google.com/presentation/d/1aeRvtKG21KHdD5lg6Hgyhx5rPq_ZOsGjG5rJ1HP7BbA/pub?start=false&loop=false&delayms=3000&slide=id.p
https://www.jianshu.com/p/cad68ca85e27
五. 总结
YOLOV2
一. 简介
YOLO9000: Better, Faster, Stronger
论文地址:https://arxiv.org/pdf/1612.08242.pdf
代码地址:http://pjreddie.com/yolo9000/
二. 网络结构
1. Better
YOLO存在的问题,在于召回率低以及关于定位(localization)的错误多,因此YOLOV2在保持分类准确率的前提下,希望对上述问题做得better。
借鉴现有的一些trick以及经验,在如下方面对YOLO进行改进。
1.1 bacth normalization
(加快收敛,正则化作用),mAP涨2个点。
1.2 High Resolution Classifier
原始YOLO是在
224
×
224
224 \times 224
224×224的分类器上,将分辨率增加到
448
×
448
448 \times 448
448×448来训练检测,因此YOLOV2直接以
448
×
448
448 \times 448
448×448为输入,让分类器在ImageNet上finetune 10个epochs,然后再训练检测,mAP涨4个点。
1.3 Convolutional With Anchor Boxes
YOLO是没有像Faster-RCNN一样利用anchor,相反,是利用全连接,直接预测box的x,y,w,h, (x,y)是相对网格中心点的归一化距离,w,h是相对整图的宽高,YOLOV2利用了anchor box来预测bounding box,剔除掉了全连接层,去掉一层pooling来获得更高分辨率的输出,且将输入由
448
×
448
448 \times 448
448×448变为
416
×
416
416 \times 416
416×416,让下采样32倍后的特征图尺寸为
13
×
13
13 \times 13
13×13,即尺寸是奇数,因此能让目标落在唯一的中心网格。因此与YOLO相比,预测了1000+ box,而不是
7
×
7
×
2
7\times7\times2
7×7×2个,如果利用anchor box的话, mAP为69.2 mAP ( -0.2% ), recall 为 88%( +7% )。
1.4 Dimension Clusters
如果考虑引入anchor的话,面临的第一个问题是手工挑选的anchor很难调整到与box相匹配,因此引入聚类的思想,自动生成anchor priors,并没有采用欧式距离来作为度量尺度,因为这样大的box会比小的box贡献更多的error,以IOU的角度度量距离,可以避免box尺度的影响:
d
(
b
o
x
,
c
e
n
t
r
o
i
d
)
=
1
−
I
O
U
(
b
o
x
,
c
e
n
t
r
o
i
d
)
d(box,centroid) = 1 −IOU(box,centroid)
d(box,centroid)=1−IOU(box,centroid)
下表是自动聚类与手工anchor的Avg IOU效果对比,可以发现的是kluster为5的效果已经与手工anchor为9效果接近,k为9的话,avg IOU为67.2,因此自动聚类获得anchor的方式能够获得一个更好的anchor先验,利于后面网络学习。 在COCO和VOC上聚类,可以发现两者都倾向于生成更瘦更高的anchor,但前者相较后者在尺寸的变化上会更多一些。
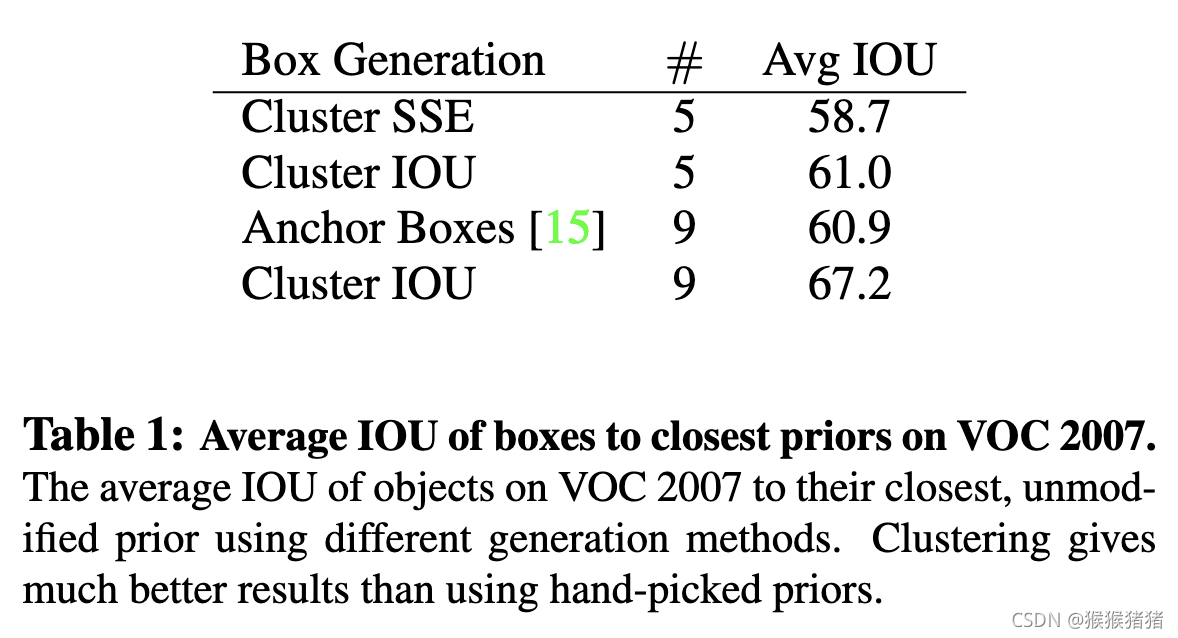
1.5 Direct location prediction
引入anchor遇到的第二个问题是模型训练极为不稳定,尤其是训练初期,大部分原因归咎于网络预测box的(x,y)需要很长时间才能稳定。对于中心点的坐标预测,往往预测tx,ty,然后进一步得到坐标,即
x
=
(
t
x
∗
w
a
)
−
x
a
y
=
(
t
y
∗
h
a
)
−
y
a
x = (t_x * w_a) - x_a \\ y = (t_y * h_a) - y_a
x=(tx∗wa)−xay=(ty∗ha)−ya
其中
w
a
,
h
a
w_a, h_a
wa,ha是anchor box的宽高,
x
a
,
y
a
x_a, y_a
xa,ya是anchor box的中心点,这是一种无约束的预测,即点可以落在图像的任意位置。改进方案是不预测offset,而是直接预测相对于网格单元的位置。
b
x
=
σ
(
t
x
)
+
c
x
b
y
=
σ
(
t
y
)
+
c
y
b
w
=
p
w
e
t
w
b
h
=
p
h
e
t
h
P
r
(
o
b
j
e
c
t
)
∗
I
O
U
(
b
,
o
b
j
e
c
t
)
=
σ
(
t
o
)
b_x = σ(t_x) + c_x \\ b_y = σ(t_y) + c_y \\ b_w = p_we^{t_w} \\ b_h = p_he^{t_h} \\ Pr(object) ∗IOU(b,object) = σ(t_o) \\
bx=σ(tx)+cxby=σ(ty)+cybw=pwetwbh=phethPr(object)∗IOU(b,object)=σ(to)
上图公式图形化说明如下:
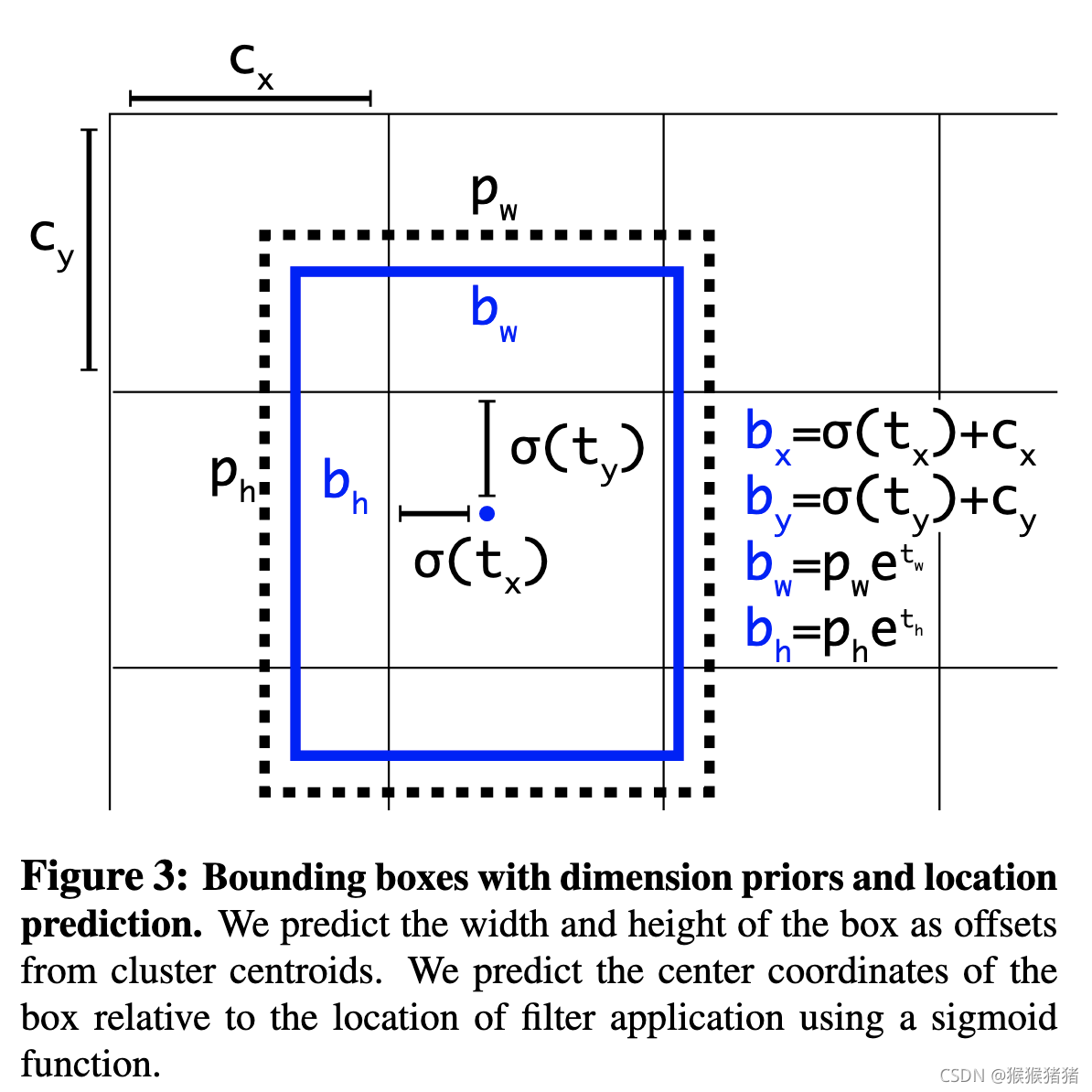
将
t
x
,
t
y
t_x, t_y
tx,ty sigmoid归一化到(0,1)之间,在输出特征图的每个网格cell,实际预测5个bounding box(相较5个anchor),每个bounding box预测
t
x
,
t
y
,
t
w
,
t
h
,
t
o
t_x, t_y, t_w, t_h, t_o
tx,ty,tw,th,to,在这种版本的anchor box基础上,YOLOV2涨点5%。
1.6 Fine-Grained Features
YOLOV2 输出的feature map是
13
×
13
13 \times 13
13×13,对于大的目标是足够的,但是为了定位更小的目标,有必要引入更加系列度的特征。不同于Faster RCNN以及SSD在不同的尺度的特征图上获取proposal, YOLOV2将先前层得到的
26
×
26
26 \times 26
26×26的特征图,通过passthrough layer来与最终的输出融合。具体融合的方式如下:将26 × 26 × 512的特征图转化为 13 × 13 × 2048的特征图(stacking adjacent features into different channels ),然后与输出的feature map进行拼接,得到细粒度增强的feature map。此举,能带来mAP 1%的增长。
1.7 Multi-Scale Training
不同于每次都将输入尺寸固定在416 × 416,YOLOV2 每隔一定iteration,会改变输入尺度,因为下采样的倍率是32,因此输入的尺度也是32的倍数,如{320, 352, …, 608}.,即最小输入尺度是320 × 320,最大输入尺度是608 × 608.
YOlOV2在不同尺度下的结果(速度以及准确率),以及与目标检测对比方法的对比
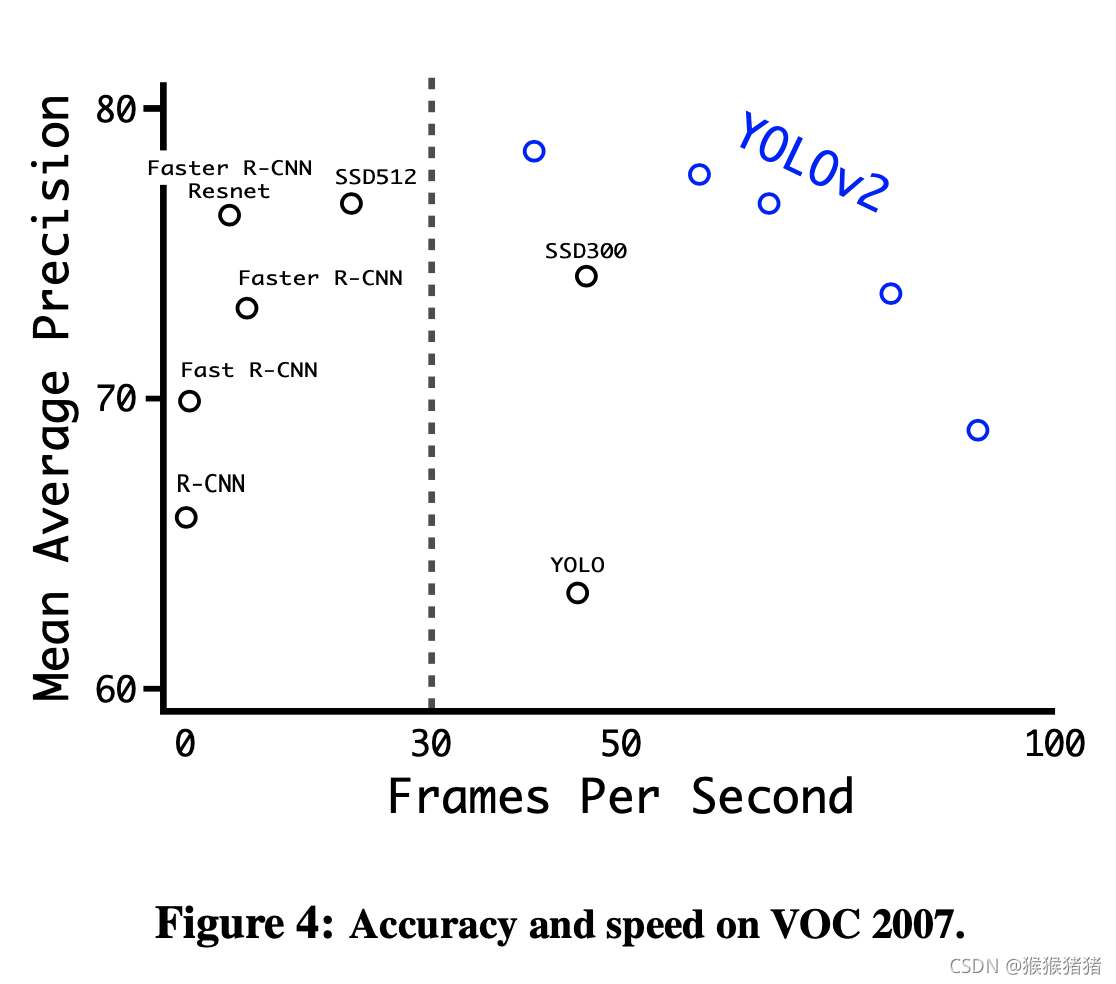
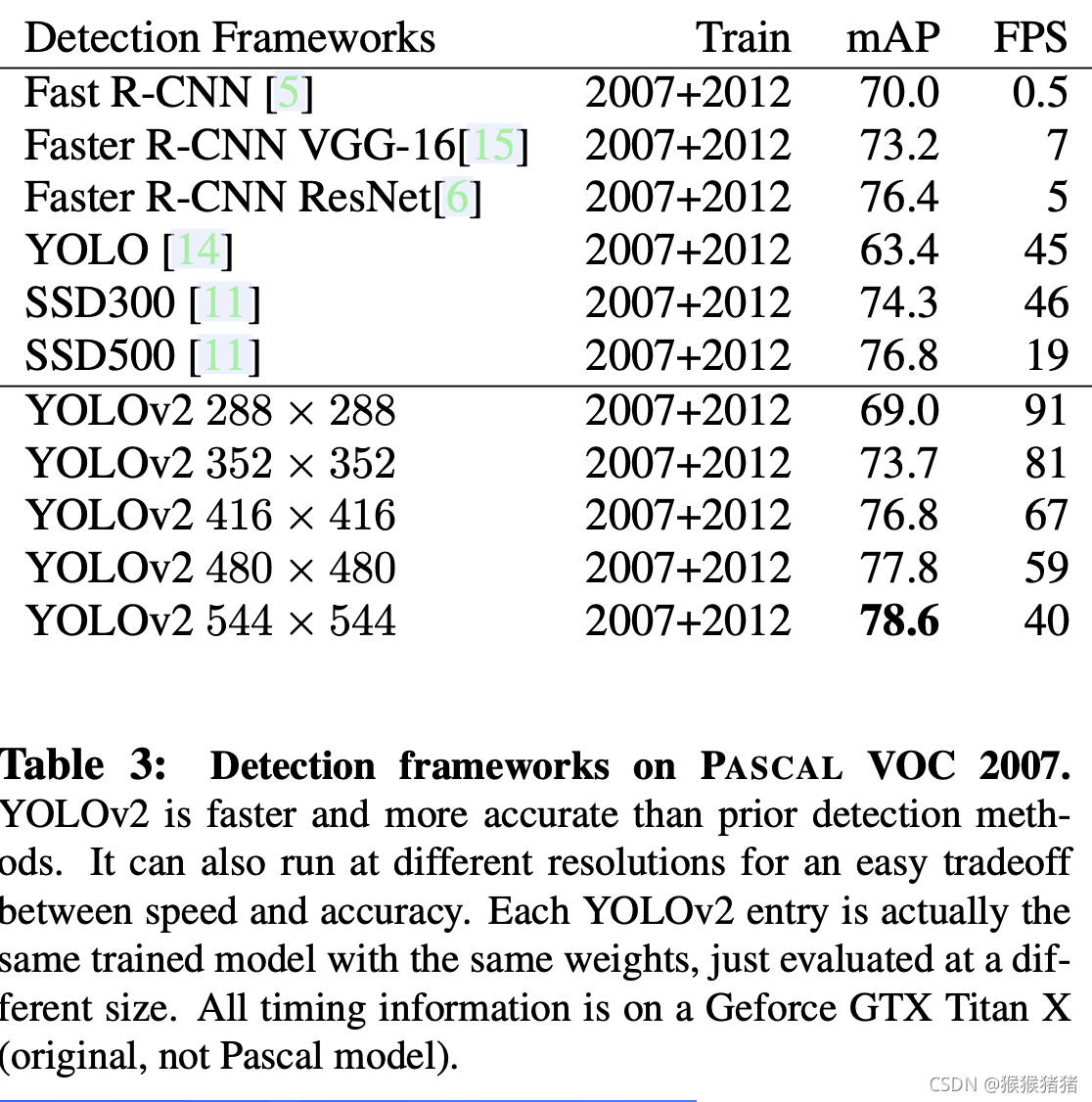
2. Faster
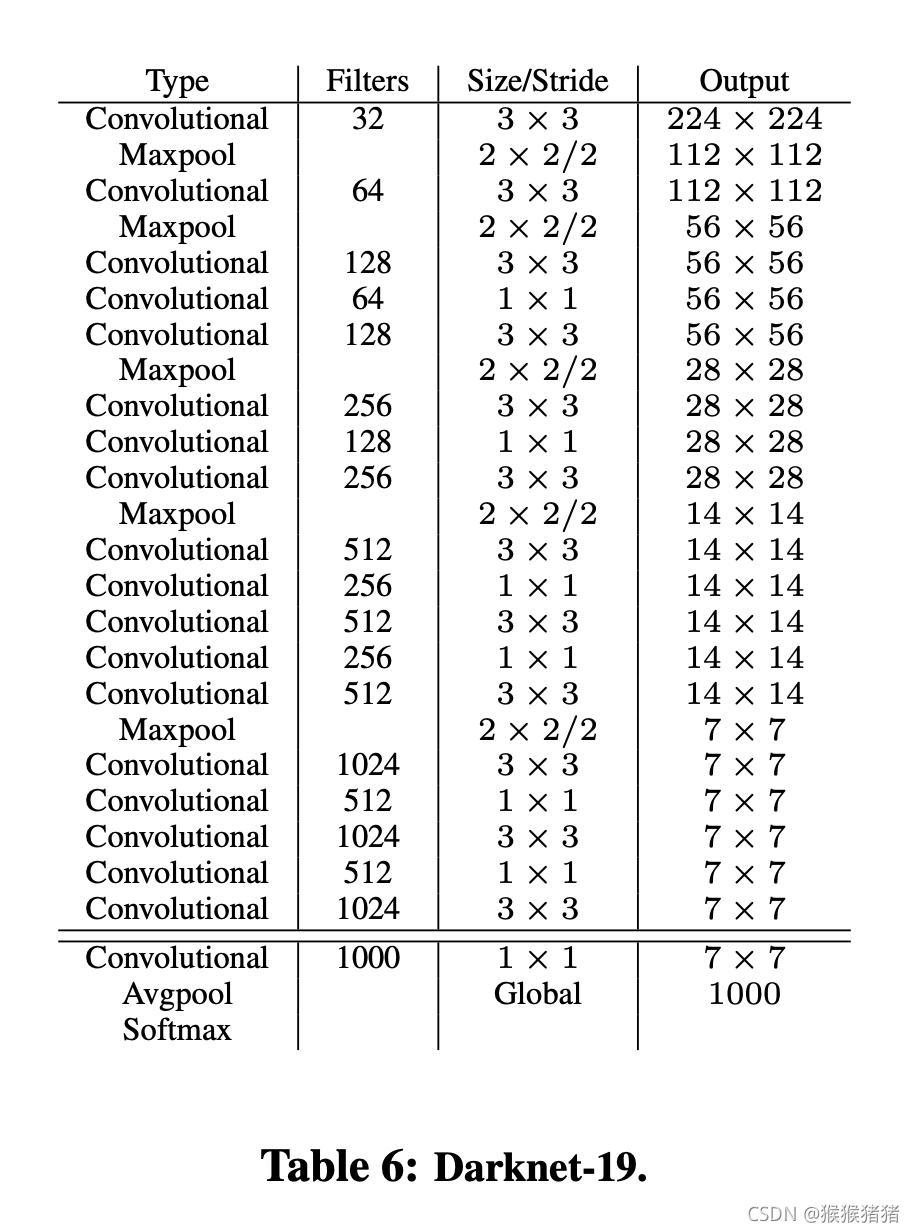
基础模型不采用vgg16,因为比较慢,采用的是自己提出的darknet-19分类网络,拥有19层卷积层以及5层max pooling,对于一张224 × 224的图像,只需要5.58 billion浮点数计算(vgg 30.69 billion),在ImageNet上是72.9%的top1 准确率,91.2%的top5准确率。
训练分类的时候,是先用224 × 224的尺度训练160个epoch,然后在448 × 448的尺度上fintune 10个epoch。
训练检测网络的时候,去除掉了最后一层卷积,增加三层 3×3卷积(1024 filters),然后接1 × 1卷积,得到我们想要的输出维度。举例来说,在VOC上,我们预测5个bounding box,每个box输出5个维度的cordinate以及20维度的classes,因此1 × 1卷积filter的数目就是5 × (5 + 20) = 125.
输入尺寸为224 × 224的darknet-19。
3.Stronger
因为ImageNet上的类别都是互斥的,而在coco上,比如狗这个类别,在ImageNet上,可能存在拉布拉多,牧羊犬等多个类别都属于狗,因此直接进行一个整体的softmax就显得不太合适,因此作者根据WordNet构造了一个WordTree,将原来的ImageNet的1000个类别,通过中间节点的方式,新增类别到1369个类别,然后在co-hyponyms(同下义词)层面上进行softmax。
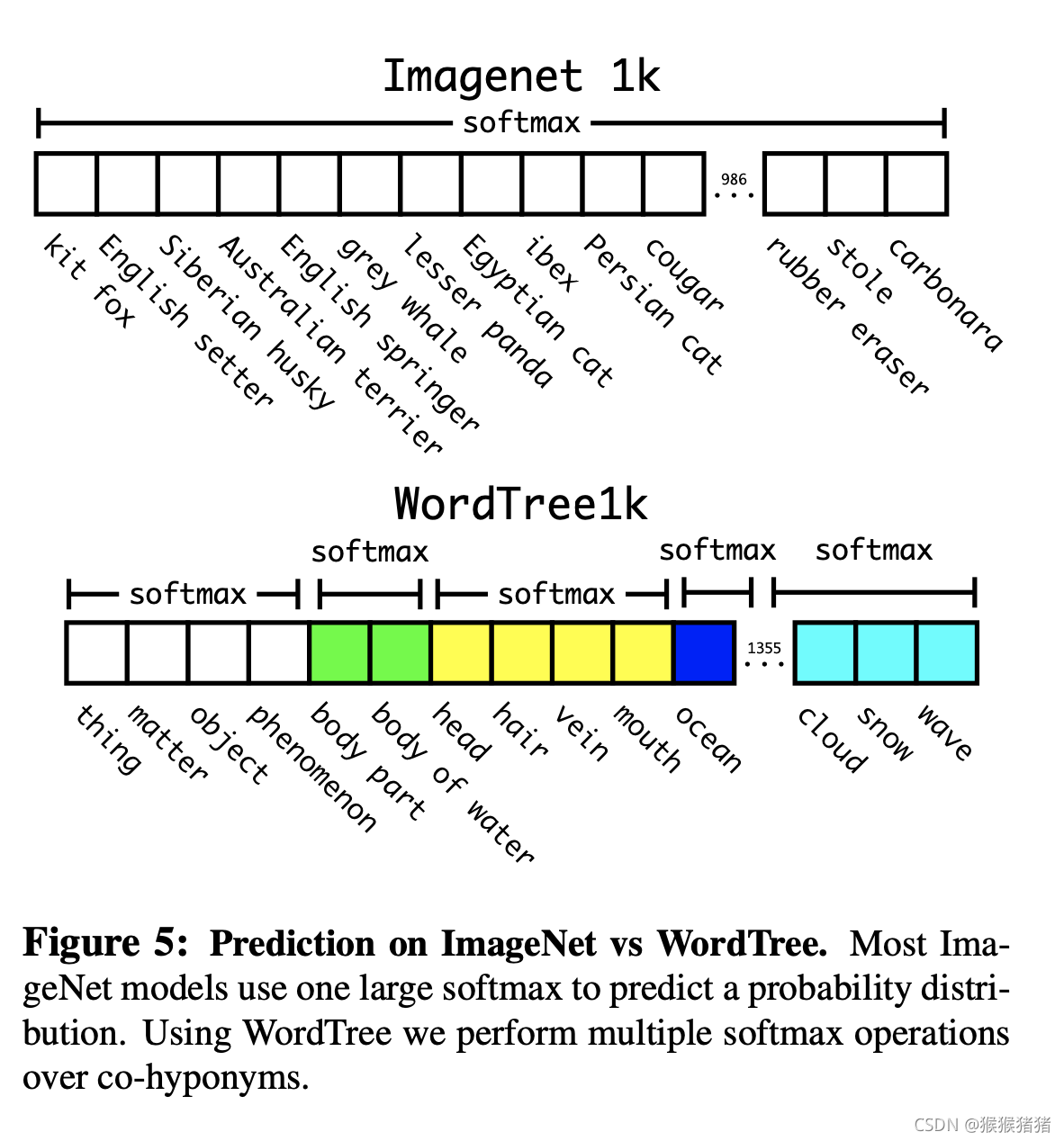
通过构造的WordTree也能很好地进行数据集的合并,最终整个WordTree的规模是9000+这是是论文标题YOLO9000的缘由.
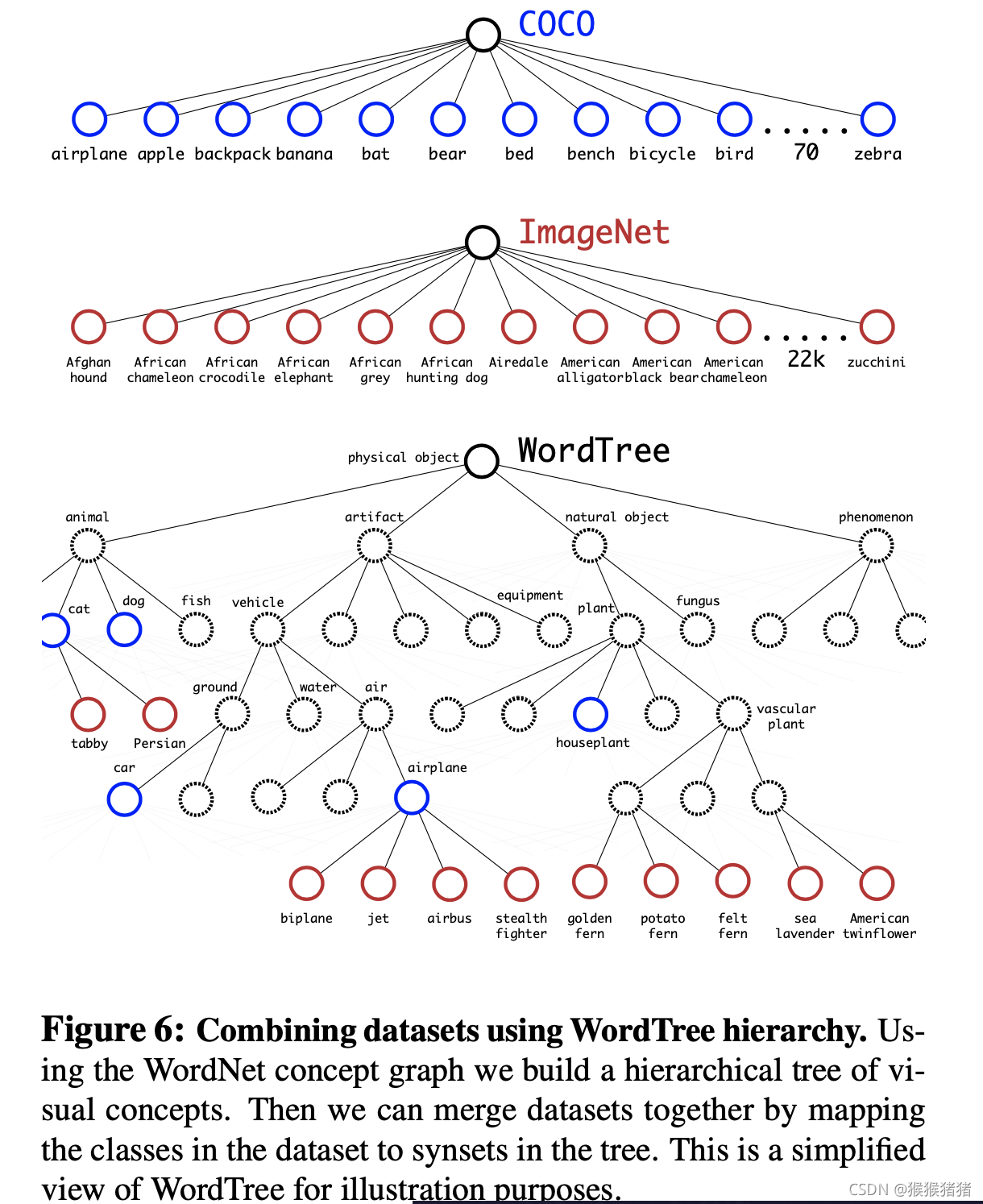
,但是大多数数据都是来自于ImageNet,即分类数据,这些图像都是没有检测的bounding box标注的,那么YOLO9000是怎样将检测与分类这两类数据进行联合训练检测的呢?
为了限制输出的维度不要太大,因此将prior的数目由5降到3,当网络遇到一个检测的图像时,损失正常反向传播,对于分类损失,仅仅反向传播at or above这个类别的损失,例如,如果标签是狗,那么就不回传德国牧羊犬vs金毛犬的分类损失,因为是没有对应的信息的。当看到的是一张分类的图像时,我们仅仅回传分类的损失,即我们将预测的到boxes,取其中得分最高的box,将该box的预测类别作为分类的类别,与ground truth的分类标签计算损失,而且我们也假定,预测的box与ground truth之间的IOU > 0.3,然后在这种假设之下,回传检测的损失。通过这种联合的训练,YOLO9000能够寻找到图像中目标的位置(基于coco的检测数据),与此同时能够对各种各样的目标进行分类(基于ImageNet的分类数据)。
当分析YOLO9000在ImageNet上的检测表现时,可以发现,其在动物类别的泛化性很好,即能够检测出需要coco中未见过的类别,但是在服饰以及器械方面的表现不佳,比如“sunglasses” 或者 “swimming trunks”. 因为coco并没有服饰相关的bounding box,而是仅仅标注了人。
YOLOV3
一. 简介
YOLOv3: An Incremental Improvement
论文地址:https://arxiv.org/abs/1804.02767
论文代码:https://pjreddie.com/darknet/yolo/
是一篇technical report rather than paper
二. 网络结构
预测box位置的方式与Yolov2一致,用logistic regression预测box得分,如果bounding box prior与ground truth的IOU相比于其他bounding box prior高,则该box score为1。与gt box有一定交叠(iou 满足一定阈值,实验中取0.5),但是得分不是最高的box,我们忽略掉这些box。对于每一个ground truth object,只分配一个bounding box prior。如果一个bounding box prior没有分配给某个ground truth,那么它不会产生coordinate与class prediction的loss,而仅仅有objectness的loss。
对于分类的loss而言,并不是用softmax,而是采用多标签分类,即多个 independent logistic classifiers,利用binary cross-entropy loss来预测类别,因为许多场景下,标签之间是有重叠以及覆盖的,比如女人和人,因此多标签的方法,更适用于复杂的场景。
YOLOV3在3个不同的尺度下来预测box,在coco上,每个尺度预测3个box,即最终的输出维度是这样一个3d的tensor: N ×N ×[3 ∗(4 + 1 + 80)]
其中N是feature map输出的网格数目,3指的是预测的3个box,4指的是coordinate,1指的是box score,80指的是类别的预测。
依旧采用kmeans的方式来生产anchor box priors,在coco上的9个cluster分别为 (10×13),(16×30),(33×23),(30×61),(62×45),(59×
119),(116 ×90),(156 ×198),(373 ×326)。
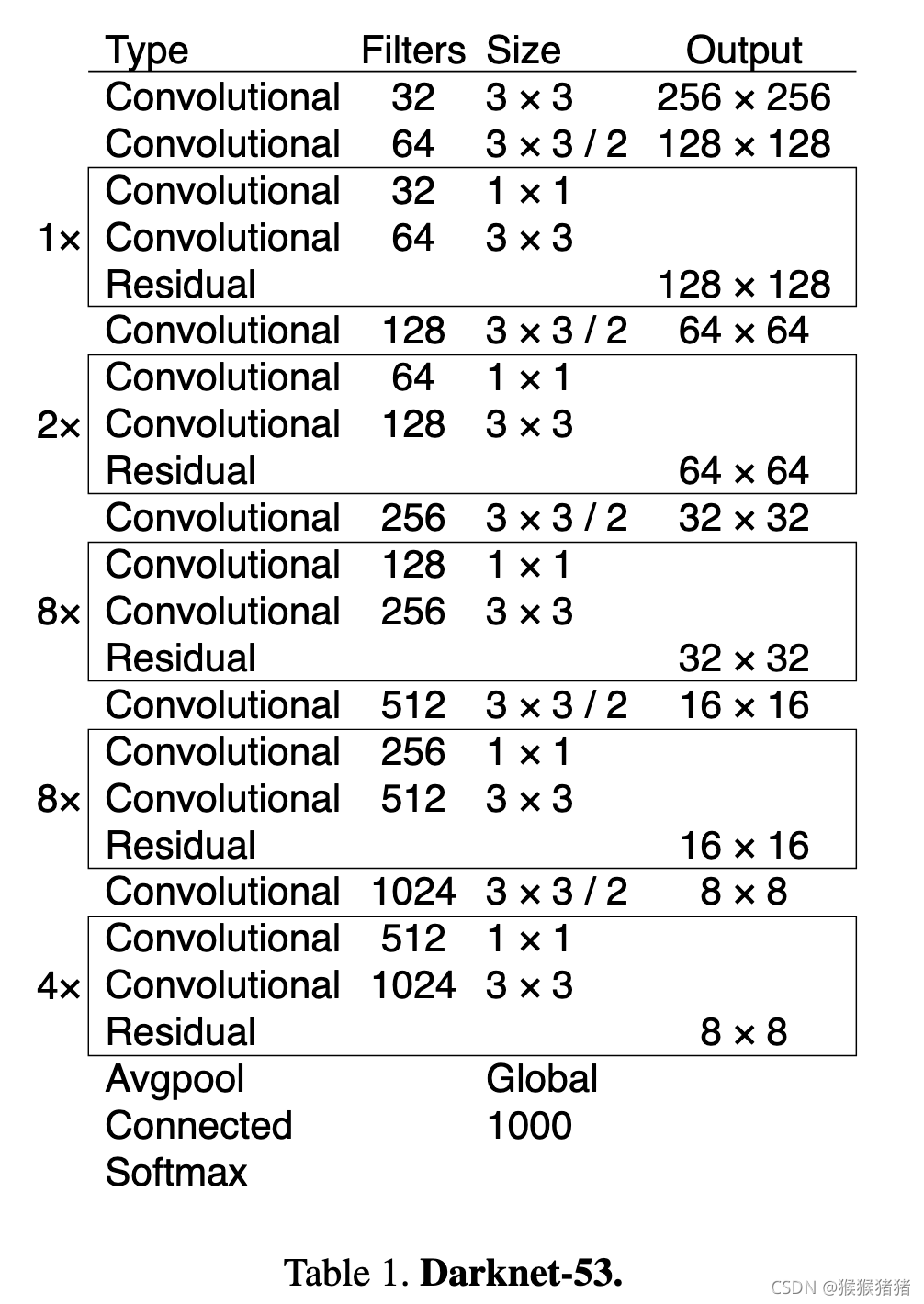
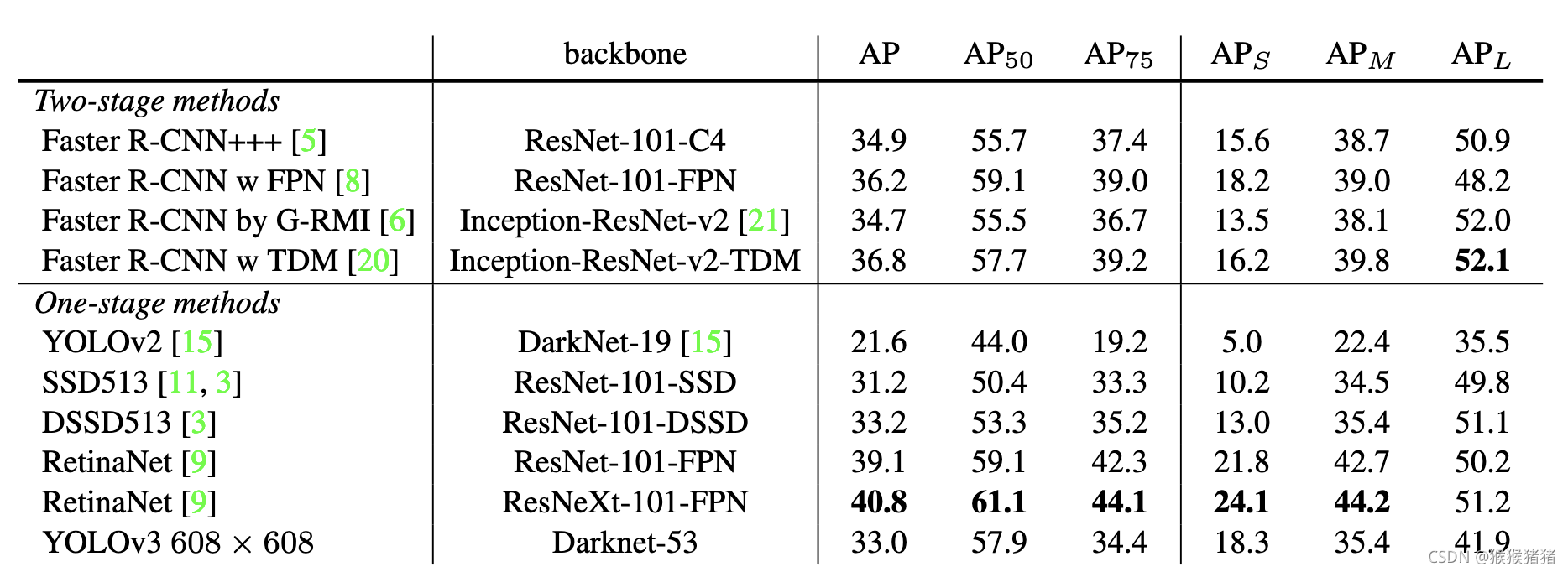
基本特征提取网络,用的不是darknet19,而是darknet53,效果更好,速度变慢。
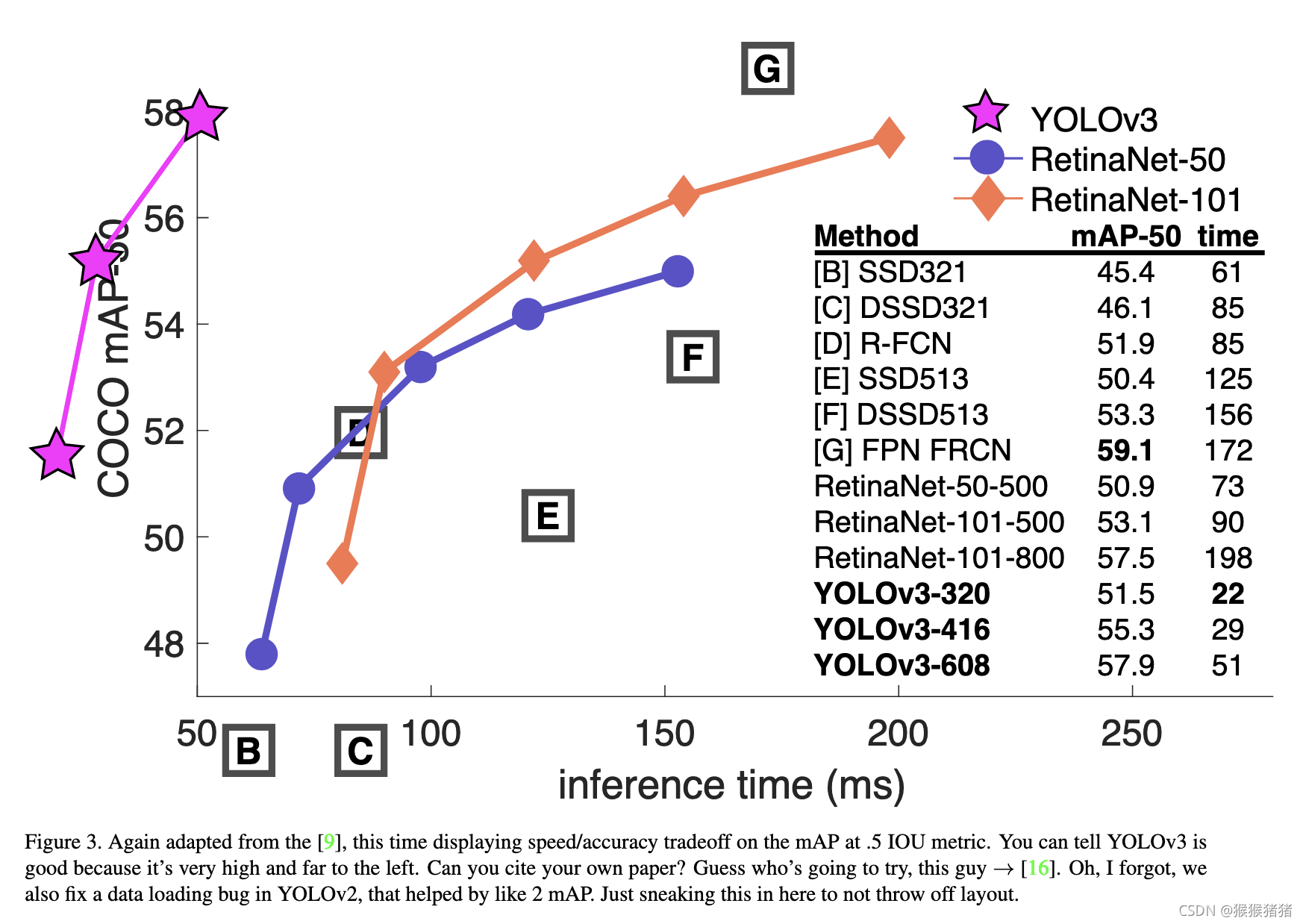
YOLOV4
一、简介
论文地址:https://arxiv.org/pdf/2004.10934.pdf
代码地址:https://github.com/AlexeyAB/darknet
一些检测器的分类:
Two stage检测器:R-CNN series, like fast R-CNN, faster R-CNN, R-FCN,Libra R-CNN
One stage 检测器:YOLO, SSD, RetinaNet
anchor free one stage检测器:CenterNet, CornerNet, FCOS等
neck往往是起到从不同阶段收集特征的作用,它往往由几个bottom-up路径和几个top-down路径组成,代表性的方法有Feature Pyramid Network(FPN), Path Aggregation Network(PAN), BiFPN, NAS-FPN等。
二、Bag of freebies
Bag of freebies指的是在训练的时候,采用的一些方法,这些方法能够让模型有更好的准确率,但是不会增加推理的负担,因此将这种只会增加训成本的训练策略叫做bag of freebies。
2.1 数据增强
光度畸变(photometric distortions) 和几何畸变(geometric distortions)是两种常用的目标检测数据增强方式,前者
YOLOV5
版权声明:本文为CSDN博主「猴猴猪猪」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/pku_langzi/article/details/120808625






