文章目录[隐藏]
- 视觉招聘小黑板
- 行业资讯
- OPT(奥普特)3D视觉检测在锂电的应用--机器视觉网 2023-12-12 15:04:06
- 南京大目视觉检测系统,助力吸管质检--机器视觉网 2023-12-12 14:54:17
- SmartGS®技术引领工业视觉革新―新闻频道- 视觉系统设计 2023/12/11 23:30:13
- 深视智能高速相机助力端子生产工艺升级―技术与应用频道- 视觉系统设计 2023/12/11 23:25:36
- 深视智能点激光陶瓷片厚度检测―技术与应用频道- 视觉系统设计 2023/12/11 23:21:17
- 【论文阅读】FIGSTEP: JAILBREAKING LARGE VISION-LANGUAGE MODELS VIA TYPOGRAPHIC VISUAL PROMPTS 2023-12-12 11:11
- 【论文阅读】Query-Relevant Images Jailbreak Large Multi-Modal Models 2023-12-12 11:30
- 【论文阅读】Jailbroken: How Does LLM Safety Training Fail? 2023-12-12 10:44
- Vary:扩充Vision Vocabulary,提升LVLM的dense和细粒度视觉感知能力 2023-12-12 11:29
- 阿里真人跳舞视频生成方案来了!高质量单步文生图;无反演文本编辑图像方法;运动可定制文生视频 2023-12-11 21:57
- 领域最全 | 计算机视觉算法在路面坑洼检测中的应用综述(基于2D图像/3D LiDAR/深度学习) 2023-12-12 08:56
- 最新突破!稀疏表示与两阶段训练策略赋予BeV分割新境界 2023-12-12 19:50
- AAAI 2024 | 让小姐姐跳起来!清华&港科大&腾讯提出:姿势可控的角色视频生成新工作 2023-12-12 17:35
- 高效视觉Transformer的综述:算法,技术和性能基准 2023-12-12 06:46
- CV计算机视觉每日开源代码Paper with code速览-2023.12.11 2023-12-11 22:47
- Monitoring Plant Growth using Computer Vision: 2023-12-12T10:44:34.000Z
- What is Few-Shot Learning?: 2023-12-12T08:09:18.000Z
- Launch: Advanced Ontology Management with Roboflow: 2023-12-11T17:58:13.000Z
视觉招聘小黑板
欲了解详情,请在公众号后台回复:231212
行业资讯
OPT(奥普特)3D视觉检测在锂电的应用--机器视觉网 2023-12-12 15:04:06
2023-12-12 15:04:06 来源: 中国机器视觉网
新能源锂电行业正迈向TWh时代,终端厂商既要保障电池产品全生命周期可靠性,又要大幅提高生产效率,打造TWh级别超大规模交付能力。机器视觉是保障锂电池性能与品质的关键一环,厂商对锂电池视觉检测重视程度持续增加,同时也对视觉检测的精度和效率提出更高的要求。
自2015年起,OPT(奥普特)开始部署锂电视觉检测应用,通过不断深入了解锂电池行业的发展趋势和客户需求,开发出一系列适合电池行业的视觉软硬件产品和解决方案,目前已实现锂电全工序覆盖。
如针对中后段的缺陷检测和高精度测量,OPT推出了3D视觉检测方案,提供性能和选型丰富3D传感器,可满足各种成本、精度、视野需求;配套的Smart3视觉软件集成了丰富的3D算法,采用高度易用的拖放式编程,极大地缩
......长按二维码访问原文

南京大目视觉检测系统,助力吸管质检--机器视觉网 2023-12-12 14:54:17
2023-12-12 14:54:17 来源: 中国机器视觉网
产品概述
吸管在生产过程中难免会出现外观瑕疵,比如体长、体短、油污、黑点等,对吸管的质量造成非常大的影响。公司依托机器视觉技术,采用工业相机和图像处理技术研发了智能吸管质量检测系统,其在速度和精度上都达到了工业应用的级别。系统用于吸管生产商和奶制品生产企业的各种类型的吸管(白色、条纹等)外观缺陷、内部缺陷检测和颜色分拣。
总体结构
系统采用结构化设计,主要包括如下几个核心部分:吸管送料整列装置、吸管图像采 集装置、吸管剔废装置和图像处理软件。 吸管采集装置包括吸管内部图像采集装置和外部图像采集装置;内部图像采集装置包括1个工业相机和1个光源组成,主要用于采集吸管内部的图像。外部图像采集装置使用1-2个工业相机和工业光源,主要采集吸管正面和反
......长按二维码访问原文

SmartGS®技术引领工业视觉革新―新闻频道- 视觉系统设计 2023/12/11 23:30:13
与其他领域采取的卷帘快门(Rolling Shutter)曝光方式不同,高速运动物体造成的形变伪影可能产生的误差将在机器视觉场景下被无限放大,拥有高帧率、无畸变的全局快门(Global Shutter)成为了工业面阵应用和智能交通系统的首选。
面阵应用全景解析
在全局快门技术方面,思特威公司具有先发优势。自2017年起,思特威便开始布局机器视觉应用领域,并着手研发SmartGS®技术。基于该技术,思特威迅速推出了全球首颗采用BSI像素架构和全局快门技术的图像传感器产品,并成功应用于工业面阵图像传感器领域。目前此技术已经迭代到第二代SmartGS®-2,相较于第一代技术大大提升了夜视效果,感度和高温性能。在第二代的基础上思特威2022年又推出了SmartGS®-2 Plus技术,通过High Density
......长按二维码访问原文

深视智能高速相机助力端子生产工艺升级―技术与应用频道- 视觉系统设计 2023/12/11 23:25:36
接线端子是电气设备中设置在导线端部,用于连接接线柱的元件,主要由一段密封在绝缘塑料中的金属片组成,其两端都具有可以插入导线的孔位,适合大量导线互联的工况,广泛应用于家用电器和工业设备等产品中。
在接线端子的生产过程中,金属片会被安插到端子的绝缘塑料中,而插入的状态也与产品质量息息相关。由于安插工序的机械动作速度快、端子产品体积小等因素,生产中容易出现金属片插入位置偏差及抖动等状况。
为提升接线端子的产品质量和生产效率,厂商们使用深视智能高速相机清晰记录下产品加工时金属片插入绝缘塑料的过程,观察插入位置的准确性以及插入过程的稳定性等,对生产工艺的改进提供了重要的参考数据。
机械动作观测
拍摄配置
型号:SH6-504-M-40
分辨率:2048×1024
帧率:3000fps
深视智能国产高速摄像
......长按二维码访问原文

深视智能点激光陶瓷片厚度检测―技术与应用频道- 视觉系统设计 2023/12/11 23:21:17
陶瓷片是电子电器、机械设备、汽车制造等应用领域的重要零部件,具有出色的绝缘、耐高温、抗电击穿等特性。然而受烧制工艺的影响,陶瓷片在生产过程中会因操作人员对温湿度变化以及材料特性的把控不当出现厚度超标等不良情况。
陶瓷片的特性和性能与自身的厚度密切相关,为保证后续产品的安装和性能,深视智能使用了SG系列激光位移传感器对陶瓷片的厚度进行高精度检测,非接触式的激光测厚方式不容易对陶瓷片造成损坏,避免划痕、形变、断裂等瑕疵的出现。
检测需求
产品名称:陶瓷片
测量项目:厚度
测量过程
陶瓷片的厚度测量采用传感器上下对射的方式,使用SG系列点激光同步连续采集检测数据,通过网口通讯,将测厚值发送给上位机并测试不同位置的点数据,而上位机则可通过判断陶瓷片的厚度区分NG料。
检测过程中,单个控制器SG5001能够
......长按二维码访问原文

【论文阅读】FIGSTEP: JAILBREAKING LARGE VISION-LANGUAGE MODELS VIA TYPOGRAPHIC VISUAL PROMPTS 2023-12-12 11:11

提出了一种针对视觉语言模型的新型越狱框架
论文地址:https://arxiv.org/abs/2311.05608
代码地址: GitHub - ThuCCSLab/FigStep: Jailbreaking Large Vision-language Models via Typographic Visual Prompts
1.Motivation
VLM可以分为三个模块:
语言模块:是一个预先训练的LLM,已经安全对齐 。
视觉模块:是一个图像编码器,将图像提示转换为视觉特征。
连接模块:将视觉特征从视觉模块映射到与语言模块相同的嵌入空间。
然而,大多数现有的开源vlm,都没有经过整体的安全评估,仅仅依靠底层的LLM作为安全护栏。因此vlm的安全特性主要取决于其基础LLM的安全特性。
......长按二维码访问原文

【论文阅读】Query-Relevant Images Jailbreak Large Multi-Modal Models 2023-12-12 11:30

论文地址: https://arxiv.org/abs/2311.17600
代码地址: GitHub - isXinLiu/MM-SafetyBench
1. Motivation
本文的研究是由观察到一个现象引起的。
如图1所示当图像与恶意查询不相关时,大型多模态模型(LMM)通常会会拒绝回应。这是因为此时大型语言模型组件占主导地位,大语言模型是经过了安全训练的,所以能够识别有害查询。
当图像与恶意查询密切相关时, 大型多模态模型(LMM)有一定的的概率会响应所提出的查询,但这个概率也是不高的。这是因为查询相关图像的存在激活了模型的视觉语言对齐模块,该模块通常没有进行安全训练,导致模型无法识别有害查询。
图1
图1下表的结果显示了在这三种有害场景中,使用与查询相关的图像攻击模型的成功率高于使用
......长按二维码访问原文

【论文阅读】Jailbroken: How Does LLM Safety Training Fail? 2023-12-12 10:44

越狱:大语言模型安全训练何以失败
本文的目标是分析LLM能够被越狱的原因
论文地址:https://arxiv.org/abs/2307.02483
1.Jailbreak 介绍
随着大模型的应用越来越广泛,有一些人就想利用大模型去获得一些有害信息。所以现在的大语言模型在预训练之后都会经过安全训练阶段,这个阶段会设置一些安全措施,比如过滤和对齐等,让模型的输出符合人类价值观,训练它拒绝提供有害信息的请求,如图1这种有害问题,它就会拒绝回答.
图1
越狱攻击就是通过设计Prompt ,绕过大模型开发者为其设置的安全和审核机制,利用大模型对输入提示的敏感性和容易受到引导的特性,诱导大模型生成不合规的、本应被屏蔽的输出。如图2这个越狱的例子:攻击者通过对“如何生成毒品”这个有害问题设计一个对
......长按二维码访问原文

Vary:扩充Vision Vocabulary,提升LVLM的dense和细粒度视觉感知能力 2023-12-12 11:29
很高兴向大家介绍我们最近在探索增强多模态大模型细粒度视觉感知方面的新工作:Vary。
Vary充分探索了视觉词表对感知能力的影响,提供了一套有效的视觉词表扩充方法。通过在公开数据集以及我们渲染的文档图表数据上训练,在保持vanilla多模态能力的同时,还激发出了端到端的中英文图片、公式截图和图表理解能力,是一套视觉感知上限极高的通用多模态框架。
Vary是我们在这个方向上的初步探索,目前Vary的基础版 demo 已经上线,代码和模型均已开源,欢迎试玩和反馈,我们将继续增强Vary作为基座的各项能力,感谢大家的持续关注!
如果我们的工作对你有所启发,也希望能在Github为我们点上一个 Star!
Project page:
Demo:
Demo的网页版和手机版(夜间主题)
Demo的网页版和手机
......长按二维码访问原文

阿里真人跳舞视频生成方案来了!高质量单步文生图;无反演文本编辑图像方法;运动可定制文生视频 2023-12-11 21:57

DreaMoving: A Human Dance Video Generation Framework based on Diffusion Models
本文提出了一种基于扩散模型的可控视频生成框架DreaMoving,用于生成高质量的定制化人类舞蹈视频。具体来说,给定目标ID和姿势序列,DreaMoving可以由姿势序列驱动,在任何位置生成目标ID跳舞的视频。
SwiftBrush: One-Step Text-to-Image Diffusion Model with Variational Score Distillation
本文提出了一种名为SwiftBrush的新型无图像模型蒸馏方案,使用特定的损失将文本到图像的扩散先验转化为与输入提示一致的3D神经辐射场,
......长按二维码访问原文

领域最全 | 计算机视觉算法在路面坑洼检测中的应用综述(基于2D图像/3D LiDAR/深度学习) 2023-12-12 08:56
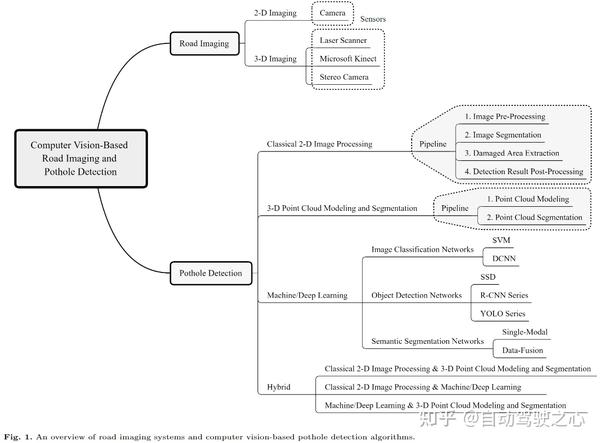
摘要
计算机视觉算法在3D道路成像和路面坑洼检测中的应用已有二十多年的历史。尽管如此,目前还缺乏有关最先进(SoTA)的计算机视觉技术的系统调研文章,尤其是为解决这些问题而开发的深度学习模型。本文首先介绍了用于2D和3D道路数据采集的传感系统,包括摄像机、激光扫描仪和微软Kinect。随后,对 SoTA 计算机视觉算法进行了全面深入的综述,包括: (1)经典的2D图像处理,(2)3D点云建模与分割,(3)机器/深度学习。本文还讨论了基于计算机视觉的路面坑洼检测方法目前面临的挑战和未来的发展趋势: 经典的基于2D图像处理和基于3D点云建模和分割的方法已经成为历史; 卷积神经网络(CNN)已经展示了引人注目的路面坑洼检测结果,并有望在未来的进展中打破瓶颈的自/无监督学习多模态语义分割。作者相信本研究可为下一代道路
......长按二维码访问原文

最新突破!稀疏表示与两阶段训练策略赋予BeV分割新境界 2023-12-12 19:50
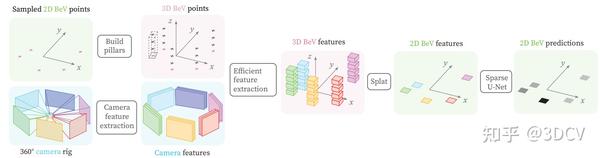
1、导读
BeV是一种将多个摄像头的图像聚合在一起的表示方式,用于实现自动驾驶中的场景理解和目标检测。然而,从摄像头图像到构建BeV地图的过程具有挑战性,需要进行深度估计和三维几何建模。过去的研究主要集中在通过学习将图像特征投影到BeV空间中,但这种方法缺乏解释性,并且对深度估计要求较高。此外,过去的方法在处理长时间序列时存在计算复杂度高的问题。因此,本文提出了一种稀疏的BeV预测方法,旨在提高效率和准确性,并允许处理更长的时间序列。
2、研究思路
本研究提出了一种稀疏的BeV(Bird's-eye View)预测方法,名为PointBeV。该方法旨在通过从图像中高效提取特征并进行时间聚合,实现对BeV的准确预测。
3、研究内容
研究人员提出了一种名为PointBeV的方法,该方法通过从图像中高效提取
......长按二维码访问原文

AAAI 2024 | 让小姐姐跳起来!清华&港科大&腾讯提出:姿势可控的角色视频生成新工作 2023-12-12 17:35

本文设计了一种新颖的两阶段训练方案,可以利用易于获得的数据集(即图像姿势对和无姿势视频)和预训练的文本到图像(T2I)模型来获得姿势可控的角色视频。
论文:https://arxiv.org/abs/2304.01186
代码链接(已开源):https://github.com/mayuelala/FollowYourPose
主页:https://follow-your-pose.github.io/
现在点击关注 @CVer官方知乎账号,可以第一时间看到最优质、最前沿的CV、AI工作~
现如今,生成文本可编辑和姿势可控的角色视频在创建各种数字人方面具有迫切的需求。然而,由于缺乏一个全面的数据集,该数据集具有成对的视频姿势字幕和视频的生成性先验模型,因此这项任务受到了限制。在这项工作中,我们设计了一
......长按二维码访问原文

高效视觉Transformer的综述:算法,技术和性能基准 2023-12-12 06:46

23年9月综述论文“A survey on efficient vision transformers: algorithms, techniques, and performance benchmarking“,来自悉尼大学。
视觉Transformer(ViT)架构正变得越来越流行,并被广泛用于处理计算机视觉应用。它们的主要特征是通过自注意机制提取全局信息的能力,优于早期的卷积神经网络。然而,ViT的部署和性能随着其规模、可训练参数量和操作而稳步增长。此外,自注意的计算和内存成本,随图像分辨率的二次方增加。一般来说,由于许多硬件和环境限制,如处理和计算能力,在现实世界的应用中使用这些架构是具有挑战性的。因此,本综述调查了确保次优估计性能的最高效方法。更详细地说,分析四个有效类:紧凑架构、修剪、知识蒸馏和量
......长按二维码访问原文

CV计算机视觉每日开源代码Paper with code速览-2023.12.11 2023-12-11 22:47
精华置顶
墙裂推荐!小白如何1个月系统学习CV核心知识:链接
点击@CV计算机视觉,关注更多CV干货
论文已打包,点击进入—>下载界面
点击加入—>CV计算机视觉交流群
1.【语义分割】(NeurIPS2023)Augmentation-Free Dense Contrastive Knowledge Distillation for Efficient Semantic Segmentation
2.【点云分割】FRNet: Frustum-Range Networks for Scalable LiDAR Segmentation
3.【多模态】Prompt Highlighter: Interactive Control for Multi-Modal LLMs
4.【多模态】GPT-4V
......长按二维码访问原文

Monitoring Plant Growth using Computer Vision: 2023-12-12T10:44:34.000Z
The article below was contributed by Timothy Malche, an assistant professor in the Department of Computer Applications at Manipal University Jaipur.
Measuring plant growth is essential for several reasons in agricultural, ecological, and scientific contexts. For example, plant growth metrics provide valuable information for use in optimizing crop yield, man
......长按二维码访问原文

What is Few-Shot Learning?: 2023-12-12T08:09:18.000Z

Humans excel at identifying new objects with minimal examples. This is a feat for many machine learning methods that typically demand thousands of instances to match such proficiency.
Earlier in the last decade, computer vision research concentrated on addressing specific tasks using vast image datasets. In recent years, however, there has been greater expl
......长按二维码访问原文

Launch: Advanced Ontology Management with Roboflow: 2023-12-11T17:58:13.000Z
Having the correct class ontology is crucial for a smooth labeling process, reducing annotation mistakes, and enabling top model performance. We are excited to introduce a new class management page, available for all projects in the Roboflow dashboard. This page is the new central hub for adding, renaming, and deleting your classes and managing annotation co
......长按二维码访问原文







