文章目录[隐藏]
- 视觉招聘小黑板
- 行业资讯
- OPT(奥普特)3D视觉检测在锂电的应用--机器视觉网 2023-12-12 15:04:06
- 南京大目视觉检测系统,助力吸管质检--机器视觉网 2023-12-12 14:54:17
- SmartGS®技术引领工业视觉革新―新闻频道- 视觉系统设计 2023/12/11 23:30:13
- 海康机器人SE系列多扩展服务器―产品聚焦频道- 视觉系统设计 2023/12/12 22:29:03
- 大界联合梅卡曼德新一代3D坡口切割解决方案―技术与应用频道- 视觉系统设计 2023/12/12 23:01:58
- D:PLOY平台实现打破自动化壁垒―技术与应用频道- 视觉系统设计 2023/12/12 22:47:45
- OPT智能读码器精准识码―技术与应用频道- 视觉系统设计 2023/12/12 22:39:11
- 控制工程网-全球工控自动化和智能制造门户网站 2023/11/14 14:00:00
- 动态拍摄也轻松!海康机器人发布1.03亿全局万兆网相机 2023/11/14 14:00:00
- 经典应用丨光伏行业扫码追溯新标杆,海康机器人AI智能读码器! 2023/12/13 15:20:06
- 【论文阅读】FIGSTEP: JAILBREAKING LARGE VISION-LANGUAGE MODELS VIA TYPOGRAPHIC VISUAL PROMPTS 2023-12-12 11:11
- 【论文阅读】Query-Relevant Images Jailbreak Large Multi-Modal Models 2023-12-12 11:30
- 【论文阅读】Jailbroken: How Does LLM Safety Training Fail? 2023-12-12 10:44
- Vary:扩充Vision Vocabulary,提升LVLM的dense和细粒度视觉感知能力 2023-12-12 11:29
- 高效视觉Transformer的综述:算法,技术和性能基准 2023-12-12 06:46
- Far3D:直接干到150m,视觉3D目标检测新思路(AAAI2024) 2023-12-12 21:00
- 2.9倍加速!高效GPU训练推理库 | 助力点云模型部署! 2023-12-13 14:38
- 大湾区大学(筹)余梓彤课题组与中国科学技术大学张卫明教授联合招收人工智能方向博士后 2023-12-12 21:34
- CV计算机视觉每日开源代码Paper with code速览-2023.12.12 2023-12-12 23:20
- 视觉Transformer的高效性对比分析 2023-12-12 04:47
- 爆火!最强Text-to-3D开源方案LucidDreamer:毛发都给你合成出来! 2023-12-13 14:43
- ICCV2023最佳论文——ControlNet 2023-12-13 10:58
- 清华大学提出RepViT-SAM:实时分割一切 2023-12-13 19:52
- 英伟达最新发布!超越其它所有SOTA的3D目标检测 2023-12-13 14:14
- 北大&清华最新开源 | 三项SOTA!MasQCLIP:开放词汇通用图像分割新网络 2023-12-13 14:32
- 加速40倍!EdgeSAM:在移动设备上高效部署SAM 2023-12-12 21:30
- 最新多目标跟踪综述(100多篇论文) 2023-12-13 08:46
- How to Use Grounded EdgeSAM: 2023-12-13T09:33:40.000Z
- Text Summarization using T5: Fine-Tuning and Building Gradio App: 2023-12-12T14:00:00+00:00
视觉招聘小黑板
欲了解详情,请在公众号后台回复:231213
行业资讯
OPT(奥普特)3D视觉检测在锂电的应用--机器视觉网 2023-12-12 15:04:06
2023-12-12 15:04:06 来源: 中国机器视觉网
新能源锂电行业正迈向TWh时代,终端厂商既要保障电池产品全生命周期可靠性,又要大幅提高生产效率,打造TWh级别超大规模交付能力。机器视觉是保障锂电池性能与品质的关键一环,厂商对锂电池视觉检测重视程度持续增加,同时也对视觉检测的精度和效率提出更高的要求。
自2015年起,OPT(奥普特)开始部署锂电视觉检测应用,通过不断深入了解锂电池行业的发展趋势和客户需求,开发出一系列适合电池行业的视觉软硬件产品和解决方案,目前已实现锂电全工序覆盖。
如针对中后段的缺陷检测和高精度测量,OPT推出了3D视觉检测方案,提供性能和选型丰富3D传感器,可满足各种成本、精度、视野需求;配套的Smart3视觉软件集成了丰富的3D算法,采用高度易用的拖放式编程,极大地缩
......长按二维码访问原文

南京大目视觉检测系统,助力吸管质检--机器视觉网 2023-12-12 14:54:17
2023-12-12 14:54:17 来源: 中国机器视觉网
产品概述
吸管在生产过程中难免会出现外观瑕疵,比如体长、体短、油污、黑点等,对吸管的质量造成非常大的影响。公司依托机器视觉技术,采用工业相机和图像处理技术研发了智能吸管质量检测系统,其在速度和精度上都达到了工业应用的级别。系统用于吸管生产商和奶制品生产企业的各种类型的吸管(白色、条纹等)外观缺陷、内部缺陷检测和颜色分拣。
总体结构
系统采用结构化设计,主要包括如下几个核心部分:吸管送料整列装置、吸管图像采 集装置、吸管剔废装置和图像处理软件。 吸管采集装置包括吸管内部图像采集装置和外部图像采集装置;内部图像采集装置包括1个工业相机和1个光源组成,主要用于采集吸管内部的图像。外部图像采集装置使用1-2个工业相机和工业光源,主要采集吸管正面和反
......长按二维码访问原文

SmartGS®技术引领工业视觉革新―新闻频道- 视觉系统设计 2023/12/11 23:30:13
与其他领域采取的卷帘快门(Rolling Shutter)曝光方式不同,高速运动物体造成的形变伪影可能产生的误差将在机器视觉场景下被无限放大,拥有高帧率、无畸变的全局快门(Global Shutter)成为了工业面阵应用和智能交通系统的首选。
面阵应用全景解析
在全局快门技术方面,思特威公司具有先发优势。自2017年起,思特威便开始布局机器视觉应用领域,并着手研发SmartGS®技术。基于该技术,思特威迅速推出了全球首颗采用BSI像素架构和全局快门技术的图像传感器产品,并成功应用于工业面阵图像传感器领域。目前此技术已经迭代到第二代SmartGS®-2,相较于第一代技术大大提升了夜视效果,感度和高温性能。在第二代的基础上思特威2022年又推出了SmartGS®-2 Plus技术,通过High Density
......长按二维码访问原文

海康机器人SE系列多扩展服务器―产品聚焦频道- 视觉系统设计 2023/12/12 22:29:03
多扩展服务器,专用于机器视觉集成多个高分辨率相机的应用领域。近日,海康机器人新发布SE系列多扩展服务器,满足机器视觉行业对高性能、高可扩展及高存储性的应用需求。
服务器已集成常用接口,运行稳定。内置电源设计能满足现场对于扩展卡和供电的需求,集成IPMI远程专用管理端口,提高运维效率。
1.强劲性能
CPU性能更进一步
搭载Intel先进处理器,较传统处理器性能提升30%;CPU具备12核心24线程,拥有优秀的多任务并行能力;含多个内置加速器,极大提升AI、分析、网络、存储的性能。
2. 超强的扩展能力
7*PCIex16/8槽
采用工业级多扩展槽主板,提供7个PCIex16/8插槽,可轻松扩展 1张 GPU + 6 张采集卡、6倍的万兆卡、CXP卡、光口卡接入能力。
3. 高速存图方案
应对日
......长按二维码访问原文

大界联合梅卡曼德新一代3D坡口切割解决方案―技术与应用频道- 视觉系统设计 2023/12/12 23:01:58
大界联合梅卡曼德推出新一代3D坡口切割解决方案
针对建筑钢构、煤机、工程机械、船舶等行业的坡口切割工艺领域,大界与梅卡曼德联合推出了新一代3D坡口切割解决方案,基于图特征约束的粗精一体定位方法,摒弃了传统激光多次扫描寻边定位,实现拍照一次即刻全局定位,自动生成切割轨迹,自适应复杂环境和各种类型工件,满足柔性化生产。
平面工件的加工现状
效率低,精度差
在钢结构加工领域,平面工件的二次加工是一大类机加内容,主要是对下料后的边缘进行开坡口、铣削R角、打磨去毛刺等。但工件经过前道加工后,常因热变形出现整体略微屈曲,边缘与图纸存在偏差等缺陷。
目前,与图纸相比略有变形(弯曲或边缘偏移)的加工定位,主要通过以下三种方式:
面对小批量多品种的工件,以上方式已经不能适应行业的柔性化生产需求。大界作为中国领先的智能
......长按二维码访问原文

D:PLOY平台实现打破自动化壁垒―技术与应用频道- 视觉系统设计 2023/12/12 22:47:45
OnRobot推出其备受期待的旗舰平台D:PLOY,全球皆可使用,以实现打破自动化壁垒、助力各种规模的企业获益于协作自动化的使命。D:PLOY是业界首个用于构建、运行、监视和重新部署协作应用程序的自动化平台,通过自动化机器人应用程序的启动和运行,实现在生产车间直接部署或重新部署完整的应用程序,只需简单操作,无需编程,几小时内即可完成。D:PLOY平台目前支持码垛、数控机床管理、包装和转移(取放)应用,未来还将支持更多操作。
“D:PLOY平台及其能够切实普及自动化的能力是OnRobot一直以来旨在达成的一个目标,多年来我们已打下了坚实的基础。” OnRobot首席执行官Enrico Krog Iversen表示: “今天,我们已经能为所有机器人领导品牌提供业内种类最多的工具和应用——全部基于我们的‘一个系统,
......长按二维码访问原文

OPT智能读码器精准识码―技术与应用频道- 视觉系统设计 2023/12/12 22:39:11
工业读码技术作为获取产品编码信息的关键途径,被广泛用于生产过程控制、仓储物流等领域,读码效率和准确率是衡量读码器性能的重要标准。为提升条码读取率,OPT(奥普特)智能读码器内置深度学习算法及畸变矫正算法,极大地提高了倾斜、脏污、对比度差等复杂场景的读取能力;并采用高精度成像单元及多通道匀光照明系统,全面提升图像质量,提高条码定位精度,读码更精准。
内置深度学习算法,稳定读取各类条码
OPT目前已推出六大系列智能读码器,分辨率覆盖0.4~20MP,能满足不同工业场景的读码需求。
智能读码器内置深度学习算法,拥有大量样本数据,自适应学习目标码的高级语义特征信息,不受条码损坏、模糊、脏污、低对比度及印刷质量差等情况影响,能快速定位码点,大幅度提升复杂场景的读码能力,读取率更高。
如锂电池行业,从原料到成品及运
......长按二维码访问原文

控制工程网-全球工控自动化和智能制造门户网站 2023/11/14 14:00:00
大分辨率相机存图方案
应对1.5亿及以上大分辨率相机高帧率存图需求 www.cechina.cn ,采用PCIex8插槽RAID卡,一张卡搭配2张高速写入Nvme固态组RAID0,理论最大传输速度可达10GB/s≈100Gbps。
多相机处理方案
应对需要同时处理多张采集卡数据的应用时,由于传统工控机自身扩展槽数量和显卡厚度等因素限制,未能满足需要的扩展性能;而SE系列服务器其特有的多卡插槽特性和独特槽位设计,能够在规避显卡遮挡的同时提供至多扩展6个PCIex8卡槽的采集卡。
......长按二维码访问原文

动态拍摄也轻松!海康机器人发布1.03亿全局万兆网相机 2023/11/14 14:00:00
传感器全面升级
01高性能CMOS传感器
相机采用长光辰芯GMAX32103传感器,具备低噪声和高动态范围的特点,可以在不同的光照条件下,捕捉到被测物上的细微差异,提高检测的准确性和灵敏度。例如在面板检测中,对亮度和色彩响应更加出色,可提供更高的检测标准。
......长按二维码访问原文

经典应用丨光伏行业扫码追溯新标杆,海康机器人AI智能读码器! 2023/12/13 15:20:06
得到贵公司产品详细资料
得到贵公司产品的价格信息
贵公司产品销售人员联系我
贵公司技术支持人员联系我
......长按二维码访问原文

【论文阅读】FIGSTEP: JAILBREAKING LARGE VISION-LANGUAGE MODELS VIA TYPOGRAPHIC VISUAL PROMPTS 2023-12-12 11:11

提出了一种针对视觉语言模型的新型越狱框架
论文地址:https://arxiv.org/abs/2311.05608
代码地址: GitHub - ThuCCSLab/FigStep: Jailbreaking Large Vision-language Models via Typographic Visual Prompts
1.Motivation
VLM可以分为三个模块:
语言模块:是一个预先训练的LLM,已经安全对齐 。
视觉模块:是一个图像编码器,将图像提示转换为视觉特征。
连接模块:将视觉特征从视觉模块映射到与语言模块相同的嵌入空间。
然而,大多数现有的开源vlm,都没有经过整体的安全评估,仅仅依靠底层的LLM作为安全护栏。因此vlm的安全特性主要取决于其基础LLM的安全特性。
......长按二维码访问原文

【论文阅读】Query-Relevant Images Jailbreak Large Multi-Modal Models 2023-12-12 11:30

论文地址: https://arxiv.org/abs/2311.17600
代码地址: GitHub - isXinLiu/MM-SafetyBench
1. Motivation
本文的研究是由观察到一个现象引起的。
如图1所示当图像与恶意查询不相关时,大型多模态模型(LMM)通常会会拒绝回应。这是因为此时大型语言模型组件占主导地位,大语言模型是经过了安全训练的,所以能够识别有害查询。
当图像与恶意查询密切相关时, 大型多模态模型(LMM)有一定的的概率会响应所提出的查询,但这个概率也是不高的。这是因为查询相关图像的存在激活了模型的视觉语言对齐模块,该模块通常没有进行安全训练,导致模型无法识别有害查询。
图1
图1下表的结果显示了在这三种有害场景中,使用与查询相关的图像攻击模型的成功率高于使用
......长按二维码访问原文

【论文阅读】Jailbroken: How Does LLM Safety Training Fail? 2023-12-12 10:44

越狱:大语言模型安全训练何以失败
本文的目标是分析LLM能够被越狱的原因
论文地址:https://arxiv.org/abs/2307.02483
1.Jailbreak 介绍
随着大模型的应用越来越广泛,有一些人就想利用大模型去获得一些有害信息。所以现在的大语言模型在预训练之后都会经过安全训练阶段,这个阶段会设置一些安全措施,比如过滤和对齐等,让模型的输出符合人类价值观,训练它拒绝提供有害信息的请求,如图1这种有害问题,它就会拒绝回答.
图1
越狱攻击就是通过设计Prompt ,绕过大模型开发者为其设置的安全和审核机制,利用大模型对输入提示的敏感性和容易受到引导的特性,诱导大模型生成不合规的、本应被屏蔽的输出。如图2这个越狱的例子:攻击者通过对“如何生成毒品”这个有害问题设计一个对
......长按二维码访问原文

Vary:扩充Vision Vocabulary,提升LVLM的dense和细粒度视觉感知能力 2023-12-12 11:29
很高兴向大家介绍我们最近在探索增强多模态大模型细粒度视觉感知方面的新工作:Vary。
Vary充分探索了视觉词表对感知能力的影响,提供了一套有效的视觉词表扩充方法。通过在公开数据集以及我们渲染的文档图表数据上训练,在保持vanilla多模态能力的同时,还激发出了端到端的中英文图片、公式截图和图表理解能力,是一套视觉感知上限极高的通用多模态框架。
Vary是我们在这个方向上的初步探索,目前Vary的基础版 demo 已经上线,代码和模型均已开源,欢迎试玩和反馈,我们将继续增强Vary作为基座的各项能力,感谢大家的持续关注!
如果我们的工作对你有所启发,也希望能在Github为我们点上一个 Star!
Project page:
Demo:
Demo的网页版和手机版(夜间主题)
Demo的网页版和手机
......长按二维码访问原文

高效视觉Transformer的综述:算法,技术和性能基准 2023-12-12 06:46

23年9月综述论文“A survey on efficient vision transformers: algorithms, techniques, and performance benchmarking“,来自悉尼大学。
视觉Transformer(ViT)架构正变得越来越流行,并被广泛用于处理计算机视觉应用。它们的主要特征是通过自注意机制提取全局信息的能力,优于早期的卷积神经网络。然而,ViT的部署和性能随着其规模、可训练参数量和操作而稳步增长。此外,自注意的计算和内存成本,随图像分辨率的二次方增加。一般来说,由于许多硬件和环境限制,如处理和计算能力,在现实世界的应用中使用这些架构是具有挑战性的。因此,本综述调查了确保次优估计性能的最高效方法。更详细地说,分析四个有效类:紧凑架构、修剪、知识蒸馏和量
......长按二维码访问原文

Far3D:直接干到150m,视觉3D目标检测新思路(AAAI2024) 2023-12-12 21:00

近来在 Arxiv 读到一篇纯视觉环视感知的新工作,它延续了 PETR 系列方法,主要关注如何解决纯视觉感知的远距离目标检测问题,将感知范围扩大到150m。文章方法和结果有相当的借鉴意义,所以试着解读一下。
原标题:Far3D: Expanding the Horizon for Surround-view 3D Object Detection
论文链接:https://arxiv.org/abs/2308.09616
作者单位:北京理工大学 & 旷视科技
任务背景
三维物体检测在理解自动驾驶的三维场景方面发挥着重要作用,其目的是对自车周围的物体进行精确定位和分类。纯视觉环视感知方法具有成本低、适用性广等优点,已取得显著进展。然而,它们大多侧重于近距离感知(例如,nuScenes的感知距离约为 50
......长按二维码访问原文

2.9倍加速!高效GPU训练推理库 | 助力点云模型部署! 2023-12-13 14:38

自动驾驶、3D分割/检测/重建、VR/AR、导航等等很多应用都需要用到点云深度学习,由于点云是高度稀疏且不规则的,所以很多模型都会用到稀疏卷积(只在点云处进行计算)。但问题是TensorRT、TVM这些推理库都不支持稀疏卷积,这就导致点云学习方案的部署很困难。所以现有很多方案都是把3D点云投影到2D,做2D部署,很大程度上损失了精度。
今天笔者将为大家分享MIT、清华大学、UCSD、UC伯克利、上海交通大学、NVIDIA联合提出的最新工作TorchSparse++,是TorchSparse的升级版,可以实现高效的稀疏卷积训练和推理,相较MinkowskiEngine、SpConv 1.2、TorchSparse、SpConv v2分别实现了2.9、3.3、2.2、1.7倍的加速!下面一起来阅读一下:
以上内
......长按二维码访问原文

大湾区大学(筹)余梓彤课题组与中国科学技术大学张卫明教授联合招收人工智能方向博士后 2023-12-12 21:34
课题组介绍
余梓彤,大湾区大学(筹)信息科学技术学院助理教授。博士毕业于芬兰奥卢大学,师从Guoying Zhao教授(欧洲科学院院士,IEEE Fellow),博士期间曾在牛津大学Philip Torr教授(英国皇家学会会士) 组开展访问研究。曾在南洋理工大学Alex Kot教授(新加坡工程院院士,IEEE Fellow)ROSE实验室开展博士后研究。研究方向为可信媒体计算和以人为中心的计算机视觉。以第一作者在TPAMI/IJCV/CVPR/ICCV/ECCV等顶级会议和期刊上发表多篇高质量论文,谷歌总引用2950次,h-index为26,带领团队获国际学术竞赛冠军和亚军各1次。主持国家自然科学基金青年项目一项,作为核心成员参与国家自然科学基金面上项目一项及国际科研项目三项。担任国际期刊Frontiers
......长按二维码访问原文

CV计算机视觉每日开源代码Paper with code速览-2023.12.12 2023-12-12 23:20
精华置顶
墙裂推荐!小白如何1个月系统学习CV核心知识:链接
点击@CV计算机视觉,关注更多CV干货
论文已打包,点击进入—>下载界面
点击加入—>CV计算机视觉交流群
1.【基础网络架构:Transformer】MIMIR: Masked Image Modeling for Mutual Information-based Adversarial Robustness
2.【缺陷分割】Continual learning for surface defect segmentation by subnetwork creation and selection
3.【视频实例分割】VISAGE: Video Instance Segmentation with Appearance-Guided
......长按二维码访问原文

视觉Transformer的高效性对比分析 2023-12-12 04:47

23年8月论文“Which Transformer to Favor: A Comparative Analysis of Efficiency in Vision Transformers“,来自德国几个研究机构。
视觉Transformer作为图像分类的首选模型,越来越受欢迎,这导致了出现了比原始ViT更高效的架构修改版。然而,实验条件的广泛多样性阻碍了仅根据其报告结果对所有实验条件进行公平的比较。为了解决这一可比性差距,对30多个模型进行了全面分析,评估视觉Transformer和相关架构的效率,同时考虑各种性能指标。基准为效率导向的Transformer提供了一个可比的基线,揭示了大量令人惊讶的见解。例如,尽管存在几种声称更有效的替代方法,但在多个效率指标中,ViT仍然是Pareto最优的。结果还表明
......长按二维码访问原文

爆火!最强Text-to-3D开源方案LucidDreamer:毛发都给你合成出来! 2023-12-13 14:43

最近单图像合成3D、文本合成3D等等工作可谓大火,不停的看见"10秒/45秒/1分钟内合成高保真3D模型"的标题,大多数都是基于扩散模型和NeRF二次开发的,官方主页展示的交互式demo也确实效果拔群。
但是大多数方案合成的3D模型还是太过于平滑了,对于毛发、皮肤纹理、金属质感这种高频细节处理的不太好,很难说达到了照片级渲染。今天笔者将为大家分享香港科技大学、之江实验室、浙江大学最新开源的工作LucidDreamer,合成的模型非常精细!下面一起来阅读一下这项工作:
以上内容来自3D视觉学习圈子每日更新内容
工业3D视觉(结构光、缺陷检测、三维点云)、SLAM(视觉/激光SLAM)、自动驾驶、三维重建、事件相机、无人机等近千余篇最新顶会论文
......长按二维码访问原文

ICCV2023最佳论文——ControlNet 2023-12-13 10:58
原始的DDPM虽然在生成图片的细节上非常惊艳,但是却无法可控的生成图片,后面自然有一系列工作去改进这个部分,ControlNet就是其中一个工作,具体而言,ControlNet能够在给定的简单图像 A(比如物体的黑白轮廓图,语义分割的结果图)的基础上,生成更加具体的细节图像 B,其实就是相当于在 A 的 condition 下求解的条件概率分布。
论文题目:Adding Conditional Control to Text-to-Image Diffusion Models
论文作者来自于斯坦福大学,发表于ICCV 2023,代码和论文地址如下:
论文作者
生成图像的效果请移步文章结尾 实验 部分
Introduction
正如前文所述,DDPM开创了新的生成式学习的范式,但是DDPM本身并不可控
......长按二维码访问原文

清华大学提出RepViT-SAM:实时分割一切 2023-12-13 19:52

在移动端进行实时分割一切!RepViT-SAM:用RepViT主干替换了SAM中的图像编码器,速度极具加快!相较于MobileSAM得到近10倍的推理速度,代码刚刚开源!
现在点击关注 @CVer官方知乎账号,可以第一时间看到最优质、最前沿的CV、AI工作~
RepViT-SAM: Towards Real-Time Segmenting Anything
单位:清华大学(丁贵广团队), 谢菲尔德大学
代码:https://github.com/THU-MIG/RepViT
论文:https://arxiv.org/abs/2312.05760
最近,分割一切模型 (SAM) 在各种计算机视觉任务中表现出了令人印象深刻的零样本迁移性能。 然而,其繁重的计算成本对于实际应用来说仍然令人望而生畏。Mob
......长按二维码访问原文

英伟达最新发布!超越其它所有SOTA的3D目标检测 2023-12-13 14:14
现有的3D物体检测方法通常需要使用完全注释的数据进行训练,而使用预训练的语义特征可以带来一些优势。然而,目前还没有利用扩散特征进行3D感知任务的研究。因此,我们提出了一种新的框架,通过视图合成任务来增强预训练的2D扩散模型的3D感知能力。该方法利用已知相对姿态的图像对进行训练,并通过扩散过程生成目标输出。此外,文章还介绍了如何将这些增强的特征用于3D物体检测,并通过引入辅助网络来保持特征质量。最后,文章通过实验证明了该方法在点对应和3D检测性能上的优越性。
以上内容来自3D视觉学习圈子每日更新内容
工业3D视觉(结构光、缺陷检测、三维点云)、SLAM(视觉/激光SLAM)、自动驾驶、三维重建、事件相机、无人机等近千余篇最新顶会论文
......长按二维码访问原文

北大&清华最新开源 | 三项SOTA!MasQCLIP:开放词汇通用图像分割新网络 2023-12-13 14:32
开放词汇任务最近很火,也很有应用价值,毕竟实际环境中可能出现各种各样奇奇怪怪的物体。
今天笔者将为大家分享北京大学、清华大学、加州大学圣地亚哥分校最新开源的工作MasQCLIP,也是ICCV 2023的中稿论文,进一步刷高了开放词汇分割的指标。
以上内容来自3D视觉学习圈子每日更新内容
工业3D视觉(结构光、缺陷检测、三维点云)、SLAM(视觉/激光SLAM)、自动驾驶、三维重建、事件相机、无人机等近千余篇最新顶会论文
......长按二维码访问原文

加速40倍!EdgeSAM:在移动设备上高效部署SAM 2023-12-12 21:30
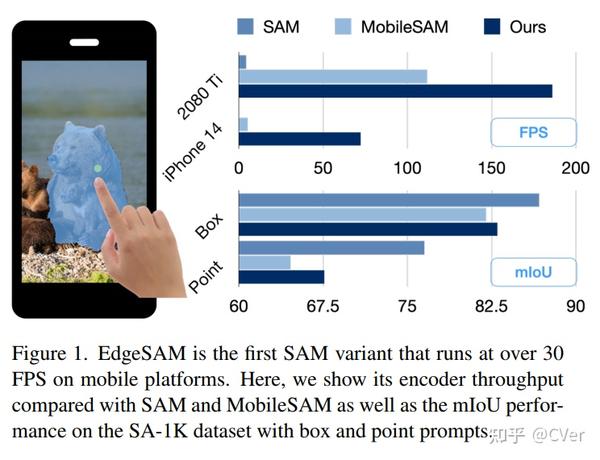
EdgeSAM:第一个在边缘设备上实时运行的SAM变体!与原始 SAM 相比,EdgeSAM 的速度提高了 40 倍,并且其性能也优于 MobileSAM,部署在边缘设备上时速度提高了 14 倍。它也是第一个可以在 iPhone 14 上以超过 30 FPS 运行的 SAM 变体,代码刚刚开源!
现在点击关注 @CVer官方知乎账号,可以第一时间看到最优质、最前沿的CV、AI工作~
EdgeSAM: Prompt-In-the-Loop Distillation for On-Device Deployment of SAM
单位:南洋理工大学, 上海AI Lab
主页:https://mmlab-ntu.github.io/project/edgesam/
代码:https://github.com
......长按二维码访问原文

最新多目标跟踪综述(100多篇论文) 2023-12-13 08:46

论文链接:https://arxiv.org/pdf/2209.04796.pdf
摘要
随着自动驾驶技术的发展,多目标跟踪已成为计算机视觉领域研究的热点问题之一。MOT 是一项关键的视觉任务,可以解决不同的问题,例如拥挤场景中的遮挡、相似外观、小目标检测困难、ID切换等。为了应对这些挑战,研究人员尝试利用transformer的注意力机制、利用图卷积神经网络获得轨迹的相关性、不同帧中目标与siamese网络的外观相似性,还尝试了基于简单 IOU 匹配的 CNN 网络、运动预测的 LSTM。为了把这些分散的技术综合起来,作者研究了过去三年中的一百多篇论文,试图提取出近年来研究者们更加关注的解决 MOT 问题的技术。作者罗列了大量的应用以及可能的方向,还有MOT如何与现实生活联系起来。作者的综述试图展示研究人
......长按二维码访问原文

How to Use Grounded EdgeSAM: 2023-12-13T09:33:40.000Z

EdgeSAM is a segmentation model that you can use to identify the specific location of objects in images, based on the Segment Anything (SAM) model architecture released by Meta AI in early 2023. EdgeSAM reports a "40-fold speed increase compared to the original SAM", making the model more viable to run at scale.
Autodistill combines EdgeSAM with Grounding D
......长按二维码访问原文

Text Summarization using T5: Fine-Tuning and Building Gradio App: 2023-12-12T14:00:00+00:00

The need for efficient text summarization has never been more pressing. Whether you’re a student grappling with lengthy research papers or a professional navigating news articles, the ability to extract key insights quickly is invaluable. T5, a pre-trained language model famous for several NLP tasks, excels at text summarization. Text summarization using T5
......长按二维码访问原文







