文章目录[隐藏]
- 视觉招聘小黑板
- 行业资讯
- 电气工程及其自动化不去电厂不去电网,还有前途吗? 2023-12-20 13:01
- From Novice to Pro: Your 2024 Guide to becoming a Computer Vision Engineer: 2023-12-20T14:05:58+00:00
- 实力强劲的显微镜成像组合:Allied Vision相机+µManager显微应用程序--机器视觉网 2023-12-21 18:11:49
- 西克中国安全胜任力中心(Safety Competence Hub)顺利成立--机器视觉网 2023-12-21 17:47:19
- 研华首次入选道琼斯可持续发展指数(DJSI)ESG实力获国际认可--机器视觉网 2023-12-21 17:40:33
- LOTS饮料瓶盖检测案例简介--机器视觉网 2023-12-21 17:14:35
- 华睿科技读码器在光伏行业的应用--机器视觉网 2023-12-21 17:13:10
- 基于T630的工业相机解决方案--机器视觉网 2023-12-21 17:00:49
- 思特威16K超高分辨率工业线阵图像传感器获“2024中国IC风云榜年度优秀创新产品奖”―新闻频道- 视觉系统设计 2023/12/20 21:56:21
- 埃科亿级像素大幅面相机―产品聚焦频道- 视觉系统设计 2023/12/20 22:03:35
- 实力强劲的显微镜成像组合:Allied Vision相机+μManager显微应用程序―技术与应用频道- 视觉系统设计 2023/12/20 21:52:48
- centos:
- 控制工程网-全球工控自动化和智能制造门户网站 2023/11/14 14:00:00
- 控制工程网-全球工控自动化和智能制造门户网站 2023/11/14 14:00:00
- 全球电动汽车产业加速前进,中国车企如何布局英国市场? 2023/11/14 14:00:00
- Self-Supervised Learning 超详细解读 (十三):DINO:视觉 Transformer 的自监督学习 2023-12-19 11:21
- Source-Free Domain Adaptation with Frozen Multimodal Foundation Model论文笔记 2023-12-20 12:03
- 12篇CV优质论文分享!(含2023CVPR获奖论文) 2023-12-20 18:04
- 大盘点!22项开源NeRF SLAM顶会方案整理!(上) 2023-12-21 16:56
- 2023图像匹配挑战冠军方案 | 无需提取特征点也能进行弱纹理三维重建! 2023-12-21 15:28
- 大盘点!22项开源NeRF SLAM顶会方案整理!(中) 2023-12-21 17:01
- 利用大模型做文本信息辅导图像盲超分任务重建的PromptSR方法 2023-12-20 12:41
- 发论文新坑来了!UrbanSyn:大规模自动驾驶合成数据集 2023-12-20 22:33
- CVPR 2023(剑桥大学最新),自适应迭代匹配和姿态估计 2023-12-20 16:19
- ICCV 2023 | R3D3 从多视图像实现动态场景的密集三维重建 2023-12-20 18:20
- 三种最常用的特征检测与匹配算法总结实践! 2023-12-20 16:14
- ICCV2023 从路径集成的角度重新审视ViT | Revisiting Vision Transformer from the View of Path Ensemble 2023-12-20 20:52
- Understanding Mosaic Data Augmentation: 2023-12-20T18:49:24+00:00
- How to Deploy CogVLM on AWS: 2023-12-20T15:54:23.000Z
- CogVLM Use Cases in Industry: 2023-12-20T13:04:49.000Z
视觉招聘小黑板
欲了解详情,请在公众号后台回复:231221
行业资讯
电气工程及其自动化不去电厂不去电网,还有前途吗? 2023-12-20 13:01
坐标北京,14年刚毕业时,班里一共40人,一半去了电厂和电网,一半去干别的(设计院、铁路、互联网、新能源、工厂等);到目前去电网一半人里的30%也出来了,发现别的行业更适合自己;而我目前在做金融相关工作,部门6个人,3个自动化,1个金融,2个电气专业;
自信点,咱们这个专业很牛的,不只是学电的,还学电子的、计算机的、控制的,什么都能搞,什么都能干,现在最需要的就是复合型的。
......长按二维码访问原文

From Novice to Pro: Your 2024 Guide to becoming a Computer Vision Engineer: 2023-12-20T14:05:58+00:00

Introduction
In this digital day and age, where technological advancements are at an unprecedented pace, one field that stands out is Computer Vision. This read is for aspiring individuals who wish to navigate the computer vision landscape. From mastering the fundamentals of image processing to exploring the many deep learning concepts, we delve into the es
......长按二维码访问原文

实力强劲的显微镜成像组合:Allied Vision相机+µManager显微应用程序--机器视觉网 2023-12-21 18:11:49
近日,Allied Vision推出一款和µManager团队联合打造的适用于显微镜成像应用的强大软硬件组合。借助现有µManager适配器,可轻松配置Allied Vision相机并为各类显微镜任务拍摄出高画质图像,如实时预览和实时控制、延时成像、多通道成像或Z-Stack成像。
目前Allied Vision相机适配器已集成到µManager软件中,为使用Allied Vision Vimba X软件开发套件(SDK)的客户提供即用解决方案。此外,Vimba X SDK支持µManager,让显微镜应用的系统设置变得非常简单。
......长按二维码访问原文

西克中国安全胜任力中心(Safety Competence Hub)顺利成立--机器视觉网 2023-12-21 17:47:19
2023-12-21 17:47:19 来源: 中国机器视觉网
随着西克集团在工业安全领域业务的不断发展,合理规划并建设西克集团在工业安全领域的技术胜任力与领先性,为全球客户提供更加专业、便捷和优质的服务的需求日益增加。西克集团针对这一需求,制定了各SSC以本地团队为基础,成立紧贴市场端的能力中心的战略。
西克中国安全团队在公司管理层的支持下,在半年时间内推动团队能力建设、架构优化、资源整合等举措,终于顺利通过德国总部评估,获得SSC08安全能力中心授权!
为什么要建立安全胜任力中心 满足市场需求;从仅产品转换为解决方案供应商;为实现动态安全奠定基础。
SICK愿景 : “在战略和运营层面上为市场提供的安全服务创造附加值和创新。”
安全胜任力中心的价值 客户收益 提供符合客户需求的安全服务和解决方案;
......长按二维码访问原文

研华首次入选道琼斯可持续发展指数(DJSI)ESG实力获国际认可--机器视觉网 2023-12-21 17:40:33
2023-12-21 17:40:33 来源: 中国机器视觉网
研华科技首次入榜“道琼斯可持续发展指数之世界指数(DJSI World)”,位列产业可持续发展得分最高前 10% 企业,5大维度获得满分。同时,在标普全球CSA评比中也表现出色,ESG实力获得国际认可。
全球工业物联网厂商研华科技今年首次入榜“道琼斯可持续发展指数之世界指数(DJSI World)”,位列产业可持续发展得分最高前 10% 企业。此外,在标准普尔全球企业可持续评比(S&P Global Corporate Sustainability Assessment)表现也相当亮眼,整体成绩不仅位于计算机、周边与办公电子设备(THQ Computers & Peripherals and Office Electronics)产业第四名
......长按二维码访问原文

LOTS饮料瓶盖检测案例简介--机器视觉网 2023-12-21 17:14:35
背景
随着生活的水平提高,食品品质及安全已成为社会关注的焦点,人们对食品安全的要求已经越来越高。生产日期码是判断食品有效期的重要依据,因此,保证生产日期等相关信息正确清晰的标注,是食品生产过程中的一个重要环节。
食品生产具有速度高、产量大的特点,且对外观质量要求高。这种高度重复、数量巨大的工作如果依靠人工检测,会带来巨大的人工管理成本。人工检查的速度慢、效率低,且存在长时间工作后疲劳误判等问题。
利用机器视觉技术,进行生产信息码采集检测是必然的发展趋势,其准确率高、工作效率高,可大幅降低生产成本;机器视觉技术检测在生产制造环节具有非常广阔的应用前景。
乐视科技在机器视觉行业深耕多年,具有丰富的瓶盖(如生产日期字符检测、logo识别、划痕等)检测经验。下面我们分享一些食品行业饮料瓶盖字符识别、表面缺陷检测
......长按二维码访问原文

华睿科技读码器在光伏行业的应用--机器视觉网 2023-12-21 17:13:10
2023-12-21 17:13:10 来源: 中国机器视觉网
背景
伴随着行业蓬勃发展和产能的快速提升,对应的生产和追溯也有了更为精细化、系统化的高要求,包括生产效率的提高、生产质量的提高、产品和关键器件的全流程全生命周期的追溯等。这几个方面都跟高效的读码和检测密切相关,下文会重点介绍读码相关的应用。
标签码
来料/工装/工序追溯等很多生产环节会有标签码,采用手持扫码枪扫码、录入信息;同时也有越来越多的工厂往流水线发展,采用固定式读码器高效智能读码,不需要人为参与。硅棒/硅锭/硅片/电池片等相关的大多是采用激光雕刻喷码,二维码QR和Data Matrix,不同的厂家选用不同的码型,此类应用的难点是不同材质和工艺刻码效果有差异、污损码、对比度低、反光、模糊、焊线干扰等。组件环节很多是条码带覆膜或者压板,
......长按二维码访问原文

基于T630的工业相机解决方案--机器视觉网 2023-12-21 17:00:49
2023-12-21 17:00:49 来源: 中国机器视觉网
方寸微官方合作伙伴奥唯思携手全国产芯片方案,耗时6个月,打造了一款高性能、低照度、全国产USB3.0工业相机方案。成功接入了Windows、Linux,以及RK3588等国产化平台,助力整体国产化方案。
T630芯片介绍
T630芯片是方寸微电子自主研发的纯国产USB3.0超高速控制器,具有功能丰富、性能强劲、扩展性强等特点,可广泛适用于视频采集卡、工业采集卡、打印机、扫描仪、数字摄像机、测量采集设备等众多电子产品。该芯片集成国产32位高性能RISC CPU,支持USB3.0、MUXIO、I2C、SPI、UART等多种接口,可快速在嵌入式主板上与FPGA/CPU进行对接通讯,作为USB3.0外扩芯片与PC或者服务器实现数据传输。T630高速接
......长按二维码访问原文

思特威16K超高分辨率工业线阵图像传感器获“2024中国IC风云榜年度优秀创新产品奖”―新闻频道- 视觉系统设计 2023/12/20 21:56:21
12月16日,2024中国半导体投资联盟年会暨中国IC风云榜颁奖典礼在北京顺利举行。大会围绕“重组创变,整合致胜”主题,聚焦四大亮点,构建“点、线、面”相结合,多层次、立体化的大会,以全球视野为背景,探析宏观局势,洞察半导体产业趋势和未来新机遇。
作为中国集成电路领域饕餮盛宴,中国半导体投资联盟年会暨中国IC风云榜颁奖典礼至今已成功举办四届,在业内享誉盛名。在本次颁奖典礼上,思特威(上海)电子科技股份有限公司(简称:思特威)16K超高分辨率工业线阵图像传感器芯片SC1630LA凭借先进的产品研发理念与卓越的产品性能,脱颖而出荣获2024中国IC风云榜年度优秀创新产品奖。
以关键核心技术自主创新为源动力,助推国产替代化
此次荣获“年度优秀创新产品奖”的是完整呈现思特威创新沉淀的重磅产品——高端工业线阵图像传
......长按二维码访问原文

埃科亿级像素大幅面相机―产品聚焦频道- 视觉系统设计 2023/12/20 22:03:35
随着新型显示行业的迅猛发展,显示屏分辨率已从过去的1K、2K、4K,逐渐升级至8K,并不断向16K甚至更高分辨率精进;LCD、OLED、Mini LED、Micro LED,显示屏类型也日趋多样化。显示屏生产工艺的不断提升,对屏幕检测精度、效率提出了更高要求,常规1亿像素以下的相机逐渐无法满足检测需求。为了适应屏幕厂商日益增长的检测要求,亿级像素以上的工业相机已成为屏幕检测不可或缺的关键视觉部件。
埃科光电率先填补亿级像素以上分辨率工业相机市场空白,不断丰富旗下亿级像素大幅面相机产品矩阵,目前共有8款产品。相机搭载高性能CMOS传感器,支持黑白/彩色图像模式,分辨率涵盖1.01-13.59亿,为显示行业高效检测提供了更多可能。
高分辨率成像,还原超清“视”界
埃科亿级像素大幅面相机包括6种分辨率,能够精准
......长按二维码访问原文

实力强劲的显微镜成像组合:Allied Vision相机+μManager显微应用程序―技术与应用频道- 视觉系统设计 2023/12/20 21:52:48
近日,Allied Vision推出一款和µManager团队联合打造的适用于显微镜成像应用的强大软硬件组合。借助现有µManager适配器,可轻松配置Allied Vision相机并为各类显微镜任务拍摄出高画质图像,如实时预览和实时控制、延时成像、多通道成像或Z-Stack成像。
目前Allied Vision相机适配器已集成到µManager软件中,为使用Allied Vision Vimba X软件开发套件(SDK)的客户提供即用解决方案。此外,Vimba X SDK支持µManager,让显微镜应用的系统设置变得非常简单。
01.µManager的应用
µManager是一个GitHub托管开源项目,由软件开发人员和用户共同开发和编写。这一软件工具可用于图像采集及控制各类显微镜硬件,包括光源、滤镜
......长按二维码访问原文

centos:
......长按二维码访问原文

控制工程网-全球工控自动化和智能制造门户网站 2023/11/14 14:00:00
资讯 > 仪器仪表
作者:www.cechina.cn2023.12.21阅读 219
制造强国
建设近十年发展现状
中国制造强国发展指数逼近德日第二阵列。十年来,中国与美国、德国、日本等制造强国的差距逐渐缩小,2021年中国制造强国发展指数逼近德日第二阵列,我国制造强国发展进程加速推进。
2012年至2021年,我国制造强国发展指数相对值与美国差距由68.04缩小至56.48,与德国差距由22.01缩小至8.79,与日本差距由31.98缩小至2.21。
中国制造业在世界占有重要地位,增加值超过美德日三国之和。2012年至2021年,我国制造业增加值由16.98万亿元增长到31.40万亿元,连续12年位居世界首位;制造业增加值占全球比重由22.30%提高到30.32%,在世界各主要经济体中位居首位;
......长按二维码访问原文

控制工程网-全球工控自动化和智能制造门户网站 2023/11/14 14:00:00
资讯 > 变频器
作者:《Power & Motion》杂志技术编辑Sara Jensen2023.12.19阅读 654
人工智能所具有的这些能力,为制造商和其他用户提高运营效率和生产力提供了可能。
*编者注:为清晰起见,问题和回答均为编辑过的版本。
《Power & Motion》(以下简称“《P&M》”): 您如何看待人工智能(AI)在制造业中的应用?
Murad Kurwa(以下简称“MK”):人工智能(AI)可以惠及一些制造流程。在决定如何在工厂车间部署AI技术时,重要的是从最终目标出发,然后利用技术来帮助实现这一目标,例如工厂生产线优化、预测性维护、异常检测、库存管理和瓶颈预防等等。
根据最终目标,可以通过收集和整理数据、选择要使用的 AI 模型类型、训练模型、确定模型的性能是否
......长按二维码访问原文

全球电动汽车产业加速前进,中国车企如何布局英国市场? 2023/11/14 14:00:00
资讯 > 市场分析
作者:www.cechina.cn2023.12.18阅读 855
英国商业贸易部与中国汽车工程学会(ChinaSAE)共同举办了“中英交通领域碳中和协同发展论坛”,为两国政策、企业在交通领域开展进一步合作凝聚共识
英国商业贸易部本次带领多家英国车企组成代表团亮相,以路演的形式直观展示了英国在汽车供应链行业内的实力。这也是英国代表团在新冠疫情后首次线下回归WNEVC。本次访华,代表团还随英国政府工业转型首席顾问和政府合作伙伴一起访问了中国华南部分中方整车厂和供应链公司,并参加了首届“国际汽车领域投资发展论坛”,就新能源汽车产业发展问题开展对话与交流。
着眼绿色交通转型
英国持续加码电气化革新
作为全球首个立法承诺 2050 年实现净零排放的主要经济体,英国将低碳出行列为国
......长按二维码访问原文

Self-Supervised Learning 超详细解读 (十三):DINO:视觉 Transformer 的自监督学习 2023-12-19 11:21

本系列已授权极市平台,未经允许不得二次转载,如有需要请私信作者,文章持续更新。
专栏目录
本文目录
1 DINO:视觉 Transformer 的自监督学习
(来自 Facebook AI Research)
1 DINO 论文解读
1.1 背景和动机
1.2 DINO 算法介绍
1.3 DINO 网络架构
1.4 DINO 训练策略
1.5 ImageNet 实验结果
1.6 消融实验结果
太长不看版
DINO 是视觉 Transformer 做自监督学习的非常经典的工作。DINO 所要探究的问题是:自监督学习算法是否能够为视觉 Transformer 带来新的特性。本文给出了以下的观察:首先,自监督训练得到的 ViT 包含关于图像语义分割的显式信息,这在以往的有监督训练和卷积网络里
......长按二维码访问原文

Source-Free Domain Adaptation with Frozen Multimodal Foundation Model论文笔记 2023-12-20 12:03
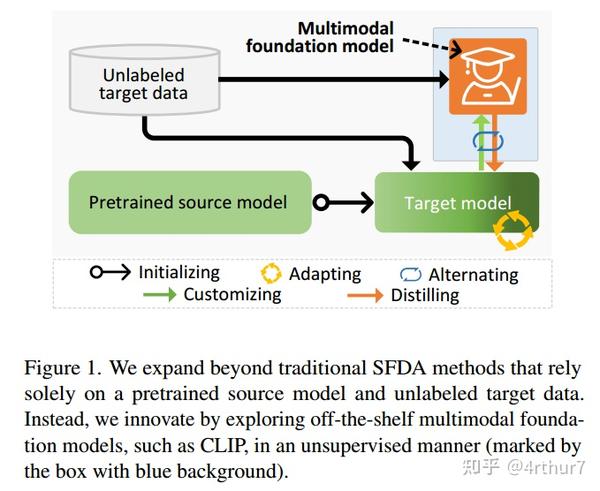
原文链接:
在这项工作中,我们首次探索了具有丰富而异构知识的现成视觉语言(ViL)多模态模型(例如 CLIP)的潜力。我们发现以零样本方式直接将ViL模型应用于目标域并不令人满意,因为它不是专门用于此特定任务的,而是在很大程度上是通用的。为了使其任务具体化,我们提出了一种新颖的蒸馏多模式基础模型(DIFO)方法。具体来说,DIFO在适应过程中在两个步骤之间交替:(i)通过以快速学习的方式最大化与目标模型的互信息来定制ViL模型,(ii)将这个定制的ViL模型的知识提炼到目标模型。为了更细粒度和更可靠的蒸馏,我们进一步引入了两个有效的正则化项,即最有可能的类别鼓励和预测一致性。
一、简介
为了解决已发现的局限性,我们率先探索现成的多模态基础模型,例如视觉语言(ViL)模型CLIP,超越了源模型和目标数据知识
......长按二维码访问原文

12篇CV优质论文分享!(含2023CVPR获奖论文) 2023-12-20 18:04
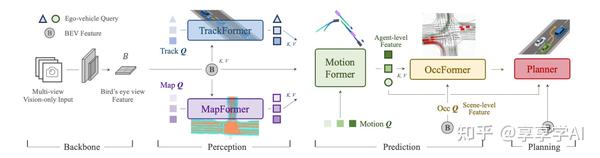
近年来计算机视觉(CV)一直是人工智能领域的一个热门方向,尤其在图像识别、人脸识别、自动驾驶、智能安防等领域的广泛应用,使得CV技术成为研究的热点。目前CV领域的论文也非常多,为了帮助大家更好地了解CV领域的研究进展和成果,本文将汇总并介绍一些CV优质论文,大家可以看一看!
1、Planning-oriented Autonomous Driving
以路径规划为导向的自动驾驶
简述:论文首次提出感知决策一体化的自动驾驶通用大模型UniAD,研究人员首次将感知、预测和规划等3大类主任务、6小类子任务(目标检测、目标跟踪、场景建图、轨迹预测、栅格预测和路径规划)整合到统一的基于Transformer的端到端网络框架下,实现了全栈关键任务驾驶通用模型。它精心设计以利用每个模块的优势,并为代理
......长按二维码访问原文

大盘点!22项开源NeRF SLAM顶会方案整理!(上) 2023-12-21 16:56
0. 笔者个人体会
NeRF结合SLAM是这两年新兴的方向,衍生出了很多工作。目前来看SLAM结合NeRF有两个方向,一个是SLAM为NeRF训练提供位姿,然后建立稠密细腻的三维场景,一个是在NeRF里建立各种损失函数反过来优化pose和depth。那么NeRF结合SLAM都有哪些典型工作呢,本文将为大家做一个简单梳理。希望能够为想要入门NeRF SLAM的小伙伴提供一点研究思考。
受于篇幅限制,本文不会过多介绍文章细节。将所有相关文章划分为仅优化NeRF、仅优化位姿、位姿和NeRF联合优化、物体级NeRF SLAM、雷达NeRF SLAM这五类。同时为避免生硬的翻译原文,本文针对每篇文章的介绍将以四个问题来进行,分别是这篇文章希望解决什么问题?核心思想是什么?具体如何实现?有什么效果?当然笔者水平有限,如
......长按二维码访问原文

2023图像匹配挑战冠军方案 | 无需提取特征点也能进行弱纹理三维重建! 2023-12-21 15:28
0. 笔者个人体会
SfM是指给定一组无序图像,恢复出相机位姿以及场景点云。通用场景下的SfM效果已经很好,而且COLMAP这类框架也很好用。但是弱纹理和无纹理场景下的SfM却很麻烦,主要目前主流的SfM框架都是先提取图像中的特征点,然后进行特征匹配。但是在无纹理条件下,很难提取稳定且重复的特征点,这就导致SfM恢复出的位姿和三维点云非常杂乱。
很直接的一个想法就是,如果不提取特征点,直接进行匹配呢?
最近,浙江大学就基于这种思想提出了一种弱纹理场景下的SfM框架,主要流程是首先基于LoFTR这类Detector-Free图像匹配算法获得粗糙位姿和点云,然后使用Transformer多视图匹配算法优化特征点坐标,利用BA和TA进一步优化位姿和点云。这个算法获得了2023 IMC的冠军,整体性能很好。今天笔
......长按二维码访问原文

大盘点!22项开源NeRF SLAM顶会方案整理!(中) 2023-12-21 17:01
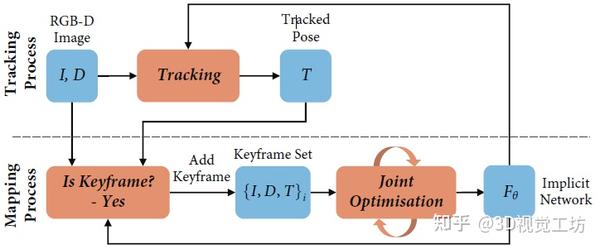
0. 笔者个人体会
上一篇文章我们介绍了仅优化NeRF和仅优化位姿的NeRF SLAM方案,本文将介绍位姿和NeRF联合优化的相关工作,也是NeRF SLAM最主要的方向。下一篇文章我们将介绍物体级NeRF SLAM和雷达NeRF SLAM的方案。
前情回顾:为避免生硬的翻译原文,本文针对每篇文章的介绍将以四个问题来进行,分别是这篇文章希望解决什么问题?核心思想是什么?具体如何实现?有什么效果?当然笔者水平有限,如果有理解不当的地方欢迎各位读者批评指正~
1. 目录
还是先放一个目录列举本文都介绍了哪些方案。
仅优化NeRF
0、NeRF
1、Point-NeRF
2、NeRF-SLAM
仅优化位姿
3、iNeRF
4、NeRF-Loc
5、NeRF-VINS(未开源)
位姿和NeRF
......长按二维码访问原文

利用大模型做文本信息辅导图像盲超分任务重建的PromptSR方法 2023-12-20 12:41
1、目前的一些比较新的图像盲超分的工作
目前一些图像盲超分工作开始将文本信息利用起来来做一个prompt的先验;
SeeSR是利用了图像中的一些物体的信息,将其抽象为文本来辅导图像盲超分任务,PromptSR是将退化信息抽象为文本信息来进行辅导图像盲超分任务;
本文就简单的总结下第二种方法,以退化信息为文本辅导的PromptSR;
两种方法都属于多模态的工作;
[1] SeeSR: Towards Semantics-Aware Real-World Image Super-Resolution
[2] Image Super-Resolution with Text Prompt Diffusion
2、Image Super-Resolution with Text Prompt Diffus
......长按二维码访问原文

发论文新坑来了!UrbanSyn:大规模自动驾驶合成数据集 2023-12-20 22:33
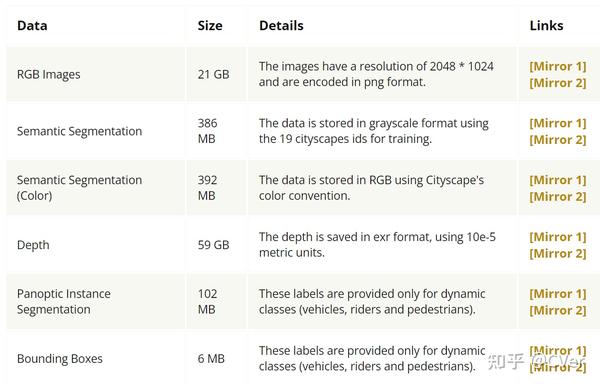
总计80+G!数据集刚刚开源!可助力各种下游自动驾驶感知任务涨点!单位:CVC(UAB), CITIC, NVIDIA等。同学们,发论文/刷榜新坑来了!把握机会啊!
快!现在点击关注 @CVer官方知乎账号,可以第一时间看到最优质、最前沿的CV、AI工作~
All for One, and One for All: UrbanSyn Dataset, the third Musketeer of Synthetic Driving Scenes
主页:http://www.urbansyn.org/#loaded
论文:https://arxiv.org/abs/2312.12176
UrbanSyn:一个大规模城市驾驶场景的逼真自动驾驶数据集。UrbanSyn 使用高质量几何和材料开发,提供像素级g
......长按二维码访问原文

CVPR 2023(剑桥大学最新),自适应迭代匹配和姿态估计 2023-12-20 16:19
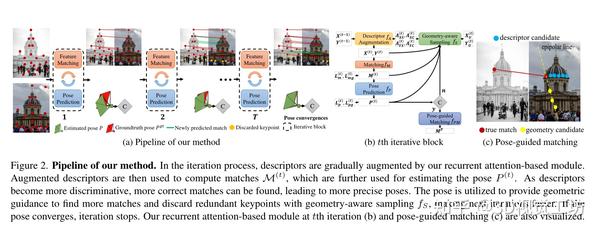
介绍
一般相机姿态估计问题通常分为两阶段来处理,即首先进行特征匹配,然后根据匹配对应关系估计姿态,所以大家往往关注在要么提高匹配质量,即研究更鲁棒高效的特征检测匹配算法,要么是研究如何过滤潜在的异常值。这样导致匹配和姿态估计割裂开来,这篇文章则不同,他们利用了这两个任务之间的几何关联:几个好的匹配就足以进行大致准确的姿态,反过来,通过提供的几何约束,大致准确的姿态又可以用来引导匹配。为此,他们提出了一个迭代匹配和姿态估计框架,实现了一个基于几何感知的递归注意力模块,该模块输出稀疏匹配和相机姿态。
此外,为了提升效率,避免对无信息特征点进行冗余操作,提出了一种采样策略,将特征点的匹配和注意力得分以及预测姿态的不确定性相结合,自适应去除关键点,与之前主要基于注意力得分的采样方法相比,有效克服了过采样问题。框架从
......长按二维码访问原文

ICCV 2023 | R3D3 从多视图像实现动态场景的密集三维重建 2023-12-20 18:20
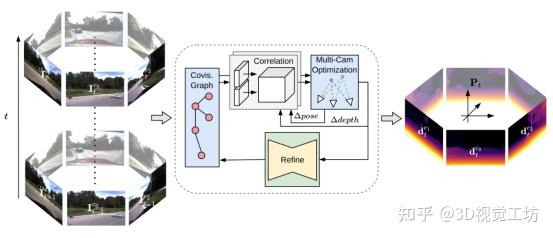
R3D3是一种用于密集三维重建和自我运动估计的多摄像头算法,该方法通过迭代地结合多摄像头的几何估计和单目深度细化来实现一致的密集三维重建。R3D3的核心思想是将单目线索与来自多摄像头的空间-时间信息的几何深度估计相结合,通过在共视图中迭代密集对应关系,计算准确的几何深度和位姿估计。为了在多摄像头设置中确定共视帧,作者提出了一种简单而有效的多摄像头算法,用于平衡性能和效率。深度细化网络以几何深度和对应的不确定性为输入,并生成细化深度,以改善例如移动物体和低纹理区域的重建,细化的深度估计作为下一次几何估计迭代的基础,从而在增量几何重建和单目深度估计之间闭合循环。R3D3在DDAD和NuScenes基准测试中实现了最优异的多摄像头深度估计性能,与单目SLAM方法相比有更高的精度和鲁棒性。
1. 引言
密集三维重建
......长按二维码访问原文

三种最常用的特征检测与匹配算法总结实践! 2023-12-20 16:14
我们都知道特征检测和匹配是计算机视觉领域中的重要任务,它们在许多应用中发挥着关键作用,比如SLAM、SFM、AR、VR等许多算法都需要稳定精确的特征检测和匹配。
特征检测算法的意义在于从图像或视频中提取出具有独特性质的特征点,这些特征点可以代表图像中的关键信息。这些特征点通常具有旋转、尺度和光照变化的不变性,使得它们在图像的不同位置和角度下都能够被准确地检测到。
特征匹配算法的意义在于将两个或多个图像中的特征点进行对应,以实现图像间的关联和匹配。通过将特征点进行匹配,可以进行目标跟踪、图像配准、三维重建等任务。
目前个人认为特征检测和匹配的研究点包括但不限于以下几个方面:
1.特征点检测算法的设计和改进,提高特征点的鲁棒性和准确性。
2.特征描述子的设计和优化,提高特征点的区分度和匹配性能。
3.多
......长按二维码访问原文

ICCV2023 从路径集成的角度重新审视ViT | Revisiting Vision Transformer from the View of Path Ensemble 2023-12-20 20:52
一、要解决的问题(Why)
本篇论文主要提供了一个新的看待ViT的视角
Vision Transformer(ViT)[15] 由多头自注意力(MHSA)和前馈网络(FFN)的交替层组成。许多后续工作 [37, 47, 42, 44, 23, 50, 29] 主要致力于优化这两个核心模块并创建各种ViT变体。然而,大多数方法并未打破基本的ViT结构,即包含残差子层的transformer层叠进行分析。
残差连接 [19] 在ViTs中被广泛采用,通过将数据直接从前一层流向后一层,绕过它们的子层。其定义如下:
x_i = g_i(x_{i-1}) + R_i(x_{i-1})
其中,层函数 g_i 和 R_i 通常分别为恒等函数和主要构建块。在ViTs中,我们观察到几乎所有的非线性结构都符合公式R_i的
......长按二维码访问原文

Understanding Mosaic Data Augmentation: 2023-12-20T18:49:24+00:00
Introduction
Data augmentation encompasses various techniques to expand and enhance datasets for machine learning and deep learning models. These methods span different categories, each altering data to introduce diversity and improve model robustness. Geometric transformations, such as rotation, translation, scaling, and flipping, modify image orientation
......长按二维码访问原文

How to Deploy CogVLM on AWS: 2023-12-20T15:54:23.000Z
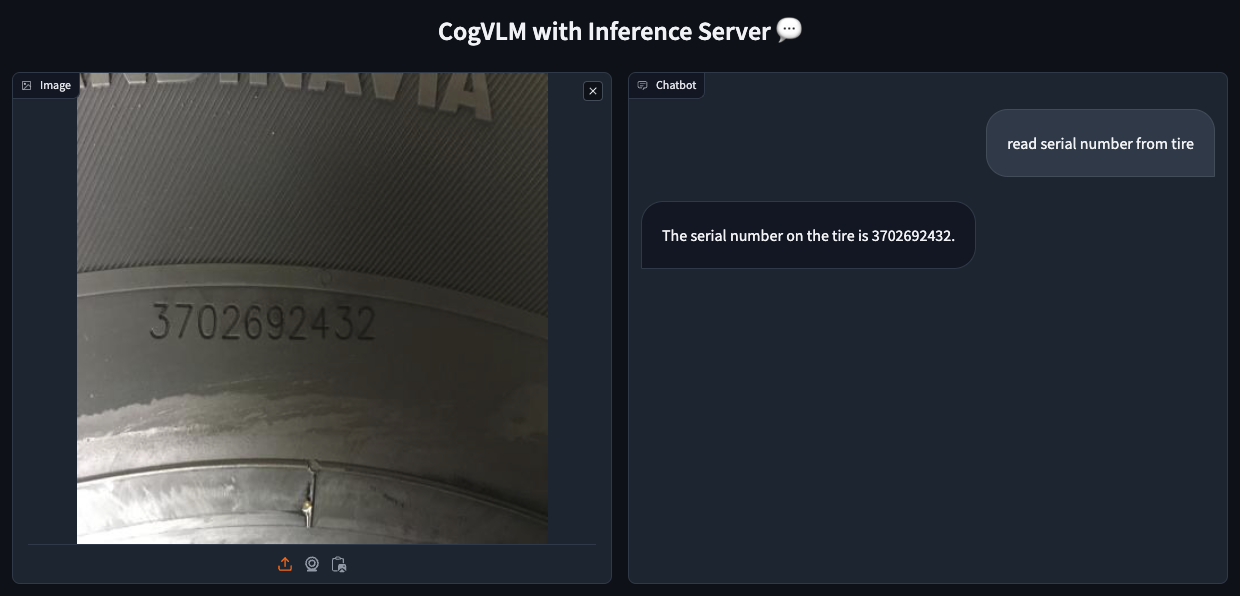
CogVLM , a powerful open-source Large Multimodal Model (LMM), offers robust capabilities for tasks like Visual Question Answering (VQA), Optical Character Recognition (OCR), and Zero-shot Object Detection .
In this guide, I'll walk you through deploying a CogVLM Inference Server with 4-bit quantization on Amazon Web Services (AWS). Let's get started.
Setup
......长按二维码访问原文

CogVLM Use Cases in Industry: 2023-12-20T13:04:49.000Z
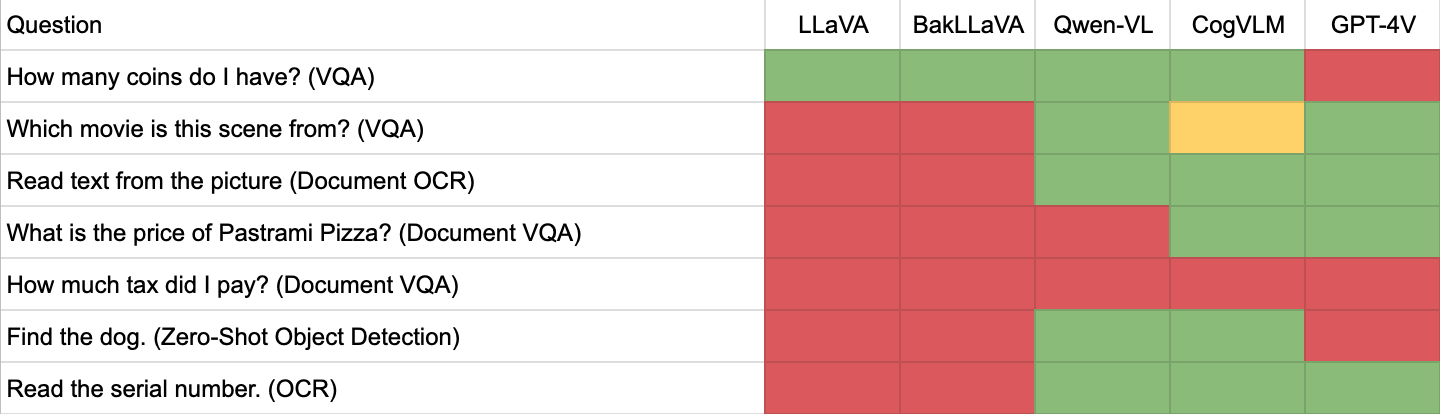
CogVLM is a Large Multimodal Model (LMM) to which you can ask questions about images and text. For example, consider a scenario where you are aiming to identify luggage on the tarmac in an airport, a potential safety hazard. You could take regular photos of a given section of tarmac and ask CogVLM “is there luggage on the tarmac?”
In this guide, we will dis
......长按二维码访问原文







