文章目录[隐藏]
- 视觉招聘小黑板
- 行业资讯
- 足式机器人的建模与控制有哪些国内外优秀著作可以供低年级直博生学习? 2023-03-08 04:18
- 自动化专业考研可以考虑哪些大学? 2022-08-25 12:33
- 蓝芯科技入选“省研发中心”,标志着其能力受到业界权威认可--机器视觉网 2023-12-26 13:41:07
- 超恩推出搭载英特尔®至强®D-2800处理器高效能ICS-1000嵌入式系统--机器视觉网 2023-12-26 13:25:50
- 梅卡曼德作为企业代表参加北京“独角兽十条”实施座谈会--机器视觉网 2023-12-26 12:04:12
- 海研科技升级版板材在线视觉检测系统再获好评--机器视觉网 2023-12-26 10:48:50
- 一文看懂CMOS图像传感器指标--机器视觉网 2023-12-26 14:33:08
- 潮流设计,谁来守护?堡盟OXM200电动汽车外观的“造型师”--机器视觉网 2023-12-26 14:17:51
- Teledyne DALSA自动化检测101:工业应用中的优势--机器视觉网 2023-12-26 14:09:50
- 工业镜头的主要参数对成像质量的影响--机器视觉网 2023-12-26 13:53:04
- 梅卡曼德作为企业代表参加北京“独角兽十条”实施座谈会―新闻频道- 视觉系统设计 2023/12/25 23:26:48
- FLIR Blackfly®S USB 3.1板级相机―产品聚焦频道- 视觉系统设计 2023/12/25 23:22:09
- LUCID Vision Labs™ SENSAiZ 智能视觉CMOS相机―产品聚焦频道- 视觉系统设计 2023/12/25 23:09:51
- 图漾科技3D工业视觉应用开发平台VISION++―产品聚焦频道- 视觉系统设计 2023/12/21 23:32:57
- 自动光学检测 (AOI) ,精确的自动化光学检测提高制造效率―技术与应用频道- 视觉系统设计 2023/12/26 15:51:33
- AI-MASTER应用于工件焊缝方向的视觉检测―技术与应用频道- 视觉系统设计 2023/12/26 9:07:31
- DLNR还没来,先看EAI-stereo! 2023-12-26 16:08
- 通用 Vision Backbone 超详细解读 (二十九):视觉 Transformer 需要寄存器 2023-12-26 15:28
- 动态环境下竟然能在嵌入式系统上实现实时语义RGB-D SLAM? 2023-12-26 11:00
- TokenFlow:一致的扩散特征用于一致的视频编辑 2023-12-26 11:59
- ICCV 2023 I NDC-Scene:单目三维语义场景补全的新突破 2023-12-26 17:08
- 图像处理神器!谷歌新作TIP:具有语义和复原指令的文本驱动图像处理 2023-12-26 11:34
- SDV-LOAM:半直接视觉和激光雷达融合SLAM 2023-12-25 14:45
- 3D 对象生成 | NeRF+GAN的超网络:HyperNeRFGAN 2023-12-25 15:28
- CVPR2023 I Gated Stereo:如何利用多视角和TOF强度线索进行深度估计? 2023-12-26 15:35
- 最新 I LEAP:一种不需要相机姿态的稀疏视图三维建模方法 2023-12-26 15:03
- 2020到2023年NeRF开源代码库与框架盘点,哪款更适合你? 2023-12-25 17:44
- 基于感知质量的滚动优化无人机导航 2023-12-26 11:15
- 最新NeRF文章 l Blended-NeRF:混合神经辐射场中的零样本物体生成和混合 2023-12-26 15:08
- CVPR 2023 I NeuMap:自动Transdecoder神经坐标映射用于相机定位 2023-12-26 15:25
- CVPR2023 | Co-SLAM: 联合坐标和稀疏参数编码的神经实时SLAM 2023-12-26 14:59
- CVPR 2023 OpenLane性能自动驾驶挑战赛冠军解决方案 2023-12-26 15:27
- ICCV2023:第一个基于DETR的高质量通用目标检测方法 2023-12-25 19:07
- 速速收藏~超全!2D单目标跟踪常用评价指标及完整代码 2023-12-25 17:49
- ICCV2023:最新激光雷达语义分割SOTA!MemorySeg! 2023-12-25 19:03
- Github70k star!GitHub中文排行榜,帮助你发现优秀中文项目 2023-12-26 16:26
- CVPR2023 I 一种实用的智能眼镜深度感知系统 2023-12-26 15:48
- ICCV 2023 I ELFNet:基于 Transformer 和深度证据学习的立体匹配 2023-12-26 16:57
- TRO新文:用于数据关联、建图和高级任务的对象级SLAM框架 2023-12-25 14:51
- CVPR2023 I 一种全新的单个宽基线立体图像对中学习渲染新视角的方法 2023-12-26 15:47
- 3D点云目标跟踪的评价指标及详细代码 2023-12-25 17:59
- 网课部署分享 | K8S 部署 JupyterHub 集群 2023-12-26 12:40
- ikd树:激光雷达SLAM中高效的点云数据结构 2023-12-25 14:39
- CVPR2023 I PartManip从点云观察中学习跨类别零件操作的通用策略 2023-12-26 15:39
- 所有指标全面领先!图像-点云配准最新SOTA!CoFiI2P详细介绍! 2023-12-25 18:56
- 一文搞定opencv中常见的关键点检测算法(附代码) 2023-12-26 11:51
- ICCV 2023 I 你还在为点云数据发愁吗?AutoSynth:自动生成 3D 训练数据 2023-12-26 17:11
- CV计算机视觉每日开源代码Paper with code速览-2023.12.25 2023-12-26 00:23
- AAAI 2024 | 西电提出RIRC:可见水印去除新工作 2023-12-26 17:30
- 多模态: 点云+文本 | 通过 CLIP 理解点云:PointCLIP 2023-12-26 15:00
- 比目前最先进的模型轻30%!高效多机器人SLAM蒸馏描述符! 2023-12-26 10:41
视觉招聘小黑板
欲了解详情,请在公众号后台回复:231226
行业资讯
足式机器人的建模与控制有哪些国内外优秀著作可以供低年级直博生学习? 2023-03-08 04:18
我自己在四足以及optimal control方面有一些经验。我可以从我个人的角度来推荐一些书籍、课程、论文、领域内知名学者和代码库:
......长按二维码访问原文

自动化专业考研可以考虑哪些大学? 2022-08-25 12:33
自动化在研究生阶段为控制科学与工程或者电子信息(控制工程),下面罗列一下控制第4次学科评估有名的院校,可以参考一下。
以上院校的专业课都涉及古典控制或者现代控制。还有个别几所学校考电路或者其他科目也可没有列写。
更多院校信息或者专业课知识可关注公众号【自动化控制考研JK】或加入qq群:893735788,关注B站:夹克学长。
......长按二维码访问原文

蓝芯科技入选“省研发中心”,标志着其能力受到业界权威认可--机器视觉网 2023-12-26 13:41:07
蓝芯科技入选“省研发中心”,标志着其能力受到业界权威认可
2023-12-26 13:41:07 来源: 中国机器视觉网
近日,蓝芯科技获得浙江省科学技术厅正式颁发的浙江省高新技术企业研究开发中心(以下简称“省研发中心”)证书。省研发中心是浙江省科技创新体系的重要组成部分,对进一步加快科技成果转化和高新技术产业发展起重要推动作用。
省研发中心的申报对企业有诸多硬性要求,首先,必须是国家高新技术企业;其次,已建有市级高新技术企业研发中心;再次,对企业的研发投入、研发团队、专利数量,以及科技成果转化等均有严格要求。
作为国内新一代移动机器人(3D视觉感知)全球引领者和智能工厂整体解决方案领先提供商,蓝芯科技坚持以创新技术驱动企业发展,打造移动机器人核心技术LX-MRDVS®(蓝芯-移动机器人深度视觉系统),
......长按二维码访问原文

超恩推出搭载英特尔®至强®D-2800处理器高效能ICS-1000嵌入式系统--机器视觉网 2023-12-26 13:25:50
2023-12-26 13:25:50 来源: 中国机器视觉网
超恩股份有限公司近日推出伺服器运算性能ICS-1000嵌入式系统,采用最新16核英特尔®至强® D-2800处理器,并可开始接受订单出货。超恩ICS-1000配置6个PCIe槽可支持1800W AI应用双显卡、8个DDR4、提供丰富I/O介面以及支持高速传输功能,可满足即时视觉与机器人控制应用需求,助力建构机自驾车、机器人控制、公共安全监控与各种边缘端AI等嵌入式应用的理想解决方案。
伺服器级性能
超恩ICS-1000嵌入式系统采用英特尔®D-2876NT处理器(Eddy Lake D HCC),支持最高16核心,512GB DDR4內存,具有高达100W的散热设计功率( TDP),展现优异系统运算效能;不仅如此,ICS-1000内建高速乙太
......长按二维码访问原文

梅卡曼德作为企业代表参加北京“独角兽十条”实施座谈会--机器视觉网 2023-12-26 12:04:12
2023-12-26 12:04:12 来源: 中国机器视觉网
为深入落实中央经济会议精神,贯彻北京市委十三届四次全会部署,着力增强高质量发展动能,支持和服务以独角兽企业为代表的民营企业在京发展,12月22日,北京市科委、中关村管委会组织召开《关于进一步培育和服务独角兽企业的若干措施》(京科发〔2023〕11号,以下简称“独角兽十条”)实施座谈会。会议由北京市人民政府副秘书长韩耕主持,北京市人民政府党组成员、副市长于英杰出席并作总结讲话。市科委、中关村管委会副主任张宇蕾,市发展改革委二级巡视员夏翊,市国资委副主任贺昂,市地方金融监管局副局长张颖,市人才工作局流动调配处处长举辉以及北京市独角兽企业代表参会。
张宇蕾报告了“独角兽十条”的落实情况,详细介绍了政策印发以来,市科委、中关村管委会等市级部门以及相关区
......长按二维码访问原文

海研科技升级版板材在线视觉检测系统再获好评--机器视觉网 2023-12-26 10:48:50
2023-12-26 10:48:50 来源: 中国机器视觉网
12月20日,海研科技全面升级版板材在线视觉检测设备已经正式发货至志邦工厂,全面升级版系统在外观设计上外观设计更加简洁、大方,同时又充满了科技感,更重要的是,产品性能得到了很大的提升并获得了客户的认可。
一直以来,海研科技都致力于深入挖掘客户的痛点,为客户提供高效且智能化的解决方案。在家具板材加工领域,板材的实际尺寸与标签信息不符、崩边、划伤、孔槽缺陷、装饰瑕疵等工艺问题一直是行业内的难题。尤其是对于大型板材的检测,由于其尺寸大、外观复杂,人工检测不仅效率低下,而且容易出错。此外,传统检测方式数据无保存,追溯困难,给企业的生产管理带来了极大的不便。
今年5月,海研科技首台板材在线视觉检测系统成功研发并应用于志邦家居生产线,为志邦家居的生产效率
......长按二维码访问原文

一文看懂CMOS图像传感器指标--机器视觉网 2023-12-26 14:33:08
2023-12-26 14:33:08 来源: 中国机器视觉网
CMOS图像传感器本质是一块芯片,主要包括:感光区阵列(像素阵列)、时序控制、模拟信号处理以及模数转换等模块。
Resolution (Number of Pixels)分辨率/像素数量
MP:megapixel,兆像素(百万像素)常见的有0.3M、1M、2M、5M、13M、20M、40M、100M(1亿像素)等。像素数量和分辨率是两个密不可分的重要概念,它们的组合方式决定了图像的数据量,同样大小的图像,分辨率越高,包含的像素越多。像素总数是指所有像素的总和,像素总数是衡量CMOS图像传感器的主要技术指标之一。CMOS图像传感器的总体像素中被用来进行有效的光电转换并输出图像信号的像素为有效像素。有效像素总数隶属于像素总数集合。有效像素
......长按二维码访问原文

潮流设计,谁来守护?堡盟OXM200电动汽车外观的“造型师”--机器视觉网 2023-12-26 14:17:51
2023-12-26 14:17:51 来源: 中国机器视觉网
超高通透性的车体正在成为新能源车辆的主流造型,超大面积的前挡风玻璃,超大型的天窗占车身的比例越来越高,曲面玻璃安装的好坏直接影响车辆的质量和外观。最新发布的堡盟OXM200/OXP200传感器可以让车用玻璃的安装非常稳定,是新能源车辆造型背后的隐藏boss。
车辆外观的“造型师”
涂胶是汽车挡风玻璃安装前的重要工艺,涂胶的质量决定了汽车在使用时是否会出现脱落、漏水等问题。均匀的涂胶不仅可以控制用胶的生产成本,也能够更好的为装配后的车辆提供良好的密封性。
在实际装配应用中,OXM200表现出色,只要在OXM200传感器激光覆盖的范围内,即可到达绝佳的测量效果。通过实时检测涂胶高度、宽度等数据,判断安装过程是否有断胶,并且可以根据胶条的高度直接
......长按二维码访问原文

Teledyne DALSA自动化检测101:工业应用中的优势--机器视觉网 2023-12-26 14:09:50
2023-12-26 14:09:50 来源: 中国机器视觉网
Teledyne DALSA的Genie Nano像机能满足Kibele-PIMS所有的分辨率和速率要求。此外,其可靠性高、耐用性强,可应付恶劣的工业环境。自动检测技术改变了制造业,由其是对于半导体芯片或锂离子电池等体积虽小但价值昂贵的产品制造有着深远影响。自动检测对制造业至关重要,可用于判断部件是否符合质量标准,如果发现不符合部件则剔除,从而确保成品质量。除探伤外,还可进行定位、识别、验证和测量工作。
自动检测在制造业中的常见应用包括检测微芯片和变压器等微小部件中的潜在异常,通过平板检测发现电视和电脑屏幕中的划痕或其他微小缺陷。该视觉系统还利用类似的摄像技术检测其他平面物体,如太阳能电池板,以及食品和饮料等物品。通过使用近红外(NIR)等特定
......长按二维码访问原文

工业镜头的主要参数对成像质量的影响--机器视觉网 2023-12-26 13:53:04
2023-12-26 13:53:04 来源: 中国机器视觉网
在机器视觉系统应用中,好的镜头就相当于人拥有好的眼睛,其作用是将光学图像聚焦在图像传感器的光敏面阵上。一个高质量的工业镜头,在分辨率、明锐度、景深等方面都有很好的体现,对各种图像的校正也比较好,但其价格也会相应的提高。
在选择工业相机的同时选择合适的镜头,你可能认为自己需要的是高分辨率的相机,但是却没有选择性价比高的镜头去搭配,最后可能在高分辨率相机上浪费钱。一个高性价比镜头,不仅体现在图像效果的层面上,也体现视觉项目的成本预算中。所以,如果我们掌握一些选择镜头的规律和经验,就可以使用同档次的镜头达到更好的效果。
不同类型的工业镜头,成像质量也各不相同;即使类型相同,其成像质量也有着很大的差异,主要是因为镜头材质、加工精度和镜片结构等因素
......长按二维码访问原文

梅卡曼德作为企业代表参加北京“独角兽十条”实施座谈会―新闻频道- 视觉系统设计 2023/12/25 23:26:48
为深入落实中央经济会议精神,贯彻北京市委十三届四次全会部署,着力增强高质量发展动能,支持和服务以独角兽企业为代表的民营企业在京发展,12月22日,北京市科委、中关村管委会组织召开《关于进一步培育和服务独角兽企业的若干措施》(京科发〔2023〕11号,以下简称“独角兽十条”)实施座谈会。会议由北京市人民政府副秘书长韩耕主持,北京市人民政府党组成员、副市长于英杰出席并作总结讲话。市科委、中关村管委会副主任张宇蕾,市发展改革委二级巡视员夏翊,市国资委副主任贺昂,市地方金融监管局副局长张颖,市人才工作局流动调配处处长举辉以及北京市独角兽企业代表参会。
张宇蕾报告了“独角兽十条”的落实情况,详细介绍了政策印发以来,市科委、中关村管委会等市级部门以及相关区政府在开展独角兽企业挖掘培育、日常服务、创新支持、金融信贷、上市融
......长按二维码访问原文

FLIR Blackfly®S USB 3.1板级相机―产品聚焦频道- 视觉系统设计 2023/12/25 23:22:09
符合USB3 Vision和Genicam标准
超紧凑型M12(S-Mount)板级摄像机
支持触发器到映像可靠性(T2IR)框架
提供全封装版本
通用规格
产品介绍
FLIR Blackfly®S USB 3.1板级相机是超紧凑的高性能区域扫描相机,设计用于集成到空间受限的系统中。这些USB 3.1板级相机采用M12 S-Mount相机支架和最新的Pregius图像传感器,可实现无失真、高动态范围图像捕捉。此外,这些相机支持触发到图像可靠性(T2IR)框架,该框架是硬件和软件功能的组合,在系统级协同工作,以帮助提高成像系统的可靠性并减少停机时间。FLIR Blackfly®的USB 3.1板级摄像机符合Genicam标准,也符合USB3 Vision标准。这些相机提供对曝光、增益、白平衡和色彩校正
......长按二维码访问原文

LUCID Vision Labs™ SENSAiZ 智能视觉CMOS相机―产品聚焦频道- 视觉系统设计 2023/12/25 23:09:51
搭载1233万像素的索尼IMX500智能视觉CMOS传感器
以太网供电(PoE)以易于集成
紧凑的 55 x 40 x 35 mm 外形尺寸
使用时需要使用 Sony AITRIOS 软件
产品介绍
LUCID Vision Labs™ SENSAiZ 智能视觉CMOS相机集成了索尼的IMX500传感器和AITRIOS软件平台,将图像处理和AI图像分析直接迁移到相机上,无需外部处理或内存。索尼的IMX500 CMOS传感器采用像素芯片和逻辑芯片堆叠设计,将AI功能直接放在传感器上,从而大大缩短了处理时间且提高了安全性。这种智能视觉传感器将许多标准的图像处理步骤从基于云的系统转移到相机本身,捕捉图像的信息和意义,只允许输出必要的数据。这带来了更低的延迟、离线图像处理、更高的安全性、更低的功耗要求
......长按二维码访问原文

图漾科技3D工业视觉应用开发平台VISION++―产品聚焦频道- 视觉系统设计 2023/12/21 23:32:57
2023年12月20日,全球领先的3D机器视觉企业图漾科技发布了3D工业视觉应用开发平台Vision++,集成了简单易用的图形化低代码开发环境、丰富的2D和3D视觉算子库、用户面板设计工具等功能组件,同时支持用户进行二次开发并可灵活扩展用户私有和第三方的算子。
自发布日起,Vision++正式面向全行业用户和合作伙伴开放免费授权,以推动3D机器视觉的应用开发更加简单快捷。
众所周知,2D机器视觉领域里有Halcon以及VisionPro这样的软件开发平台,拥有广泛的用户基础和庞大的生态系统,在便利了用户的项目开发的基础上,推动了整个2D视觉行业的技术普及及应用渗透。
而在新兴的3D视觉领域中还缺乏同类型的软件开发平台,导致目前3D视觉项目面临着开发门槛高的挑战。作为业内的领先企业,图漾科技率先推出
......长按二维码访问原文

自动光学检测 (AOI) ,精确的自动化光学检测提高制造效率―技术与应用频道- 视觉系统设计 2023/12/26 15:51:33
凌华科技自动光学检测 (AOI) 解决方案采用Intel CPU、GPU,以及经过OpenVINO toolkit优化的AI模型,提供高精度的大规模视觉推理,减少制造过程中有关质量保证的间接成本。
人类的视觉和注意力无法满足生产线上视觉产品检测的需求。人类在从事高速和重复的判断时,准确性和可靠性就会下降。多年来,利用计算机视觉技术来增强人类的工 作流程,已经成功地减少了疲劳并提高了准确性和生产力。
现在,AI 的进步进一步改 进了这个模型,让基于神经网络的自动光学检测(AOI),大幅减轻检测人员的工作 负担。AOI系统使用相机传感器来采集生产线上产品的图像,然后通过算法分析这些图像,并 识别其缺陷和异常。这种流程适用于各种制造行业,具有改善质量控制和降低成本的 潜力。因此,预计到2032年1,全球细分市场的
......长按二维码访问原文

AI-MASTER应用于工件焊缝方向的视觉检测―技术与应用频道- 视觉系统设计 2023/12/26 9:07:31
利用 AI-MASTER 视觉系统检测工件的焊缝方向,即用机器视觉拍摄取图,对工件特征点的识别来进行工件方向的判定。AI-MASTER视觉系统在该领域有很多成功应用,另外,在半导体、电子、激光加工、太阳能、金属加工、汽车、包装等众多行业也有着普遍的应用。
客户名称 :常州柯勒玛智能装备有限公司
常州柯勒玛智能装备有限公司,公司致力于为客户提供智能制造装备及工业机器人系统集成解决方案,提供从设计研发,生产制造,销售,服务于一体的覆盖全项目周期的产品与服务。我们以“专业,创新,服务,诚信”为宗旨,为新能源汽车,卫浴,农业自动化,航空航天等领域的客户提供服务。
柯勒玛公司业务范围:工厂智能装备整体解决方案,工业机器人系统集成:切割,喷涂,涂胶,打磨抛光,智能搬运等公司地址位于常州天宁区,注册资本980万,拥有专
......长按二维码访问原文

DLNR还没来,先看EAI-stereo! 2023-12-26 16:08
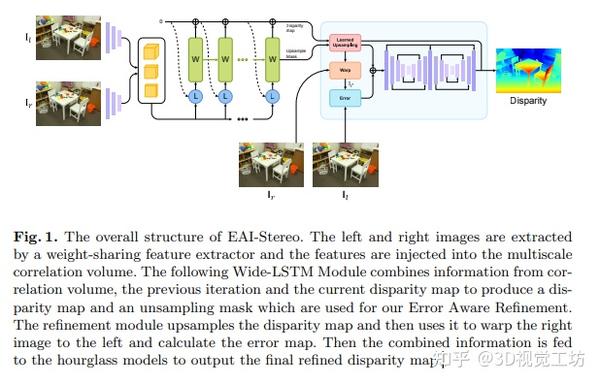
由诡谷子AI开放实验室开发的双目视觉立体匹配算法EAIStereo ( EAI-Stereo: Error aware iterative network for stereo matching),针对立体匹配算法中未充分利用高频信息而导致相对模糊的问题,提出了一种误差感知细化模块,将来自原始图像的高频信息结合进来进行误差校正,生成出精细的细节和尖锐的边缘。另外,为了提高数据传输效率,作者还提出了迭代多尺度宽式长短时记忆网络。实验证明,该方法在多个数据集上取得了良好的效果,并且在 Middlebury 排行榜和 ETH3D 立体基准测试上表现出色。
1 前言
估计像素对应关系的问题是立体匹配的任务。 传统立体匹配算法有四步骤:匹配代价计算、代价聚合、视差计算和优化。 学习式方法与传统方法相比,通常产生更准确
......长按二维码访问原文

通用 Vision Backbone 超详细解读 (二十九):视觉 Transformer 需要寄存器 2023-12-26 15:28
本系列已授权极市平台,未经允许不得二次转载,如有需要请私信作者。
专栏目录
本文目录
1 视觉 Transformer 需要寄存器
(来自 FAIR, Meta)
1 Register 论文解读
1.1 背景:视觉 Transformer 的特征中存在 "伪影"
1.2 视觉 Transformer 中 "伪影" 的特点
1.3 针对 "伪影" 的假设和补救措施
1.4 实验结果
太长不看版
本文提出视觉 Transformer 的特征中存在 "伪影",这个现象无论是有监督训练还是自监督训练的视觉 Transformer 中都存在。这些 "伪影" 会导致一些 token 的拥有很高的范数,这些 token 通常是在图片信息密度比较低的背景中出现,然后会参与到后续模型的计算过程中。
作者通
......长按二维码访问原文

动态环境下竟然能在嵌入式系统上实现实时语义RGB-D SLAM? 2023-12-26 11:00

大多数现有的视觉SLAM方法严重依赖于静态世界假设,在动态环境中很容易失效。本文提出了一个动态环境下的实时语义RGB-D SLAM系统,该系统能够检测已知和未知的运动物体。为了减少计算成本,其只对关键帧进行语义分割以去除已知的动态对象,并保持静态映射以实现稳健的摄像机跟踪。此外,文章还提出了一个有效的几何模块,通过将深度图像聚类到几个区域,并通过它们的重投影误差来识别动态区域,从而检测未知的运动物体。
论文题目:Towards Real-time Semantic RGB-D SLAM in Dynamic Environments
中文题目:动态环境下实时语义RGB-D SLAM研究
作者:Tete Ji, Chen Wang, and Lihua Xie
作者机构:新加坡南洋理工大学电气与电子工程学
......长按二维码访问原文

TokenFlow:一致的扩散特征用于一致的视频编辑 2023-12-26 11:59

Basic Information:
Title: TokenFlow: Consistent Diffusion Features for Consistent Video Editing (TokenFlow:一致的扩散特征用于一致的视频编辑)
Authors: Michal Geyer, Omer Bar-Tal, Shai Bagon, Tali Dekel
Affiliation: Weizmann Institute of Science (以色列魏茨曼科学研究所)
Keywords: generative AI, video editing, text-to-image diffusion model, semantic correspondences, temporal consiste
......长按二维码访问原文

ICCV 2023 I NDC-Scene:单目三维语义场景补全的新突破 2023-12-26 17:08

本文提出了一种新颖的归一化设备坐标场景完成网络(NDC-Scene),用于解决单目三维语义场景完成(SSC)中的几个关键问题。通过将二维特征图扩展到归一化设备坐标空间,而不是直接扩展到世界空间,以及使用深度自适应双解码器进行上采样和融合,提出的方法在单目SSC任务中表现出色,并在室外SemanticKITTI和室内NYUv2数据集上优于最先进的方法。
读者理解:
本文提出了一种新的方法,用于从单个图像中预测复杂的语义和几何形状,而无需3D输入。作者指出了当前最先进方法中存在的几个关键问题,包括射线到3D空间中投影的2D特征的特征模糊性,3D卷积的姿态模糊性以及不同深度层次上3D卷积中的计算不平衡性。为了解决这些问题,作者设计了一种新颖的规范化设备坐标场景补全网络(NDC-Scene),通过逐步恢复深度维度来
......长按二维码访问原文

图像处理神器!谷歌新作TIP:具有语义和复原指令的文本驱动图像处理 2023-12-26 11:34

一句话总结
图像处理神器!TIP:一个统一的文本驱动框架,用于使用语义和复原提示进行指示图像处理。据称,这是第一个同时支持语义和参数嵌入复原指令的框架,允许用户灵活地提示调优结果以达到他们的预期,在定量和定性结果方面都显著优于先前的工作!代码即将开源!
点击关注 @CVer官方知乎账号,可以第一时间看到最优质、最前沿的CV、AI工作~
TIP
TIP: Text-Driven Image Processing with Semantic and Restoration Instructions
单位:谷歌, HKUST
主页:https://chenyangqiqi.github.io/tip/
论文下载链接(PDF已上传至星球,可一键下载):https://arxiv.org/abs/2312.
......长按二维码访问原文

SDV-LOAM:半直接视觉和激光雷达融合SLAM 2023-12-25 14:45

SDV-LOAM:半直接视觉和激光雷达融合SLAM
参考论文:SDV-LOAM: Semi-Direct Visual–LiDAR Odometry and Mapping
作者机构:华中科技大学人工智能研究所
论文链接:[https://ieeexplore.ieee.org/document/10086694]
项目主页:[https://github.com/ZikangYuan/SDV-LOAM)
本文介绍了SDV-LOAM,一种融合相机和 LiDAR 信息的系统,用于实现准确、强大的姿态估计和建图。现有方法使用特征或直接方法作为视觉模块,无法很好地处理视觉模块中稀疏特征建立造成的误差。作者的动机是结合两种方法的优势来实现准确的姿态估计。本文提出的研究方法SDV-LOAM 包括,半直接视觉里程
......长按二维码访问原文

3D 对象生成 | NeRF+GAN的超网络:HyperNeRFGAN 2023-12-25 15:28

3D对象的生成模型在VR和增强现实应用中越来越受欢迎。但使用标准的3D表示(如体素或点云)来训练这些模型是具有挑战性的,并且需要复杂的工具来进行适当的颜色渲染。神经辐射场( NeRF )在从一小部分2D图像合成复杂3D场景的新视图方面提供了最先进的质量。
作者提出了一个生成模型 HyperNeRFGAN ,它使用超网络范式来生成由 NeRF 表示的三维物体。超网络被定义为为解决特定任务的单独目标网络生成权值的神经模型。基于 GAN 的模型,利用超网络范式将高斯噪声转换为 NeRF 的权重。通过 NeRF 渲染2D新视图,并使用经典的2D判别器以隐式形式训练整个基于GAN的结构。
提出了基于 NeRF 的隐式GAN架构——第一个用于生成高质量3D NeRF 表示的GAN模型。与基于 SIREN 的架构相比,利
......长按二维码访问原文

CVPR2023 I Gated Stereo:如何利用多视角和TOF强度线索进行深度估计? 2023-12-26 15:35

Gated Stereo是一种高分辨率和长距离深度估计技术,可在活动门控立体图像上运行。使用主动和高动态范围的被动捕捉,Gated Stereo利用多视角线索以及来自主动门控的飞行时间强度线索。为此,作者提出了一种具有单眼和立体深度预测分支的深度估计方法,在最终融合阶段中将它们结合起来。
1 前言
本文提出了一种名为Gated Stereo的高分辨率和远距离深度估计技术,其基于活动门控立体图像进行运算。Gated Stereo通过利用多视角线索和来自活动门控的飞行时间强度线索,以及活动捕获和高动态范围的被动捕获,实现了立体深度信息的高效估计。为了实现这个目的,作者提出了一种具有单目和立体深度预测分支的深度估计方法,在最终的融合阶段组合这两个分支。每个块都通过监督和门控自监督损失的组合进行监督学习。为了便于训
......长按二维码访问原文

最新 I LEAP:一种不需要相机姿态的稀疏视图三维建模方法 2023-12-26 15:03

摄像机姿态对于多视角三维建模是否必要?现有的方法主要假设可以获得准确的摄像机姿态。虽然这个假设对于密集视图可能成立,但对于稀疏视图,准确估计摄像机姿态常常是困难的。作者的分析显示,噪声估计的姿态会导致现有稀疏视图三维建模方法的性能下降。为了解决这个问题,作者提出了LEAP,一种新颖的无姿态方法,挑战了摄像机姿态不可或缺的普遍观念。LEAP舍弃了基于姿态的操作,从数据中学习几何知识。LEAP配备了一个神经体积,该体积在场景之间共享,并且通过参数化编码几何和纹理先验。对于每个输入的场景,作者通过按特征相似性驱动的方式聚合2D图像特征来更新神经体积。更新后的神经体积被解码为辐射场,从而可以从任意视点合成新的视图。通过对物体为中心和场景级别的数据集进行实验,作者展示了LEAP在使用最先进的姿态估计器预测的姿态时显著优于
......长按二维码访问原文

2020到2023年NeRF开源代码库与框架盘点,哪款更适合你? 2023-12-25 17:44
自从在ECCV'20被提出以来,NeRF(神经辐射场)在3D视觉领域激发了很多有趣的创新工作,同时也出现了很多优秀的开源工作,本文对近期(2020-2023)的NeRF相关典型的开源代码库和框架做一个盘点,涵盖静态场景、动态场景、相机位姿优化、可变形场景、无界场景、表面重建、显式建模、集成开发框架、加速库等,希望能对大家有一点点帮助。
1 NeRF开源代码库
1.1 NeRF
1.2 pixelNeRF
1.3 Nerfies
1.4 mip-NeRF
1.5 BARF
1.6 NeuS
1.7 mip-NeRF 360
1.8 TensoRF
1.9 TAVA
1.10 dycheck
1.11 K-Planes
1.12 NeuS2/NeuS2++
2 NeRF开源框架
2.1
......长按二维码访问原文

基于感知质量的滚动优化无人机导航 2023-12-26 11:15

1 前言
微型飞行器(MAVs)既灵活又通用,适用于工业检测、农业和货物运输等各种任务。为了使无人机能够在未知环境中自主运行,需要可靠的定位和对自身位姿的估计。在用于状态估计的不同传感器中,摄像机重量轻且节能,非常适合于微型飞行器。
在对于基于视觉的状态估计中,摄像机的运动对估计精度有重要影响。因此,在规划无人机的运动时,既要考虑以上的任务,又要考虑感知质量。
本文的设计思路是一个典型的ActiveSLAM问题,作者选择了使状态估计精度最大化的运动,使得无人机在运行过程中不至于发生定位丢失,而且他们没有摒弃了优化全局地图中的运动轨迹的方法,而是用滚动的方式来解决主动SLAM问题,这样有效地降低了计算资源。
形象说明:他们算法的示意图如上所示,这个方法遵循图中蓝色轨迹运动,这个轨迹可以避开障碍物、到达指定
......长按二维码访问原文

最新NeRF文章 l Blended-NeRF:混合神经辐射场中的零样本物体生成和混合 2023-12-26 15:08
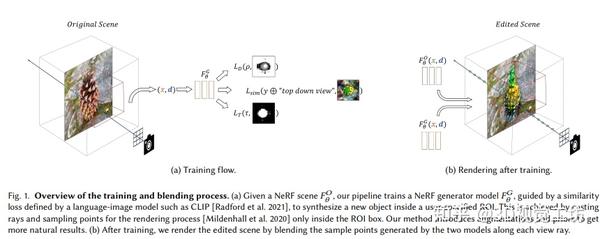
Blended-NeRF是一个强大而灵活的框架,用于编辑NeRF场景中的特定兴趣区域。该框架利用预训练的语言-图像模型和现有NeRF场景上初始化的3D MLP模型,根据文本提示或图像块合成并混合对象到原始场景中的指定区域。使用3D ROI框实现局部编辑,并通过体积混合技术将合成内容与现有场景融合。为了获得逼真且一致的结果,该框架使用几何先验和3D增强技术提高视觉保真度。在定性和定量测试中,Blended-NeRF展示了比基准方法更大的灵活性和多样性的逼真多视图一致结果。此外,该框架适用于多种3D编辑应用。
1 前言
近年来,在神经隐式表示领域取得了重要的进展,特别是对于3D场景的隐式表示。NeRFs是一种基于MLP的神经模型,可以通过体积渲染从有限数量的观测生成高质量的图像。然而,编辑NeRF表示的场景是具
......长按二维码访问原文

CVPR 2023 I NeuMap:自动Transdecoder神经坐标映射用于相机定位 2023-12-26 15:25
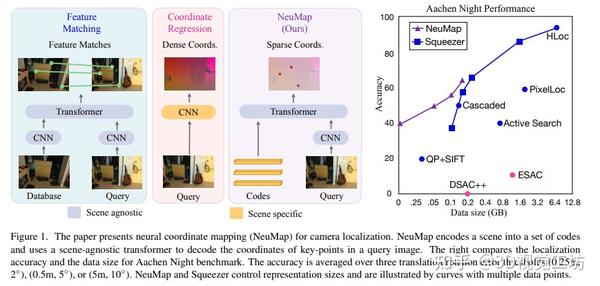
本文介绍了一种用于相机定位的端到端神经映射方法NeuMap。NeuMap通过使用可学习的潜在编码和基于Transformer的自动解码器来编码整个场景并回归查询像素的3D坐标。相比于当前的特征匹配方法和坐标回归方法,NeuMap能够在保持较小场景表示大小的同时,取得显著优于其他方法的表现。在Aachen夜间基准测试中,NeuMap仅使用6MB的数据就实现了39.1%的准确率,而其他方法在高压缩设置下需要100MB或几GB,并且无法成功。这种基于神经网络的方法在处理大规模数据时具有较强的鲁棒性,并且能够快速优化新场景的编码。
1 前言
本文介绍了一种名为NeuMap的神经坐标映射方法,用于图像的相机定位任务。NeuMap利用紧凑的场景表示和稳健的性能,结合了特征匹配和场景坐标回归两种方法的优势。NeuMap首
......长按二维码访问原文

CVPR2023 | Co-SLAM: 联合坐标和稀疏参数编码的神经实时SLAM 2023-12-26 14:59
本文提出了Co-SLAM,一种基于混合表示的神经RGB-D SLAM系统,可以实时执行鲁棒的相机跟踪和高保真的表面重建。 Co-SLAM将场景表示为多分辨率哈希网格,以利用其高收敛速度和表示高频局部特征的能力。 此外,Co-SLAM结合了one-blob编码,以促进未观察区域的表面一致性和补全。这种联合参数坐标编码通过将快速收敛和表面孔填充这两方面的优点结合起来,实现了实时性和鲁棒性。 此外,我们的射线采样策略允许Co-SLAM在所有关键帧上执行全局BA,而不是像其它的神经SLAM方法那样需要关键帧选择来维持少量活动关键帧。 实验结果表明,Co-SLAM以10-17Hz的频率运行,并在各种数据集和基准(ScanNet, TUM, Replica, Synthetic RGBD)中获得了最先进的场景重建结果,并具
......长按二维码访问原文

CVPR 2023 OpenLane性能自动驾驶挑战赛冠军解决方案 2023-12-26 15:27
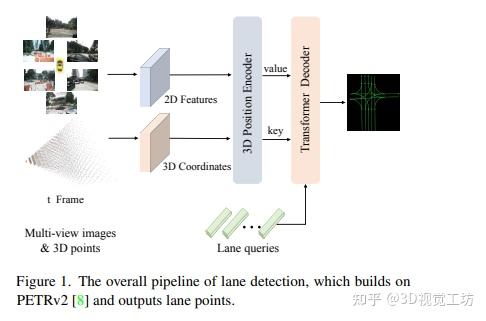
本研究提出了解决OpenLane拓扑任务的一流方法,该任务是自主驾驶挑战赛中的主要任务之一。作者通过使用性能强大的PETRv2检测器和热门的YOLOv8检测器,在中心线和交通元素的检测阶段实现了优秀的表现。同时,作者的方法还设计了一个简单而有效的基于多层感知器的拓扑预测头部。实验结果显示,作者的方法在OpenLaneV2测试集上取得了55%的OLS,比第二名解决方案高出8个百分点。这表明作者的方法在拓扑任务中取得了显著的性能优势,并具有实际应用的潜力。
1 引言
本文介绍了OpenLane拓扑任务,这是自主驾驶领域的一个新的感知和推理任务,用于理解三维场景结构。任务的关键是分析交通元素和中心线之间的感知实体之间的关系。作者提出了一个多阶段的框架,将基本的检测和拓扑预测任务解耦。具体方法包括使用先进的3D/2
......长按二维码访问原文

ICCV2023:第一个基于DETR的高质量通用目标检测方法 2023-12-25 19:07
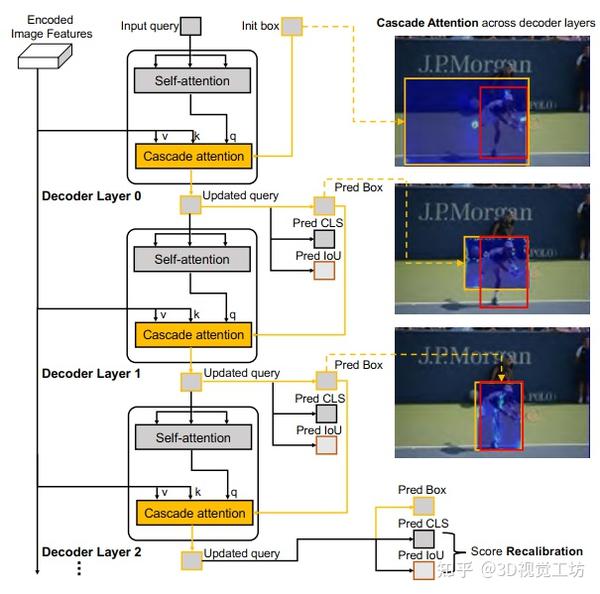
概述
目标检测是具有广泛实际应用的计算机视觉任务,如自动驾驶和医学影像。随着DETR 的出现,基于Transformer的检测器的发展令人瞩目,并且在最新的DETR系列方法在COCO挑战中以明显的优势击败了基于CNN的检测器。
但是,现有DETR系列模型在非COCO数据集上表现较差,且预测框不够准确。
本文提出了Cascade-DETR用于高质量通用目标检测。我们通过提出Cascade Attention层同时解决不同域的泛化问题和定位精度问题,它通过限制注意力到先前的预测框,将以对象中心的信息直接输入到检测解码器中。为进一步提高准确性,我们还重新访问查询分数。我们预测查询期望的IoU,而不再依赖于分类分数,从而大大提高了校准后的置信度。最后,我们引入了通用目标检测基准UDB10,其中包含10个数据集。同
......长按二维码访问原文

速速收藏~超全!2D单目标跟踪常用评价指标及完整代码 2023-12-25 17:49
这里分别展示了APE、AOR、Pixel Error threshold、Overlap Rate threshold、Success plot、TRE、SRE和EAO八种指标的计算代码。
# APE(Average Pixel Error):平均像素误差,一般指预测框与真实框中心位置的像素距离取帧平均。 # 假设preds和gts是两个列表,分别存储预测框和真实框的中心坐标,如[(x1, y1), (x2, y2), ...] # 假设n是帧数 def APE ( preds , gts , n ): # 初始化总误差为0 total_error = 0 # 遍历每一帧 for i in range ( n ): # 计算预测框和真实框中心坐标的欧式距离 error = (( preds [ i ][ 0
......长按二维码访问原文

ICCV2023:最新激光雷达语义分割SOTA!MemorySeg! 2023-12-25 19:03
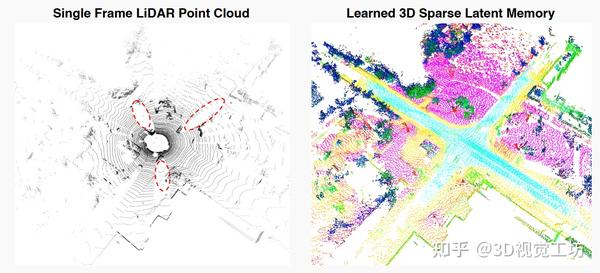
笔者总结
本文提出了一种在线激光雷达语义分割框架MemorySeg,它利用三维潜在记忆来改进当前帧的预测。传统的方法通常只使用单次扫描的环境信息来完成语义分割任务,而忽略了观测的时间连续性所蕴含的上下文信息。该框架旨在解决在激光雷达表示中引入记忆的若干挑战,包括遮挡、资源限制和动态场景。作者引入了一种点级邻域变化正则化器,用于抑制局部三维邻域内预测的剧烈变化,并在SemanticKITTI、nuScenes和PandaSet等公开数据集上验证了MemorySeg的有效性。所提出的框架构建了周围环境的稀疏三维潜在表示,提供了丰富的三维上下文,从而区分不同的类别,尤其是在当前被遮挡的区域。MemorySeg优于仅依赖激光雷达的当前最先进的语义分割方法。该方法能够保留先前观测到的区域,即使在当前被遮挡,因为遮挡物和
......长按二维码访问原文

Github70k star!GitHub中文排行榜,帮助你发现优秀中文项目 2023-12-26 16:26

项目地址:https://github.com/GrowingGit/GitHub-Chinese-Top-Charts
你还在寻找GitHub中文资料而发愁吗?你还在GitHub因为英文不好而犯难吗?你还在找不到中文组织而难过吗?
GitHub中文排行榜「帮助你发现优秀中文项目,可以无语言障碍地、更高效地吸收优秀经验成果」
项目特色亮点
【首创】中文排行榜
筛选出有中文文档的项目进行排名,帮助大家更低门槛探索优秀开源项目,打破语言障碍; 中文项目既包含国产好项目,也包含国外优质的含中文文档的项目; 评选逻辑是保持活跃+总星数;
【首创】中文增速榜
帮助大家发现增速较快的项目,优秀不止于老项目; 评选逻辑是保持活跃+日均涨星数;
【首创】中文新秀榜
帮助大家发现近一年的潜力新项目,后起之秀就在
......长按二维码访问原文

CVPR2023 I 一种实用的智能眼镜深度感知系统 2023-12-26 15:48
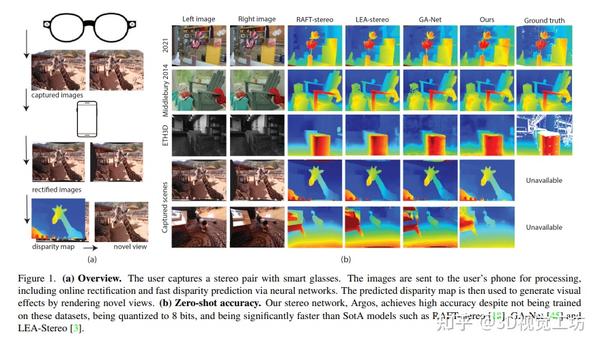
本文提出了一种生产化的端到端立体深度感知系统设计,可以完成预处理、在线立体校正和立体深度估计,并支持纠偏失败后的单目深度估计备选方案。同时,该深度感知系统的输出应用于一种基于智能眼镜拍摄的视角生成管道,创造出具有3D计算摄影效果的视觉效果。此外,该系统设计可以在手机的严格计算预算内运行,具有通用性,可以适用于各种品牌的智能手机。该论文的设计是为了解决智能眼镜中的深度感知问题,可以为智能眼镜提供更好的增强现实体验。
1 前言
本文介绍了一种生产化的端到端深度感知系统,包括预处理、在线立体校正、立体深度估计并支持单目深度估计的备用方案。该系统的输出结果应用于视角生成的渲染管道,创建具有3D计算摄影效果的效果。该系统设计具有通用性和稳健性,可以用于不同品牌的主流手机。
我们的技术和系统贡献包括:
详细描述了一
......长按二维码访问原文

ICCV 2023 I ELFNet:基于 Transformer 和深度证据学习的立体匹配 2023-12-26 16:57
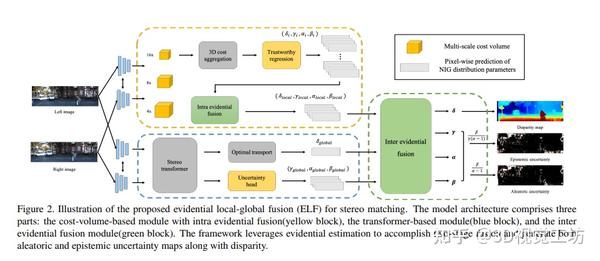
本文引入了Evidential Local-global Fusion (ELF)框架,用于解决立体匹配中的可信度估计和融合问题。与传统方法仅预测视差图不同,作者的模型估计了基于证据的视差,考虑了模糊不确定性和认知不确定性。通过正态逆伽马分布进行证据融合,实现了多层次预测的内部证据融合和基于成本体积和变换器的立体匹配的证据间融合。实验结果表明,所提出的框架有效地利用了多视角信息,在准确性和跨域泛化性能上达到了最先进水平。
1 前言
立体匹配是在给定一对矫正图像的情况下,估计密集视差图的目标,是各种应用中最基础的问题之一,例如3D重建、自动驾驶和机器人导航。借助卷积神经网络的快速发展,许多立体匹配模型通过构建代价体积并使用3D卷积的方式取得了有希望的性能。最近,借助transformer的支持,提出了利用自注
......长按二维码访问原文

TRO新文:用于数据关联、建图和高级任务的对象级SLAM框架 2023-12-25 14:51

对象SLAM被认为对于机器人高级感知和决策制定越来越重要。现有研究在数据关联、对象表示和语义映射方面存在不足,并且经常依赖于额外的假设,从而限制了它们的性能。在本文中,我们提出了一个综合的对象SLAM框架,该框架专注于基于对象的感知和面向对象的机器人任务。首先,我们提出了一种集成数据关联方法,用于通过结合参数和非参数统计测试来关联复杂条件下的对象。此外,我们建议基于iForest和线对齐的对象建模的离群鲁棒质心和尺度估计算法。然后由估计的通用对象模型表示轻量级和面向对象的地图。考虑到对象的语义不变性,我们将对象图转换为拓扑图以提供语义描述符以实现多图匹配。最后,我们提出了一种对象驱动的主动探索策略,以在抓取场景中实现自主建图。
提出的对象SLAM框架。
1 系统框架
本框架主要包含4个模块:
1.Tra
......长按二维码访问原文

CVPR2023 I 一种全新的单个宽基线立体图像对中学习渲染新视角的方法 2023-12-26 15:47
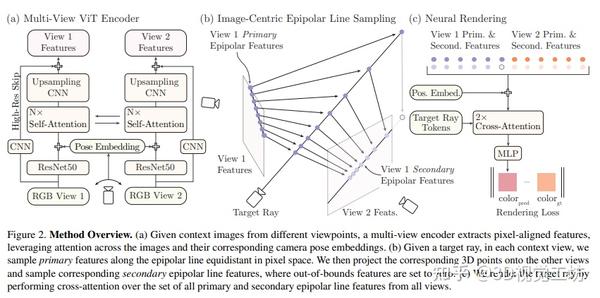
作者引入了一种方法,可以仅使用单个宽基线立体图像对生成新视角。在这种具有挑战性的情况下,3D场景点只被正常观察一次,需要基于先验进行场景几何和外观的重建。作者发现从稀疏观测中生成新视角的现有方法因恢复不正确的3D几何和可导渲染的高成本而失败,这阻碍了其在大规模训练中的扩展。作者通过构建一个多视图转换编码器、提出一种高效的图像空间极线采样方案来组装目标射线的图像特征,以及一个轻量级的基于交叉注意力的渲染器来解决这些问题。作者的贡献使作者的方法能够在一个大规模的室内和室外场景的真实世界数据集上进行训练。作者展示了本方法学习到了强大的多视图几何先验,并降低了渲染时间。作者在两个真实世界数据集上进行了广泛的对比实验,在保留测试场景的情况下,明显优于先前从稀疏图像观测中生成新视图的方法并实现了多视图一致的新视图合成。
......长按二维码访问原文

3D点云目标跟踪的评价指标及详细代码 2023-12-25 17:59
3D点云目标跟踪的评价指标,可以根据跟踪的目标是单个还是多个,分为单目标跟踪(SOT)和多目标跟踪(MOT)两种。一般来说,SOT的评价指标主要关注跟踪的准确性和鲁棒性,而MOT的评价指标则需要考虑跟踪的完整性和一致性。
SOT的常用评价指标有:
平均重叠率(Average Overlap Rate, AOR):表示预测的3D边界框与真实的3D边界框之间的重叠比例的平均值。
平均中心误差(Average Center Error, ACE):表示预测的3D边界框与真实的3D边界框之间的中心点距离的平均值。
成功率(Success Rate, SR):表示预测的3D边界框与真实的3D边界框之间的重叠比例超过某个阈值(如0.5)的帧数占总帧数的比例。
精确率(Precision Rate, PR):表示预
......长按二维码访问原文

网课部署分享 | K8S 部署 JupyterHub 集群 2023-12-26 12:40
该文章分享一次 Computer Vision 网课实践平台部署方案。在进行 CV 相关技术教学时,往往会涉及到学生实操环节,之前每次授课,如果将源代码发给学生,都会有学生环境安装问题。于是便实践了以下粗糙的 k8s 部署 jupyterhub 方案。总结来说,该方案能根据学生数量,自动拓展服务器规模。同时保证每位同学的网课环境一致,避免了不必要的环境安装问题。
JupyterHub K8S on Azure K8S services
该方案中我们使用 Azure K8S 服务,搭建多用户 JupyterHub 环境。当然你也可以使用其他 K8S 平台,或者自己在本地安装 K8S 集群。了解 K8S 基本概念与操作。关于 K8S 基础理论,可以参考 K8S 视频教程笔记
K8S 基础概念
来源:k8s
......长按二维码访问原文

ikd树:激光雷达SLAM中高效的点云数据结构 2023-12-25 14:39

作者机构:HKU
项目主页:https://github.com/hku-mars/ikd-Tree.git
k-d树是一种常用的多维数据结构,它可以用于范围搜索、最近邻搜索等问题。但是,在实际应用中,我们经常需要对动态数据进行查询和修改操作。这时候,传统的k-d树就显得力不从心了。为了解决这个问题,研究人员提出了动态k-d树(Dynamic k-d Tree)这一概念。与传统的k-d树不同,动态k-d树可以支持插入、删除和修改操作,并且能够保持平衡状态。动态k-d树可以用于各种多维数据结构问题,例如范围搜索、最近邻搜索等。本文将介绍动态k-d树的基本原理、实现方法。
1 基本原理
1.1 k-d树
首先,我们来回顾一下传统的k-d树。k-d树是一种二叉搜索树,它将每个节点表示为一个超矩形,并按照某种
......长按二维码访问原文

CVPR2023 I PartManip从点云观察中学习跨类别零件操作的通用策略 2023-12-26 15:39
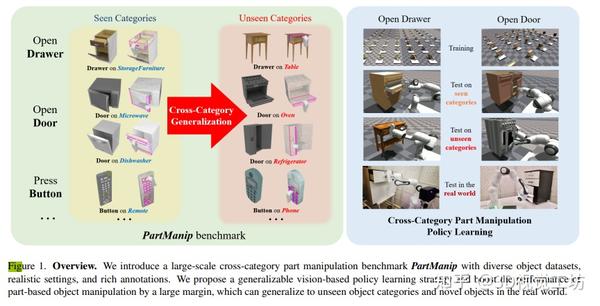
学习一个具有一般化能力的物体操作策略对于一个具身体的智能体在复杂的现实世界场景中工作至关重要。部件作为不同物体类别中的共享组件,具有增加操作策略的一般化能力并实现跨类别物体操作的潜力。在这项工作中,作者构建了第一个大规模的、基于部件的跨类别物体操作基准,名为PartManip,它由11个物体类别、494个物体和6个任务类别中的1432个任务组成。与以前的工作相比,作者的基准也更加多样化和现实化,即具有更多的物体,并使用稀疏视点云作为输入,而没有像部件分割这样的预先信息。为了解决基于视觉的策略学习的困难,作者首先使用提出的基于部件的规范化和部件感知奖励来训练一个基于状态的专家,然后将知识传递给一个基于视觉的学生。作者还发现,具有表达力的主干网络对于克服不同物体的大量差异至关重要。为了实现跨类别的一般化,作者引入了
......长按二维码访问原文

所有指标全面领先!图像-点云配准最新SOTA!CoFiI2P详细介绍! 2023-12-25 18:56
1. 笔者总结
本文介绍了 CoFiI2P,这是一种新颖的图像到点云(I2P)配准网络。传统的I2P配准方法通常在点到像素级别估计对应关系,但忽略了全局关系,这往往导致陷入局部最优解。为了解决这个问题,CoFiI2P采用分层的方式提取对应关系,使神经网络可以考虑全局信息,从而获得全局最优解。
具体来说:
图像和点云首先通过 Siamese编码器-解码器网络 进行分级特征提取。
进行分级特征提取。 设计了一个 从粗到细 的匹配模块,建立鲁棒的特征对应关系。
的匹配模块,建立鲁棒的特征对应关系。 在 粗匹配 模块中,采用了一种新颖的 I2P Transformer 模块 ,从图像和点云中捕获全局信息,并估计粗糙的超点到超像素匹配对。
模块中,采用了一种新颖的 ,从图像和点云中捕获全局信息,并估计粗糙的超
......长按二维码访问原文

一文搞定opencv中常见的关键点检测算法(附代码) 2023-12-26 11:51
前言
角点时图像中存在物体边缘角落位置的点或者一些特殊位置的点,角点检测(Corner Detection)是计算机视觉系统中获取图像特征的一种方法,是运动检测、图像匹配、视频跟踪、三维重建和目标识别的基础。
本篇文章将介绍opencv中常用的几种角点检测方法的原理和基于C++的实现。
一、Harris角点检测
Harris角点原理:设置一个矩形框,将这个矩形框放置在图像中,将矩形框内像素进行求和,然后移动矩形框,当相邻两次求和得到的值差别较大时,判定矩形框内存在Harris角点。
通常出现的位置:直线的端点处、直线的交点处、直线的拐点处。
但是如果按照上述检测原理检测,会很麻烦,很难确定矩形框移动的方向和当框内出现角点时,角点的具体位置。
因此,在程序中一般是用以下方式进行检测: 1.定义Har
......长按二维码访问原文

ICCV 2023 I 你还在为点云数据发愁吗?AutoSynth:自动生成 3D 训练数据 2023-12-26 17:11

本文介绍了一种名为 AutoSynth 的自动生成 3D 训练数据的方法,用于点云配准。该方法通过探索包含数百万个不同 3D 形状的数据集搜索空间,在低成本的情况下自动筛选出一个最佳数据集。为了实现这一目标,该方法通过组装形状基元生成合成的 3D 数据集,并采用元学习策略来搜索适用于实际点云的最佳训练数据。为了提高搜索的效率,点云配准网络被一个规模更小的替代网络代替,速度提高了 4056.43 倍。实验结果表明,使用作者搜索的数据集进行训练的神经网络相比于使用常用的 ModelNet40 数据集进行训练的网络,在 TUDL、LINEMOD 和 Occluded-LINEMOD 数据集上具有更好的性能。
读者理解:
这篇文章提出了一个称为AutoSynth的新方法,可以自动生成大量3D训练数据,并从数百万种可
......长按二维码访问原文

CV计算机视觉每日开源代码Paper with code速览-2023.12.25 2023-12-26 00:23
精华置顶
墙裂推荐!小白如何1个月系统学习CV核心知识:链接
点击@CV计算机视觉,关注更多CV干货
论文已打包,点击进入—>下载界面
点击加入—>CV计算机视觉交流群
1.【图像分类】(AAAI2024)I-CEE: Tailoring Explanations of Image Classifications Models to User Expertise
2.【目标检测】(AAAI2024)Object-Aware Domain Generalization for Object Detection
3.【Open-Vocabulary Object Detection】(AAAI2024)Weakly Supervised Open-Vocabulary Object Detection
......长按二维码访问原文

AAAI 2024 | 西电提出RIRC:可见水印去除新工作 2023-12-26 17:30

一句话总结
RIRC:一种可见水印去除新工作,其是两阶段框架:初始阶段集中于识别和分离水印成分,而后续阶段则集中于背景内容恢复,在两个大规模数据集上性能表现SOTA!
点击关注 @CVer官方知乎账号,可以第一时间看到最优质、最前沿的CV、AI工作~
RIRC
Removing Interference and Recovering Content Imaginatively for Visible Watermark Removal
单位:西电, 港中大, 中山大学等
论文:https://arxiv.org/abs/2312.14383
可见水印虽然有助于保护图像版权,但经常会扭曲底层内容,使场景解释和图像编辑等任务变得复杂。可见水印去除的目的是消除水印的干扰,恢复背景内容。然而,现有的方法通
......长按二维码访问原文

多模态: 点云+文本 | 通过 CLIP 理解点云:PointCLIP 2023-12-26 15:00
基于视觉-语言的对比预训练 (CLIP),提出在自然语言监督下学习可转移的视觉特征,已经在图像与文本匹配的 2D 视觉识别中表现出了令人鼓舞的效果。通过大规模 2D图像-文本对预训练的 CLIP 是否可以推广到三维识别?该作者提出 PointCLIP 来首次确定这种设置是可行的, PointCLIP 在 CLIP 编码的3D点云和类别文本之间进行对齐。具体来说,通过将3D点云投影到多视图深度图上对其进行编码,并以端到端的方式聚合逐视图的 zero-shot 预测,从而实现从 2D 到 3D 的高效知识转移。为了更好地提取全局特征,并将 3D few-shot 知识自适应地融合到 2D 预训练的CLIP中,进一步设计了一个 inter-view 适配器。此外, PointCLIP 与经典 3D 监督网络之间的知识
......长按二维码访问原文

比目前最先进的模型轻30%!高效多机器人SLAM蒸馏描述符! 2023-12-26 10:41
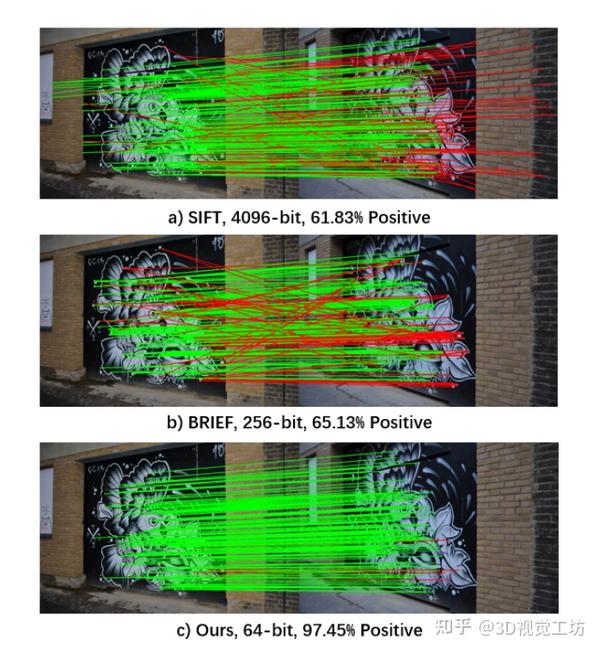
本文通过生成具有最小推理时间的紧凑且具有判别性的特征描述符来解决多机器人探索过程中保持低水平通信带宽的同时进行精确定位的问题;文中将描述符生成转化为老师-学生框架下的学习问题。首先设计一个紧凑的学生网络,通过从预训练的大型教师模型中转移知识来学习它。为了减少从教师到学生的描述符维度,文中提出了一种新的损失函数,使知识在两个不同维度的描述符之间转移。
1 前言
多机器人SLAM系统(MR-SLAM系统)相比单机器人系统最主要的限制是:通信带宽的限制。在MR-SLAM系统中,为了整合整个团队的所有轨迹,团队中的每个机器人都需要共享其关键帧数据(包括关键帧姿态和观察到的特征点),以处理机器人间的闭环和全局定位。这种类型的数据交换占用了很高的通信容量,很可能降低实时性能。
一些工程上的解决方案比如降低频率、减少关
......长按二维码访问原文







