文章目录[隐藏]
- 视觉招聘小黑板
- 行业资讯
- Research Areas in Computer Vision: Trends and Challenges: 2024-02-07T12:56:15+00:00
- SynSense收购类脑视觉传感器公司iniVation―新闻频道- 视觉系统设计 2024/2/8 23:51:51
- 得利捷将亮相2024广州国际 工业自动化技术及装备展览会!―新闻频道- 视觉系统设计 2024/2/8 23:46:20
- 低畸变双远心镜头TTL18.5-215-380―产品聚焦频道- 视觉系统设计 2024/2/8 23:49:11
- 棱镜vs单传感器多线相机哪个更适合您的检测系统?―技术与应用频道- 视觉系统设计 2024/2/8 23:44:27
- AI辅助海洋监测系统提供长期深潜监测―技术与应用频道- 视觉系统设计 2024/2/8 23:39:23
- 【论文精读】ViT-Adapter 2024-02-09 13:18
- 【论文精读】 Vision Transformer(ViT) 2024-02-08 11:31
- MedSAM in 3D Slicer: 分割一切医学图像 2024-02-08 16:28
- CV计算机视觉每日开源代码Paper with code速览-2024.2.7 2024-02-08 00:13
- 清华最新!基于Transformers进行端到端图像到LiDAR地图定位 2024-02-09 09:47
- AAAI 2024 | Adobe提出全新上下文提示学习框架CoPL,高效提升下游性能 2024-02-09 11:30
- 老板把“拔掉显卡以提升性能”当真了该咋整...【代码优化之SIMD篇】 2024-02-08 09:38
- ICLR 2024 | Harvard FairSeg:第一个研究分割算法公平性的大型医疗分割数据集 2024-02-08 18:05
- Use Cases for Computer Vision in Healthcare: 2024-02-09T10:50:24.000Z
- First Impressions with Gemini Advanced: 2024-02-08T16:23:02.000Z
- Top Data Labeling Tool & Techniques for Precision Agriculture: 2024-02-09T06:04:17+00:00
- 2024最新!斯坦福李飞飞开年巨作!AI Agent综述!80页!多模态智能体!微软共同出品! 2024-02-07 22:00
视觉招聘小黑板
欲了解详情,请在公众号后台回复:240209
行业资讯
Research Areas in Computer Vision: Trends and Challenges: 2024-02-07T12:56:15+00:00
Basics of Computer Vision
Computer Vision (CV) is a field of artificial intelligence that trains computers to interpret and understand the visual world. Using digital images from cameras and videos, along with deep learning models, computers can accurately identify and classify objects, and then react to what they “see.”
Key Concepts in Computer Vision
Im
......长按二维码访问原文

SynSense收购类脑视觉传感器公司iniVation―新闻频道- 视觉系统设计 2024/2/8 23:51:51
近日,类脑感知及计算头部公司SynSense(时识科技)正式宣布战略收购瑞士类脑视觉传感器公司iniVation。两家公司拥有共同的学术起源和成功的合作基础,本次收购后将优势互补、业务协同,赋能全球工业和消费市场,为行业发展注入源动力。
本次收购被视为类脑领域的重大资源整合及里程碑事件。SynSense响应国家战略性新兴产业发展规划和“自主创新,安全可控”的集成电路发展战略,致力于为客户带来高效率、高性能的突破性类脑智能产品与解决方案。通过对iniVation的收购,SynSense将凭借其独特的前沿技术和多元化的客户市场布局,为工业安防、眼动追踪、消费电子、航空航天和自动驾驶等领域的客户提供前所未有的解决方案,未来有望在全球范围内快速扩张,形成产业规模效应,进一步提升公司盈利能力。
类脑感知及计算作为国内
......长按二维码访问原文

得利捷将亮相2024广州国际 工业自动化技术及装备展览会!―新闻频道- 视觉系统设计 2024/2/8 23:46:20
广州国际智能制造技术与装备展览会(SPS – Smart Production Solutions Guangzhou, 前称SIAF)将于2024年3月4至6日在广州进出口商品交易会展馆隆重举行。新命名重新定义了展会理念,展会将与母展德国智能生产解决方案展览会(SPS)同步,继续深耕华南制造业的同时,也将融入SPS品牌全球网络的行业资源,促进展会平台间的资源及专业知识交流。
汇集智能生产解决方案,赋能华南转型升级,届时,专注在自动数据采集及工厂自动化领域的全球领先供应商——Datalogic得利捷将盛装出席,在此诚邀您莅临我们的展位参观、交流与指导
Datalogic得利捷
展位:Hall 13.2 - D50,诚邀您的莅临!
Datalogic得利捷将携条码识别,激光打标,机器视觉,手持扫码设备,移
......长按二维码访问原文

低畸变双远心镜头TTL18.5-215-380―产品聚焦频道- 视觉系统设计 2024/2/8 23:49:11
双远心镜头对精密尺寸测量有着非常重要的意义,随着机器视觉的不断发展,对双远心镜头的性能要求也越来越高。本公司致力于双远心镜头的研发,着重提高镜头的各项性能参数。
光虎双远心镜头系列拥有高远心度、低畸变率的性能特点,主要应用于精密测量领域及高精度视觉定位。
TTL18.5系列标准双远心镜头标准C接口,最大兼容1.1"(对角线18.5mm)靶面工业相机。
产品特点
>>光学倍率在1.609x-0.059x
>>视野范围在11.5mm-315mm之间,满足对不同视场的需求
>>工作距离在25mm-545mm之间,满足对不同工作距离的需求
>>低于0.05%的畸变,小于0.05°的远心度
>>双侧远心设计,超大景深,高分辨率
>>多层镀膜设计,光透过率高
>>工业级防水
>>高分辨或大景深两种选择
......长按二维码访问原文

棱镜vs单传感器多线相机哪个更适合您的检测系统?―技术与应用频道- 视觉系统设计 2024/2/8 23:44:27
视觉系统的设计师们,在遇到水果、豆类、谷物等常见分拣应用时,常会问我们:“棱镜式相机比三线相机更好吗?为什么呢?”
下面,我们就来分析一下。
用来进行自动检测的分拣设备,它会根据预设的颜色、大小、形状、结构参数准确地对物体进行分拣,判定检测对象合格与否。这是一种能够同时保证质量和最大产量的经济高效的解决方案。
在这样的应用中,检测对象的大小、长度各异,且往往都在连续高速的移动。这种情况下,过去一般会选择线阵扫描相机,它的主要特点是逐行扫描,能较好地发现对象的具体缺陷。
线阵扫描相机大致可分为两类:
单传感器多线相机。常见配置有双线插值彩色、RGB三线线阵、RGB+NIR多光谱四线线阵等。
多传感器棱镜相机。主要配置有3通道(R-G-B)和4通道(R-G-B-NIR)。线阵传感器安装在棱镜块上,光线分
......长按二维码访问原文

AI辅助海洋监测系统提供长期深潜监测―技术与应用频道- 视觉系统设计 2024/2/8 23:39:23
图1:MarineSitu公司开发了一种AI辅助相机系统,可以长时间监测水下环境。
MarineSitu是美国华盛顿州的一家新兴公司,公司于2017年作为华盛顿大学的子公司而成立。MarineSitu公司的创始人兼总裁James Joslin在华盛顿大学完成了研究生学业,在成立MarineSitu之前,他在华盛顿大学做了几年的研究工程师。在美国能源部的资助下,MarineSitu公司开始构建用于监测海洋生物和水下环境的集成式机器视觉系统,主要用于监测波浪能转换器和水下涡轮机等设备周围的条件;波浪能转换器和水下涡轮机被用于相对较新的可再生海洋能源行业,该行业被称为“蓝色经济”,通常指海洋资源的可持续经济发展。
将相机用于各种水下视觉系统应用,并不是什么新鲜事儿。然而,Joslin指出,大多数为水下应用
......长按二维码访问原文

【论文精读】ViT-Adapter 2024-02-09 13:18
摘要
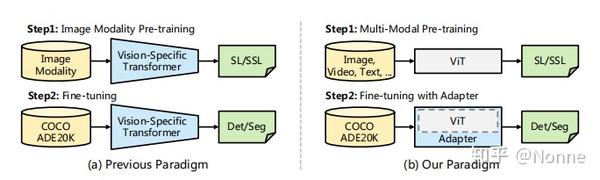
视觉transformer类的模型可以分为普通ViT和视觉transformer变体两类。后者通常使用局部空间操作将特定于视觉的归纳偏差引入到其架构中,故而可以产生更好的结果(如Swin Transformer)。但普通的ViT可以使用包括图像,视频和文本的大量多模态数据进行预训练,这鼓励模型学习丰富的语义表示,但与特定于视觉的transformer变体相比,普通ViT在密集预测方面有决定性的缺陷。故有如下改进:
本文探索了一种新的范式,不同于以往的预训练+微调(上图a),本文开发了基于普通ViT的适配器(上图b),以缩小普通ViT和特定视觉transformer变体之间的性能差距
设计了一个空间先验模块和两个特征交互操作,在不重新设计ViT架构的情况下注入图像先验,以补充普通ViT缺失的图像局部
......长按二维码访问原文

【论文精读】 Vision Transformer(ViT) 2024-02-08 11:31
摘要
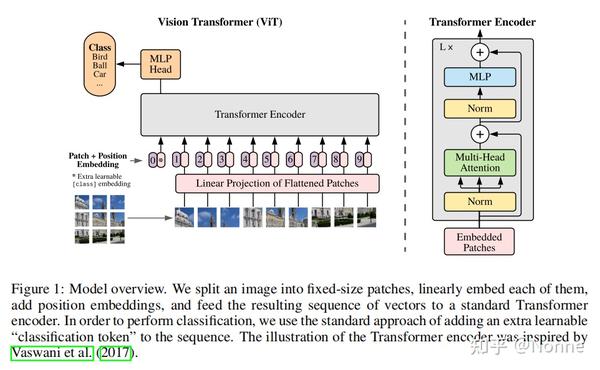
验证了当拥有足够多的数据进行预训练的时候,ViT的表现就会超过CNN,突破transformer缺少归纳偏置的限制,可以在下游任务中获得较好的迁移效果。
架构
如上图,给定图像 x \in R^{H \times W \times C} 分割为2D patch序列 x_p \in R^{N \times (P^2 \cdot C)} ,其中 (H, W) 是原 始图像的分辨率, C 是通道的数量, (P, P) 为每个图像patch的分辨率, N = HW/P^2 是patch的数量,这作为Transformer的输入序列长度。后通过patch embedding将patch展平并通过线性投影映射到D维度E \in R^{D \times (P^2 \cdot C)} 。
类似于B
......长按二维码访问原文

MedSAM in 3D Slicer: 分割一切医学图像 2024-02-08 16:28
MedSAM-Lite 3D Slicer简介
这是 MedSAM 的官方 3D Slicer 插件存储库,可用于在医学图像中分割任何物体。
什么是MedSAM:点击查看这篇文章
查看分割演示 添加视频
文中涉及到的视频前往VX查看
安装
您可以在此处观看安装步骤的视频教程(中英文): 【添加安装视频】
安装步骤
从其官方网站安装3D Slicer 网站链接[1]。我们的插件兼容性已经通过 3D Slicer >= 5.4.0 进行了测试。 从 MedSAMSlicer 发行页[2] 下载特定版本的插件并提取到所需位置。 在 Slicer 应用程序中,选择顶部工具栏中的 Welcome to Slicer 下拉菜单,然后转到 Developer Tools > Extension Wizard
......长按二维码访问原文

CV计算机视觉每日开源代码Paper with code速览-2024.2.7 2024-02-08 00:13
精华置顶
墙裂推荐!小白如何1个月系统学习CV核心知识:链接
点击@CV计算机视觉,关注更多CV干货
论文已打包,点击进入—>下载界面
点击加入—>CV计算机视觉交流群
1.【基础网络架构:Transformer】LF-ViT: Reducing Spatial Redundancy in Vision Transformer for Efficient Image Recognition
2.【视频分割】(TMLR2024)We're Not Using Videos Effectively: An Updated Domain Adaptive Video Segmentation Baseline
3.【域自适应】Continuous Unsupervised Domain Adaptati
......长按二维码访问原文

清华最新!基于Transformers进行端到端图像到LiDAR地图定位 2024-02-09 09:47
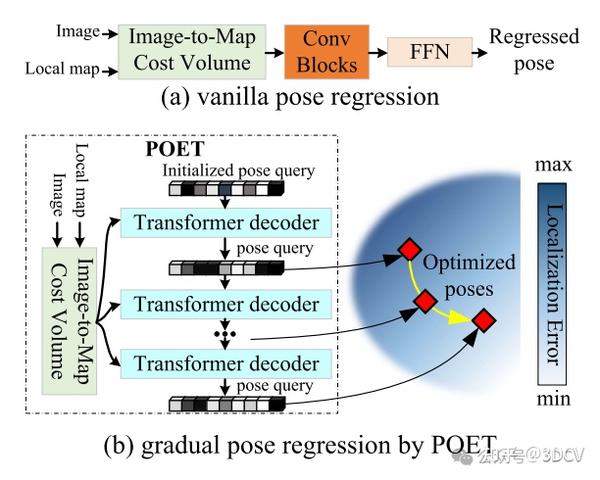
在这项研究中,我们基于学习的图像到激光雷达地图定位方法来实现低成本和高精度的车辆定位。在现有的工作中,姿势相关的信息或约束被认为包含在跨模态匹配信息中。他们通过一个简单的姿态回归模块直接根据匹配信息估计姿态,该模块由堆叠的卷积层和全连接层组成,如图1(a)所示,无法充分利用匹配信息,限制了姿态估计的性能。为此,我们提出了一种基于Transformer的神经网络,据我们所知,它应该是第一个将姿势隐式表示为高维特征向量的提议,在本工作中称为姿势查询。特别是,我们设计了一种新颖的POET模块,其中可以通过从跨模态特征之间的成本量中检索相关匹配信息来不断优化姿势查询,如图1 (b)所示。受益于所提出的POET模块,我们的网络在集成到迭代定位系统中时可以显着提高定位精度。
移步公众号「3DCV」第一时间获取工业3D视觉
......长按二维码访问原文

AAAI 2024 | Adobe提出全新上下文提示学习框架CoPL,高效提升下游性能 2024-02-09 11:30
公众号:将门创投(thejiangmen)
作者:seven_
论文题目:CoPL: Contextual Prompt Learning for Vision-Language Understanding
论文链接: https:// arxiv.org/abs/2307.0091 0
提示学习(Prompt Learning)在近几年的快速发展,激活了以Transformer为基础的大型语言模型(LLM)的性能涌现。这一技术范式迅速在多模态学习等领域进行迁移,例如在CLIP跨模态对齐模型中加入可学习的Prompt,就可以在多种下游任务展现出通用性能,且具有一定的泛化能力。但这种简单的提示方法仍具有局限性,主要分为两个方面,其一是使用全局视觉特征作为提示输入可能会导致模型缺乏关注图像中前景对象的注意力
......长按二维码访问原文

老板把“拔掉显卡以提升性能”当真了该咋整...【代码优化之SIMD篇】 2024-02-08 09:38

摘要:本文章会介绍几种常见代码加速手段,并以加速双线性插值算法为例,演示如何使用SSE指令集加速算法。
经过上一篇文章的介绍,想必各位 \enclose{horizontalstrike}{用不起显卡} 对CPU一心一意的程序员们已经开始期待该如何不花一分钱,用SIMD就能给代码加速了。
但在那之前,咱还得先把基本概念给过一下。
一、啥是SIMD
字面解释SIMD(Single Instruction Multiple Data,单指令多数据)。
不懂啥意思吧,那我们想象这么一个场景:小学生张三放寒假,就差一天开学了,突然发现寒假作业还有100道加法题没做。
张三【一个人】吭哧吭哧算,每次还只能做【一道题】,这叫【单】指令【单】数据,SISD。
像不像组会前的你
但这时候张三想起来:我有一百个哥
......长按二维码访问原文

ICLR 2024 | Harvard FairSeg:第一个研究分割算法公平性的大型医疗分割数据集 2024-02-08 18:05
公众号:将门创投(thejiangmen)
作者:Yu Tian
近年来,人工智能模型的公平性问题受到了越来越多的关注,尤其是在医学领域,因为医学模型的公平性对人们的健康和生命至关重要。高质量的医学公平性数据集对促进公平学习研究非常必要。现有的医学公平性数据集都是针对分类任务的,而没有可用于医学分割的公平性数据集,但是医学分割与分类一样都是非常重要的医学AI任务,在某些场景分割甚至优于分类, 因为它能够提供待临床医生评估的器官异常的详细空间信息。
在本文中,我们提出了第一个用于医学分割的公平性数据集,名为Harvard-FairSeg,包含10,000个患者样本。此外,我们提出了一种公平的误差界限缩放方法,通过使用最新的Segment Anything Model(SAM),以每个身份组的上界误差为基础重
......长按二维码访问原文

Use Cases for Computer Vision in Healthcare: 2024-02-09T10:50:24.000Z
The healthcare industry is quick to adopt technologies that show promise to improve patient care. The fourth industrial revolution has brought massive development within the space, turning hospitals into data-rich facilities looking for innovative and secure technical solutions . While computer vision technology has long held promise in healthcare, recent ad
......长按二维码访问原文

First Impressions with Gemini Advanced: 2024-02-08T16:23:02.000Z

Introduced in December 2023, Gemini is a series of multimodal models developed by Google and Google’s DeepMind research lab. On release, the Roboflow team evaluated Gemini across a series of qualitative tests that we have conducted across a range of other multimodal models. We found Gemini performed well in some areas, but not others.
On February 8th, 2024,
......长按二维码访问原文

Top Data Labeling Tool & Techniques for Precision Agriculture: 2024-02-09T06:04:17+00:00
Precision agriculture, powered by technologies like machine learning and computer vision, is changing the way we do farming. The global AI market size in agriculture was USD 1.37 billion in 2022, with projections indicating it will exceed approximately USD 11.13 billion by 2032. A 23.3% CAGR is driven by AI technology supporting data collection, structuring,
......长按二维码访问原文

2024最新!斯坦福李飞飞开年巨作!AI Agent综述!80页!多模态智能体!微软共同出品! 2024-02-07 22:00

哈喽,我是@Sophia,这是李飞飞团队2024年开年巨作!80页,内容太棒了!!!
https://arxiv.org/pdf/2401.03568.pdf
研究者们定义AI Agent作为一类能够感知视觉刺激、语言输入和其他以环境为基础的数据,并能生成具有无尽代理体的有意义的实体行动的交互系统。
多模态智能体AI(Multimodal Agent AI: MAA)是一类基于理解多模态感知输入在特定环境中生成有效行为的系统。
论文目录,一共80页!
随着大型语言模型(LLMs)和视觉语言模型(VLMs)的出现,许多不同领域的MAA系统已经被开发出来,这些领域包括基础研究和应用。虽然这些研究领域通过与各自领域的传统技术(例如,视觉问题回答和视觉语言导航)整合,迅速发展,但它们都关注如数据收集、基准测试
......长按二维码访问原文






