文章目录[隐藏]
- 行业资讯
- 您的 2024 年 6 大计算机视觉问题指南:2024-02-14T13:41:54+00:00
- 新药时代:人工智能如何赋能和颠覆蛋白质、生物制剂、治疗剂和材料的发现:2024-02-15T09:22:16-0500
- CVPR 2022论文分享:《Modeling Indirect Illumination for Inverse Rendering》 2024-02-14 23:30
- 【论文精读】BEiT 2024-02-15 16:17
- 总结 | ORB_SLAM2源码中字典使用细节 2024-02-15 09:52
- [分享][每日更新][2024.02.15][CV_arxiv_papers] 2024-02-16 12:25
- 超全的3D视觉数据集汇总 2024-02-15 09:54
- 聊聊三维重建-双目立体视觉原理 2024-02-15 09:50
- 最强汇总整理 | 3D视觉系统化学习路线 2024-02-15 09:47
- ICCV 2023 | 密集群体分析 | Point-Query Quadtree for Crowd Counting, Localization, and More 2024-02-16 15:56
- 在机器学习中处理缺失值的 4 大技术:2024-02-15T17:00:44.000Z
行业资讯
您的 2024 年 6 大计算机视觉问题指南:2024-02-14T13:41:54+00:00

介绍
计算机视觉是人工智能的最新子集,近年来需求激增。这要归功于我们今天拥有的令人难以置信的计算能力和大量的数据可用性。我们都在日常生活中以某种形式使用过计算机视觉应用程序,比如我们移动设备上的面部解锁
...... 长按二维码访问原文

新药时代:人工智能如何赋能和颠覆蛋白质、生物制剂、治疗剂和材料的发现:2024-02-15T09:22:16-0500
我们很高兴地宣布 LDV Capital 的 Evan Nisselson 和 Generate Biomedicines 的联合创始人兼首席战略和创新官 Molly Gibson 博士之间的炉边谈话,Generate Biomedicines 是一家存在于生物学、机器学习和生物工程交叉领域的新型治疗公司。该公司致力于彻底改变毒品迪斯科
...... 长按二维码访问原文

CVPR 2022论文分享:《Modeling Indirect Illumination for Inverse Rendering》 2024-02-14 23:30

设置
根据在未知静态照明下捕获的多视图 RGB 图像来估计对象的空间变化双向反射分布函数(Spatially Varying Bidirectional Reflectance Distribution Function, SVBRDF)。
我们的方法能够重建具有无约束反射的高质量间接光,并且不需要已知的照明条件。
问题
先前的做法:最近的作品探索了自然照明下灵活的捕捉设置。 这些方法通常将几何和空间变化的 BRDF (SVBRDF) 表示为基于坐标的神经网络,并通过优化将渲染图像与输入图像进行比较的重新渲染损失来恢复它们。
存在的问题:然而,在自然照明下拍摄通常会表现出复杂的效果,例如柔和的阴影和相互反射。 在优化 SVBRDF 和灯光参数时模拟这些效果很困难,因为它需要在基于物理的渲染中进行昂贵的
......长按二维码访问原文

【论文精读】BEiT 2024-02-15 16:17
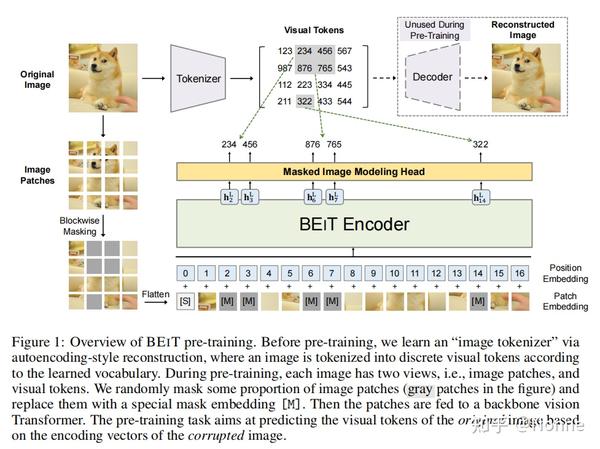
摘要
提出一种掩码图像建模任务,以自监督方式预训练视觉transformer。
对BEIT进行了预训练,并对下游任务进行微调实验,如图像分类和语义分割。
发现自监督BEIT的自注意力机制可以学会区分语义区域和对象边界。
框架
给定输入图像 x ,BEiT将其编码为上下文向量表示。如上图,BEiT通过自监督学习掩码图像建模 (MIM) 任务进行预训练,恢复编码向量的masked image patches。对于下游任务 (如图像分类和语义分割),在经预训练的BEiT上添加任务层,并对特定数据集上的参数进行有监督微调。
图像表示
本方法中,图像有两种表示视图,即images patches和visual tokens。两者分别在预训练任务中作为输入和输出表示。
Images patch
输
......长按二维码访问原文

总结 | ORB_SLAM2源码中字典使用细节 2024-02-15 09:52
前段时间,主要对ORB-SLAM2中字典的训练与使用进行了些研究,关于字典的训练之前也写过一篇文章:VSLAM|回环检测之词袋字典如何生成?,简单讲解了如何使用我们自己的数据集进行训练字典,ORB-SLAM作者提供的是字典层数为6层,当然我们也可以训练更低层数的字典,以减小程序所占内存。
本篇文章,主要就单目ORB-SLAM2源码中使用字典的一些函数进行简单剖析。当然,笔者也刚入行VSLAM时间不长,如有不到之处,还请多批评指正。
备注:对于下述的代码注释,主要借鉴了泡泡机器人给出的中文注释
粗略统计了下,单目ORB-SLAM2中主要有四个地方涉及到了字典,以下介绍其函数细节。
移步公众号「3DCV」第一时间获取工业3D视觉、自动驾驶、SLAM、三维重建、最新最前沿论文和科技动态。
推荐阅读
1、重
......长按二维码访问原文

[分享][每日更新][2024.02.15][CV_arxiv_papers] 2024-02-16 12:25

Publish Date Title Title_CN Authors PDF Code
2024-02-15 MM-Point: Multi-View Information-Enhanced Multi-Modal Self-Supervised 3D Point Cloud Understanding MM-Point:多视图信息增强的多模态自监督 3D 点云理解 Hai-Tao Yu, Mofei Song http:// arxiv.org/pdf/2402.1000 2v1 null
2024-02-15 LLMs as Bridges: Reformulating Grounded Multimodal Named Entity Recognition 法学硕士作为桥梁:重新制定扎根多模态命名
......长按二维码访问原文

超全的3D视觉数据集汇总 2024-02-15 09:54

KITTI数据集由德国卡尔斯鲁厄理工学院和丰田美国技术研究院联合创办,是目前国际上最大的自动驾驶场景下的计算机视觉算法评测数据集。该数据集用于评测立体图像(stereo),光流(optical flow),视觉测距(visual odometry),3D物体检测(object detection)和3D跟踪(tracking)、语义分割等计算机视觉技术在车载环境下的性能。KITTI包含市区、乡村和高速公路等场景采集的真实图像数据,每张图像中最多达15辆车和30个行人,还有各种程度的遮挡与截断。整个数据集由389对立体图像和光流图,39.2 km视觉测距序列以及超过200k 3D标注物体的图像组成。
移步公众号「3DCV」第一时间获取工业3D视觉、自动驾驶、SLAM、三维重建、最新最前沿论文和科技动态。
推荐
......长按二维码访问原文

聊聊三维重建-双目立体视觉原理 2024-02-15 09:50
三维重建是个跨多学科的应用领域,围绕不同的尺度大小、不同速度要求、不同精度要求、不同硬件成本等要求发展出了各种各样的技术方案。在这个应用领域,充分体现了,没有最好的设备,只有最合适的方案。在本系列文章中,我尝试解释接触过的不同技术方案,如有错误之处,敬请斧正。
移步公众号「3DCV」第一时间获取工业3D视觉、自动驾驶、SLAM、三维重建、最新最前沿论文和科技动态。
推荐阅读
1、重磅发布!3D视觉系统学习路线总结!
2、基于NeRF/Gaussian的全新SLAM算法
3、面向自动驾驶的BEV与Occupancy网络全景解析与实战
......长按二维码访问原文

最强汇总整理 | 3D视觉系统化学习路线 2024-02-15 09:47
我们生活在三维空间中,如何智能地感知和探索外部环境一直是个热点难题。2D视觉技术借助强大的计算机视觉和深度学习算法取得了超越人类认知的成就,而3D视觉则因为算法建模和环境依赖等问题,一直处于正在研究的前沿。近年来,3D视觉技术快速发展,并开始结合深度学习算法,在智能制造、自动驾驶、AR/VR、SLAM、无人机、三维重建、人脸识别等领域取得了优异的效果。
移步公众号「3DCV」第一时间获取工业3D视觉、自动驾驶、SLAM、三维重建、最新最前沿论文和科技动态。
推荐阅读
1、重磅发布!3D视觉系统学习路线总结!
2、基于NeRF/Gaussian的全新SLAM算法
3、面向自动驾驶的BEV与Occupancy网络全景解析与实战
......长按二维码访问原文

ICCV 2023 | 密集群体分析 | Point-Query Quadtree for Crowd Counting, Localization, and More 2024-02-16 15:56
注:文章链接在本文末尾
摘要
我们表明,人群计数可以看作是一个可分解的点查询过程。这种公式允许将任意点作为输入,并共同推理这些点是否拥挤以及它们的位置。但是,查询处理在必要查询点的数量上引发了一个潜在的问题。太少意味着低估;
......长按二维码访问原文

在机器学习中处理缺失值的 4 大技术:2024-02-15T17:00:44.000Z
让这个项目栩栩如生 在 Paperspace 上运行
数据正日益成为互联网上每个人的宝贵财富,将信息转化为数据对于各种业务问题变得越来越重要。虽然数据偶尔会从 Kaggle.com 等网站和各种来源通过网站上的网络抓取获得,但这种数据会越来越频繁
...... 长按二维码访问原文






