文章目录[隐藏]
- 视觉招聘小黑板
- 行业资讯
- 大模型加持,凌云光AI+Vision助力多行业创新发展--机器视觉网 2024-03-26 11:35:55
- 巨哥科技推出多光谱红外相机,快速识别材料属性--机器视觉网 2024-03-27 16:41:30
- 友思特与Solectrix正式建立合作伙伴关系--机器视觉网 2024-03-27 15:43:45
- 中集天达与劳易测签署战略合作协议--机器视觉网 2024-03-27 13:30:06
- 创科视觉引领革新,助力汽车雷达组装与全检无缝对接--机器视觉网 2024-03-26 14:03:16
- 揭秘中科微至RGB-D智能立体相机视觉识别技术--机器视觉网 2024-03-26 13:47:16
- 三维扫描技术赋能鞋业生态,推动鞋企按下数字化升级快进键--机器视觉网 2024-03-26 13:34:18
- 拓朗工控助力充电站安全监控管理解决方案--机器视觉网 2024-03-26 13:28:44
- 友思特描绘未知:数据缺乏场景的缺陷检测方案--机器视觉网 2024-03-26 12:03:59
- 斯睿特,前后风挡玻璃引导组装视觉系统方案--机器视觉网 2024-03-26 11:53:09
- 基于光谱共焦技术的曲面玻璃检测--机器视觉网 2024-03-27 17:50:21
- 深视智能高速相机助力锂电行业高质量发展--机器视觉网 2024-03-27 17:37:40
- 宸曜科技助力AI技术绘制地图--机器视觉网 2024-03-27 17:25:39
- AI机器视觉大模型在磁片色选机上的实践应用--机器视觉网 2024-03-27 16:56:24
- LMI Technologies 3D视觉助力铁路检测,为您的安全保驾护航--机器视觉网 2024-03-27 15:25:46
- 沃德普计算成像助力2.5D缺陷检测--机器视觉网 2024-03-27 14:39:08
- 埃科光电将携新品亮相成都机器视觉创新论坛―新闻频道- 视觉系统设计 2024/3/26 22:57:26
- 凌云光AI+Vision助力多行业创新发展―新闻频道- 视觉系统设计 2024/3/26 22:50:27
- 所罗门联合安提国际亮相慕尼黑上海电子生产设备展―新闻频道- 视觉系统设计 2024/3/26 22:46:00
- Sherlock8 AI 驱动的视觉检测可以发现极小的纳米级 PCB 缺陷―技术与应用频道- 视觉系统设计 2024/3/26 22:39:17
- 堡盟获奖产品连连看―新闻频道- 视觉系统设计 2024/3/27 20:08:59
- 3D视觉引导拆码垛系统方案全面升级―技术与应用频道- 视觉系统设计 2024/3/27 20:18:33
- 汽车常见检测案例中的光源应用参考―技术与应用频道- 视觉系统设计 2024/3/27 20:27:05
- 检测图像中的孤立点 2024-03-26 09:56
- PYRA:超轻量级ViT适应&推理高效微调模块 2024-03-26 16:47
- MMLU Clinical Topics 数据集介绍 2024-03-26 08:42
- 【论文和源码解读】Scaling on Scales:When Do We Not Need Larger Vision Models? 2024-03-26 22:53
- 阅读笔记:anomalyCLIP零样本缺陷检测 2024-03-27 09:18
- CVPR 2024 | 涨点神器!谷歌提出:小样本图像分类的冻结特征增强 2024-03-27 12:15
- 现代化工业生产线中的机器视觉检测AI质检解决方案 2024-03-27 17:34
- 基于YOLOv8/v5和ByteTrack的多目标检测计数与跟踪系统(深度学习代码+UI界面实现+训练数据集) 2024-03-27 12:24
- 艾科瑞特科技:计算机视觉-通用领域2D全身关键点检测模型 2024-03-26 22:00
- 艾科瑞特科技:计算机视觉-人体美型 2024-03-26 22:05
- 艾科瑞特科技:计算机视觉-手部检测模型 2024-03-26 22:02
- CVPR 2024 | 北大&谷歌提出DrivingGaussian:环视动态自动驾驶场景重建仿真 2024-03-26 17:22
- [分享][每日更新][2024.03.24][CV_arxiv_papers] 2024-03-26 11:41
- 详细解读associative embedding“关联嵌入”(以HigherHRNet为例) 2024-03-26 10:09
- 精品推荐 |《工业视觉系统编程及基础应用》职业教育教材正式出版 2024-03-26 17:32
- 艾科瑞特科技:计算机视觉-人体关键点检测模型-15点人体关键点 2024-03-26 22:07
- 新的SDK加速人工智能研究、计算机视觉、数据科学等 2024-03-26 10:36
- CVPR 2024——PatchFusion:基于Tile的高分辨率单目度量深度估计网络 2024-03-26 13:23
- 艾科瑞特科技:计算机视觉-人像增强修复-高分辨率人脸 2024-03-26 22:03
- 人员区域入侵检测算法在边缘设备的应用与表现 2024-03-27 10:34
- Introducing Moondream2: A Tiny Vision-Language Model: 2024-03-27T12:05:44+00:00
- Vikas Verma: 14.0.0
- Guide on 3D Medical Image Segmentation with Monai & UNET: 2024-03-27T11:06:57+00:00
- In Cabin Monitoring: Best Practices For Data Annotation and Workflow Management: 2024-03-27T08:12:08+00:00
- Fine-Tuning YOLOv9 Models on Custom Dataset: 2024-03-26T13:00:00+00:00
视觉招聘小黑板
欲了解详情,请在公众号后台回复:240327
行业资讯
大模型加持,凌云光AI+Vision助力多行业创新发展--机器视觉网 2024-03-26 11:35:55
2024-03-26 11:35:55 来源: 中国机器视觉网
前不久,凌云光·元客视界AI数智人已入驻京东京麦平台。作为首批入驻的三家直播数字人方案提供商,凌云光也是首个应用完全国产大模型GLM驱动的解决方案提供商 。截至目前,凌云光已累计为平台的117家品牌商提供了数字人服务。
大模型+数字人,直播又现新质生产力
相较于传统真人直播,凌云光·元客视界AI数智人具有真人音色复刻能力,且无需硬件设备即可实现云端部署,快速开播;同时,基于GLM-4大模型可在直播过程做到实时互动、“真人化”回复,每天成本不到百元;24小时不间断直播,有效弥补真人带货直播“空档”。数字人也提供了包月、包年的使用方案,方便广大品牌商进行测试和使用。
“在24年春节大促期间,头部家电客户采用凌云光·元客视界AI数智人在天猫旗
......长按二维码访问原文

巨哥科技推出多光谱红外相机,快速识别材料属性--机器视觉网 2024-03-27 16:41:30
2024-03-27 16:41:30 来源: 中国机器视觉网
在物料分选、材料分类、异物检测等应用领域,普通的RGB相机往往难以满足需求。多光谱红外相机探测目标对不同波段的光的吸收,形成代表材料属性的图像,提升分析的效率和准确性。巨哥科技最新推出的多光谱相机光谱响应范围900至1700nm,有效覆盖短波红外范围,适用于广泛的材料光谱分析。
该相机具有7个波长通道,可提供丰富的光谱信息。一次多光谱成像时间小于0.1秒,>10Hz的多光谱成像帧频确保了对动态过程的实时监控。
通过收集不同波长下的光谱数据,该相机能够创建详细的材料光谱特征库,结合先进的数据处理算法构建高精度光谱模型,可实现自动化生产线上的快速材料分拣、质量控制和异物检测等任务。巨哥科技丰富的光谱分析和建模经验可以应对需要精确材料鉴别的复杂应用
......长按二维码访问原文

友思特与Solectrix正式建立合作伙伴关系--机器视觉网 2024-03-27 15:43:45
2024-03-27 15:43:45 来源: 中国机器视觉网
友思特与国际领先的嵌入式方案技术公司Solectrix正式建立了合作伙伴关系。这一里程碑式的合作旨在结合双方的优势,为全球客户提供更为出色的视觉采集卡解决方案。通过这次合作,我们将共同努力推动行业创新。Solectrix的先进技术将与友思特的市场洞察和专业知识相结合,为不同行业的客户带来定制化、一站式的视觉解决方案。我们坚信,这次合作将大大提升双方的技术研发能力和市场竞争力。
关于Solectrix
Solectrix作为科技领域创新者和独立的全方位服务提供商,基于客户需求开发和制造精密且尖端的嵌入式电子解决方案,并提供内部开发的基础电子元件和系统。
Solectrix以140名团队成员和高精尖的技术专长,为客户提供从概念到硬件、软件和
......长按二维码访问原文

中集天达与劳易测签署战略合作协议--机器视觉网 2024-03-27 13:30:06
2024-03-27 13:30:06 来源: 中国机器视觉网
3月21日,在对劳易测德国总部进行参观和交流期间,中集天达与劳易测进行了战略合作协议签署。中集天达旗下包括深圳中集天达空港设备有限公司、深圳中集天达物流系统工程有限公司、中集德立物流系统(苏州)有限公司、德利九州物流自动化系统(北京)有限公司、昆山中集物流自动化设备有限公司、深圳中集智能停车有限公司等多家企业,与劳易测达成了一份为期三年的战略合作协议。
这份战略合作协议的签署标志着双方将在产品技术研发、行业解决方案应用以及新的业务拓展等多个维度进行全面深化的合作,旨在通过共享优势资源,实现互利共赢的局面。未来,这一战略合作关系还将进一步扩展至德利新加坡和德利美国等下属公司,共同致力于推动全球物流行业的智能化升级和发展。
当天,作为中集天达物流
......长按二维码访问原文

创科视觉引领革新,助力汽车雷达组装与全检无缝对接--机器视觉网 2024-03-26 14:03:16
2024-03-26 14:03:16 来源: 中国机器视觉网
相对于传统的汽车雷达组装质量检测主要依赖人工目检和简单的测试设备不同,机器视觉技术以其高效、精准、非接触式的特点,正逐渐成为汽车雷达组装质量检测的新选择。通过引入机器视觉系统,我们可以实现对雷达组装过程中多个关键环节的自动化检测,包括但不限于:零件有无、组件定位与识别、PCB针脚、外观缺陷检测、尺寸测量等。
创科视觉雷达项目组装全检测试机
外胆有无/ 探芯面检测
检测项目:1.外胆有无检测,2.探芯面缺陷检测;3.探芯颜色。
检测标准:1.具备RGB识别功能;2.划痕>2mmx0.2mm,颗粒>0.2mm;3.误判率≤0.1%,MSA<10%。 检测配置:创科智能机器视觉软件CKVisionBuilder+2D视觉系统+汽车雷达全检测试 ......长按二维码访问原文

揭秘中科微至RGB-D智能立体相机视觉识别技术--机器视觉网 2024-03-26 13:47:16
2024-03-26 13:47:16 来源: 中国机器视觉网
在电商飞速发展的时代,物流行业面临着前所未有的挑战。中科微至推出RGB-D智能立体相机,赋能物流自动化装配线,提升处理能力。
技术原理
中科微至的RGB-D智能立体相机,结合RGB和深度数据,能够精准识别和定位目标的三维空间位置。采用智能深度学习算法,快速处理图像并准确识别目标。获取目标的深度信息后,转化为三维点云数据,并去除噪声,更精确地表达目标的三维结构。最后,结合2D图像分割和3D点云信息,实现目标在三维空间的精确定位和跟踪。
产品优势
在实现目标的3D识别和定位方面,该相机具备显著的优势:
高效性:结合2D感知和立体视觉技术,快速、准确地识别和定位目标实时获取目标深度信息确保精确定位。鲁棒性:不仅能识别颜色和形状,还能获取深度信
......长按二维码访问原文

三维扫描技术赋能鞋业生态,推动鞋企按下数字化升级快进键--机器视觉网 2024-03-26 13:34:18
2024-03-26 13:34:18 来源: 中国机器视觉网
传统制鞋加工工序繁杂,周期长成本高,产品更新乏力,难以快速响应市场个性化、多元化的需求,各大鞋企纷纷寻求转型之道。三维扫描技术的引入则为传统制鞋业注入了创新活力,不仅可实现鞋业设计、制造降本提效,亦可推动其生产链从单一加工制造向研发、设计、营销延伸,全方位、全链条为鞋业数字化转型与发展赋能。
传统鞋样设计、开版之痛
一款新鞋从设计构思到作出成品中间约有120道工序,一般大厂品牌在新品正式大规模生产之前,光是设计开发的流程周期就需要约8-12个月。在漫长的设计流程中,楦师会先根据大数据,或者已有产品和经验来反复修改打磨设计和制作楦头。随后,开版师则在楦师交付的楦头上贴美纹纸,绘制帮面式样,获取帮面样板。后道工序则会基于此样板来进行皮料的裁剪、缝
......长按二维码访问原文

拓朗工控助力充电站安全监控管理解决方案--机器视觉网 2024-03-26 13:28:44
2024-03-26 13:28:44 来源: 中国机器视觉网
背景
近年来,随着电动汽车逐渐成为燃油汽车的有力替代品,消费者对电动汽车的认识影响力迅速变化,市场占有率也迅速攀升,成为新的汽车消费主流。随着电动汽车的普及,新能源汽车充电也成为每个车主的日常,充电桩也逐渐成为了城市公共设施的一部分。然而充电桩的安全问题一直是大家关注的焦点,特别是在一些公共区域和停车场等场所,充电桩的安全问题更加突出。因此,如何保障充电桩的安全成为了一个紧迫的问题。
目前遇到的问题
1、充电桩铺设数量庞大、安装地点分散,环境严苛、管理不易,设备维护成本往往十分高昂。2、充电桩行业协议并未统一规范,各个厂家充电桩设备所用协议大有不同, 对于监控中心的管理工作造成了一定的难度,不便数据统计。3、充电站多为户外环境,对设备性能要
......长按二维码访问原文

友思特描绘未知:数据缺乏场景的缺陷检测方案--机器视觉网 2024-03-26 12:03:59
2024-03-26 12:03:59 来源: 中国机器视觉网
导读
深度学习模型帮助工业生产实现更加精确的缺陷检测,但其准确性可能受制于数据样本的数量。友思特 Neuro-T 视觉平台克服了数据缺乏状况的困难,通过零代码设置GAN模型和无监督学习模型,轻松实现缺陷图像的标注、绘制和导出。
工业应用中存在较多的缺陷检测需求。针对缺陷检测需求,常见的解决方案有两种:基于目标正常图像数据的模板匹配;训练深度学习模型检测目标缺陷。
其中,第2种方式具有更强的鲁棒性和泛化能力。然而由于深度学习模型的准确率跟数据量的大小挂钩,深度学习缺陷检测方案面临着缺乏足够的缺陷样本进行模型训练的问题。
友思特推出 Neuro-T 机器视觉软件平台,通过GAN和无监督学习模型两种不同的手段,以两种不同的方式形成数据缺乏场景的
......长按二维码访问原文

斯睿特,前后风挡玻璃引导组装视觉系统方案--机器视觉网 2024-03-26 11:53:09
2024-03-26 11:53:09 来源: 中国机器视觉网
一、方案简介
斯睿特旗下的前后风挡玻璃引导组装方案通过3D激光工业视觉技术,实现前后风挡玻璃自动安装。其核心技术包括3D激光引导机器人技术以及空间3维精准定位组装。
二、方案工作原理简述
三、方案视觉系统阐述
(一)视觉系统构成
(二)视觉原理介绍
前后风挡安装时,车身来料有偏差,需利用视觉引导机器人对车身进行3D定位, 通过视觉拍照计算,输出∆x,∆y, ∆z, ∆θx, ∆θy,∆θz六个数据坐标到机械手,补偿位置偏移,实现精准安装前后风挡。
四、方案硬件优势
(一)硬件特点
1. 把相机、镜头集中于一起,形成一体式检测头。2. CMOS传感器,可提供高度可靠的测量结果,可根据不同客户需求搭配不同精度相机和镜头,提供
......长按二维码访问原文

基于光谱共焦技术的曲面玻璃检测--机器视觉网 2024-03-27 17:50:21
2024-03-27 17:50:21 来源: 中国机器视觉网
自1973年4月,马丁·库帕发明世界上第一台商用手机以来(当时价格为3995美元),历经50年发展与变迁,手机屏幕规格顺应科技发展水平进行技术升级迭代:单色LCD屏(1983)-单色触摸屏(1994)-四色彩屏(1997)-全彩屏(2001)-多点触空电容屏(2007)-AMOLED屏(2008)-全面屏(2014)-曲面屏(2015)-异形屏(2017)-折叠屏(2019)。
而据最新爆料,华为P70系列将会在三月份前后发布,新产品采用1.5K等深微四曲屏,6.7英寸左右常规尺寸窄屏幕。虽然产品实体图还未曝光,但我们可以看出,手机厂商们在对手机曲面屏进行以消费者体验为优先的创新研发。
智能手机作为人类使用频率最高的工具,已成为消费者在日常生
......长按二维码访问原文

深视智能高速相机助力锂电行业高质量发展--机器视觉网 2024-03-27 17:37:40
2024-03-27 17:37:40 来源: 中国机器视觉网
随着新能源技术的飞速发展,锂电池也凭借长循环寿命、高电极电压等优良性能,成为了手机、笔记本、电动汽车等现代化产品理想的动力来源,广泛应用于工业社会的各个领域。
为满足市场对锂电池产品质量和数量的要求,企业不断加大研发和产能的投入,以提升锂电池的产品性能和生产效率,而高速相机的快速发展让锂电行业的产品优化和工序改进带来更多创新。本期内容,深Sir就为大家分享深视智能高速相机在锂电行业丰富的解决方案。
电芯卷绕观测
应用场景
电芯卷绕设备在卷绕工序中容易出现多执行机构工作不协同、执行精度不达标等情况,导致隔膜断裂、隔膜厚度不达标等问题,无法通过目测或工业相机拍摄来捕捉高速卷绕的机械动作,分析故障原因。
解决方案
1.采用深视智能高速相机S
......长按二维码访问原文

宸曜科技助力AI技术绘制地图--机器视觉网 2024-03-27 17:25:39
2024-03-27 17:25:39 来源: 中国机器视觉网
我们的客户利用地理空间成像技术及AI和特征提取技术,提供拥有出色细节和有建设性洞察的高清2D和3D矢量地图。专用于车载应用的Nuvo VTC系列车载计算平台安装在地形勘测车上,拥有丰富I/O和大容量存储,已成为客户在道路项目上的紧密合作伙伴。
在地图绘制和地理编码中保持一致性和准确性是非常重要的,有利于进行分析和避免错误、节省成本。一直以来,由GIS专员人工建立和维护地图数据都是一个相当耗时的过程,而地面风貌又时常在变换。一家先进的技术公司利用新的地理空间成像技术及其专有的先进人工智能(AI)和特征提取技术,提供拥有出色细节和有建设性洞察的高清(HD) 2D和3D矢量地图,并保持每年更新。
他们的项目成果为政府、商业和人道主义组织提供了基础数
......长按二维码访问原文

AI机器视觉大模型在磁片色选机上的实践应用--机器视觉网 2024-03-27 16:56:24
2024-03-27 16:56:24 来源: 中国机器视觉网
随着科技的飞速发展,AI机器视觉在工业自动化领域的应用愈发引人注目。其中,磁片色选机作为智能制造的关键环节,其升级与改进对于提高产品质量和生产效率至关重要。本文将深入探讨AI机器视觉的大模型在磁片色选机上的实践应用,涵盖色选机的构造、应用场景、检测的缺陷类型、检测难点、检测精度以及未来展望。
一、应用场景:
磁片色选机在电子制造、光伏产业等领域广泛应用。在电子制造中,磁片作为电路板的重要组成部分,对其表面的质量要求极高。在光伏产业中,磁片的质量直接影响太阳能电池的发电效率。AI机器视觉大模型通过对颜色、纹理等特征的深度学习分析,实现对磁片的精准分类和缺陷检测,确保产品质量。
二、色选机的构造:
磁片色选机的构造较为复杂,主要包括照明系统、
......长按二维码访问原文

LMI Technologies 3D视觉助力铁路检测,为您的安全保驾护航--机器视觉网 2024-03-27 15:25:46
2024-03-27 15:25:46 来源: 中国机器视觉网
高速铁路供电安全检测监测系统(6C系统)
6C 系统的主要功能是对高速铁路的牵引供电系统进行全方位、全覆盖的综合检测监测,主要包括:随着轨道交通的不断发展,对轨道安全检测的要求也越来越高。安全检测始终是保障城市轨道交通安全的重中之重。本期为大家介绍LMI Technologies 一体式3D激光轮廓传感器在铁轨3D轮廓检测、轨面磨损以及接触网与受电弓滑板检测的应用。
铁轨3D检测
· 应用和挑战
随着铁路里程和行车密度的增加,列车运行速度和载重的提升,都会增大铁路轨道的负载影响列车的正常运行,严重时甚至发生重大安全事故。因此,定期对铁轨轮廓尺寸进行3D检测是保证列车安全运行、减少事故发生的必要措施。Gocator一体式智能传感器精度高
......长按二维码访问原文

沃德普计算成像助力2.5D缺陷检测--机器视觉网 2024-03-27 14:39:08
2024-03-27 14:39:08 来源: 中国机器视觉网
背景
机器视觉是一个新兴且不断迭代发展的行业,近年来行业内陆续推出了不同角度照明方案、分时频闪成像方案、光谱成像、3D成像等方案,仍然存在难以检测的缺陷类型。如凹凸特征检测并有效识别其特征大小,棱边缺陷检测,有感、无感划痕区分,兼容所有特征的检测等。这些难题,成为了行业内一直难以攻克的问题。
沃德普计算成像系统
针对这些挑战,沃德普推出了计算成像系统,其中包含了悟空相位成像系统(图(1))和线扫光度立体成像系统(图(2))。这两个系统均利用特殊光场照明,并利用图像信息增强的新技术,助力解决以上难题。
悟空相位成像系统,通过拍摄获取多张图像序列,每个都有不同的照明或光学配置,从每个图像中提取数据并进行组合,获取图像中任意位置特征均呈现出来的
......长按二维码访问原文

埃科光电将携新品亮相成都机器视觉创新论坛―新闻频道- 视觉系统设计 2024/3/26 22:57:26
2024年3月28日,机器视觉产业联盟将在成都举办AI+机器视觉技术工业应用创新论坛暨机器视觉新品推介会,主要围绕当前国际国内新科技和经济发展形势及相关行业动态情况进行探讨交流,推动AI+机器视觉赋能成都电子信息、汽车制造、重大装备等现代高端产业应用场景的落地,促进产业创新融合发展,共建智能制造产业生态圈。
参会产品
埃科光电将携短波红外制冷线阵相机、TS-U30系列小面阵相机等众多新品,出席本次机器视觉创新论坛及新品推介会,诚挚邀请您来现场一探究竟。
短波红外制冷线阵相机
短波红外制冷线阵相机搭载先进的全局快门InGaAs传感器,锁定特定波段,快速响应;采用标准化GigE Vision、Camera Link接口,链路稳定,传输流畅;支持TEC制冷功能,温度可低于环境温度20°C。
TS-U30系列
......长按二维码访问原文

凌云光AI+Vision助力多行业创新发展―新闻频道- 视觉系统设计 2024/3/26 22:50:27
在被誉为“全球三大家用电器与消费电子展览会”之一的AWE 2024展会现场,凌云光·元客视界AI数智人小美正在电商平台上为家电品牌详细介绍着官方旗舰店中冰箱的产品特性,引来众多家电厂商驻足围观。
前不久,凌云光·元客视界AI数智人已入驻京东京麦平台。作为首批入驻的三家直播数字人方案提供商,凌云光也是首个应用完全国产大模型GLM驱动的解决方案提供商 。截至目前,凌云光已累计为平台的117家品牌商提供了数字人服务。
大模型+数字人
相较于传统真人直播,凌云光·元客视界AI数智人具有真人音色复刻能力,且无需硬件设备即可实现云端部署,快速开播;同时,基于GLM-4大模型可在直播过程做到实时互动、“真人化”回复,每天成本不到百元;24小时不间断直播,有效弥补真人带货直播“空档”。数字人也提供了包月、包年的使用方案,
......长按二维码访问原文

所罗门联合安提国际亮相慕尼黑上海电子生产设备展―新闻频道- 视觉系统设计 2024/3/26 22:46:00
上周,应安提国际与其代理商罗升邀请,所罗门于2024年3月20日至22日参加了位于上海新国际博览中心的 「慕尼黑上海电子生产设备展会」,搭载安提国际(Aetina)的高性能边缘计算设备展出智慧医疗解决方案。
转自:所罗门3D视觉
注:文章版权归原作者所有,本文仅供交流学习之用,如涉及版权等问题,请您告知,我们将及时处理。
......长按二维码访问原文

Sherlock8 AI 驱动的视觉检测可以发现极小的纳米级 PCB 缺陷―技术与应用频道- 视觉系统设计 2024/3/26 22:39:17
手机行业的规模和竞争力推动了许多行业的投资和创新,从成像、软件,甚至冶金。毫无疑问,半导体技术和市场受到了最大的冲击和影响, 更小封装更高性能是半导体市场几十年来一直不懈的需求。 几个月前,苹果发布了最新款 iPhone,其中一些配备了台湾台积电生产的全新 3 纳米制造工艺的新型 A17 仿生芯片。 据报道,苹果采购了台积电能够生产的所有3nm芯片。 这些芯片比 5 纳米前代芯片更小、更快、耗电更低、更节能。 据苹果公司称,每块芯片都有 190 亿个晶体管,其中一些晶体管非常小,可能只有 12 个硅原子宽。
同样的压力也延伸到了印刷电路板制造领域。据报道,苹果公司将改用树脂涂层铜 (RCC) 箔作为其新的 PCB 材料,从而使该公司能够将其制造得更薄。 这对制造商来说将是一个挑战,因为 RCC 箔非常脆弱,研
......长按二维码访问原文

堡盟获奖产品连连看―新闻频道- 视觉系统设计 2024/3/27 20:08:59
堡盟作为自动化智能方案解决方案专家,凭借良好的产品创新性一直为国际权威大奖所青睐。其中PAD20气泡传感器,PLP70物位传感器,PAC50分析传感器,PL20点物位开关等产品屡获国际大奖。包括全球工业自动化领域权威技术期刊messtec drives Automation所颁发的Automation Best Award2023奖项以及在德国举办代表全球食品工业顶尖技术的International FoodTec Award国际食品技术奖等等。
面对本土市场客户需求,堡盟引入旗下最优秀的产品,为中国客户带来高品质产品,实现生产效率和产品质量的提升,并得到良好的反馈。
获奖精品大盘点
PAD20气泡检测传感器
PAD20气泡检测传感器是一款获得本土客户广泛青睐的产品,在继获得2021年“乳品技术奖”之后
......长按二维码访问原文

3D视觉引导拆码垛系统方案全面升级―技术与应用频道- 视觉系统设计 2024/3/27 20:18:33
随着海康机器人3D视觉引导拆码垛方案的推出,方案系统架构得到了进一步完善和优化,物流仓储、食品饮料、化工、汽车、3C等多个行业纷纷应用该方案,实现了柔性、高效、安全的自动化生产。
经过持续的技术积累和迭代,该方案在升级中变得更加强大、易用,部署也更加简单。摒弃繁琐的操作,企业可以轻松实现自动化生产,提升生产效率,降低人工成本。海康机器人3D视觉引导拆码垛方案,以技术升级为企业开启自动化生产新纪元。
方案升级
1.AI识别能力升级
识别能力超强
基于超过1000种场景和百万级数据类型的积累,超级AI模型具备极强的识别能力。无论是麻包袋、纸箱还是包裹,都能轻松识别。同时,它还能灵活适应物料变形、垛型松散等特殊情况。
模型精简,快速部署
为了快速解决新场景下数据少的难题,通过模型增强、均衡训练等方法,泛
......长按二维码访问原文

汽车常见检测案例中的光源应用参考―技术与应用频道- 视觉系统设计 2024/3/27 20:27:05
随着机器视觉的飞速发展,图像处理、智能定位、缺陷检测在现代汽车工业中广泛应用。在汽车制造行业,小到汽车零件生产检测,大到汽车的自动驾驶AI识别,都离不开机器视觉。本文分享在一些常见的汽车检测案例中,所使用的机器视觉光源。
汽车连接器针脚检测
使用光源:LTS-3RN12090-R高角度环形光源
检测汽车连接器针脚,使用高角度环形光垂直照射,使针尖部分的轮廓明显,有利于机械手的抓取与对位(见图1)。
图1:汽车连接器针脚实物图(左)与检测案例图(右)。
汽车刹车片轮廓检测
使用光源:LTS-3FT250250-W背光源
检测刹车片的轮廓,判断物料是否正确,跟装配方向是否一致,同时需要精确的定位;使用背光源可清晰地呈现轮廓(见图2)。
图2:汽车刹车片实物图(左)与轮廓检测案例图(右)。
汽车火花
......长按二维码访问原文

检测图像中的孤立点 2024-03-26 09:56
这里用了二阶导数(拉普拉斯)来做卷积。
上式中的二阶有限差分计算为:
获得卷积后的图像g(x)后,通过一个规定的阈值,去找到对应的通孔。
下图是一张喷气发动机涡轮叶片的X射线图像。图像的右上象限中,有一个黑色像素的通孔。那么就可以用上述的公式复现,其中的T值可以选为图像像素最大值的90%。借助这个阈值去控制检测结果。
原图
kernel卷积核
......长按二维码访问原文

PYRA:超轻量级ViT适应&推理高效微调模块 2024-03-26 16:47

arXiv链接:https://arxiv.org/abs/2403.09192
最近,Transformer的规模迅速增长,这向基础模型的下游任务适应中引入了相当大的训练开销和推理效率方面的挑战。现有的工作,即参数高效微调(Parameter-Efficient Fine-Tuning,PEFT)和模型压缩,分别研究了这两部分挑战。然而,PEFT不能保证原始骨干网络的推理效率,特别是对于大规模模型。模型压缩需要显著的训练成本进行结构搜索和重新训练。因此,它们的简单组合不能保证以最小的成本同时实现训练效率和推理效率。在本文中,我们提出了一种新颖的并行生成重激活(Parallel Yielding Re-Activation,PYRA)方法,以应对训练-推理高效任务适应的挑战。PYRA首先利用并行生成的自适应权
......长按二维码访问原文

MMLU Clinical Topics 数据集介绍 2024-03-26 08:42
数据集信息
MMLU (Massive Multitask Language Understanding) 是一个旨在评估语言模型在多任务上的表现的基准。MMLU 的测试题目涵盖了 57 个不同的领域,其中有 6 个领域与医学知识相关,包括解剖学 (anatomy)、临床知识 (clinical knowledge)、专业医学 (professional medicine)、遗传学 (medical genetics)、大学医学 (college medicine) 和大学生物学 (college biology)。MMLU 一共包含 15908道题目, 并将其分为少样本开发集、验证集和测试集。少样本开发集每个科目有5个问题,验证集可用于选择超参数,由1540个问题组成,测试集有14079个问题。每个科目至少
......长按二维码访问原文

【论文和源码解读】Scaling on Scales:When Do We Not Need Larger Vision Models? 2024-03-26 22:53
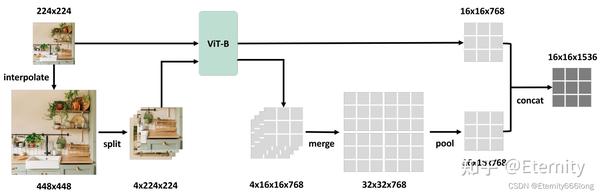
原文地址:https://arxiv.org/abs/2403.13043
开源代码:https://github.com/bfshi/scaling_on_scales
0. 问题和想法
本文提出的问题 :对于更好的视觉理解来说,更大的模型一定是必要的吗?
:对于更好的视觉理解来说,更大的模型一定是必要的吗? 核心思想: 保持预训练模型的规模不变,通过在越来越多的图像尺寸上运行获得越来越强大的特征 ,本文的作者结合上面的思想提出了 Scaling on Scales (S^2^)。
1. 观察和见解
观察 1:虽然在许多情况下,使用 S^2 的较小的模型比较大的模型能获得更好的下游性能,但 较大的模型仍能在较难的例子中表现出更优越的泛化能力 。 见解 1: 较小模型至少应该具有与较大模型相似的
......长按二维码访问原文

阅读笔记:anomalyCLIP零样本缺陷检测 2024-03-27 09:18
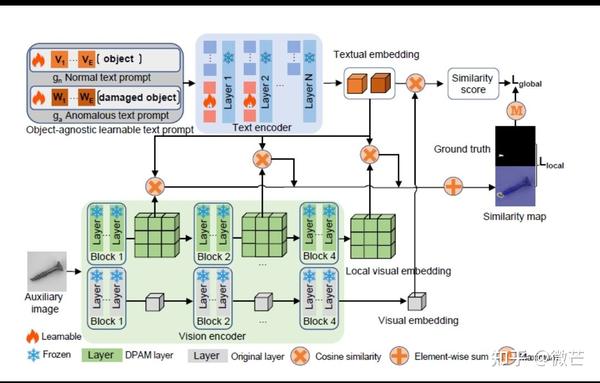
论文题目:anomalyclip: object-agnostic prompt learning for zero-shot anomaly detection零样本异常检测的对象不可知提示学习
先定义一下此处的零样本异常检测:即使用辅助数据训练的检测模型来检测目标数据集,且训练数据集中没有任何目标数据集的异常样本
最近,大型预训练视觉语言模型(VLM),例如 CLIP,在各种视觉任务(包括异常检测)中表现出了强大的零样本识别能力。 然而,它们的零样本性能很弱,因为视觉语言模型更多地关注于对前景对象的类语义进行建模,而不是对图像中的异常/正常进行建模。
就此作者提出AnomalyCLIP ,其学习与对象无关的文本提示,无论其前景对象如何,都可以捕获图像中的一般正常性和异常性。 这使得模型能够专注于异常图
......长按二维码访问原文

CVPR 2024 | 涨点神器!谷歌提出:小样本图像分类的冻结特征增强 2024-03-27 12:15

本文提出FroFA(冻结特征增强),总共涵盖了二十种特征增强,研究表明其可以在三个网络架构、三个大型预训练数据集和八个迁移数据集上一致地提高小样本性能。大家赶紧学起来!
点击关注 @CVer官方知乎账号,可以第一时间看到最优质、最前沿的CV、AI、AIGC工作~
点击进入:CVer技术交流平台
FroFA
Frozen Feature Augmentation for Few-Shot Image Classification
单位:Google DeepMind等
主页:https://frozen-feature-augmentation.github.io/
论文:https://arxiv.org/abs/2403.10519
在预训练的视觉模型输出(即所谓的“冻结特征”)之上训练线性分
......长按二维码访问原文

现代化工业生产线中的机器视觉检测AI质检解决方案 2024-03-27 17:34

随着科技的日新月异,现代化工业生产正在经历一场前所未有的智能化革命。在这一进程中,机器视觉与人工智能技术深度融合,构建了高效精准的AI质检解决方案,极大地提升了工业生产线的产品质量管理水平。其中,DLIA工业缺陷检测软件作为关键技术载体,正逐步引领着这场制造业品质控制的革新。
机器视觉检测技术,通过模拟人类视觉系统,结合先进的图像处理算法和深度学习算法,能够实现对产品全方位、实时、高效的自动检测,解决了传统的质检方式效率低下的问题。它的核心是运用AI算法对采集的图像数据进行深度分析和理解。在高速运行的工业生产线上,高清摄像头捕捉每一个产品的细微特征,并将这些图像信息实时传输至质量管理系统。DLIA工业缺陷检测基于深度学习的智能图像分析能力,可以精准识别出产品表面的微小瑕疵、尺寸偏差甚至内部结构
......长按二维码访问原文

基于YOLOv8/v5和ByteTrack的多目标检测计数与跟踪系统(深度学习代码+UI界面实现+训练数据集) 2024-03-27 12:24
摘要:之前的多目标检测与跟踪系统升级到现在的v2.0版本,本博客详细介绍了基于YOLOv8/YOLOv5和ByteTrack的多目标检测计数与跟踪系统。该系统利用最新的YOLOv8和YOLOv5进行高效目标检测,并通过ByteTrack算法实现精确的目标跟踪,适用于多种场景如人群监控、交通流量分析等。系统设计包含深度学习模型训练、系统架构设计等内容。使用5542张行人车辆图片数据进行训练,并对比分析了YOLOv8/v5的模型,并评估性能指标如mAP、F1 Score等。系统基于PySide6设计了用户UI界面和SQLite数据库的登录注册界面,图像、视频、摄像头以及批量文件处理等多种功能,可点击按钮更换模型。
完整资源中包含数据集及训练代码,环境配置与界面中文字、图片、logo等的修改方法请见视频,项目完整文
......长按二维码访问原文

艾科瑞特科技:计算机视觉-通用领域2D全身关键点检测模型 2024-03-26 22:00

艾科瑞特科技:计算机视觉-通用领域2D全身关键点检测模型
关键词:目标检测、目标跟踪、图像识别、图像分类、视频分析、自然语言处理、自然语言分析、计算机视觉、人工智能、AIGC、AI、大模型、多模态大模型、API、Docker、镜像、API市场、云市场、国产软件、信创
内容摘要:
行人图像特征表示提取,图像的特征表示可以用于计算两张图片之间的相似程度,从而判断两张图片中的人是不是同一个个体,适用场景:
智能安防:在安防监控系统中,通过行人图像特征提取和相似度匹配,实现自动识别和追踪特定目标人物。
人脸识别:辅助人脸识别系统,在人脸不清晰或遮挡的情况下,通过行人图像特征进行身份确认。
智能零售:分析顾客在店内的行走轨迹和购物行为,为个性化推荐和营销策略提供支持。
智能交通:监测人行道和交通路口的行人流
......长按二维码访问原文

艾科瑞特科技:计算机视觉-人体美型 2024-03-26 22:05

艾科瑞特科技:计算机视觉-人体美型
关键词:目标检测、目标跟踪、图像识别、图像分类、视频分析、自然语言处理、自然语言分析、计算机视觉、人工智能、AIGC、AI、大模型、多模态大模型、API、Docker、镜像、API市场、云市场、国产软件、信创
内容摘要:
人体美型模型,给定一张单个人物图像(半身或全身),无需任何额外输入,端到端地实现对人物身体区域(肩部,腰部,腿部等)的自动化美型处理,适用于应用场景:
摄影后期处理:在摄影作品中,对人物身体进行美型处理,使照片效果更佳。
广告模特美型:在广告拍摄中,对模特进行美型,提升广告视觉效果。
社交媒体照片优化:在社交媒体平台上发布个人照片前,进行美型处理,提升个人形象。
婚纱照片修饰:在婚纱照片中,对新娘或新郎的身体进行美型,使照片更加完美。
影视特
......长按二维码访问原文

艾科瑞特科技:计算机视觉-手部检测模型 2024-03-26 22:02

艾科瑞特科技:计算机视觉-手部检测模型
关键词:目标检测、目标跟踪、图像识别、图像分类、视频分析、自然语言处理、自然语言分析、计算机视觉、人工智能、AIGC、AI、大模型、多模态大模型、API、Docker、镜像、API市场、云市场、国产软件、信创
内容摘要:
手部检测模型是一种专门设计用于在图像中识别并定位手部区域的算法工具。它接受一张图像作为输入,然后运用深度学习和计算机视觉技术对手部进行检测,最后输出所有检测到的手部区域的检测框、置信度和标签,其常见应用场景:
手势关键点检测:通过检测手部区域并提取关键点,实现对手势的精确识别和解析。
手势识别:在人机交互、游戏娱乐等领域,通过识别手部姿势来控制设备或执行命令。
手部重建:结合计算机图形学技术,实现对手部形态的精细重建,用于虚拟现实、增强现实等
......长按二维码访问原文

CVPR 2024 | 北大&谷歌提出DrivingGaussian:环视动态自动驾驶场景重建仿真 2024-03-26 17:22

本文介绍了来自北京大学王选计算机研究所的王勇涛团队与其合作者的最新研究成果DrivingGaussian。针对自动驾驶场景,该篇工作提出了一个高效、高质量的动态环视驾驶场景三维重建与仿真框架,在大规模环视动态驾驶场景重建任务上表现出色,论文已被CVPR 2024录用。
点击关注 @CVer官方知乎账号,可以第一时间看到最优质、最前沿的CV、AI、AIGC工作~
点击进入:CVer技术交流平台
论文标题:DrivingGaussian: Composite Gaussian Splatting for Surrounding Dynamic Autonomous Driving Scenes
论文:https://arxiv.org/abs/2312.07920
项目主页:
https://githu
......长按二维码访问原文

[分享][每日更新][2024.03.24][CV_arxiv_papers] 2024-03-26 11:41

2024-03-24
EgoExoLearn: A Dataset for Bridging Asynchronous Ego- and Exo-centric View of Procedural Activities in Real World
Egoexolearn:用于桥接异步的自我和以外的过程的数据集,以现实世界中的程序活动为中心
Yifei Huang, Guo Chen, Jilan Xu, Mingfang Zhang, Lijin Yang, Baoqi Pei, Hongjie Zhang, Lu Dong, Yali Wang, Limin Wang, et.al.
null
......长按二维码访问原文

详细解读associative embedding“关联嵌入”(以HigherHRNet为例) 2024-03-26 10:09
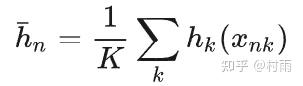
1. associateive embedding解决了一个什么问题?
在多人2D人体关键点检测任务中,使用的方法可以分为自顶向下方法和自底向上方法。自顶向下方法将多人2D人体关键任务分为两个阶段,第一个阶段是使用人体检测器(目标检测)检测出每个人体实例(生成检测框),第二个阶段是将检测到的人体检测框放入单人关键点检测网络(相当于从原始图片中截出一张单人的子图)。自底向下方法为从一张含有多人的图片中先检测出所有潜在的人体的关键点再通过一个“分组”的方法将这些潜在的人体关键点进行分配,分配成N个人体实例。
associateive embedding就是为了解决自底向上的方法中的关键点分组的问题。
2. 什么是associateive embedding?
associateive embedding的中
......长按二维码访问原文

精品推荐 |《工业视觉系统编程及基础应用》职业教育教材正式出版 2024-03-26 17:32

2023年2月,工信部、教育部、财政部等七部门联合印发《智能检测装备产业发展行动计划(2023—2025年)》的通知,提出智能检测装备是智能制造的核心装备,明确工业视觉算法、图像处理软件等专用检测分析软件的开发作为基础创新重点方向。
2023年7月,教育部办公厅《关于加快推进现代职业教育体系建设改革重点任务的通知》中明确提出,开展职业教育优质教材建设。教材内容充分反映行业前沿技术,积极体现产业发展的新技术、新工艺、新规范、新标准,呈现形式要新颖、生动活泼、丰富多彩;鼓励和支持以工作分析为依据,以项目、任务、活动、案例等为载体的教材编写方式。
在此大背景下,作者团队编著了《工业视觉系统编程及基础应用》一书。该书力求产学融合,围绕工业视觉技术的具体应用,基于DCCKVisionPlus平台软件,详细介绍了工业视
......长按二维码访问原文

艾科瑞特科技:计算机视觉-人体关键点检测模型-15点人体关键点 2024-03-26 22:07

艾科瑞特科技:计算机视觉-人体关键点检测模型-15点人体关键点
关键词:目标检测、目标跟踪、图像识别、图像分类、视频分析、自然语言处理、自然语言分析、计算机视觉、人工智能、AIGC、AI、大模型、多模态大模型、API、Docker、镜像、API市场、云市场、国产软件、信创
内容摘要:
人体关键点检测模型是一种基于深度学习的计算机视觉技术,专门用于在输入的人物图像中检测和定位人体的关键点,具有广泛的应用场景:
运动分析和训练:在体育训练中,教练可以通过分析运动员的关键点轨迹,评估其动作的正确性和效率,提供有针对性的指导。
健康监测与康复:在医疗领域,医生可以利用人体关键点检测来监测患者的动作和姿态,评估其康复进展,制定个性化的治疗方案。
自动驾驶与辅助驾驶:在自动驾驶车辆中,通过检测行人和驾驶员的关键
......长按二维码访问原文

新的SDK加速人工智能研究、计算机视觉、数据科学等 2024-03-26 10:36
NVIDIA AI上的JAX
就在今天,在GTC 2022上,NVIDIA在NVIDIA AI上推出了JAX,这是其GPU加速深度学习框架的最新成员。JAX是一个快速增长的高性能数值计算和机器学习研究库。
JAX可以自动区分原生Python函数,并实现类似NumPy的API。
只需几行代码,JAX就可以实现跨多节点和多GPU系统的分布式训练,通过NVIDIA GPU上的XLA优化内核加速性能。
使用JAX实施的一些研究领域包括变压器、强化学习、流体动力学、地球物理建模、药物发现、计算机视觉等。JAX的早期采用者包括DeepMind、Google Research、eBay和InstaDeep。
NVIDIA正在与JAX团队合作,以确保JAX用户在GPU上获得最佳性能和更好的体验。优化的亮点包括以下内容
......长按二维码访问原文

CVPR 2024——PatchFusion:基于Tile的高分辨率单目度量深度估计网络 2024-03-26 13:23

高分辨率深度估计。基于Tile的单目度量深度估计模型处理高分辨率图像,并在与合成训练数据集UnrealStereo4K相对应的测试图像上提供具有复杂细节的高质量深度估计,以及对其他类型的真实图像的zero-shot泛化。上:UnrealStereo4K的域内样本。中:来自middlebury2014年的域外样本。下:来自互联网的域外样本
Abstract
主流的深度估计模型难以适应当今消费者相机和设备中日益增加的分辨率。现有的高分辨率策略显示出了希望,但它们往往面临着局限性,从误差传播到高频细节的丢失。本文提出PatchFusion,一个新颖的基于Tile的框架,有三个关键组件来提高state of the art:
(1)通过高级特征指导将全局一致的粗预测与更精细、不一致的图块预测融合在一起;
(2)
......长按二维码访问原文

艾科瑞特科技:计算机视觉-人像增强修复-高分辨率人脸 2024-03-26 22:03

艾科瑞特科技:计算机视觉-人像增强修复-高分辨率人脸
关键词:目标检测、目标跟踪、图像识别、图像分类、视频分析、自然语言处理、自然语言分析、计算机视觉、人工智能、AIGC、AI、大模型、多模态大模型、API、Docker、镜像、API市场、云市场、国产软件、信创
内容摘要:
人像增强修复-高分辨率人脸是一种运用先进算法对图像中的人像进行修复和增强的技术,同时能够处理高分辨率的人脸图像,以达到提升图像质量和形象的目的,其应用场景包含:
个人修图:用户可以使用该技术来修复和增强自拍或日常照片,提升个人形象。
社交媒体:在社交媒体平台上,用户可以利用该技术快速生成高质量的人像照片,吸引更多关注和点赞。
婚纱摄影:婚纱摄影机构可以利用该技术为新人拍摄出更加完美的婚纱照,留下美好回忆。
证件照制作:在制作证
......长按二维码访问原文

人员区域入侵检测算法在边缘设备的应用与表现 2024-03-27 10:34

人员区域入侵检测算法是当前安全管理领域中备受关注的技术之一。传统的安全监控手段存在监控盲区和人力资源投入大的弊端,而基于人工智能技术的入侵检测算法则提供了一种高效、准确的解决方案。本文将深入探讨一款创新的人员区域入侵检测算法,旨在提高安全管理水平,保障各类场景的安全。
功能介绍:
该算法基于深度学习技术,通过大量场景数据的收集与分析,训练出高效的模型以实现对人员区域入侵的检测。其核心功能包括实时分析视频画面,识别人员是否越界进入禁止区域,并即时发出警报以通知相关责任人。该算法不仅能够应对不同场景下的入侵行为,还能够自适应不同光照条件和背景干扰,保证了监测的准确性和稳定性。
工作原理:
1.目标检测与跟踪:算法首先利用人脸检测模块标记出场景中的人员存在区域,并采用目标检测技术实现对人员的跟踪与定位。
2
......长按二维码访问原文

Introducing Moondream2: A Tiny Vision-Language Model: 2024-03-27T12:05:44+00:00
Vision Language models are the models that can process and understand both visual and language(textual input) data simultaneously. These models combine techniques from Computer Vision and Natural Language Processing to understand and generate text based on the image content and language instruction.
There are many large vision language models available such
......长按二维码访问原文

Vikas Verma: 14.0.0
We use cookies on Analytics Vidhya websites to deliver our services, analyze web traffic, and improve your experience on the site. By using Analytics Vidhya, you agree to our Privacy Policy and Terms of Use
......长按二维码访问原文

Guide on 3D Medical Image Segmentation with Monai & UNET: 2024-03-27T11:06:57+00:00
Introduction
3D image segmentation involves partitioning volumetric data into distinct regions to extract meaningful information such as identifying organs, tumors, etc. With applications ranging from medical diagnosis to industrial inspection and robotics, 3D segmentation plays a pivotal role in understanding complex three-dimensional structures and object
......长按二维码访问原文

In Cabin Monitoring: Best Practices For Data Annotation and Workflow Management: 2024-03-27T08:12:08+00:00

In the advancing autonomous mobility landscape, in-cabin monitoring has emerged as a critical technology, enhancing passenger safety and transforming the driving experience. The effectiveness of in-cabin monitoring systems depends on accurate and efficient data annotation, which serves as the foundation upon which AI models operate. It enables them to analyz
......长按二维码访问原文

Fine-Tuning YOLOv9 Models on Custom Dataset: 2024-03-26T13:00:00+00:00
Fine-tuning YOLOv9 models on custom datasets can dramatically enhance object detection performance, but how significant is this improvement? In this comprehensive exploration, YOLOv9 has been fine-tuned on the SkyFusion dataset, with three distinct classes: aircraft, ship, and vehicle. Through an extensive series of experiments, including modifications to le
......长按二维码访问原文







