文章目录[隐藏]
- 行业资讯
- STM32 嵌入式机器学习(TinyML)教程-02 2021-02-16 21:36
- 前沿重器[8] | CV研究启发语义相似和表征 2022-02-20 20:30
- 机器视觉重点整理 2021-08-24 23:18
- 数据增强(Data Augmentation)在图像分类的应用前景探究 2021-08-11 14:52
- 高瓴资本调研的机器视觉赛道,一个暴利的蓝海行业 2021-03-17 20:22
- VIT Vision Transformer | 先从PyTorch代码了解 2021-02-03 15:00
- 在Windows环境下配置、安装GPU版本YOLOv4(超详细) 2020-09-16 22:49
- 传统图像处理还有前景吗? 2023-04-14 08:08
- 新一代砌砖机器人再次刷新自己的砌砖速度纪录!挑战大砖自如堆砌! 2020-09-28 20:14
- 变频器是如何实现调速的,输入单相电输出为什么变成了三相电? 2021-11-22 09:30
- 入坑机械十年,我们队伍很庞大 2021-03-28 11:46
- 凌云光AI+Vision为工业制造注入新动能--机器视觉网 2024-04-07 11:01:29
- 金品公司荣获DCMM级认证,其数据管理能力正式达到国家标准--机器视觉网 2024-04-07 10:53:07
- 思特威快速启动技术,低功耗IoT设备进阶必备--机器视觉网 2024-04-07 14:29:53
- 走进中车时代电气,看春运背后的智造新速度--机器视觉网 2024-04-07 14:01:20
- 阿丘科技智能相机在食品包装检测的应用--机器视觉网 2024-04-07 13:43:27
- 高混浊水中光信标跟踪及其在水下船坞中的应用--机器视觉网 2024-04-07 11:51:04
- 中科微至单件分离系统为物流自动化加码提速--机器视觉网 2024-04-07 11:31:53
- Basler助力实现对长途列车的自动检测--机器视觉网 2024-04-07 11:20:05
- CMOS 图像传感器为自动驾驶汽车提供视觉感知--机器视觉网 2024-04-07 11:11:22
- 祝贺小米物流北京仓柔性自动化开机仪式圆满成功―新闻频道- 视觉系统设计 2024/4/7 21:45:43
- 海伯森高端智能传感器受邀亮相三大展会―新闻频道- 视觉系统设计 2024/4/7 21:42:34
- 一文了解3D双激光涂胶视觉检测系统―技术与应用频道- 视觉系统设计 2024/4/7 21:55:37
- 《Understanding Vision: Theory, Models, and Data》读书笔记(2)——持续更新 2024-04-07 00:41
- 两个专栏帮你搞定【图像拼接(image stitching)】 2024-04-06 18:58
- CVPR 2024 | 让模型关注你想要的任何属性!CPAL:弱监督语义分割新网络 2024-04-06 17:25
- 网络摄像头与机器视觉相机 2024-04-07 09:16
- 自动图像增强和统一光谱校准 2024-04-07 09:25
- 大模型系列08-多模态(视觉语言)大模型 2024-04-07 02:35
- 零样本!Zero123-6D从单一RGB图像到类别级姿态估计 2024-04-06 20:16
- Transformer为什么会比CNN好 2021-12-23 11:24
- 生动形象!原来深度学习激活函数这么有意思! 2021-09-27 10:00
- 苏黎世大学 SVO 2.0 代码终于开源啦! 2021-07-14 13:10
- [分享][每日更新][2024.04.03][CV_arxiv_papers] 2024-04-07 09:12
- 港大等提出细铁丝网SLAM和三维重建!专治疑难杂症? 2020-08-18 07:29
- 机器视觉中图像采集卡的功能与应用 2024-04-07 13:38
- “计算机视觉女神”被IEEE期刊封杀 2024-04-07 20:23
- CVPR 2024 | 异常检测新网络!InCTRL:学习基于少量正常样本提示的上下文差异实现通用异常检测 2024-04-07 17:13
- NVIDIA最新GSNeRF 通用语义神经辐射场与增强的3D场景理解 2024-04-07 15:01
行业资讯
STM32 嵌入式机器学习(TinyML)教程-02 2021-02-16 21:36
STM32 嵌入式机器学习(TinyML)教程-02
STM32 FP-AI-VISION1视频应用笔记第2部分:FP-AI-VISION1概述 在STM32H747I Discovery开发板上,使用机器学习技术,开发机器视觉应用,本教程由ST(意法半导体)官方发布,中文字幕由微信公号:边缘智能实验室翻译制作。
......长按二维码访问原文

前沿重器[8] | CV研究启发语义相似和表征 2022-02-20 20:30
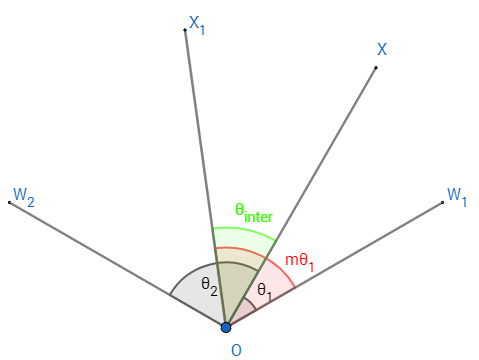
之前在小布助手的文章里,其实能注意到一个细节,就是在损失函数的设计上借鉴了人脸识别的一些技术思路,尤其是损失函数这块。仔细想,人脸识别的核心需求是要求给定一张人脸,快速从录入的库里找到与之接近的人脸并识别是否是该人,库里的人脸千千万,快速识别就成为一个很有挑战性的难题,这个就和语义表征非常相似,而他们的秘诀之一,就是这个损失函数,在人脸识别等相关领域里,在损失函数上的确有很多语义相似度可以借鉴的思路。
常规操作
比较经典的,对于二分类,假设有两个类 q_1 和 q_2 ,我们可以这么认为分到这两者的概率分别就是:
p1=\frac{exp(W_{1}^{T}f+ b_{1})}{exp(W_{1}^{T}f_i + b_{1})+exp(W_{2}^{T}f_i + b_{2})}
otag\ \\p2
......长按二维码访问原文

机器视觉重点整理 2021-08-24 23:18
本文使用 Zhihu On VSCode 创作并发布
本文为笔者大二时期机器视觉课程的重点内容归纳,如有纰漏请随时联系笔者。
数字图像的概念与性质
距离
距离种类
欧氏距离: D_E=\sqrt{(m-h)^2+(n-k)^2}
城区距离: D_4=|m-h|+|n-k|
棋盘距离: D_8=\max\{|m-h|,|n-k|\}
距离变换
给出图像中每个像素与某个图像子集的距离,算法如下:
从上到下,从左至右遍历, F(p)=\underset{q\in AL}{\min}\{F(p),D(p,q)+F(q)\} 从下到上,从右到左遍历, F(p)=\underset{q\in BR}{\min}\{F(p),D(p,q)+F(q)\}
import numpy as np def di
......长按二维码访问原文

数据增强(Data Augmentation)在图像分类的应用前景探究 2021-08-11 14:52
主要结论:
引言:
数据增强在很多领域都有很广泛的应用,例如医学成像,热学成像以及深度学习等等。本文仅关注在深度学习领域中的数据增强的历史、应用以及其前景。
众所周知,深度学习是一个数据驱动的领域,如今机器视觉已经在图像分类,图像分割,目标检测等领域有了长足的发展。一般来说,在机器视觉任务中,目标是基于可用的训练数据训练模型以正确预测新(训练集中未出现的)图像的类别即模型需要有一定泛化性。因为模型能够概括从训练中提取的知识图像以正确分类培训期间未遇到的图像。有一种泛化性较差的模型被称为模型过拟合,即拟合了不需要的属性。这就要求我们的模型足够简单,以免对这些不需要的属性进行记录。
有多种方法提高DL模型的泛化能力(并避免过度拟合),例如,通过正则化机制及dropout, weight decay, bat
......长按二维码访问原文

高瓴资本调研的机器视觉赛道,一个暴利的蓝海行业 2021-03-17 20:22
2021年前两月,高瓴资本调研了4家工业自动化领域的公司,分别是哈工智能,海得控制,矩子科技,天准科技。
其中,矩子科技,天准科技这两个公司,更精准的说,应该属于机器视觉赛道。
机器视觉是什么东西呢?
简而言之,机器视觉是指用机器来实现人的视觉功能。
今天我就来说说投资机器视觉赛道需要了解的一些关键知识。
我们首先来分析一下为什么机器视觉赛道是个暴利的蓝海行业?
其次我会分析一下机器视觉赛道最有投资价值的细分领域是哪些?
一,为什么机器视觉赛道是个暴利的蓝海行业?
机器视觉赛道究竟有什么魅力呢?
我们只要设想一下如下场景就可以明白了。
现在,工厂的生产线上需要很多QC质量检验员用肉眼检查产品的质量缺陷。
以后,这些QC会全部下岗,被机器视觉替
......长按二维码访问原文

VIT Vision Transformer | 先从PyTorch代码了解 2021-02-03 15:00
代码来自github 参考目录:
【前言】:看代码的时候,也许会不理解VIT中各种组件的含义,但是这个文章的目的是了解其实现。在之后看论文的时候,可以做到心中有数,而不是一片茫然。
VIT类
初始化
和之前的学习一样,从大模型类开始看起,然后一点一点看小模型类:
class ViT(nn.Module): def __init__(self, *, image_size, patch_size, num_classes, dim, depth, heads, mlp_dim, pool = 'cls', channels = 3, dim_head = 64, dropout = 0., emb_dropout = 0.): super().__init__() assert image_size
......长按二维码访问原文

在Windows环境下配置、安装GPU版本YOLOv4(超详细) 2020-09-16 22:49
关于YOLO
Yolo是一种物件侦测的方法,类似的有R-CNN,Fast R-CNN等
Yolo使用的是one stage方法,也就是只需要对图片作一次 CNN便能够判断图片内的物体位置与类别,因此提升辨识速度。
目前官方给出的yolo版本有
Yolo1
Yolo2
Yolo3
Yolo4
Yolo5目前还未被官方承认(类似于yolo4的改进版,没有太大区别)
每个版本也有其对应的tiny-yolo版本,即轻量级yolo,更小,方便在移动设备上使用(准确率有损失)
原作者是使用darknet神经网络来实现yolo的
搭建yolo环境
为了在window上快乐的使用yolo4,接下来就开始环境配置的部分啦~
Demo使用的配置为Win10 + CUDA10.0 + Pytho
......长按二维码访问原文

传统图像处理还有前景吗? 2023-04-14 08:08
给你一个最简单的项目,测量手机屏幕尺寸,要求到亚像素精度。
测量,这是工业检测中最常见的场景之一。
给你足够的手机屏幕图片,大小都有,带框的,不带框的,宽的高的窄的。
或者你自己生成一堆随机大小的矩形,自己训模型去。
用啥模型你一时半会都不知道吧? 哈。
你终于找到了这个模型,git clone开始调参。
你吭哧吭哧的调的时候,隔壁传统算法都上线了一个月了,算法很简单,i5 CPU能跑到200帧。
调了一周,性能满意。结果产线上屏幕换型了。
隔壁改一下roi,接着跑。
你说,再拍一波测试集,我要验证性能。
就算客户能忍得了你,老板也忍不了你了。
有一些领域,传统算法就是又快又准又稳定。深度学习永远也搞不定。
......长按二维码访问原文

新一代砌砖机器人再次刷新自己的砌砖速度纪录!挑战大砖自如堆砌! 2020-09-28 20:14
新一代砌砖机器人再次刷新自己的砌砖速度纪录!挑战大砖自如堆砌!
机器人时代似乎离现实生活愈来愈近,扫地机器人、擦窗机器人等家用机器人已经普及!这回亮相的机器人是专为建筑工地设计的砌砖机器人,且已经是更新的一代,并在每小时砌砖速度上再次刷新自创的记录!
......长按二维码访问原文

变频器是如何实现调速的,输入单相电输出为什么变成了三相电? 2021-11-22 09:30
变频器是如何实现调速的,输入单相电输出为什么变成了三相电?
......长按二维码访问原文

入坑机械十年,我们队伍很庞大 2021-03-28 11:46
入坑机械十年,我们队伍很庞大
我是女生,对机械是真爱,辗转多年还是没有放弃它,做结构,做自动化,接触各个供应链的同行,对以后得工作方向有所思考,望大家参考
......长按二维码访问原文

凌云光AI+Vision为工业制造注入新动能--机器视觉网 2024-04-07 11:01:29
2024-04-07 11:01:29 来源: 中国机器视觉网
近日,凌云光知识理性研究院副院长全煜鸣发表《AI+Vision在工业中的应用》主题报告。人工智能迅速发展,AI技术已成为推动工业发展的关键力量。凌云光将AI技术与机器视觉相结合,有效解决工业质检中的难题,特别是在难以用传统方法描述和量化的质量管理问题上取得了突破。
在视觉感知方面,凌云光应用人眼视觉模型建立科学品质基准,用工业质检1000万数据集练就预训练视觉大模型,用模型剪枝知识蒸馏方法轻量化分类分割模型进行端侧提效。
同时,凌云光工业AI质检平台F.Brain可完成工业质检AI的数据管理、模型迭代、模型评估优化和部署,结合质量管理系统GMQM,完成工厂级数据闭环,小端处理、边云计算,大大提高视觉AI的应用效率。
在精密组装领域,凌云
......长按二维码访问原文

金品公司荣获DCMM级认证,其数据管理能力正式达到国家标准--机器视觉网 2024-04-07 10:53:07
2024-04-07 10:53:07 来源: 中国机器视觉网
近日,金品公司以出色的数据战略和执行能力,成功通过了严格的审查,荣获DCMM(甲方二级)证书。这一荣誉标志着金品公司的数据管理能力达到了行业领先水平。
自2018年国家级数据管理领域评估标准——数据管理能力成熟度模型(DCMM)发布以来,其已成为衡量企业在数据管理和运营领域实力的重要标准,受到了社会各界的广泛关注和积极参与。DCMM不仅为企业提供了一个全面评估和提升数据管理能力的框架,而且成为了企业数字化转型过程中不可或缺的参考和工具。
获得DCMM证书的企业,标志着在数据管理和运营方面遵循了严格的国家标准,在竞争激烈的市场中的领先地位和强大的实力。
什么是DCMM?
DCMM是《数据管理能力成熟度评估模型》GB/T 36073-2018
......长按二维码访问原文

思特威快速启动技术,低功耗IoT设备进阶必备--机器视觉网 2024-04-07 14:29:53
2024-04-07 14:29:53 来源: 中国机器视觉网
近年来,随着物联网技术的不断演进,智能家居应用逐渐融入人们的日常生活。市面上常见的智能家居设备,如智能可视门铃、家用摄像头(IPC)等,多为无线电池供电摄像头(以下简称“无线电池摄像头”),因体积小巧、无需布线、安装灵活、支持WiFi联网查看等特点,在消费端市场广受追捧。据Yole最新预测,到2028年,该类设备的出货量将增长至1.9亿颗。与此同时,无线电池摄像头在续航能力方面的局限性依然不可忽视:它们一般采用锂电池或干电池供电,需定期充电或更换电池。因此,高性能、低功耗的摄像头系统设计解决方案迫在眉睫。
无线电池摄像头如何省电?
为降低系统功耗,先进的主流智能手机通常配备了“抬手亮屏”或“注视亮屏”的功能,通过手机内部传感器检测来激活手
......长按二维码访问原文

走进中车时代电气,看春运背后的智造新速度--机器视觉网 2024-04-07 14:01:20
走进中车时代电气,看春运背后的智造新速度
2024-04-07 14:01:20 来源: 中国机器视觉网
作为中国电气化铁路装备事业的开拓者和领先者,中车时代电气近年来与海康机器人携手,对其生产制造中心进行智能化升级。2023年,智能化升级后的中车时代电气轨道交通变流器智能制造示范工厂入选国家级智能工厂。
2024年春运步入尾声,预计有90亿人次跨区域流动。更快速、更便捷的高铁在这场壮观的迁徙中发挥着重要作用。你知道吗,高铁背后其实蕴藏着丰富的智能制造基因。下面小编带大家走进中车时代电气,一览高铁背后的智造新速度。
如何满足多元化需求?
中车时代电气智能工厂产线众多,每条产线的物料需求各异,倾向于多品种小批量的模式;物料大小件特征明显,SKU多;物料按照类型分布在各个库区,配送节拍多样,全厂物料分布点
......长按二维码访问原文

阿丘科技智能相机在食品包装检测的应用--机器视觉网 2024-04-07 13:43:27
2024-04-07 13:43:27 来源: 中国机器视觉网
包装作为食品产业中不可或缺的一环,承担着保护食品品质、传递关键信息的重要职责。其不仅仅是产品的外在表现,更是消费者对食品安全和品质的信任基石。
EVS-SC200深度学习智能相机,凭借高效AI算法,完成OCR、装配验证、计数、瑕疵检测、分类等任务,有效捕捉并预警食品包装的潜在问题,赋能食品包装环节的工艺过程管控,为食品安全保驾护航!
包装字符识别
EVS-SC200能够轻松识别包装上的喷码字符。无论是漏码还是标识不清晰的产品,它都能够准确抓取并剔除,确保喷印信息与实际产品信息的一致性。此外,它还可兼容不同规格、不同图案包装的字符检测,为食品企业提供更加全面的解决方案。
包装装配检查
EVS-SC200能够学习并识别目标的形态、颜色等特征
......长按二维码访问原文

高混浊水中光信标跟踪及其在水下船坞中的应用--机器视觉网 2024-04-07 11:51:04
2024-04-07 11:51:04 来源: 中国机器视觉网
了解海洋环境对各种水下任务至关重要,如资源的探测和水下结构的检查,没有自主水下航行器(AUVs)的介入,这些任务就无法进行。由于机载电池和数据存储容量不足, AUVs在执行水下探索任务也会受到限制。水下对接站的出现能够很好的解决这一问题,它能够为水下机器人提供水下充电和数据传输。然而在动态海洋环境中,浑浊和低光条件是阻碍成功对接的关键挑战。
在本文中,研究人员提出了一种基于视觉的引导方法,使用锁定检测以减轻浊度的影响,同时屏蔽杂光和噪声。锁定检测方法锁定位于对接站灯标的闪烁频率,并消除其他频率无用光的影响。该方法使用两个固定频率发光的信标,安装在模拟对接站和一个sCMOS相机(鑫图Dhyana 400BSI)上。概念验证实验结果表明,该方法能够
......长按二维码访问原文

中科微至单件分离系统为物流自动化加码提速--机器视觉网 2024-04-07 11:31:53
2024-04-07 11:31:53 来源: 中国机器视觉网
2023年,我国邮政行业寄递业务量同比增长16.8%,达到了惊人的1624.8亿件。[1]这个成绩的取得一方面归功于市场因素,另一方面则得益于单件分离系统等智能物流装备在邮政行业的广泛应用。中科微至单件分离系统通过智能识别和精细管理每个快递包裹,有效解决了传统批量处理模式下混装导致的分拣困难、效率低下等问题,为自动化分拣提质增效。
技术原理
单件分离系统采用视觉识物技术,并控制单元的独立运动实现包裹分离,一般由输入段、发散分离段、居中段和拉距段这4个部分组成。
输入段:通过传感器检测包裹有无,控制皮带机启停,将包裹输入系统;发散分离段:利用相机识别包裹位置,发送信号给PLC,控制伺服电机将包裹发散分离;居中段:将分开的包裹居中,确保它们在进
......长按二维码访问原文

Basler助力实现对长途列车的自动检测--机器视觉网 2024-04-07 11:20:05
2024-04-07 11:20:05 来源: 中国机器视觉网
Deutsche Bahn德国联邦铁路公司使用图像技术来完成维护工作:借助E-Check,为不断增加的长途运输旅客数量做好准备。
火车数量不断增加,技术工人日益短缺
在未来几年内,Deutsche Bahn德国联邦铁路公司的长途运力将比2020年增加近一倍。届时,维护需求将会增加。除了进行结构化和人员投资之外,还需要投资自动化系统才能满足上述需求。启动E-Check流程旨在开发一套半自动化的检测和维护系统,用于维护各种ICE城际快速列车(ICE是德国InterCity Express长途列车的缩写)。第一个配备新技术是位于科隆市尼佩斯区的ICE工厂。到2025年,柏林、多特蒙德、汉堡和慕尼黑将陆续采用这项新技术。E-Check可提供的帮助包括
......长按二维码访问原文

CMOS 图像传感器为自动驾驶汽车提供视觉感知--机器视觉网 2024-04-07 11:11:22
2024-04-07 11:11:22 来源: 中国机器视觉网
要实现全自动驾驶汽车,需要整合来自多种传感器的信息,其中摄像头的信息可能是最重要的。这些摄像头必须能够在各种条件下连续捕捉最微小的细节,以确保车辆乘客和其他道路使用者的安全。本文将探讨在选择图像传感器时需要注意的关键特性,以便为自动驾驶汽车提供所需的出色功能组合。
图 1 图像传感器是实现自动驾驶的重要组成部分
图像传感器负责将光子转化为电子,然后存储为数字图像数据。如今,图像传感器广泛应用于各种摄像头视觉应用,包括智能工厂、医学成像和汽车领域。图像传感器的选择取决于给定应用所需的性能水平。在决定使用哪种图像传感器时,首先需要了解所需的帧率、预期的照明条件和所需的系统容限,但如果缺乏视觉系统方面的工程专业知识,可能会让这个过程变得艰巨。好在有
......长按二维码访问原文

祝贺小米物流北京仓柔性自动化开机仪式圆满成功―新闻频道- 视觉系统设计 2024/4/7 21:45:43
4月3日下午,小米物流北京仓柔性自动化开机仪式顺利举行,本次开机是小米智能化战略布局的重要一步。
新的仓储展现新的实力。海康机器人参与并见证该智能仓圆满开机!
随着业务的快速发展和市场多样性的需求,此次小米物流北京仓进行了全面升级。引入海康机器人智慧物流解决方案,真正实现了仓库的柔性化运营。
该方案立足于对仓储空间的极致利用和对货物智能化拣选的深度挖掘,不仅应用了高效率、高存储、高稳定性的料箱机器人,同时应用了高效灵活的潜伏机器人,实现效率与存储双赢。
站在AI全面爆发的新风口,小米决心要把软硬深度融合的升级版科技战略,全面贯彻到从设计生产到仓储物流的每个环节。海康机器人发力于智能制造和智慧物流,双方深度合作,进一步提升终端消费者的购物体验。
本次开机仪式不仅代表着小米仓储服务能力的进一步提升,也预示
......长按二维码访问原文

海伯森高端智能传感器受邀亮相三大展会―新闻频道- 视觉系统设计 2024/4/7 21:42:34
随着工业4.0时代的深入推进,智能制造已成为全球制造业转型升级的重要方向。在刚刚落幕的韩国智能工厂及自动化展、成都AI+机器视觉技术工业应用创新论坛和ITES深圳工业展上,海伯森系列展品精彩亮相,以多元的应用方案与观众互动,展现了品牌在高端智能传感器领域的领先实力与创新思维。
产品亮相
海伯森技术(深圳)有限公司,作为一家持续多年为海内外500强名企提供高性能传感器产品及优质技术服务的国产高端智能传感器制造企业,在光学精密测量、工业2D/3D检测、机器人智能应用等领域已形成成熟的产品矩阵。主力产品包括3D闪测传感器、3D线光谱共焦传感器、点光谱共焦位移传感器、超高速工业相机、六维力传感器、激光对刀仪、激光对针传感器及各类激光检测传感器。
应用演示
在展会上,我们展示了在技术创新方面的成果,包括光谱共焦传
......长按二维码访问原文

一文了解3D双激光涂胶视觉检测系统―技术与应用频道- 视觉系统设计 2024/4/7 21:55:37
玻璃三角胶,作为一种重要的粘合剂和密封材料,其独特的粘性和密封性能使得它在多个领域中都发挥着不可或缺的作用。
在汽车制造中,玻璃三角胶用于挡风玻璃、侧窗玻璃与天窗玻璃的粘接与密封。起到了高温稳定性、低温韧性、耐冲击性等的作用。
自动设备涂胶过程中,由于胶水残留气泡,胶嘴堵塞,胶嘴残胶引起卷胶,涂胶设备本身信号故障等问题,容易出现胶水缺失,胶型宽度,位置偏移等情况,进而导致密封性不足,影响玻璃透光性,玻璃无法正确安装或固定。
3D双激光涂胶软件在生产过程中的应用
产品介绍
斯睿特3D双激光涂胶检测产品,在生产作业工位上,运用蓝紫光测量技术与激光三角法,在线跟随式检测实时捕捉胶体三维信息精确输出点云及高度数据。产品地图直观呈现胶条检测状态,便于迅速定位异常。
主要适用于天窗侧窗玻璃胶等工件监控胶型品质检
......长按二维码访问原文

《Understanding Vision: Theory, Models, and Data》读书笔记(2)——持续更新 2024-04-07 00:41
本文将在huuuuusy:《Understanding Vision: Theory, Models, and Data》读书笔记(1)的基础上继续介绍,主要包含对第2章内容的学习笔记。这一章首先介绍了神经元、神经回路和大脑区域,从而概述了构成视觉通路的大脑区域。其次,介绍视网膜和V1的神经特性。在此基础上,沿着视觉信息的路径进一步描述一些纹外区域(视觉区域 2 [V2]、视觉区域 4 [V4]、中颞视觉区域 [MT]/视觉区域 5 [V5] 和下颞叶皮层 [IT]),并讨论背侧流和腹侧流之间的分离及其不同的处理重点。随后介绍眼球运动和视觉注意力的概述,以及与这些相关的大脑区域和神经活动。最后一小节列出了视觉行为研究中的典型主题,并将它们与本书的主题联系起来。
这一章也是后续章节的阅读基础,李老师用一些数学模
......长按二维码访问原文

两个专栏帮你搞定【图像拼接(image stitching)】 2024-04-06 18:58
【图像拼接论文精读】专栏:图像拼接论文精读
【图像拼接源码精读】专栏:图像拼接论文源码精读
前言
图像拼接(image stitching)是计算机视觉中的高级图像处理手段,是一个小众方向,研究的人很少,自然也没有人做这个领域的专栏教程。一方面,入门该邻域的难度大、门槛高,需要强大的数学、图形学功底;另一方面,在本领域内想创新比较困难,文章确实比较难发,研究者越来越少。全网能搜集到的也都是一些零散的知识和浅显的解读,没有深入。
鄙人不才,写了两个专栏,帮你搞定【图像拼接(image stitching)】,不用再为看不懂论文,看不懂代码而苦恼。
专栏简介
专栏分为【图像拼接论文精读】专栏和【图像拼接源码精读】专栏。
顾名思义,一个帮你看懂论文原理,助力论文写作;另一个帮你读懂代码,跑出实验结果,进
......长按二维码访问原文

CVPR 2024 | 让模型关注你想要的任何属性!CPAL:弱监督语义分割新网络 2024-04-06 17:25

本文分享论文Hunting Attributes: Context Prototype-Aware Learning for Weakly Supervised Semantic Segmentation,一种基于上下文原型感知学习(CPAL)的弱监督语义分割方法,旨在通过缓解实例与上下文之间的知识偏差来改善类激活图的完整性。
点击关注 @CVer官方知乎账号,可以第一时间看到最优质、最前沿的CV、AI、AIGC工作~
快点击进入:Mamba和图像分割技术交流平台
本工作由Monash Medical AI Group (MMAI)提出。Monash MMAI是由Zongyuan Ge(戈宗元)副教授带领,研究方向包括但不限于医学影像处理,医学人工智能。MMAI目前已在JAMA,柳叶刀子刊,Nature子
......长按二维码访问原文

网络摄像头与机器视觉相机 2024-04-07 09:16

撸陆知识小课堂,每周都有干货内容等着大家!
我们使用网络摄像头,它们非常便宜。它们似乎在 Zoom 会议或渲染办公室内部的良好图像方面表现良好。那么为什么不直接使用网络摄像头作为机器视觉应用程序的前端呢?
在我们深入分析和解释原理之前,让我们先通过以下同一印刷电路板 (PCB) 的并排图像来了解一下:
机器视觉相机和镜头与网络摄像头
并排图像
在上面的图像对中,左侧图像是使用 20MP 机器视觉相机和高分辨率镜头生成的。右图使用了带有消费者传感器和光学器件的网络摄像头。
两者都在相同的照明下使用,并在指定的操作条件下进行最佳定位等。换句话说,我们试图给网络摄像头一个公平的机会。
即使在上图中,左侧图像看起来也很清晰,对比度良好,而右侧图像对比度较差,即使在宽视场 (FOV) 下也很
......长按二维码访问原文

自动图像增强和统一光谱校准 2024-04-07 09:25

撸陆知识小课堂,每周都有干货内容等着大家!
使用高光谱相机进行测量时,准确的光谱校准至关重要。光谱特征的位置需要尽可能精确。必须在光谱采样中准确估计峰值的中心位置。然而,正如此处介绍的,即使相机之间的采样相同,但设备之间采样带的位置可能不同。为了简化设备之间的数据交换和模型的可转移性,同一类型相机之间的统一光谱校准(即光谱带的位置,以纳米为单位)是最重要的指标。此功能是 Specim FX 相机的特色。
VNIR = 可见近红外 (400 – 1000 nm)
AIE = 自动图像增强
通常,每个以推扫方式工作的光谱相机都有不同的光谱校准。这是由于这些设备的组装方式造成的。光谱仪将穿过入口狭缝的光分散到 2D 探测器上(参见下图 1)。探测器有两个轴:空间轴(水平)和光谱
......长按二维码访问原文

大模型系列08-多模态(视觉语言)大模型 2024-04-07 02:35
前言
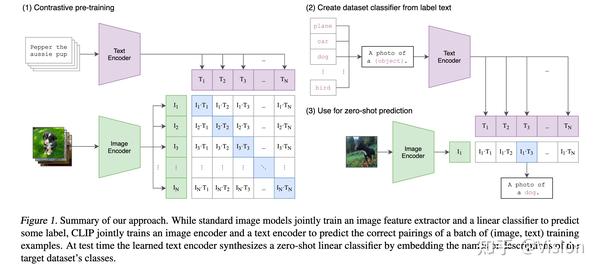
按照之前Vision:大模型系列00 - 前言规划,带来第8篇文章-多模态大模型(视觉语言大模型)的发展过程和目前研究现状。想了解语言/视觉各自单模态的研究发展细节的话见之前分享过的第6篇(大模型系列06 - 自然语言大模型)和第7篇(大模型系列07-视觉大模型)。·由于目前还没有统一的视觉/语言通用大模型底座,更多的是利用各自领域训练好的大模型,对一些对齐和后续特定任务的finetuning。其实多模态这块没有看到什么新的方法论,研究工程更多的是在处理数据,或者为了减少脏数据对效果的影响,在模型结构设计和训练上做一些适当的调整。整体工作涉及到16篇paper。
对齐视觉和文本的embedding
[推荐]【CLIP】Learning Transferable Visual Models From
......长按二维码访问原文

零样本!Zero123-6D从单一RGB图像到类别级姿态估计 2024-04-06 20:16
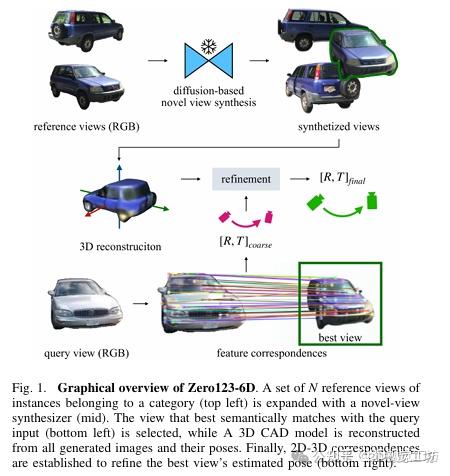
论文题目:Zero123-6D: Zero-shot Novel View Synthesis for RGB Category-level 6D Pose Estimation
作者:Francesco Di Felice, Alberto Remus等
作者机构:Department of Excellence in Robotics & AI, Mechanical Intelligence Institute, Scuola Superiore Sant’Anna, Pisa, Italy等
论文链接:https://arxiv.org/pdf/2403.14279.pdf
这篇论文介绍了一种名为Zero123-6D的方法,旨在通过结合扩散模型和特征提取技术,增强RGB类别级别的6D姿态估计。该
......长按二维码访问原文

Transformer为什么会比CNN好 2021-12-23 11:24
Transformer为什么会比CNN好
《沈向洋带你读论文》第三期邀请的嘉宾是微软认知服务首席研究经理袁路老师,在节目中袁路老师分享了他对于Transformer和CNN的异同、优劣的看法。完整版视频现已同时推出www.bilibili.com/video/BV1L3411x7hw。跟视频读论文,了解IDEA behind Papers。
......长按二维码访问原文

生动形象!原来深度学习激活函数这么有意思! 2021-09-27 10:00
生动形象!原来深度学习激活函数这么有意思!
深度学习内容有的很枯燥乏味,本视频来自Insane在推特上的一个分享,将激活函数用拟人的方式表现出来,直观且有意思
......长按二维码访问原文

苏黎世大学 SVO 2.0 代码终于开源啦! 2021-07-14 13:10
苏黎世大学 SVO 2.0 代码终于开源啦!
代码地址:https://github.com/uzh-rpg/rpg_svo_pro_open SVO 2.0 有如下特点: 1、支持透视、鱼眼和双目相机 2、视觉惯性里程计: SVO 2.0 +视觉惯性滑动窗口优化后端(OKVIS修改) 3、视觉惯性SLAM: SVO 2.0 +视觉惯性后端+使用iSAM2全局BA地图。全球地图是实时更新的(多亏了iSAM2),并用于定位。 4、通过DBoW2和位姿图形成的闭环支持一个轻量级的、全局一致(但不那么精确)的地图。 欢迎加入技术交流群一起和同行交流,入群请添加此微信号:chichui502 ,备注:“名字+学校/公司+研究方向”。
......长按二维码访问原文

[分享][每日更新][2024.04.03][CV_arxiv_papers] 2024-04-07 09:12

Publish Date Title Title_CN Authors PDF Code
2024-04-04 MVD-Fusion: Single-view 3D via Depth-consistent Multi-view Generation MVD-Fusion:通过深度一致的多视图生成实现单视图 3D Hanzhe Hu, Zhizhuo Zhou, Varun Jampani, Shubham Tulsiani http:// arxiv.org/pdf/2404.0365 6v1 null
2024-04-04 RaFE: Generative Radiance Fields Restoration RaFE:生成辐射场恢复 Zhongkai Wu, Ziyu Wan, Jing Zhang
......长按二维码访问原文

港大等提出细铁丝网SLAM和三维重建!专治疑难杂症? 2020-08-18 07:29
港大等提出细铁丝网SLAM和三维重建!专治疑难杂症?
Vid2Curve: Simultaneous Camera Motion Estimation and Thin Structure Reconstruction from an RGB Video(SIGGRAPH 2020) 细结构,如线框雕塑、栅栏、电缆、电线和树枝,在现实世界中很常见。利用传统的基于图像或基于深度的重建方法获取其三维数字模型具有极大的挑战性,因为细结构往往缺乏明显的点特征,且存在严重的自遮挡现象。我们提出了第一种方法,从手持相机的彩色视频中,完成同时估计相机运动和重建复杂的高质量三维细结构。
......长按二维码访问原文

机器视觉中图像采集卡的功能与应用 2024-04-07 13:38

机器视觉技术广泛应用于工业生产检测、医疗、交通等领域助力实现自动化、智能化。整个机器视觉系统可分为图像采集和图像处理两大模块。而图像采集卡是图像数据采集部分和处理部分的接口,起着重要作用。
在机器视觉系统中,图像采集部分主要由工业相机、工业镜头以及光源组合而成,而图像处理部分则是由图像处理软件来实现。图像采集卡可理解为工业相机(视频源)和计算机(软件)之间的接口。图像采集卡采集到的图像供计算机或者其它处理器处理。
01图像采集卡的原理
首先相机及光学系统“看”到的真实世界的具体部分作为光信号。然后CCD或者CMOS芯片将光信号转化为电信号。相机将视频信号以一定的格式或者协议输出至图像采集卡。每个像素独立的把光强以灰度值(Gray Level)的形式表达。这些光强值从CCD 或者CMOS芯片的矩阵中被转移存
......长按二维码访问原文

“计算机视觉女神”被IEEE期刊封杀 2024-04-07 20:23
来源 | 量子位 ID | QbitAI
计算机学术界的女神“Lenna”被IEEE“封杀”了——
IEEE计算机协会宣布,4月1日起不再接收包含该图像的论文。
△Lenna图
IEEE技术&会议活动副主席Terry Benzel在邮件里这样写道:
IEEE本着坚持促进开放、包容及公平文化的承诺,同时尊重照片主体Lena Forsén本人的意愿,决定不再接收包含Lenna图像的论文。
也就是说,之后委员会或审稿人会特地留意论文中是否有这张图,如果有的话,会要求作者用替换图片。
“Lenna图”的时代彻底结束了?要知道,这张图曾经的火爆程度belike:
“计算机视觉女神”
Lenna图最初是登在1972年11月期的《花花公子》(Playboy)杂
......长按二维码访问原文

CVPR 2024 | 异常检测新网络!InCTRL:学习基于少量正常样本提示的上下文差异实现通用异常检测 2024-04-07 17:13
InCTRL:一种通才异常检测新网络,引入上下文残差学习,在多个数据集上性能表现SOTA!优于WinCLIP等网络,泛化性极强!代码即将开源!单位:新加坡管理大学
点击关注 @CVer官方知乎账号,可以第一时间看到最优质、最前沿的CV、AI、AIGC工作~
快点击进入:异常检测和缺陷检测技术交流平台
文章:https://arxiv.org/pdf/2403.06495
代码:https://github.com/mala-lab/InCTRL
CVPR 2024 论文和开源项目合集请戳—>https://github.com/amusi/CVPR2024-Papers-with-Code
背景:
异常检测(AD)是计算机视觉领域的一个重要任务,其目的是识别出与数据集中大多数样本显著不同的样本。这
......长按二维码访问原文

NVIDIA最新GSNeRF 通用语义神经辐射场与增强的3D场景理解 2024-04-07 15:01

本文提出的GSNeRF方法在解决通用的新视角合成和语义分割问题上具有创新性和实用性。通过将视觉特征提取和深度图预测结合起来,GSNeRF能够在不需要重新训练的情况下泛化到未见过的场景,这在实际应用中具有重要意义。实验结果表明,GSNeRF在真实世界和合成数据集上取得了良好的表现,优于现有方法。这表明GSNeRF是一种有效的方法,可以应用于各种需要新视角合成和语义分割的场景。
1 引言
这篇论文介绍了一种名为GSNeRF的通用语义神经辐射场,旨在同时解决通用化新视角合成和语义分割的问题。GSNeRF通过学习场景的视觉特征、深度信息和语义信息,能够在未见场景上渲染新的视角图像,并生成相应的语义分割掩码。该方法包括两个关键学习阶段:语义地理推理和深度引导视觉渲染。前者用于推导场景的视觉特征和聚合源视图的深度信息,
......长按二维码访问原文







