2021.11.19 更新
下面的代码片段大家可以参考着实现,如果直接拖拽到最新版的yolov5文件夹中运行可能会出错,应该我当时那个代码片段写的比较早,后续yolov5更新了,有些函数名有变动,所以直接运行会出错。我这里有当时和这个代码片段对应的yolov5的代码,但是不太知道这是哪个版本的yolov5。
所以有需要的朋友直接在公众号:万能的小陈后台回复qtv5,获取整个文件夹以及模型,配置环境后可以直接运行,配置环境教程可以参考这里注:压缩包名字为qt5_yolov5_1.0的对应原始版本,也就是下面代码片段可以直接用的,qt5_yolov5_2.0对应的是优化后的。这两个压缩包中的yolov5也不是同一个版本的,一个是2021年上半年的,一个是2021年下半年的
以下是正文
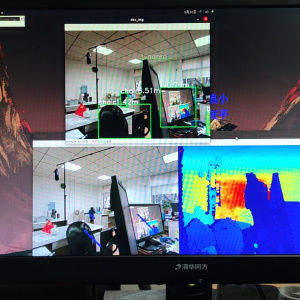
实现效果如下所示,可以检测图片、视频以及摄像头实时检测。
yolov5界面检测效果(pyqt5搭建)
测试平台:显卡1080ti。视频检测是优化后的版本,之前版本也可以视频检测,但是没这么流畅,优化后的版本在公众号:
万能的小陈 后台回复
qtv5。

具体细节实现可以参考上一篇博客:Pyqt搭建YOLOV3目标检测界面(超详细+源代码)
使用的yolov5版本为https://github.com/ultralytics/yolov5
这里直接贴出具体代码。
方法1:共两个文件,
ui_yolov5.py、detect_qt5.py,然后把yolov5的代码下载下来,直接把这两个文件拷贝到yolov5根目录,下载yolov5官方的yolov5s.pt权重,放置根目录,然后运行ui_yolov5.py即可。
方法2:整个yolov5以及两个文件都已上传在github,点这里 。无法访问github的关注公众号:万能的小陈,回复
qtv5即可获取下载链接。(包含所有代码以及权重文件),只需要配置一下环境,配置环境可以参考这里,如果环境配置困难的或者失败的,在公众号后台回复pyqt5即可获取完整环境。
文件1:ui_yolov5.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# @author : ChenAng
# @file : ui_yolov5.py
# @Time : 2021/8/27 10:13
import time
import os
from PyQt5 import QtWidgets, QtCore, QtGui
from PyQt5.QtGui import *
import cv2
import sys
from PyQt5.QtWidgets import *
from detect_qt5 import main_detect,my_lodelmodel
'''摄像头和视频实时检测界面'''
class Ui_MainWindow(QWidget):
def __init__(self, parent=None):
super(Ui_MainWindow, self).__init__(parent)
# self.face_recong = face.Recognition()
self.timer_camera1 = QtCore.QTimer()
self.timer_camera2 = QtCore.QTimer()
self.timer_camera3 = QtCore.QTimer()
self.timer_camera4 = QtCore.QTimer()
self.cap = cv2.VideoCapture()
self.CAM_NUM = 0
# self.slot_init()
self.__flag_work = 0
self.x = 0
self.count = 0
self.setWindowTitle("yolov5检测")
self.setWindowIcon(QIcon(os.getcwd() + '\\data\\source_image\\Detective.ico'))
# self.resize(300, 150) # 宽×高
window_pale = QtGui.QPalette()
window_pale.setBrush(self.backgroundRole(), QtGui.QBrush(
QtGui.QPixmap(os.getcwd() + '\\data\\source_image\\backgroud.jpg')))
self.setPalette(window_pale)
self.setFixedSize(1600, 900)
self.my_model = my_lodelmodel()
self.button_open_camera = QPushButton(self)
self.button_open_camera.setText(u'打开摄像头')
self.button_open_camera.setStyleSheet('''
QPushButton
{text-align : center;
background-color : white;
font: bold;
border-color: gray;
border-width: 2px;
border-radius: 10px;
padding: 6px;
height : 14px;
border-style: outset;
font : 14px;}
QPushButton:pressed
{text-align : center;
background-color : light gray;
font: bold;
border-color: gray;
border-width: 2px;
border-radius: 10px;
padding: 6px;
height : 14px;
border-style: outset;
font : 14px;}
''')
self.button_open_camera.move(10, 40)
self.button_open_camera.clicked.connect(self.button_open_camera_click)
#self.button_open_camera.clicked.connect(self.button_open_camera_click1)
# btn.clicked.connect(self.openimage)
self.btn1 = QPushButton(self)
self.btn1.setText("检测摄像头")
self.btn1.setStyleSheet('''
QPushButton
{text-align : center;
background-color : white;
font: bold;
border-color: gray;
border-width: 2px;
border-radius: 10px;
padding: 6px;
height : 14px;
border-style: outset;
font : 14px;}
QPushButton:pressed
{text-align : center;
background-color : light gray;
font: bold;
border-color: gray;
border-width: 2px;
border-radius: 10px;
padding: 6px;
height : 14px;
border-style: outset;
font : 14px;}
''')
self.btn1.move(10, 80)
self.btn1.clicked.connect(self.button_open_camera_click1)
# print("QPushButton构建")
self.open_video = QPushButton(self)
self.open_video.setText("打开视频")
self.open_video.setStyleSheet('''
QPushButton
{text-align : center;
background-color : white;
font: bold;
border-color: gray;
border-width: 2px;
border-radius: 10px;
padding: 6px;
height : 14px;
border-style: outset;
font : 14px;}
QPushButton:pressed
{text-align : center;
background-color : light gray;
font: bold;
border-color: gray;
border-width: 2px;
border-radius: 10px;
padding: 6px;
height : 14px;
border-style: outset;
font : 14px;}
''')
self.open_video.move(10, 160)
self.open_video.clicked.connect(self.open_video_button)
print("QPushButton构建")
self.btn1 = QPushButton(self)
self.btn1.setText("检测视频文件")
self.btn1.setStyleSheet('''
QPushButton
{text-align : center;
background-color : white;
font: bold;
border-color: gray;
border-width: 2px;
border-radius: 10px;
padding: 6px;
height : 14px;
border-style: outset;
font : 14px;}
QPushButton:pressed
{text-align : center;
background-color : light gray;
font: bold;
border-color: gray;
border-width: 2px;
border-radius: 10px;
padding: 6px;
height : 14px;
border-style: outset;
font : 14px;}
''')
self.btn1.move(10, 200)
self.btn1.clicked.connect(self.detect_video)
print("QPushButton构建")
# btn1.clicked.connect(self.detect())
# btn1.clicked.connect(self.button1_test)
#btn1.clicked.connect(self.detect())
# btn1.clicked.connect(self.button1_test)
btn2 = QPushButton(self)
btn2.setText("返回上一界面")
btn2.setStyleSheet('''
QPushButton
{text-align : center;
background-color : white;
font: bold;
border-color: gray;
border-width: 2px;
border-radius: 10px;
padding: 6px;
height : 14px;
border-style: outset;
font : 14px;}
QPushButton:pressed
{text-align : center;
background-color : light gray;
font: bold;
border-color: gray;
border-width: 2px;
border-radius: 10px;
padding: 6px;
height : 14px;
border-style: outset;
font : 14px;}
''')
btn2.move(10, 240)
btn2.clicked.connect(self.back_lastui)
# 信息显示
self.label_show_camera = QLabel(self)
self.label_move = QLabel()
self.label_move.setFixedSize(100, 100)
# self.label_move.setText(" 11 待检测图片")
self.label_show_camera.setFixedSize(700, 500)
self.label_show_camera.setAutoFillBackground(True)
self.label_show_camera.move(110,80)
self.label_show_camera.setStyleSheet("QLabel{background:#F5F5DC;}"
"QLabel{color:rgb(300,300,300,120);font-size:10px;font-weight:bold;font-family:宋体;}"
)
self.label_show_camera1 = QLabel(self)
self.label_show_camera1.setFixedSize(700, 500)
self.label_show_camera1.setAutoFillBackground(True)
self.label_show_camera1.move(850, 80)
self.label_show_camera1.setStyleSheet("QLabel{background:#F5F5DC;}"
"QLabel{color:rgb(300,300,300,120);font-size:10px;font-weight:bold;font-family:宋体;}"
)
self.timer_camera1.timeout.connect(self.show_camera)
self.timer_camera2.timeout.connect(self.show_camera1)
# self.timer_camera3.timeout.connect(self.show_camera2)
self.timer_camera4.timeout.connect(self.show_camera2)
self.timer_camera4.timeout.connect(self.show_camera3)
self.clicked = False
# self.setWindowTitle(u'摄像头')
self.frame_s=3
'''
# 设置背景图片
palette1 = QPalette()
palette1.setBrush(self.backgroundRole(), QBrush(QPixmap('background.jpg')))
self.setPalette(palette1)
'''
def back_lastui(self):
self.timer_camera1.stop()
self.cap.release()
self.label_show_camera.clear()
self.timer_camera2.stop()
self.label_show_camera1.clear()
cam_t.close()
ui_p.show()
'''摄像头'''
def button_open_camera_click(self):
if self.timer_camera1.isActive() == False:
flag = self.cap.open(self.CAM_NUM)
if flag == False:
msg = QtWidgets.QMessageBox.warning(self, u"Warning", u"请检测相机与电脑是否连接正确",
buttons=QtWidgets.QMessageBox.Ok,
defaultButton=QtWidgets.QMessageBox.Ok)
else:
self.timer_camera1.start(30)
self.button_open_camera.setText(u'关闭摄像头')
else:
self.timer_camera1.stop()
self.cap.release()
self.label_show_camera.clear()
self.timer_camera2.stop()
self.label_show_camera1.clear()
self.button_open_camera.setText(u'打开摄像头')
def show_camera(self): #摄像头左边
flag, self.image = self.cap.read()
dir_path=os.getcwd()
camera_source =dir_path+ "\\data\\test\\2.jpg"
cv2.imwrite(camera_source, self.image)
width = self.image.shape[1]
height = self.image.shape[0]
# 设置新的图片分辨率框架
width_new = 700
height_new = 500
# 判断图片的长宽比率
if width / height >= width_new / height_new:
show = cv2.resize(self.image, (width_new, int(height * width_new / width)))
else:
show = cv2.resize(self.image, (int(width * height_new / height), height_new))
show = cv2.cvtColor(show, cv2.COLOR_BGR2RGB)
showImage = QtGui.QImage(show.data, show.shape[1], show.shape[0],3 * show.shape[1], QtGui.QImage.Format_RGB888)
self.label_show_camera.setPixmap(QtGui.QPixmap.fromImage(showImage))
def button_open_camera_click1(self):
if self.timer_camera2.isActive() == False:
flag = self.cap.open(self.CAM_NUM)
if flag == False:
msg = QtWidgets.QMessageBox.warning(self, u"Warning", u"请检测相机与电脑是否连接正确",
buttons=QtWidgets.QMessageBox.Ok,
defaultButton=QtWidgets.QMessageBox.Ok)
else:
self.timer_camera2.start(30)
self.button_open_camera.setText(u'关闭摄像头')
else:
self.timer_camera2.stop()
self.cap.release()
self.label_show_camera1.clear()
self.button_open_camera.setText(u'打开摄像头')
def show_camera1(self):
flag, self.image = self.cap.read()
dir_path = os.getcwd()
camera_source = dir_path + "\\data\\test\\2.jpg"
cv2.imwrite(camera_source, self.image)
im0, label = main_detect(self.my_model, camera_source)
if label=='debug':
print("labelkong")
width = im0.shape[1]
height = im0.shape[0]
# 设置新的图片分辨率框架
width_new = 700
height_new = 500
# 判断图片的长宽比率
if width / height >= width_new / height_new:
show = cv2.resize(im0, (width_new, int(height * width_new / width)))
else:
show = cv2.resize(im0, (int(width * height_new / height), height_new))
im0 = cv2.cvtColor(show, cv2.COLOR_RGB2BGR)
# print("debug2")
showImage = QtGui.QImage(im0, im0.shape[1], im0.shape[0], 3 * im0.shape[1], QtGui.QImage.Format_RGB888)
self.label_show_camera1.setPixmap(QtGui.QPixmap.fromImage(showImage))
'''视频检测'''
def open_video_button(self):
if self.timer_camera4.isActive() == False:
imgName, imgType = QFileDialog.getOpenFileName(self, "打开视频", "", "*.mp4;;*.AVI;;*.rmvb;;All Files(*)")
self.cap_video = cv2.VideoCapture(imgName)
flag = self.cap_video.isOpened()
if flag == False:
msg = QtWidgets.QMessageBox.warning(self, u"Warning", u"请检测相机与电脑是否连接正确",
buttons=QtWidgets.QMessageBox.Ok,
defaultButton=QtWidgets.QMessageBox.Ok)
else:
# self.timer_camera3.start(30)
self.show_camera2()
self.open_video.setText(u'关闭视频')
else:
# self.timer_camera3.stop()
self.cap_video.release()
self.label_show_camera.clear()
self.timer_camera4.stop()
self.frame_s=3
self.label_show_camera1.clear()
self.open_video.setText(u'打开视频')
def detect_video(self):
if self.timer_camera4.isActive() == False:
flag = self.cap_video.isOpened()
if flag == False:
msg = QtWidgets.QMessageBox.warning(self, u"Warning", u"请检测相机与电脑是否连接正确",
buttons=QtWidgets.QMessageBox.Ok,
defaultButton=QtWidgets.QMessageBox.Ok)
else:
self.timer_camera4.start(30)
else:
self.timer_camera4.stop()
self.cap_video.release()
self.label_show_camera1.clear()
def show_camera2(self): #显示视频的左边
#抽帧
length = int(self.cap_video.get(cv2.CAP_PROP_FRAME_COUNT)) #抽帧
print(self.frame_s,length) #抽帧
flag, self.image1 = self.cap_video.read() #image1是视频的
if flag == True:
if self.frame_s%3==0: #抽帧
dir_path=os.getcwd()
# print("dir_path",dir_path)
camera_source =dir_path+ "\\data\\test\\video.jpg"
cv2.imwrite(camera_source, self.image1)
width=self.image1.shape[1]
height=self.image1.shape[0]
# 设置新的图片分辨率框架
width_new = 700
height_new = 500
# 判断图片的长宽比率
if width / height >= width_new / height_new:
show = cv2.resize(self.image1, (width_new, int(height * width_new / width)))
else:
show = cv2.resize(self.image1, (int(width * height_new / height), height_new))
show = cv2.cvtColor(show, cv2.COLOR_BGR2RGB)
showImage = QtGui.QImage(show.data, show.shape[1], show.shape[0],3 * show.shape[1], QtGui.QImage.Format_RGB888)
self.label_show_camera.setPixmap(QtGui.QPixmap.fromImage(showImage))
else:
self.cap_video.release()
self.label_show_camera.clear()
self.timer_camera4.stop()
self.label_show_camera1.clear()
self.open_video.setText(u'打开视频')
def show_camera3(self):
flag, self.image1 = self.cap_video.read()
self.frame_s += 1
if flag==True:
if self.frame_s % 3 == 0: #抽帧
# face = self.face_detect.align(self.image)
# if face:
# pass
dir_path = os.getcwd()
camera_source = dir_path + "\\data\\test\\video.jpg"
cv2.imwrite(camera_source, self.image1)
# print("im01")
im0, label = main_detect(self.my_model, camera_source)
# print("imo",im0)
# print(label)
if label=='debug':
print("labelkong")
# print("debug")
# im0, label = slef.detect()
# print("debug1")
width = im0.shape[1]
height = im0.shape[0]
# 设置新的图片分辨率框架
width_new = 700
height_new = 500
# 判断图片的长宽比率
if width / height >= width_new / height_new:
show = cv2.resize(im0, (width_new, int(height * width_new / width)))
else:
show = cv2.resize(im0, (int(width * height_new / height), height_new))
im0 = cv2.cvtColor(show, cv2.COLOR_RGB2BGR)
# print("debug2")
showImage = QtGui.QImage(im0, im0.shape[1], im0.shape[0], 3 * im0.shape[1], QtGui.QImage.Format_RGB888)
self.label_show_camera1.setPixmap(QtGui.QPixmap.fromImage(showImage))
'''单张图片检测'''
class picture(QWidget):
def __init__(self):
super(picture, self).__init__()
self.str_name = '0'
self.my_model=my_lodelmodel()
self.resize(1600, 900)
self.setWindowIcon(QIcon(os.getcwd() + '\\data\\source_image\\Detective.ico'))
self.setWindowTitle("yolov5目标检测平台")
window_pale = QtGui.QPalette()
window_pale.setBrush(self.backgroundRole(), QtGui.QBrush(
QtGui.QPixmap(os.getcwd() + '\\data\\source_image\\backgroud.jpg')))
self.setPalette(window_pale)
camera_or_video_save_path = 'data\\test'
if not os.path.exists(camera_or_video_save_path):
os.makedirs(camera_or_video_save_path)
self.label1 = QLabel(self)
self.label1.setText(" 待检测图片")
self.label1.setFixedSize(700, 500)
self.label1.move(110, 80)
self.label1.setStyleSheet("QLabel{background:#7A6969;}"
"QLabel{color:rgb(300,300,300,120);font-size:20px;font-weight:bold;font-family:宋体;}"
)
self.label2 = QLabel(self)
self.label2.setText(" 检测结果")
self.label2.setFixedSize(700, 500)
self.label2.move(850, 80)
self.label2.setStyleSheet("QLabel{background:#7A6969;}"
"QLabel{color:rgb(300,300,300,120);font-size:20px;font-weight:bold;font-family:宋体;}"
)
self.label3 = QLabel(self)
self.label3.setText("")
self.label3.move(1200, 620)
self.label3.setStyleSheet("font-size:20px;")
self.label3.adjustSize()
btn = QPushButton(self)
btn.setText("打开图片")
btn.setStyleSheet('''
QPushButton
{text-align : center;
background-color : white;
font: bold;
border-color: gray;
border-width: 2px;
border-radius: 10px;
padding: 6px;
height : 14px;
border-style: outset;
font : 14px;}
QPushButton:pressed
{text-align : center;
background-color : light gray;
font: bold;
border-color: gray;
border-width: 2px;
border-radius: 10px;
padding: 6px;
height : 14px;
border-style: outset;
font : 14px;}
''')
btn.move(10, 30)
btn.clicked.connect(self.openimage)
btn1 = QPushButton(self)
btn1.setText("检测图片")
btn1.setStyleSheet('''
QPushButton
{text-align : center;
background-color : white;
font: bold;
border-color: gray;
border-width: 2px;
border-radius: 10px;
padding: 6px;
height : 14px;
border-style: outset;
font : 14px;}
QPushButton:pressed
{text-align : center;
background-color : light gray;
font: bold;
border-color: gray;
border-width: 2px;
border-radius: 10px;
padding: 6px;
height : 14px;
border-style: outset;
font : 14px;}
''')
btn1.move(10, 80)
# print("QPushButton构建")
btn1.clicked.connect(self.button1_test)
btn3 = QPushButton(self)
btn3.setText("")
btn3.setStyleSheet('''
QPushButton
{text-align : center;
background-color : white;
font: bold;
border-color: gray;
border-width: 2px;
border-radius: 10px;
padding: 6px;
height : 14px;
border-style: outset;
font : 14px;}
QPushButton:pressed
{text-align : center;
background-color : light gray;
font: bold;
border-color: gray;
border-width: 2px;
border-radius: 10px;
padding: 6px;
height : 14px;
border-style: outset;
font : 14px;}
''')
btn3.move(10, 160)
btn3.clicked.connect(self.camera_find)
self.imgname1='0'
def camera_find(self):
ui_p.close()
cam_t.show()
def openimage(self):
imgName, imgType = QFileDialog.getOpenFileName(self, "打开图片", "", "*.jpg;;*.png;;All Files(*)")
if imgName!='':
self.imgname1=imgName
# print("imgName",imgName,type(imgName))
im0=cv2.imread(imgName)
width = im0.shape[1]
height = im0.shape[0]
# 设置新的图片分辨率框架
width_new = 700
height_new = 500
# 判断图片的长宽比率
if width / height >= width_new / height_new:
show = cv2.resize(im0, (width_new, int(height * width_new / width)))
else:
show = cv2.resize(im0, (int(width * height_new / height), height_new))
im0 = cv2.cvtColor(show, cv2.COLOR_RGB2BGR)
showImage = QtGui.QImage(im0, im0.shape[1], im0.shape[0], 3 * im0.shape[1], QtGui.QImage.Format_RGB888)
self.label1.setPixmap(QtGui.QPixmap.fromImage(showImage))
# jpg = QtGui.QPixmap(imgName).scaled(self.label1.width(), self.label1.height())
# self.label1.setPixmap(jpg)
def button1_test(self):
if self.imgname1!='0':
QApplication.processEvents()
im0,label=main_detect(self.my_model,self.imgname1)
QApplication.processEvents()
width = im0.shape[1]
height = im0.shape[0]
# 设置新的图片分辨率框架
width_new = 700
height_new = 500
# 判断图片的长宽比率
if width / height >= width_new / height_new:
show = cv2.resize(im0, (width_new, int(height * width_new / width)))
else:
show = cv2.resize(im0, (int(width * height_new / height), height_new))
im0 = cv2.cvtColor(show, cv2.COLOR_RGB2BGR)
image_name = QtGui.QImage(im0, im0.shape[1], im0.shape[0], 3 * im0.shape[1], QtGui.QImage.Format_RGB888)
# label=label.split(' ')[0] #label 59 0.96 分割字符串 取前一个
self.label2.setPixmap(QtGui.QPixmap.fromImage(image_name))
# jpg = QtGui.QPixmap(image_name).scaled(self.label1.width(), self.label1.height())
# self.label2.setPixmap(jpg)
else:
QMessageBox.information(self, '错误', '请先选择一个图片文件', QMessageBox.Yes, QMessageBox.Yes)
if __name__ == '__main__':
app = QApplication(sys.argv)
splash = QSplashScreen(QPixmap(".\\data\\source_image\\logo.png"))
# 设置画面中的文字的字体
splash.setFont(QFont('Microsoft YaHei UI', 12))
# 显示画面
splash.show()
# 显示信息
splash.showMessage("程序初始化中... 0%", QtCore.Qt.AlignLeft | QtCore.Qt.AlignBottom, QtCore.Qt.black)
time.sleep(0.3)
splash.showMessage("正在加载模型配置文件...60%", QtCore.Qt.AlignLeft | QtCore.Qt.AlignBottom, QtCore.Qt.black)
cam_t=Ui_MainWindow()
splash.showMessage("正在加载模型配置文件...100%", QtCore.Qt.AlignLeft | QtCore.Qt.AlignBottom, QtCore.Qt.black)
ui_p = picture()
ui_p.show()
splash.close()
sys.exit(app.exec_())
文件2:detect_qt5.py
import argparse
import time
from pathlib import Path
import cv2
import torch
import torch.backends.cudnn as cudnn
from models.experimental import attempt_load
from utils.datasets import LoadStreams, LoadImages
from utils.general import check_img_size, check_requirements, check_imshow, non_max_suppression, apply_classifier, \
scale_coords, xyxy2xywh, strip_optimizer, set_logging, increment_path, save_one_box
from utils.plots import colors, plot_one_box
from utils.torch_utils import select_device, load_classifier, time_synchronized
def my_lodelmodel():
parser = argparse.ArgumentParser()
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--weights', nargs='+', type=str, default='yolov5s.pt',
help='model.pt path(s)')
opt = parser.parse_args()
device = select_device(opt.device)
'''
打包为exe 时候 这个select——device可能会出错,所以替换为 # device ='cuda:0'
'''
# device ='cuda:0'
print("device", device)
weights = opt.weights
# Load model
model = attempt_load(weights, map_location=device) # load FP32 model
return model
@torch.no_grad()
def detect(opt, my_model, source_open):
source, weights, view_img, save_txt, imgsz = opt.source, opt.weights, opt.view_img, opt.save_txt, opt.img_size
save_img = not opt.nosave and not source.endswith('.txt') # save inference images
webcam = source.isnumeric() or source.endswith('.txt') or source.lower().startswith(
('rtsp://', 'rtmp://', 'http://', 'https://'))
label = 'debug' #
# Directories
save_dir = increment_path(Path(opt.project) / opt.name, exist_ok=opt.exist_ok) # increment run
(save_dir / 'labels' if save_txt else save_dir).mkdir(parents=True, exist_ok=True) # make dir
# Initialize
set_logging()
device = select_device(opt.device)
half = opt.half and device.type != 'cpu' # half precision only supported on CUDA
# Load model
# model = attempt_load(weights, map_location=device) # load FP32 model
model = my_model
stride = int(model.stride.max()) # model stride
imgsz = check_img_size(imgsz, s=stride) # check img_size
names = model.module.names if hasattr(model, 'module') else model.names # get class names
if half:
model.half() # to FP16
# Second-stage classifier
classify = False
if classify:
modelc = load_classifier(name='resnet101', n=2) # initialize
modelc.load_state_dict(torch.load('weights/resnet101.pt', map_location=device)['model']).to(device).eval()
# Set Dataloader
vid_path, vid_writer = None, None
source = source_open
if webcam:
view_img = check_imshow()
cudnn.benchmark = True # set True to speed up constant image size inference
dataset = LoadStreams(source, img_size=imgsz, stride=stride)
else:
dataset = LoadImages(source, img_size=imgsz, stride=stride)
# Run inference
if device.type != 'cpu':
model(torch.zeros(1, 3, imgsz, imgsz).to(device).type_as(next(model.parameters()))) # run once
t0 = time.time()
for path, img, im0s, vid_cap in dataset:
img = torch.from_numpy(img).to(device)
img = img.half() if half else img.float() # uint8 to fp16/32
img /= 255.0 # 0 - 255 to 0.0 - 1.0
if img.ndimension() == 3:
img = img.unsqueeze(0)
# Inference
t1 = time_synchronized()
pred = model(img, augment=opt.augment)[0]
# Apply NMS
pred = non_max_suppression(pred, opt.conf_thres, opt.iou_thres, opt.classes, opt.agnostic_nms,
max_det=opt.max_det)
t2 = time_synchronized()
# Apply Classifier
if classify:
pred = apply_classifier(pred, modelc, img, im0s)
# Process detections
for i, det in enumerate(pred): # detections per image
if webcam: # batch_size >= 1
p, s, im0, frame = path[i], f'{i}: ', im0s[i].copy(), dataset.count
else:
p, s, im0, frame = path, '', im0s.copy(), getattr(dataset, 'frame', 0)
p = Path(p) # to Path
save_path = str(save_dir / p.name) # img.jpg
txt_path = str(save_dir / 'labels' / p.stem) + ('' if dataset.mode == 'image' else f'_{frame}') # img.txt
s += '%gx%g ' % img.shape[2:] # print string
gn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # normalization gain whwh
imc = im0.copy() if opt.save_crop else im0 # for opt.save_crop
if len(det):
# Rescale boxes from img_size to im0 size
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], im0.shape).round()
# Print results
for c in det[:, -1].unique():
n = (det[:, -1] == c).sum() # detections per class
s += f"{n} {names[int(c)]}{'s' * (n > 1)}, " # add to string
# Write results
for *xyxy, conf, cls in reversed(det):
if save_txt: # Write to file
xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
line = (cls, *xywh, conf) if opt.save_conf else (cls, *xywh) # label format
with open(txt_path + '.txt', 'a') as f:
f.write(('%g ' * len(line)).rstrip() % line + '\n')
if save_img or opt.save_crop or view_img: # Add bbox to image
c = int(cls) # integer class
label = None if opt.hide_labels else (names[c] if opt.hide_conf else f'{names[c]} {conf:.2f}')
plot_one_box(xyxy, im0, label=label, color=colors(c, True), line_thickness=opt.line_thickness)
# if opt.save_crop:
# save_one_box(xyxy, imc, file=save_dir / 'crops' / names[c] / f'{p.stem}.jpg', BGR=True)
#
# # Print time (inference + NMS)
# print(f'{s}Done. ({t2 - t1:.3f}s)')
# Stream results
# if view_img:
# cv2.imshow(str(p), im0)
# cv2.waitKey(1) # 1 millisecond
# Save results (image with detections)
# if save_img:
# if dataset.mode == 'image':
# cv2.imwrite(save_path, im0)
# else: # 'video' or 'stream'
# if vid_path != save_path: # new video
# vid_path = save_path
# if isinstance(vid_writer, cv2.VideoWriter):
# vid_writer.release() # release previous video writer
# if vid_cap: # video
# fps = vid_cap.get(cv2.CAP_PROP_FPS)
# w = int(vid_cap.get(cv2.CAP_PROP_FRAME_WIDTH))
# h = int(vid_cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
# else: # stream
# fps, w, h = 30, im0.shape[1], im0.shape[0]
# save_path += '.mp4'
# vid_writer = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc(*'mp4v'), fps, (w, h))
# vid_writer.write(im0)
# if save_txt or save_img:
# s = f"\n{len(list(save_dir.glob('labels/*.txt')))} labels saved to {save_dir / 'labels'}" if save_txt else ''
# print(f"Results saved to {save_dir}{s}")
print(f'Done. ({time.time() - t0:.3f}s)')
return im0,label
def main_detect(my_model,source_open):
# if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--weights', nargs='+', type=str, default='yolov5s.pt', help='model.pt path(s)')
parser.add_argument('--source', type=str, default='data/images', help='source') # file/folder, 0 for webcam
parser.add_argument('--img-size', type=int, default=640, help='inference size (pixels)')
parser.add_argument('--conf-thres', type=float, default=0.25, help='object confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.45, help='IOU threshold for NMS')
parser.add_argument('--max-det', type=int, default=1000, help='maximum number of detections per image')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', action='store_true', help='display results')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
parser.add_argument('--save-crop', action='store_true', help='save cropped prediction boxes')
parser.add_argument('--nosave', action='store_true', help='do not save images/videos')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --class 0, or --class 0 2 3')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--update', action='store_true', help='update all models')
parser.add_argument('--project', default='runs/detect', help='save results to project/name')
parser.add_argument('--name', default='exp', help='save results to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--line-thickness', default=3, type=int, help='bounding box thickness (pixels)')
parser.add_argument('--hide-labels', default=False, action='store_true', help='hide labels')
parser.add_argument('--hide-conf', default=False, action='store_true', help='hide confidences')
parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
opt = parser.parse_args()
print(opt)
im0, label = detect(opt, my_model, source_open)
print("detect")
return im0, label
版权声明:本文为CSDN博主「万能的小陈」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_42035347/article/details/119960202