文章目录[隐藏]
- 视觉招聘小黑板
- 行业资讯
- 自动化领域卡脖子问题是什么? 2023-03-18 12:16
- 机器人革命迟迟没有到来的原因是什么? 2019-09-16 18:57
- 英特尔发布《2023 中国光伏行业机器视觉系统应用白皮书》,全面赋能中国制造业转型升级--机器视觉网 2023-10-16 14:35:07
- TeledyneFlir和Ansys合作推进热成像技术在驾驶辅助和自动驾驶系统中的集成应用--机器视觉网 2023-10-16 14:25:05
- 系统集成:将视觉系统集成到生产工艺中--机器视觉网 2023-10-17 14:54:11
- 3D视觉技术在物流行业五大场景的应用--机器视觉网 2023-10-16 15:51:51
- Snappy Wide 荣获 VSDC Innovators Awards 2023 金奖―新闻频道- 视觉系统设计 2023/10/16 23:54:33
- 梅卡曼德AI+3D视觉助力智慧物流―新闻频道- 视觉系统设计 2023/10/17 21:05:00
- 度申科技将携全系列线阵、面阵工业相机亮相VisionCon成都视觉会议―新闻频道- 视觉系统设计 2023/10/17 21:08:32
- [T-PAMI2023] Temporal Perceiver: 通用时序边界检测方法 2023-10-17 14:00
- ICCV 2023 | 论文速递:EgoObjects:用于细粒度物体理解的大规模自我中心数据集 2023-10-16 20:22
- ICCV 2023 | 论文速递:DiffIR:高效的图像恢复扩散模型 2023-10-16 20:17
- TRO 2023|iSimLoc:利用虚拟图像对未看到的环境进行视觉全局定位 2023-10-16 09:40
- 机器视觉新手入门必看:图像处理基础知识 2023-10-17 16:22
- 使用目标之间的先验关系提升目标检测器性能 2023-10-17 12:24
- 港科大提出适用于夜间场景语义分割的无监督域自适应新方法 2023-10-16 00:16
- Frequency-Aware Re-parameterization:一个好像有用但并不多的小trick 2023-10-17 12:08
- 强化学习与视觉语言模型之间的碰撞,UC伯克利提出语言奖励调节LAMP框架 2023-10-17 12:00
- 【arXiv 2310】BAAF:一种用于医学超声图像分割任务的基准注意力自适应框架(BAAF) 2023-10-16 15:03
- 域自适应语义分割调研(一) 2023-10-17 15:49
- 【ICLR2023】Cross-Layer Retrospective Retrieving via Layer Attention: 2023-10-16 23:22
- 普林斯顿陈丹琦团队:手把手教你给羊驼剪毛,5%成本拿下SOTA 2023-10-16 12:10
- 计算机视觉中人脸识别方向和医学图像分割方向哪个比较有前景? 2023-10-16 08:00
- 硕士毕业论文马上开题了,准备做医学图像分割方向,请问分割哪个部位好搞呢,创新点该怎么想? 2023-10-16 07:53
- Ferret: 一个以开放词汇去理解图像的多模态大语言模型 2023-10-17 02:40
- GPT-4 Vision Prompt Injection: 2023-10-16T17:42:01.000Z
- Top 5 AI papers of September 2023: 2023-10-17T13:00:00+00:00
- 百度开大会,王小川伺机宣布新融资 2023-10-17 19:44
- 百度“最强”大模型发布,我们第一时间实测了一波 2023-10-17 19:04
- PyTorch官方认可!斯坦福博士新作:长上下文LLM推理速度提8倍 2023-10-17 15:28
- 7B羊驼战胜540B“谷歌版GPT”,MIT用博弈论调教大模型,无需训练就能完成 2023-10-17 14:15
- AirPods可以“读脑”了?还是能同时监测汗液乳酸浓度的那种|Nature 2023-10-16 17:08
- 全面的中文大语言模型评测来啦!香港中文大学研究团队发布 2023-10-16 12:40
- 大语言模型击败扩散模型!视频图像生成双SOTA,谷歌CMU最新研究 2023-10-16 12:31
视觉招聘小黑板
机器视觉算法工程师 ,1.2-1.8万·14薪武汉·洪山区3-4年本科,医疗设备/器械民营
机器视觉工程师 ,1-1.8万苏州2年本科,电子技术/半导体/集成电路民营
机器视觉算法工程师 ,1.5-2.7万深圳·南山区3-4年本科,计算机软件民营
销售工程师(机器视觉) ,1-2万东莞·南城区3-4年大专,仪器仪表/工业自动化民营
机器视觉工程师 ,1-2万深圳·龙华区3-4年本科,仪器仪表/工业自动化民营
机器视觉调试工程师 ,8千-1.2万厦门·翔安区1年大专,电子技术/半导体/集成电路民营
机器视觉销售工程师 ,1.6-2.1万苏州·吴中区1年大专,仪器仪表/工业自动化已上市
算法工程师(图像/AI/机器视觉/深度学习) ,1.5-2万广州·南沙区3-4年本科,计算机软件创业公司
机器视觉调试工程师 ,1.2-1.8万北京·通州区3-4年大专,仪器仪表/工业自动化民营
机器视觉调试工程师 ,8千-1.2万昆山1年大专,电子技术/半导体/集成电路民营
机器视觉算法工程师 ,1.5-2.5万成都·高新区3-4年本科,仪器仪表/工业自动化已上市
高薪机器视觉算法工程师(五险一金+带薪年假) ,8千-1.5万无锡·滨湖区3-4年本科,机械/设备/重工民营
机器视觉调试工程师 ,8千-1.5万成都·龙泉驿区3-4年大专,仪器仪表/工业自动化民营
机器视觉调试工程师 ,8千-1.2万惠州·大亚湾区2年大专,电子技术/半导体/集成电路民营
机器视觉应用工程师 ,1.3-2万上海·松江区3-4年大专,仪器仪表/工业自动化民营
机器视觉工程师 ,1-1.5万·13薪武汉·洪山区3-4年本科,快速消费品(食品、饮料、化妆品)民营
机器视觉调试工程师 ,8千-1.5万重庆·渝北区3-4年大专,仪器仪表/工业自动化民营
机器视觉软件工程师 ,1.6-2.1万长沙·浏阳市3-4年大专,机械/设备/重工民营
机器视觉工程师 ,2.5-4万上海·普陀区5-7年硕士,新能源已上市
机器视觉工程师 ,1.3-2万苏州·高新区5-7年本科,机械/设备/重工外资(欧美)
欲了解详情,请在公众号后台回复:231017
行业资讯
自动化领域卡脖子问题是什么? 2023-03-18 12:16
自动化有点大,单纯从控制这边说。
最大的差距应该是基础硬件和基础软件,比如波士顿动力搞的那个液压驱动,然后各种工业软件啥的,这个某种角度也不是自动化或者控制的问题。
然后有一些方向感觉还是有滞后的,比如国外目前比较新的热门方向应该是Learning for Control,这个我感觉国内目前还是有比较大的滞后。不过这种理论工作上的欠债相对好补。
比较难补的方向是理论和实验要结合的。比如个人比较关注的高敏捷运动控制,感觉差距很大。比如UZH做的四旋翼无人机竞速,MIT做的那种固定翼无人机的Perching(据说好像已经用到美国的军用无人机上面了),还有各种无人驾驶极限操控问题(比如Georgia Tech的Autorally, Stanford的Shelley,ETH的AMZ,还有DARPA在推的Racer
......长按二维码访问原文

机器人革命迟迟没有到来的原因是什么? 2019-09-16 18:57

先抛结论:在我看来,之所以我们心目中的「机器人革命」迟迟没有到来,是因为人类对自身属性过于自信,以至于在发展的过程中,不知不觉地找错了方向,从而走了一些弯路。
最近有传言,《黑客帝国》要拍第四部了。作为非常经典的科幻电影,黑客帝国中机器人的形象也代表了很大一部分人对机器人的想象:有头、有五官、有四肢。除了脸上的器官有点奇怪,让人一眼就看出是机器人以外,其他特征和人相差无几。
《黑客帝国动画版》中的机器人形象
事实上,现在也有不少优秀的科技公司,把科研攻关的重点放在了「人形机器人」上。比如大名鼎鼎的 Boston Dynamics[1],在对「人形机器人」的探索中就取得了非常大的突破,之前就发布过它「跳跃障碍」和「后空翻」的视频,最近又发布了它「识别复杂地形」和「跑酷」的视频,让人非常惊叹。
Boston
......长按二维码访问原文

英特尔发布《2023 中国光伏行业机器视觉系统应用白皮书》,全面赋能中国制造业转型升级--机器视觉网 2023-10-16 14:35:07

2023-10-16 14:35:07 来源: 中国机器视觉网
在工业数字化转型与“双碳”目标的引领下,制造业、新能源产业众多领域,正在以前所未有的速度步入工业 4.0 时代。在全球“碳中和”的大趋势推动下,光伏发电产业作为目前最具发展潜力的可再生能源产业之一,整体发展迅猛。
自动化、智能化生产设备作为光伏制造企业的核心资产,其性能、技术发展对光伏产品的生产效率、产品质量、生产成本有着重要影响。为了进一步提高光伏产品的光电转化率,实现生产的降本增效,搭载 AI 技术的机器视觉克服人工目检缺陷,实现了生产全过程的精准定位识别、质量检测、数据管理,在光伏生产领域广泛应用。
然而,当前机器视觉系统在光伏产线的覆盖率尚未达到饱和,部分工艺环节仍处于技术攻关阶段,诸多工业场景下的技术应用仍存在较大的突破空间。为此,
......长按二维码访问原文

TeledyneFlir和Ansys合作推进热成像技术在驾驶辅助和自动驾驶系统中的集成应用--机器视觉网 2023-10-16 14:25:05

TeledyneFlir和Ansys合作推进热成像技术在驾驶辅助和自动驾驶系统中的集成应用
2023-10-16 14:25:05 来源: 中国机器视觉网
帮助车辆改善在所有天气和照明条件下的环境感知能力,对于减少全球创纪录的车祸死亡人数以及实现更安全的自动驾驶汽车(AV)系统至关重要。2023年6月,美国州长公路安全协会(GHSA)预计,2022年全美有7508名行人死于交通事故,这是自1981年以来美国行人死亡人数最高的一年。
车辆环境感知工程师可以利用热成像数据和计算机模拟来提高系统性能,加速高级驾驶辅助系统(ADAS)和AV系统的开发
目前,将长波红外数据集成到车辆现有传感器套件中,成为改进ADAS和AV系统的有效手段之一。热探测能够填补车辆环境感知能力的缺陷,通过与可见光相机、雷达以及激光雷达
......长按二维码访问原文

系统集成:将视觉系统集成到生产工艺中--机器视觉网 2023-10-17 14:54:11

2023-10-17 14:54:11 来源: 中国机器视觉网
稳定、均一的质量检验工作在制造过程中扮演者关键角色。如今,越来越多的制造厂开始配备多个机器视觉检测系统,覆盖整条生产链,将质量水平提升到了前所未有的高度。在制造环境中实现系统间信息交换的自动化是系统集成的精髓,可提高生产力和质量、降低成本与浪费、实现整体创新等。我在担任销售与应用支持经理期间,曾和许多系统集成商共事,他们靠我们的产品来为其视觉系统的开发提供支持。我们和密歇根州大急流城的系统集成商Active Inspection公司的创始人兼总裁Arun Dalmia博士进行过深度交流,并向他询问了系统集成在打造健壮、可持续的制造工艺当中起到的作用以及系统集成商的角色发展等问题。
在工业机器视觉与机器学习方案的设计开发领域,Active Ins
......长按二维码访问原文

3D视觉技术在物流行业五大场景的应用--机器视觉网 2023-10-16 15:51:51

2023-10-16 15:51:51 来源: 中国机器视觉网
3D视觉技术是指基于三维立体感知的计算机视觉技术,通过使用3D相机和传感器,可以获取和分析物体的三维形状、结构和尺寸等信息。在物流行业中,3D视觉技术被广泛应用于货物分类和分拣、货物体积测量和尺寸验证、高密度堆垛和仓库管理、货物损坏和质量控制以及包裹识别和跟踪等方面。
货物分类和分拣
在物流行业中,货物的分类和分拣是一个基本但关键的任务。传统上,人工分拣需要大量的人力和时间,并且容易出现错误。然而,通过使用3D视觉技术,可以实现高效的货物分类和分拣,从而改善这一问题。
3D视觉技术通过3D相机和传感器,可以准确地捕捉和分析货物的三维形状、尺寸和体积等信息,从而精确地将其分配到正确的位置,大大提高了分拣的速度和准确性。例如,当货物进入分拣区域
......长按二维码访问原文

Snappy Wide 荣获 VSDC Innovators Awards 2023 金奖―新闻频道- 视觉系统设计 2023/10/16 23:54:33

从2D到3D、从黑白到彩色,从低分辨率到高分辨率、从静态图像到动态影像,机器视觉不断进行技术突破。对于企业而言,如何实现更高产能以满足现代化物流运营中心不断增长的产能需求?我们想,唯有自动化系统才是解答。其中,机器视觉能够很好替代人工完成生产和物流中的条码、字符、图像精准识别工作,可以实现快速、准确、高效提取商品的信息,对产品进行高效率、高质量、精准化的质量检测,助力生产和物流向智能化变革升级。
2023年9月22日,由《Vision Systems Design》举办的《视觉系统设计》创新奖 2023(VSDC Innovators Awards 2023)于上海成功举办。多年来,Innovators Awards在来在海外享有盛誉,今年大赛经过 9 位专家评委及近 40 位业界大众评委参与打分评定,最终逐
......长按二维码访问原文

梅卡曼德AI+3D视觉助力智慧物流―新闻频道- 视觉系统设计 2023/10/17 21:05:00

10月24日,亚洲国际物流技术与运输系统展览会(CeMAT ASIA 2023)将在上海新国际博览中心盛大开启。作为亚太地区物流行业年度盛会,此次CeMAT展出面积超80000�O,将汇集800+国内外一线品牌,为预计到场的14万观众展示高端物流技术。
本次是梅卡曼德连续第四次参展,我们将携物流场景全新应用3D视觉引导快递供包亮相CeMAT现场。同时,我们也将为现场观众展示针对透明物体、纸箱、麻袋、周转箱等物流行业典型物体的先进3D成像和识别技术。在此,我们诚邀您莅临CeMAT ASIA 2023梅卡曼德展位(W3-B2),了解梅卡曼德最新AI+3D视觉技术,共赴智慧物流之旅!
展会亮点
物流场景高速快递供包应用首发
助力物流等领域智能化升级
梅卡曼德AI+3D视觉技术在物流搬运、分拣场景应用广泛。此
......长按二维码访问原文

度申科技将携全系列线阵、面阵工业相机亮相VisionCon成都视觉会议―新闻频道- 视觉系统设计 2023/10/17 21:08:32
10月19日,VisionCon视觉系统设计技术会议将在成都盛大开幕。作为国内工业相机头部企业,度申科技将携高性能4K、8K、12K、16K线阵及全系列面阵工业相机亮相此次会议,与行业精英共同探讨机器视觉的未来发展。
本次会议主题为“机器视觉助中国制造业加速智能化进程”,议题内容涉及多个方向。想来现场和度申面对面交流、合作,即刻扫码预约。
会议信息
......长按二维码访问原文

[T-PAMI2023] Temporal Perceiver: 通用时序边界检测方法 2023-10-17 14:00
本文介绍一下今年我们组被T-PAMI 2023收录的时序边界检测工作 Temporal Perceiver: A General Architecture for Arbitrary Boundary Detection。
论文链接:
代码地址:
TL;DR 我们提出一种对视频中一类因为语义不连贯而自然产生的时序边界 (Generic Boundary) 的通用检测方法,基于Transformer Decoder建立了一个编码器-解码器结构。在编码阶段,我们利用一组可学习的隐查询量 (Latent Queries) 来压缩冗余的输入时序特征为边界特征 (Boundary Queries) 和上下文特征 (Context Queries),在线性复杂度内有效完成特征压缩;在解码阶段,我们采用另一组可
......长按二维码访问原文

ICCV 2023 | 论文速递:EgoObjects:用于细粒度物体理解的大规模自我中心数据集 2023-10-16 20:22

在自我中心视觉数据中的物体理解可以说是自我中心视觉中的一个基础研究课题。然而,现有的物体数据集要么不是自我中心的,要么在物体类别、视觉内容和注释粒度方面存在限制。在这项工作中引入了EgoObjects,一个用于细粒度物体理解的大规模自我中心数据集。其试验版包含了来自50多个国家的250名参与者使用4种可穿戴设备收集的超过9,000个视频,以及来自368个物体类别的超过650,000个物体注释。与先前的数据集不同,EgoObjects还为每个物体附上了一个实例级别的标识符,并包括超过14,000个独特的物体实例。EgoObjects旨在捕捉相同物体在不同背景复杂性、周围物体、距离、光照和相机运动下的情况。与数据收集同时,通过开发多阶段联合注释流程进行了数据注释,以适应数据集的不断增长。为了启动关于EgoObjec
......长按二维码访问原文

ICCV 2023 | 论文速递:DiffIR:高效的图像恢复扩散模型 2023-10-16 20:17
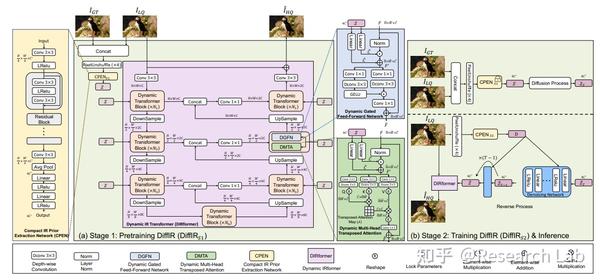
扩散模型(DM)通过将图像合成过程建模成去噪网络的顺序应用,取得了SOTA性能。然而,与图像合成不同,图像恢复(IR)对生成与地面实况一致的结果有强烈的约束。因此,对于IR来说,传统的DM在大型模型上运行大量迭代以估计整个图像或特征图是低效的。为了解决这个问题,本文提出了一种高效的IR扩散模型(DiffIR),它由紧凑的IR先验提取网络(CPEN)、动态IR变换器(DIRformer)和去噪网络组成。具体而言,DiffIR有两个训练阶段:预训练和训练DM。在预训练中,将地面实况图像输入CPEN,以捕获紧凑的IR先验表示(IPR),以指导DIRformer。在第二阶段,训练DM直接估计与预训练的CPEN相同的IRP,只使用LQ图像。观察到,由于IPR只是一个紧凑的向量,DiffIR可以使用比传统DM更少的迭代来获
......长按二维码访问原文

TRO 2023|iSimLoc:利用虚拟图像对未看到的环境进行视觉全局定位 2023-10-16 09:40
以下内容来自小六的机器人SLAM学习圈知识星球每日更新内容
点击领取学习资料 → 机器人SLAM学习资料大礼包
#论文##开源# TRO 2023|iSimLoc:利用虚拟图像对未看到的环境进行视觉全局定位
【iSimLoc: Visual Global Localization for Previously Unseen Environments With Simulated Images】
作者单位:卡耐基梅隆大学与加州大学圣地亚哥分校
开源代码:GitHub: Let’s build from here · GitHub MetaSLAM/iSimLocServer
文章链接:iSimLoc: Visual Global Localization for Previously...
相机由于
......长按二维码访问原文

机器视觉新手入门必看:图像处理基础知识 2023-10-17 16:22
1、 数字图像 是什么:
数字图像是二维图像用有限数字数值像素的表示,是可以用数字计算机或数字电路存储和处理的图像。
2、 数字图像处理 包括内容:
图像数字化;图像变换;图像增强;图像恢复;图像压缩编码;图像分割;图像分析与描述;图像的识别分类。
3、 数字图像处理 系统包括部分:
输入(采集)--存储--输出(显示)--通信--图像处理与分析。
4、从“模拟图像”到“数字图像”要经过的步骤有:
图像信息的获取;图像信息的存储;图像信息处理;图像信息的传输;图像信息的输出和显示。
5、数字图像1600x1200什么意思?
表示空间分辨率为1600x1200像素;灰度范围0~255指图像的256阶灰阶,不同程度的灰色来表示图像的明暗关系。
6、图像的数字化包括哪两个过程?
采样;量化
采
......长按二维码访问原文

使用目标之间的先验关系提升目标检测器性能 2023-10-17 12:24
精华置顶
墙裂推荐!小白如何1个月系统学习CV核心知识:链接
点击@CV计算机视觉,关注更多CV干货
点击加入—>CV计算机视觉交流群
今天跟大家分享阿姆斯特丹大学等提出的用于提升目标检测和实例分割性能的新方法RP-FEM,该方法将目标之间位置的先验关系融入到feature中。
1.动机
在认知心理学中,人类通过理解物体之间的关系来感知世界。通过认识物体之间的关联,建立对环境的心理表征,对可能的行为进行推断,实现对这些行为结果的预测。从简单的日常活动(如过马路)到更复杂的任务(如理解自然语言、计划和决策)。
同样,在计算机视觉领域,物体之间的关系已经成为一个重要的研究方向。利用对象间的关系,计算机视觉系统可以增强图像中目标检测和分割的能力,推理它们之间的关系,构建更复杂的应用程序实现对视觉信息的深
......长按二维码访问原文

港科大提出适用于夜间场景语义分割的无监督域自适应新方法 2023-10-16 00:16
精华置顶
墙裂推荐!小白如何1个月系统学习CV核心知识:链接
点击@CV计算机视觉,关注更多CV干货
点击加入—>CV计算机视觉交流群
跟大家分享港科大提出的无监督域自适应夜间场景语义分割方法,该方法对夜间的动态目标和小目标做了针对性的优化。
论文标题:Towards Dynamic and Small Objects Refinement for Unsupervised Domain Adaptative Nighttime Semantic Segmentation
机构:港科大
论文地址: https:// arxiv.org/pdf/2310.0474 7.pdf
工程主页: https:// rorisis.github.io/DSRNS S/
代码即将开源
关键词:语义分割、无
......长按二维码访问原文

Frequency-Aware Re-parameterization:一个好像有用但并不多的小trick 2023-10-17 12:08
F-principle/Spectral bias
神经网络训练中有个现象,就是网络倾向于先学习低频成分,再学习高频成分,这被称作F-Principle或者是Spectral Bias。下面是一个例子:
用一个全连接DNN去拟合camera man
关于这个现象,上交的@许志钦老师有很多的研究,如果想了解更多可以参考,比如这篇overview:2201.07395
Optimization in Frequency Domain
这个现象大多数时候很难评判是“好”还是“坏”,但是由于倾向性的存在,如果有些任务是对高频信息成分更加敏感的话,无疑这个现象是不利于训练收敛速度的。
既然是频率敏感的现象,有没有办法利用频率解决这件事呢?比方说,直接在频域进行优化?
Frequency-Aware Re-p
......长按二维码访问原文

强化学习与视觉语言模型之间的碰撞,UC伯克利提出语言奖励调节LAMP框架 2023-10-17 12:00
公众号:将门创投(thejiangmen)
作者:seven_
在强化学习(RL)领域,一个重要的研究方向是如何巧妙的设计模型的奖励机制,传统的方式是设计手工奖励函数,并根据模型执行任务的结果来反馈给模型。后来出现了以学习奖励函数(learned reward functions,LRF)为代表的稀疏奖励机制,这种方式通过数据驱动学习的方式来确定具体的奖励函数,这种方法在很多复杂的现实任务中展现出了良好的性能。
本文介绍一篇来自UC伯克利研究团队的最新论文,本文作者质疑,使用LRF来代替任务奖励的方式是否合理。因此本文以当下火热的视觉语言模型(Vision-Language Models,VLMs)的zero-shot能力为研究对象,作者认为这种zero-shot能力可以作为RL模型的预训练监督信号,而不
......长按二维码访问原文

【arXiv 2310】BAAF:一种用于医学超声图像分割任务的基准注意力自适应框架(BAAF) 2023-10-16 15:03
提出了一个更通用和稳健的基准注意力自适应框架(BAAF),以帮助医生更快、更准确地分割或诊断超声图像中的病变和组织,并减少对人类准确性和精度的依赖。
BAAF: A Benchmark Attention Adaptive Framework for Medical Ultrasound Image Segmentation Tasks
Gongping Chen, Lei Zhao, Xiaotao Yin, Liang Cui, Jianxun Zhang, Yu Dai
The AI-based assisted diagnosis programs have been widely investigated on medical ultrasound images. Complex scenari
......长按二维码访问原文

域自适应语义分割调研(一) 2023-10-17 15:49
未完待续~~~
MIC: Masked Image Consistency for Context-Enhanced Domain Adaptation
本文提出了一个遮掩图像一致性(MIC)模块,通过增强UDA学习的目标域的空间上下文关系作为额外的线索,实现鲁棒的视觉识别。MIC将在被遮掩的目标图像之间强行一致,其中patch随机被扣除,并且基于完整的图像通过一个指数移动平均教师模型生成伪标签。为了最小化一致性损失,网络必须学习从其上下文推断被掩蔽区域的预测。由于其简单和通用的概念,MIC可以集成到各种UDA方法中,跨越不同的视觉识别任务,如图像分类,语义分割和目标检测。
MIC
CDAC: Cross-domain Attention Consistency in Transformer for D
......长按二维码访问原文

【ICLR2023】Cross-Layer Retrospective Retrieving via Layer Attention: 2023-10-16 23:22

......长按二维码访问原文

普林斯顿陈丹琦团队:手把手教你给羊驼剪毛,5%成本拿下SOTA 2023-10-16 12:10
前言 给 Llama 2(羊驼)大模型剪一剪驼毛,会有怎样的效果呢?今天普林斯顿大学陈丹琦团队提出了一种名为 LLM-Shearing 的大模型剪枝法,可以用很小的计算量和成本实现优于同等规模模型的性能。
本文转载自机器之心
仅用于学术分享,若侵权请联系删除
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
CV各大方向专栏与各个部署框架最全教程整理
【CV技术指南】CV全栈指导班、基础入门班、论文指导班 全面上线!!
自大型语言模型(LLM)出现以来,它们便在各种自然语言任务上取得了显著的效果。不过,大型语言模型需要海量的计算资源来训练。因此,业界对构建同样强大的中型规模模型越来越感兴趣,出现了 LLaMA、MPT 和 Falcon,实现了高效的推
......长按二维码访问原文

计算机视觉中人脸识别方向和医学图像分割方向哪个比较有前景? 2023-10-16 08:00
水paper那肯定首选医学图像分割方向,不用犹豫。
随便列举几个吧
将U-Net 和Transformer结合。
此外,U-Net 在FCN 的基础上增加了上采样操作的次数和跳跃连接,使用跳跃连接将解码器的输出特征与编码器的语义特征融合,提高了分割精度,改善了 FCN 上采样不足的问题。
U-Net中没有全连接层,通过互连卷积与反卷积过程中的特征,将上下文信息传递到更高层,实现了信息补充;另外,其网络深层的卷积特征图中包含了分割的抽象特征,有利于像素分类,具有语义分割模型的端对端特点。U-Net 具有数据量需求小和训练速度快的特点,在标记数据稀缺的医学影像分割领域得到了广泛应用。然而,仅使用U-Net不能满足对小病灶分割精度的需求,因此一些研究以 U-Net 作为基准模型
......长按二维码访问原文

硕士毕业论文马上开题了,准备做医学图像分割方向,请问分割哪个部位好搞呢,创新点该怎么想? 2023-10-16 07:53
公开数据集不少,自己去看下。
至于创新的话:
随便列举几个吧
将U-Net 和Transformer结合。
此外,U-Net 在FCN 的基础上增加了上采样操作的次数和跳跃连接,使用跳跃连接将解码器的输出特征与编码器的语义特征融合,提高了分割精度,改善了 FCN 上采样不足的问题。
U-Net中没有全连接层,通过互连卷积与反卷积过程中的特征,将上下文信息传递到更高层,实现了信息补充;另外,其网络深层的卷积特征图中包含了分割的抽象特征,有利于像素分类,具有语义分割模型的端对端特点。U-Net 具有数据量需求小和训练速度快的特点,在标记数据稀缺的医学影像分割领域得到了广泛应用。然而,仅使用U-Net不能满足对小病灶分割精度的需求,因此一些研究以 U-Net 作为基准模型,此
......长按二维码访问原文

Ferret: 一个以开放词汇去理解图像的多模态大语言模型 2023-10-17 02:40
10月11日发表论文“Ferret: Refer And Ground Anything Any-Where At Any Granularity“,来自哥伦比亚大学和苹果公司。
Ferret,是一种多模态大语言模型(MLLM),能够理解图像中任何形状或粒度的空间引用,并准确地落地开放词汇的描述。 为了统一 LLM 范式中的引用和落地,Ferret 采用了一种混合区域表示,将离散坐标和连续特征联合集成在一起来表示图像中的区域。 为了提取多样(versatile)区域的连续特征,作者提出了一种空间-觉察的视觉采样器,其擅长处理包括不同形状的不同稀疏度。 因此,Ferret 可以接受不同的区域输入,例如点、边框和自由形状。 为了增强 Ferret 的期待功能,作者清洗出GRIT(Ground-and-Refer
......长按二维码访问原文

GPT-4 Vision Prompt Injection: 2023-10-16T17:42:01.000Z
Prompt injection is a vulnerability in which attackers can inject malicious data into a text prompt, usually to execute a command or extract data. This compromises the system's security, allowing unauthorized actions to be performed.
Some time ago we showed you how to use prompt injection to jailbreak OpenAI’s Code Interpreter, allowing you to install unaut
......长按二维码访问原文

Top 5 AI papers of September 2023: 2023-10-17T13:00:00+00:00
Introduction
In the ever-evolving landscape of artificial intelligence, staying updated with the latest breakthroughs is paramount. September 2023 has been a testament to the relentless pursuit of knowledge in the AI community, with researchers pushing the boundaries of what’s possible. In this article, we will cover the Top 5 AI papers of September 2023. I
......长按二维码访问原文

百度开大会,王小川伺机宣布新融资 2023-10-17 19:44

衡宇 发自 凹非寺
量子位 | 公众号 QbitAI
国内大模型,今天太热闹。
北京,百度开大会,李彦宏亲自展示文心大模型的升级,风头无两。
还是在北京,王小川大模型公司百川智能,毫无征兆地对外官宣新融资。
融资金额3亿美元,是他家官方第二次对外宣布的融资金额。
再一看这一轮(A1)公布的投资方名单,好家伙:阿里、腾讯、小米……
熟悉的名字,熟悉的竞对,在大模型时代换了马甲,激烈开展新一轮比拼。
国内最速大模型独角兽?如果不算隐退的它……
百川智能官方消息,此轮公开的是公司A1轮融资,融资金额3亿美元。
加上天使轮中,创始人王小川自带入场的5000万美元,两轮共融资3.5亿美元。
百川智能官方消息称,A1轮具体的投后估值并未对外公开,但公司已经“跻身科技独角兽行列”。
创下国内大模型初创
......长按二维码访问原文

百度“最强”大模型发布,我们第一时间实测了一波 2023-10-17 19:04
鱼羊 萧箫 发自 凹非寺
量子位 | 公众号 QbitAI
就在刚刚,文心大模型4.0版本正式发布!
北京首钢园现场,李彦宏直接放话:
文心大模型4.0综合水平与GPT-4相比已经毫不逊色。
话不多说,一起来看现场演示效果。
先来段倒装prompt:
我想回承德买房,能用公积金贷款吗?手续怎么办?我在北京工作。
不仅关键信息“北京工作”放在了最后,公积金具体是在哪里交的也没有明示。
但新版文心一言完全没有被这些小陷阱坑到,顺利给出了正确答案。
生成方面,当场剪出一整段数字人口播视频,毫不费劲:
解起数学题来也得心应手,可以说是家长辅导作业神器了(doge)。
新版文心一言还现场写起了武侠小说,即使持续添加人物角色、增加戏剧冲
......长按二维码访问原文

PyTorch官方认可!斯坦福博士新作:长上下文LLM推理速度提8倍 2023-10-17 15:28
丰色 发自 凹非寺
量子位 | 公众号 QbitAI
这两天,FlashAttention团队推出了新作:
一种给Transformer架构大模型推理加速的新方法,最高可提速8倍。
该方法尤其造福于长上下文LLM,在64k长度的CodeLlama-34B上通过了验证。
甚至得到了PyTorch官方认可:
如果你之前有所关注,就会记得用FlashAttention给大模型加速效果真的很惊艳。
不过它仅限于训练阶段。
因此,这一新成果一出,就有网友表示:
等推理加速等了好久,终于来了。
据介绍,这个新方法也是在FlashAttention的基础之上衍生而出,主要思想也不复杂:
用并行操作尽快加载Key和Value缓存,然后分别重新缩放再合并结果,
......长按二维码访问原文

7B羊驼战胜540B“谷歌版GPT”,MIT用博弈论调教大模型,无需训练就能完成 2023-10-17 14:15
克雷西 发自 凹非寺
量子位 | 公众号 QbitAI
基于博弈论,MIT提出了一种新的大模型优化策略。
在其加持之下,7B参数的Llama在多个数据集上超越了540B的“谷歌版GPT”PaLM。
而且整个过程无需对模型进行额外训练,消耗的算力资源更低。
这种基于博弈论制定的优化策略被称为均衡排名(Equilibrium Ranking)。
研究团队将大模型语言解码过程转化为正则化不完全信息博弈。
这个词可以拆解成“正则化”和“不完全信息博弈”两部分,我们将在原理详解部分展开介绍。
在博弈过程中,模型不断对生成的答案进行优化,让生成结果更加符合事实。
实验结果表明,在多个测试数据集上,均衡排名优化方式的效果显著优于其他方式,甚至其他模型。
那么,均衡排序方法具体是如何将博弈论应用到大模型当中
......长按二维码访问原文

AirPods可以“读脑”了?还是能同时监测汗液乳酸浓度的那种|Nature 2023-10-16 17:08
西风 发自 凹非寺
量子位 | 公众号 QbitAI
AirPods可以监测大脑信号了?!
还是能预测阿尔茨海默症和帕金森的那种?
最近,一款耳内传感器登上了Nature。
把它“贴”在AirPods等耳机上,不仅能监测佩戴者的脑电波,还能监测汗液中的乳酸浓度。
如此一来,得到的数据就可用于癫痫、阿尔茨海默症等神经退行性疾病的早期诊断。
关键它还很小巧插入耳朵中几乎看不见,且由柔性材料制作佩戴起来也很舒适。
研究人员将这款传感器的检测数据与市售脑电图设备和含有乳酸的血液样本数据进行了比较。结果证实,使用这种传感器收集的数据与现有方法检测出的结果基本一致。
其实早在几个月前,苹果就为AirPods申请了一项设计专利,瞄准的就是能够监测脑电图、肌电图、心电图等生物信号这个方向。
但没想到苹果这边
......长按二维码访问原文

全面的中文大语言模型评测来啦!香港中文大学研究团队发布 2023-10-16 12:40
允中 发自 凹非寺
量子位 | 公众号 QbitAI
ChatGPT 的一声号角吹响了2023年全球大语言模型的竞赛。
2023年初以来,来自工业界和研究机构的各种大语言模型层出不穷,特别值得一提的是,中文大语言模型也如雨后春笋般,在过去的半年里不断涌现。
与此同时,和如何训练大语言模型相比,另一些核心的难题同时出现在学术界和产业界的面前:究竟应该如何理解和评价中文大语言模型的能力?在中文和英文大模型的理解和评测上又应该有什么联系与区别?
带着问题的思考,我们发现,近期的一系列中文大模型的评测研究陆续呈现,尽管极大地推进了中文大语言模型理解,但仍然有一些关键的研究问题需要关注和讨论。
想要准确全面地理解和评测中文大语言模型,这些问题亟须解决:
评测数据与指标的选择需要更加全面。 传统的自动评测工作
......长按二维码访问原文

大语言模型击败扩散模型!视频图像生成双SOTA,谷歌CMU最新研究 2023-10-16 12:31
白交 发自 凹非寺
量子位 | 公众号 QbitAI
语言模型击败扩散模型,在视频和图像生成上实现双SOTA!
这是来自谷歌CMU最新研究成果。
据介绍,这是语言模型第一次在标志性的ImageNet基准上击败扩散模型。
而背后的关键组件在于视觉分词器(video tokenizer) ,它能将像素空间输入映射为适合LLM学习的token。
谷歌CMU研究团队提出了MAGVIT-v2,在另外两项任务中超越了之前最优视觉分词器。
大语言模型击败扩散模型
已经形成共识的是,大语言模型在各个生成领域都有出色的表现。比如文本、音频、代码生成等。
但一直以来在视觉生成方面,语言模型却落后于扩散模型。
团队认为,其主要原因在于缺乏一个好的视觉表示,类似于自研语言系统,能有效地对视觉世界进行
......长按二维码访问原文






