文章目录[隐藏]
- 视觉招聘小黑板
- 行业资讯
- 菲特获批筹建天津市工业AI视觉检测技术重点实验室--机器视觉网 2024-01-29 17:09:25
- 华睿科技喜获浙江省首台(套)荣誉--机器视觉网 2024-01-29 15:37:04
- 中科君达通过“安徽省企业技术中心”认定和安徽省首台套重大技术装备--机器视觉网 2024-01-29 14:38:43
- 曲面高反光表面3D缺陷检测系统图文全解--机器视觉网 2024-01-29 16:44:30
- 基于光谱成像的塑料分类解决方案--机器视觉网 2024-01-29 14:57:25
- CMOS图像传感器原理及行业应用分析--机器视觉网 2024-01-29 13:29:13
- ICLR 2024 | AnomalyCLIP:零样本异常检测的对象不可知提示学习 2024-01-28 16:59
- 2023年计算机视觉领域关键性进展 2024-01-28 15:44
- NeurIPS 2023 Spotlight | 用于真实图像去模糊的层次结合扩散模型HI-Diff 2024-01-29 10:49
- ICLR 2024 | DiffusionSat:第一个用于卫星图像的生成式基础模型 2024-01-29 11:11
- TGRS2024|基于类别级波段学习的高光谱图像分类特征提取 |北理&北航 2024-01-29 14:50
- Sketch2NeRF:多视角草图引导的文本到3D生成 2024-01-28 11:00
- ICLR 2024 Oral | 三⾏代码,即插即⽤!NUS尤洋团队新作—InfoBatch,⽆损数据集动态剪枝加速 2024-01-29 11:48
- 2023 ICML | 用于通用图像复原的可控视觉与语言模型 2024-01-29 09:43
- 3D点云目标检测网络VoxelNet简介 2024-01-28 17:17
- 机器视觉中图像处理有哪些相关知识? 2024-01-29 16:30
- 复旦最新提出!革命性的LiDAR SLAM统一架构 2024-01-29 15:19
- 资源与学习路径 2024-01-28 23:23
视觉招聘小黑板
欲了解详情,请在公众号后台回复:240129
行业资讯
菲特获批筹建天津市工业AI视觉检测技术重点实验室--机器视觉网 2024-01-29 17:09:25
2024-01-29 17:09:25 来源: 中国机器视觉网
天津市重点实验室是市科技创新体系的重要组成部分,是国家级重点实验室的后备力量,是组织高水平基础研究和应用基础研究、前沿技术研究的核心力量,是聚集和培养优秀科技人才、开展高水平学术交流的重要基地。
“十项行动”是天津全面贯彻落实党的二十大精神的生动实践,也是打开菲特公司高质量发展之门的“金钥匙”。2023年,菲特公司紧紧围绕高质量发展奋斗目标和全年指标任务,广大职工以奋斗突破、奉献担当的饱满精神状态,沉着应对百年变局,扎实推进“十项行动”往深里走、向实处做。2024年,赢战开门红,日前,天津市科技局下发《关于批准筹建天津市重点实验室的通知》,公布了新一批天津市重点实验室筹建名单,菲特申报的“天津市工业AI视觉检测技术重点实验室”获批筹建。
以中
......长按二维码访问原文

华睿科技喜获浙江省首台(套)荣誉--机器视觉网 2024-01-29 15:37:04
客户业务层ERP主要实现产品信息的下发和接收,MES主要负责输送线的调度和产品信息的传递;业务层内还包含华睿的iWMS,主要用于预冷库内的库存管理和出入库的任务分配。
调度层包含ICS、WCS、RCS,ICS负责第三方系统的对接,WCS仓库控制系统,负责仓储配套设备的调度;RCS机器人调度系统,负责AMR设备的调度。
设备层主要由AMR、仓储配套设备RGV、物流设备组成。
预冷库布局如下图4所示:
图4 预冷库布局示意图
整体作业流程示意如下图5所示,其中各个系统模块分别承担了不同的内容。
图5 整体作业流程图
主要挑战项如下:
人工将清洗的产品搬运上输送线;输送线输送产品进入预冷库;RGV自动取产品料筐码放在移动大料架上;AMR将装满的大料架搬运入库内进行存储;当有出库需求时,AMR将装满预冷
......长按二维码访问原文

中科君达通过“安徽省企业技术中心”认定和安徽省首台套重大技术装备--机器视觉网 2024-01-29 14:38:43
2024-01-29 14:38:43 来源: 中国机器视觉网
近日,安徽省经济和信息化厅官网公布了《关于2023年(第32批)安徽省企业技术中心拟认定名单的公示》,合肥中科君达视界技术股份有限公司(以下简称“公司”)成功获得“安徽省企业技术中心”认定。这是公司继国家高新技术企业、国家级专精特新“小巨人”企业后在技术创新方面实现的又一突破。
省级企业技术中心是安徽省内规格高、影响力重大的技术创新平台。认定条件包括考评企业的创新经费、创新人才、技术积累、技术产出和创新效益等多方面指标,并经过专家组评审、相关部门核查、综合评定等流程最终确认。参评的企业必须具备完善的技术创新体系,拥有自主知识产权技术并具有核心竞争力,研究开发与创新水平在全省同行业中处于领先地位。
此外,2023年第四批安徽省首台套重大技术
......长按二维码访问原文

曲面高反光表面3D缺陷检测系统图文全解--机器视觉网 2024-01-29 16:44:30
摇橹船科技自主研发的曲面高反光表面3D缺陷检测系统可帮助汽车及半导体等行业客户解决检测过程中采集数据庞大,处理时间过长、缺陷种类繁多这三大导致曲面高反光产品缺陷检测难度大的检测“痛点”。
综上,曲面高反光表面3D缺陷检测系统是摇橹船科技自主研发的又一款高端检测装备,该套装备专业地融合了机器视觉与人工智能技术,使得高反光物体的三维成像成为可能,不仅突破了传统结构光三维成像的“痛点”,还成功地解决了该领域长期存在的“堵点”,曲面高反光表面3D缺陷检测系统以其精准的检测能力,极大地满足了汽车、半导体等行业客户对降本增效的迫切需求。随着中国产业迈向高质量发展的新阶段,高端智能检测装备产业发挥着越来越重要的支撑作用,摇橹船科技始终坚持创新驱动,致力于为产业升级提供坚实的技术保障,并为智能视觉产业的高质量发展做好“守门人
......长按二维码访问原文

基于光谱成像的塑料分类解决方案--机器视觉网 2024-01-29 14:57:25
2024-01-29 14:57:25 来源: 中国机器视觉网
随着塑料工业的迅猛发展,以及塑料垃圾的不断增长,废旧塑料再生利用行业日益兴起。但由于塑料品种繁多,应用领域非常广泛,所以在回收过程中,很多不同种类及颜色的塑料被混合在一起。不同种类的塑料性能及加工条件是不同的,混合后对加工和应用的影响非常大,所以在废旧塑料回收过程中进行分选是必不可少的环节。
大多数塑料回收厂使用不同的技术,从条形码阅读器和RGB相机到X射线和涡流系统。这些传统技术虽然在一定程度上能满足简单、粗放的塑料分选,但识别材料的能力有限,并不是完美的解决方案。例如,如果塑料瓶缺少条形码,使用条形码阅读器则无法检测它是PET还是HDPE。电涡流检测器可以分辨导电金属,但不能分离塑料或纸浆。RGB相机可以将瓶子分为透明,黑色和彩色,但无法区
......长按二维码访问原文

CMOS图像传感器原理及行业应用分析--机器视觉网 2024-01-29 13:29:13
2024-01-29 13:29:13 来源: 中国机器视觉网
COMS图像传感器原理
原理
CMOS 图像传感器是一种光学传感器,是摄像头模组的核心元器件,对摄像头的光线感知和图像质量起到了关键的影响。CMOS 图像传感器首先通过感光单元阵列将所获取对象景物的亮度和色彩等信息由光信号转换为电信号;再将电信号按照顺序进行读出并通过 ADC(Analog Digital Convertor)数模转换模块转换成数字信号;最后将数字信号进行预处理,并通过传输接口将图像信息传送给平台接收。
图 CMOS 图像传感器示意图 CMOS 图像传感器是模拟电路和数字电路的集成。主要由四个组件构成:微透镜、彩色滤光片(CF)、感光二极管(PD)、电路层。
图 CMOS构成 光通过具有球形表面的微透镜后聚拢穿过彩色滤光片
......长按二维码访问原文

ICLR 2024 | AnomalyCLIP:零样本异常检测的对象不可知提示学习 2024-01-28 16:59

AnomalyCLIP:一种使 CLIP 适应不同领域的准确零样本异常检测方法,对 17 个真实世界异常检测数据集的大规模实验表明,AnomalyCLIP在工业、医疗领域上实现了卓越的零样本异常检测和分割性能!代码即将开源!
点击关注 @CVer官方知乎账号,可以第一时间看到最优质、最前沿的CV、AI、医学影像工作~
AnomalyCLIP
AnomalyCLIP: Object-agnostic Prompt Learning for Zero-shot Anomaly Detection
单位:浙大, 新加坡管理大学, 哈佛大学
代码:https://github.com/zqhang/AnomalyCLIP
论文:https://arxiv.org/abs/2310.18961
CVPR 2
......长按二维码访问原文

2023年计算机视觉领域关键性进展 2024-01-28 15:44

2023 年是聊天机器人和大型语言模型的一年(LLMs)。从 GPT-4 到 Mixtral,Llamas, Vicunas, Dolphins,几乎每天都在某个基准测试中看到一种新的最先进的模型。同时,每周在提示、微调、量化、服务LLMs等方面都有新的突破。
值得开心的是,计算机视觉在 2023 年也迎来了标志性的一年。从新的基础模型到准确的实时检测,有太多的东西可以讲了。作为总结,我选择了十一个2023年的关键性发展,跟大家共享~
NO1. YOLO重生:NextGen 目标检测
在过去十年的大部分时间里,YOLO 系列模型一直是实时目标检测任务的热门选择。在 2023 年之前,YOLO 已经经历了多次迭代,流行的变体包括 Ultralytics 的 YOLOv5 和 YOLOv8(2022
......长按二维码访问原文

NeurIPS 2023 Spotlight | 用于真实图像去模糊的层次结合扩散模型HI-Diff 2024-01-29 10:49

公众号:将门创投(thejiangmen)
作者:陈铮
本文介绍了一种新型图像去模糊模型——分层集成扩散模型(HI-Diff)。HI-Diff主要在高度压缩的潜在空间中运行扩散模型,以生成去模糊过程的先验特征。并且高度压缩的潜在空间确保了DM的效率。此外,HI-Diff采用分层集成模块,将先验与基于回归的模型在多个尺度上融合,增强了模型在处理复杂模糊场景时的泛化能力。通过在合成和真实世界模糊数据集上的全面实验,我们证明了HI-Diff超越了当前最先进的方法。
01. 研究问题
图像去模糊是计算机视觉领域的一个长期研究任务,旨在从模糊图像中恢复出清晰的图像。造成图像模糊的因素有多种,例如相机抖动、快速移动的物体等。这些因素导致的模糊在真实场景中往往是复杂且非均匀的。因此,开发有效的图像去模糊算法对于提高图
......长按二维码访问原文

ICLR 2024 | DiffusionSat:第一个用于卫星图像的生成式基础模型 2024-01-29 11:11

DiffusionSat:第一个大规模卫星图像生成基础模型,即一种基于Stable Diffusion的latent扩散模型架构的遥感数据生成基础模型,可以用于解决多种生成任务,包括高分辨率卫星图像生成、超分辨率、时序生成和修复等。
点击关注 @CVer官方知乎账号,可以第一时间看到最优质、最前沿的CV、AI、医学影像工作~
DiffusionSat
DiffusionSat: A Generative Foundation Model for Satellite Imagery
单位:斯坦福大学, Stability AI
论文:https://arxiv.org/abs/2312.03606
CVPR 2023 论文和开源项目合集请戳—> https://github.com/amusi/CVP
......长按二维码访问原文

TGRS2024|基于类别级波段学习的高光谱图像分类特征提取 |北理&北航 2024-01-29 14:50
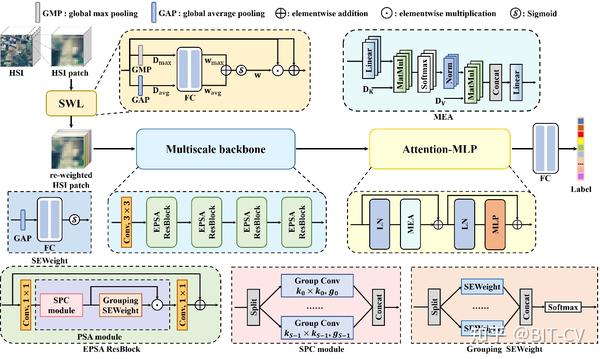
遥感顶刊:IEEE Transactions on Geoscience and Remote Sensing(TGRS2024)
主题:基于类别级波段学习的高光谱图像分类特征提取 Category-Level Band Learning-Based Feature Extraction for Hyperspectral Image Classification
作者:Ying Fu, Hongrong Liu, Yunhao Zou, Shuai Wang, Zhongxiang Li, and Dezhi Zheng
单位:北京理工大学,北京航空航天大学
原文地址:https://ieeexplore.ieee.org/document/10360444
代码链接:https://github.
......长按二维码访问原文

Sketch2NeRF:多视角草图引导的文本到3D生成 2024-01-28 11:00
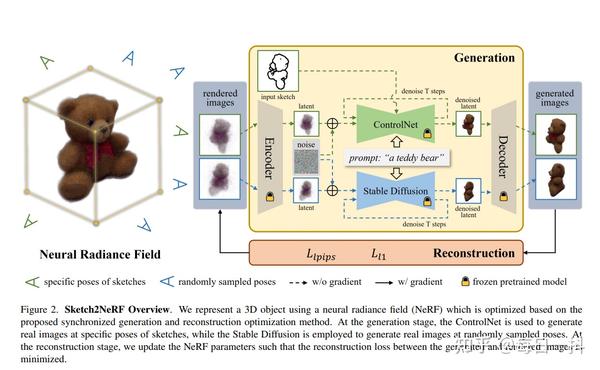
Sketch2NeRF: Multi-view Sketch-guided Text-to-3D Generation
标题:Sketch2NeRF:多视角草图引导的文本到3D生成
地址: https://arxiv.org/pdf/2401.14257.pdf
摘要:最近,文本到3D的方法已经在使用文本描述生成高保真度的3D内容方面取得了成功。然而,生成的对象是随机的,并且缺乏细粒度的控制。草图提供了一种廉价的方法,可以引入这种细粒度的控制。然而,由于草图的抽象性和模糊性,从这些草图中实现灵活的控制是具有挑战性的。在本文中,我们提出了一个多视角草图引导的文本到3D生成框架(即Sketch2NeRF),以在3D生成中添加草图控制。具体而言,我们的方法利用预训练的2D扩散模型(例如,稳定扩散和Control
......长按二维码访问原文

ICLR 2024 Oral | 三⾏代码,即插即⽤!NUS尤洋团队新作—InfoBatch,⽆损数据集动态剪枝加速 2024-01-29 11:48
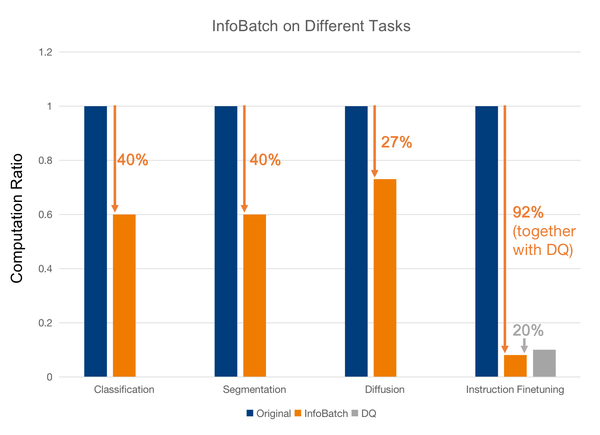
公众号:将门创投(thejiangmen)
作者:Ziheng Qin
随着深度学习的网络参数量和数据集规模增长,算力需求日益增加,如何节省训练成本正在成为逐渐凸显的需求。现有的数据集压缩方法大多开销较高,且难以在达到无损的情况下获得可观的节省率;加权抽样的相关方法则对于模型和数据集的特点较为敏感且依赖于重复抽样假设,在实际应用中难以和已完成调参的学习率调整策略结合。两种从数据角度出发的方法在实践中很难真正帮助节省计算。
在本篇工作中,研究者从数据迭代这个角度切入进行了研究。长久以来,数据集的迭代方式大都采用随机迭代。对此,作者提出了InfoBatch框架,根据网络对样本的拟合情况进行动态剪枝采样的方法,并利用重缩放(rescaling)来维持剪枝后的梯度更新(Gradient Update)期望,以此在
......长按二维码访问原文

2023 ICML | 用于通用图像复原的可控视觉与语言模型 2024-01-29 09:43

本次分享一篇通用图像复原文章,在传统单一任务的基础上进行通用任务的图像复原。本文于2023年发表于ICML 基于Diffsion Model的图像复原任务的延伸,利用了CLIP进行提示,进行图像复原任务的延伸,简称DA CLIP,第一作者来自瑞典的Uppsala University。
原文:
Luo, Z., Gustafsson, F. K., Zhao, Z., Sjölund, J., & Schön, T. B. (2023). Controlling vision-language models for universal image restoration.arXiv preprint arXiv:2310.01018.
一、背景
文章贡献包括两方面,一个是
......长按二维码访问原文

3D点云目标检测网络VoxelNet简介 2024-01-28 17:17
前面的文章介绍了点云目标检测的几篇综述文献,这一篇参考第二篇综述介绍一些经典的网络,主要包含其大体内容、贡献点和一些细节,后续还会慢慢补充。
半夜打老虎:深度学习3D目标检测综述文献一
半夜打老虎:深度学习3D目标检测综述文献二
VoxelNet
PDF: https://arxiv.org/abs/1711.06396
CODE: https://github.com/skyhehe123/VoxelNet-pytorch
大体内容
不同于piontNet等直接在点云上操作,VoxelNet将点云空间划分成相同大小体素格子,然后记录每个体素里面的点,对每个体素里面的点进行采样并借助多个VFE层提取出点云特征,然后通过一个中间卷积层(由于VFE输出是4维张量,所以采用的3D卷积),扩大感受野的同时
......长按二维码访问原文

机器视觉中图像处理有哪些相关知识? 2024-01-29 16:30

1、图像灰度均值是对平均灰度的一种度量,反映了图像的亮度,均值越大说明图像亮度越大,反之越小。图像灰度方差反映了图像像素值与均值的离散程度,标准差越大说明图像的质量越好。
2、采样间隔值越小,空间分辨率(图像中可分辨的最小细节)越高,图像质量越好,图像数据量越大。(图像质量指人们对一幅图像视觉感受的主观评价)
3、检测图像边缘的数学方法:图像梯度、差分和卷积。有限差分滤波器、高斯滤波器、Canny边缘检测器。
4、高通、低通滤波器:频率低的地方是较平滑的,因为平滑的地方灰度值变化比较小;频率高处通常是边缘或者噪声,因为这些地方往往是灰度值突变的。
(1)高通(锐化)滤波器保留远离频谱图中心的高频部分,舍弃掉靠近频谱图中心的低频部分。通常会保留图像的边界,即突出边缘。
(2)低通(平滑)滤波器保留靠近频
......长按二维码访问原文

复旦最新提出!革命性的LiDAR SLAM统一架构 2024-01-29 15:19
SLAM是机器人和自动驾驶领域中的一个基本问题,旨在在探索环境的同时重建地图并估计机器人在其中的位置。激光雷达的点云数据被广泛应用于捕捉环境的复杂三维结构。然而,现有的SLAM方法要么依赖于密集的点云数据以实现高精度定位,要么使用通用的描述符来减小地图的大小。这两个方面似乎存在冲突。因此,我们提出了一种统一的架构,DeepPointMap(DPM),在这两个方面都具有出色的优势。
移步公众号「3DCV」第一时间获取工业3D视觉、自动驾驶、SLAM、三维重建、最新最前沿论文和科技动态。
推荐阅读
1、基于NeRF/Gaussian的全新SLAM算法
2、移动机器人规划控制入门与实践:基于Navigation2
3、自动驾驶的未来:BEV与Occupancy网络全景解析与实战
......长按二维码访问原文

资源与学习路径 2024-01-28 23:23

视频及相关的内容生成与处理大约有以下的途径:
人工:通过拍摄与剪辑来生成处理
自动化处理:
通过 AIGC 来生成
通过 CG(计算机图形学)技术来生成
通过 CV(计算机视觉)技术来理解及进行处理
本文记录相关的资源及学习路径。
视频剪辑及程序化处理
剪映:剪映太好使了,里面有很多 AI 功能,很有帮助。vip 值得订阅,不贵。
DaVinci Resolve:达芬奇,一站式音视频处理平台,免费版已经足够强大了。达芬奇几千页的官方手册,也够使了。
图像编辑推荐 affinity photo,不贵。这里不推荐 Adobe 系列,那玩意太贵。
python 基础
[book] python 精粹,David M. Bealey。 一本300页的小书,能够快速浏览 python 的语
......长按二维码访问原文







