文章目录[隐藏]
- 视觉招聘小黑板
- 行业资讯
- Teledyne FLIR IIS 推出超小体积的模块化面阵相机Dragonfly S--机器视觉网 2024-02-23 13:40:36
- 劳易测新品测量和检测二合一的解决方案ODT 3CL1-2M--机器视觉网 2024-02-23 10:51:42
- 沃德普摄像头模组外框胶水检测案例--机器视觉网 2024-02-23 15:40:40
- 基于轻辙视觉引擎高精度测量优势,助力木材加工厂自动化品质管控--机器视觉网 2024-02-23 15:00:20
- 基于机器视觉的点胶视觉检测方案--机器视觉网 2024-02-23 14:51:24
- 机器视觉行业中连通性的重要作用--机器视觉网 2024-02-23 14:39:16
- 深入汽车产线,视比特全车身防呆在线检测系统精准护航整车质量--机器视觉网 2024-02-23 14:11:10
- 基于5G 的工业AI视觉检测系统应用--机器视觉网 2024-02-23 13:55:07
- 适用于Visionary-T Mini AP的体积测量软件―产品聚焦频道- 视觉系统设计 2024/2/22 23:11:55
- 思特威推出具有AOV快启功能的5MP高分辨率IoT图像传感器―产品聚焦频道- 视觉系统设计 2024/2/22 23:05:58
- 机器视觉系统集成怎么做―技术与应用频道- 视觉系统设计 2024/2/22 22:58:13
- 阿丘科技助力硅片分选解决方案再升级―技术与应用频道- 视觉系统设计 2024/2/22 22:52:56
- YOLOv9来咧!YOLOv7团队新作 2024-02-22 17:53
- 炸场!神经网络扩散来了!扩散模型可以生成高性能神经网络参数 2024-02-23 12:13
- EfficientViT-SAM重磅开源!加速分割一切模型而不会造成性能损失 2024-02-23 17:18
- 改进何恺明的MAE!谷歌新作VideoPrism:视频理解的基础视觉编码器 2024-02-22 22:50
- Talk|北京理工大学陈焕然:损失函数景观与泛化性的关系 2024-02-23 12:00
- 视觉常用的目标识别方法有三种:Blob分析法、模板匹配法、深度学习法 2024-02-22 14:53
- LLD-MMRI2023 多相位MR肝脏病变诊断数据集介绍 2024-02-23 09:54
- 【文章精读】An image is worth 16X16 words transformers for image recognition at scale 2024-02-23 08:49
- 【论文精读】IBOT 2024-02-22 22:37
- 提示文本理解更好,图像质量更强的Stable Diffusion 3来啦! 2024-02-23 10:47
- image:
- How to Train a YOLOv9 Model on a Custom Dataset: 2024-02-23T11:52:55.000Z
- LLMs on DO+PS Multinode H100s: Pretraining and Finetuning MosaicML Models: 2024-02-22T17:00:25.000Z
视觉招聘小黑板
欲了解详情,请在公众号后台回复:240223
行业资讯
Teledyne FLIR IIS 推出超小体积的模块化面阵相机Dragonfly S--机器视觉网 2024-02-23 13:40:36
2024-02-23 13:40:36 来源: 中国机器视觉网
在龙年这个充满活力与创新的年份,我们迫不及待要为你揭晓一项新惊喜:Teledyne FLIR IIS 推出新款模块化紧凑型 USB3 机器视觉相机系列Dragonfly S 系列,为科技界献上一份特别的贺礼。
自古以来,龙在我国文化中占据着举足轻重的地位,成为了民族精神的象征。在传统文化中,龙被视为道德和智慧的化身,代表着追求精神境界和智慧的力量。正如Teledyne在企业文化中的精神内涵,追求卓越,不断创新,以满足时代发展的需求。
小巧轻便的全新 Dragonfly S 相机系列是嵌入式或手持式应用的理想选择
Dragonfly S 的模块化设计可加快各类工业和非工业领域的成像应用开发周期。“对于工厂自动化和嵌入式视觉设备制造商来说,这可
......长按二维码访问原文

劳易测新品测量和检测二合一的解决方案ODT 3CL1-2M--机器视觉网 2024-02-23 10:51:42
2024-02-23 10:51:42 来源: 中国机器视觉网
外壳小,工作范围大,得益于TOF技术(飞行时间技术),劳易测的新型ODT3CL1-2M紧凑型漫反射传感器的工作范围可达两米。这个二合一传感器可以在检测物体的同时传输测量值。
ODT3CL1-2M解决了检测任务,并为机器控制提供了距离信息。该传感器还可以检测距离达两米的彩色结构化物体
凭借新型ODT3CL1-2M激光漫反射传感器,劳易测的传感器专家正在扩大其3C系列距离传感器的工作范围。得益于创新的飞行时间(TOF)技术,具有背景抑制功能的开关和测量传感器ODT3CL1-2M工作范围可达两米。这使得它适用于内部物流中需要跨越长距离的多种应用:例如,用于监控货物位置的自动引导车、控制机器人抓取器或质量控制。即使在恶劣条件下也能保证可靠地使用。
......长按二维码访问原文

沃德普摄像头模组外框胶水检测案例--机器视觉网 2024-02-23 15:40:40
2024-02-23 15:40:40 来源: 中国机器视觉网
一、检测背景
高端智能产品普及下应运而生的摄像模组产业也进入蓬勃发展阶段。摄像头模组,全称Compact Camera Module,简写为CCM,是影像捕捉至关重要的电子器件。摄像头模组结构非常精细,内部多处元件有点胶工艺要求。而手机摄像头模组的外框,是固定内部元件结构也保护内部元件。其点胶工艺也需要精确无误,多胶、溢胶、少胶或是胶水出现异常都会对后续使用产生影响。
二、检测项目
三、检测方案
观察到胶水的缺陷种类比较多,单一同轴光源呈现明场效果并不能将缺陷完全检测,因此我们加上低角度环形光源,呈现出暗场效果,能将部分明场呈现不出的效果补全。
同轴光源明场效果:
环形光源暗场效果:
打光示意图
四、产品介
......长按二维码访问原文

基于轻辙视觉引擎高精度测量优势,助力木材加工厂自动化品质管控--机器视觉网 2024-02-23 15:00:20
2024-02-23 15:00:20 来源: 中国机器视觉网
轻辙视觉引擎
轻辙视觉引擎是以低代码为基础,深度学习技术为核心的视觉业务流程编排引擎,用于快速搭建部署复杂视觉检测流程软件方案。
轻辙视觉引擎,轻量级产品实现高效应用
作为深眸科技的核心产品之一,轻辙视觉引擎是基于云原生技术实现的视觉应用产品,也是一个开放的二次开发视觉平台。其具备自定义丰富的个性化视觉功能,能够衍生更多视觉应用,包括高性能检测和测量,其视觉检测能力以99.9%为基准,系统可用性以99.99%为基础,大幅提高可用视觉服务。
核心功能
产品优势
优势1:自定义业务流程
系统将常见的功能都提前开发好放入平台内,用户仅需要把自己需要的功能挑选出来,如搭建积木般的搭建业务流程,轻松,快速,易于调整。
优势2:模块化功能
......长按二维码访问原文

基于机器视觉的点胶视觉检测方案--机器视觉网 2024-02-23 14:51:24
2024-02-23 14:51:24 来源: 中国机器视觉网
光学评估
在点胶缺陷检测系统的设计过程中,需要对光学检测时的硬件进行选型。如图所示,考虑到胶条为透明胶,存在反光现象,所以要求光源在各个角度的光照程度较为均匀,而同轴光具有高密度排列,成像清晰,亮度均匀等特点。
此外,在要求光照亮度均匀的同时,由于部分胶条中存在气泡,而同轴光源距离胶条存在一定的距离,采集到的图片无法观察到气泡特征, 故考虑使用条形光源对胶条上方进行照射,使得气 泡特征可见。由于垂直照射方式具有照射面积大、 光照均匀性好等优点,故同轴光源选择垂直照射方式,而条形光源主要是为了对胶条进行光照加强, 同时为了不遮挡同轴光源,故选择侧面照射。
缺陷定义
点胶缺陷的类别定义在实际的点胶过程中,往往因为点胶量的大小、 点胶压力、
......长按二维码访问原文

机器视觉行业中连通性的重要作用--机器视觉网 2024-02-23 14:39:16
2024-02-23 14:39:16 来源: 中国机器视觉网
从制造过程到医疗诊断,机器视觉技术彻底改变了我们认知世界的方式。这个十分先进的领域在很大程度上依赖于机器查看和解释视觉数据的能力,使其成为很多行业自动化和质量控制的重要组成部分。连通性在提高机器视觉系统的效果和效率方面发挥着至关重要的作用。请继续阅读,了解机器视觉行业中连通性的各 个组成部分及其极为重要的作用。
机器视觉连通性组件
摄像头和传感器:机器视觉的中心是捕获图像和数据的摄像头和传感器。这些设备 负责获取视觉信息,它们的连通性对于数据传输和控制至关重要。现代相机通常具有各种接口,例如GigE Vision、USB或 CoaxPress,以确保无缝的数据传输。
影像截取卡:影像截取卡相当于相机和计算机之间的中介,从摄像机中捕获数据并使
......长按二维码访问原文

深入汽车产线,视比特全车身防呆在线检测系统精准护航整车质量--机器视觉网 2024-02-23 14:11:10
2024-02-23 14:11:10 来源: 中国机器视觉网
随着消费者对汽车个性化需求的不断提升,汽车主机厂在造型、颜色和配置等方面提供了各式各样的方案以满足市场需求。生产需求的日益多样化和复杂性,也使得整车装配过程易出现错装、漏装、混装等问题,为汽车总装质量控制带来了极大挑战。
为解决上述行业痛点,视比特为汽车主机厂量身定制了全车身防呆在线检测系统,采用自研AI视觉技术,实时、精准、全方位检测车身外观,兼容多型号产品,灵活性高,有效拦截并防止缺陷车辆流出。
全车身防呆在线检测系统
系统为新车出厂把好最后一道检测工序,确保每一辆下线汽车都达到高质量标准,为汽车制造商降低售后成本、减少客户投诉、在市场竞争中脱颖而出增添了有力武器。
基于自研AI视觉车身防呆准确率≥99.9%
系统基于以数据为中
......长按二维码访问原文

基于5G 的工业AI视觉检测系统应用--机器视觉网 2024-02-23 13:55:07
2024-02-23 13:55:07 来源: 中国机器视觉网
摘要:在数字化浪潮的驱动下,5G、MEC、云计算、AI等新兴技术手段不断与制造业融合,并逐步走向应用推广。视觉检测是工业生产的重要环节,针对格力工业视觉检测需求,设计了基于5G的工业AI视觉检测系统,并对系统的工作原理、架构、功能及系统在实际生产环境下的测试结果进行了详细介绍。最后结合智能制造产业升级和5G技术的推广与发展需求对系统应用前景进行了价值分析。
关键词:智能制造;视觉检测;AI;5G;MEC
前言
机器视觉检测是指利用机器替代人工实现检测和判断[1]。典型的机器视觉检测系统包括相机、镜头、光源、工控机、图像处理系统、执行机构、被测物等。其检测原理是通过相机对被测对象进行图像拍摄,然后将图像数据传送至图像处理系统。图像处理系统通过
......长按二维码访问原文

适用于Visionary-T Mini AP的体积测量软件―产品聚焦频道- 视觉系统设计 2024/2/22 23:11:55
非常高兴地向大家介绍Visionary 3D视觉系列推出的全新软件产品 – 适用于Visionary-T Mini AP的体积测量功能软件。
此款软件可搭载到传感器—Visionary-T Mini AP上,直接输出测量结果。无须额外工控机运行软件。
产品描述
Visionary T-Mini 因其体积小,视野大,抗光性强,高帧率的特点,使其非常适用于交叉带分拣机等有体积测量和灰度仪需求的应用场景。且因Visionary-T Mini AP的高帧率,大视野特点,本产品可适应高达2.5m/s线速度的流道。
体积检测软件应用会检查您配置的3D检测区域,标定平面后,若检测到3D物体,可根据物体的点云数据自动计算。输出被测物体的以下数据:
► 被测物体的有无
► 被测物体的位置坐标
► 被测物体的长宽高数
......长按二维码访问原文

思特威推出具有AOV快启功能的5MP高分辨率IoT图像传感器―产品聚焦频道- 视觉系统设计 2024/2/22 23:05:58
近日,技术先进的CMOS图像传感器供应商思特威(SmartSens,股票代码688213),宣布推出5MP高分辨率快启物联网IoT系列图像传感器新品——SC535IoT。这款背照式新品搭载SmartClarity®-3技术、Lightbox IR®技术以及第二代SmartAEC™技术,支持近红外感度增强、全时录像、高动态范围三大功能,兼顾超低功耗性能,为高端物联网相机带来更加出色的夜视全彩成像表现,可满足智能家居视觉系统对更高分辨率的需求。
此次发布的SC535IoT采用2592Hx1944V分辨率设计,以4:3画幅规格提供更大的垂直空间,并支持双目拼接,更好地赋能球形全景相机与鱼眼摄像头等物联网新机型,为家用IoT摄像头以及其他物联网场景的高效运作提供关键的支持。
先进第二代SmartAEC™技术,成就卓
......长按二维码访问原文

机器视觉系统集成怎么做―技术与应用频道- 视觉系统设计 2024/2/22 22:58:13
机器视觉(Machine Vision)作为光电技术应用的一个特定领域,目前已经发展成为一个前景光明、活力无限的行业,年平均增长速度超过2O% 。机器视觉广泛应用于微电子、电子产品、汽车、医疗、印刷、包装、科研、军事等众多行业。涉及技术一致,应用差异明显,是各种机器视觉应用系统的共同特点。
机器视觉系统集成时,涉及到多门技术,最基本的系统也需要照明、成像、图像数字化、图像处理算法、计算机软件硬件等,稍微复杂一点的系统还会用到机械设计、传感器、电子线路、PLC、运动控制、数据库、SPC等等。要把这么多不同方面的技术和知识组合到系统里,使其相互完美配合并稳定地工作,对系统集成人员提出了很高的要求。作者根据多年的经验,讲解了机器视觉系统集成时所涉及的各种技术、需要综合考虑的因素以及评估机器视觉系统项目成功的可能性的
......长按二维码访问原文

阿丘科技助力硅片分选解决方案再升级―技术与应用频道- 视觉系统设计 2024/2/22 22:52:56
硅片生产是光伏产业链上游的核心环节,为后续制造更高发电效率的光伏组件提供有力保障。随着市场对硅片品质的要求不断提高,硅片生产过程中的检测维度需更加精细,涵盖外观缺陷、尺寸、数量、平整度、距离和定位等高精度检测。
特别在生产工艺后段,品质管控的标准达到了新的高度。硅片在经历切割、清洗、烘干等工序后,将进行缺陷检测,然后直接包装出货。如何在高速产线上可靠识别、稳定检出缺陷,对 AI 的算法能力提出巨大挑战。
阿丘科技,助力光伏生产可靠运行
阿丘科技拥有丰富的落地经验和持续创新的技术积累,针对多个行业细分场景推出“最优系统”定制开发和 AI 解决方案,积极推进行业自动化,为客户提供更优质的选择。
AIDI 专业级工业AI视觉算法平台软件内置八大 AI 功能,可用于解决复杂缺陷的定位、检测、分类及字符识别等问题
......长按二维码访问原文

YOLOv9来咧!YOLOv7团队新作 2024-02-22 17:53
论文:
github代码
主要内容
主要是提出了两点:
一、提出使用PGI(Programmable Gradient Information,可编程梯度信息)来解决信息瓶颈问题和深度监督机制不适合轻量级神经网络的问题。
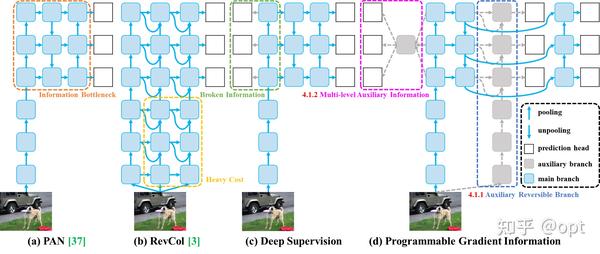
论文中图3
图中(d)为提出的PGI。PGI主要包括三个组成部分,即(1)主分支,(2)辅助可逆分支,(3)多级辅助信息。其中推理过程仅使用 main 分支,因此不需要任何额外的推理成本。辅助可逆分支(auxiliary reversible branch)处理神经网络深化带来的问题。网络深化会造成信息瓶颈。多级辅助分支(multi-level auxiliary information),旨在处理深度监管导致的误差累积问题。
二、设计了GELAN(Generalized
......长按二维码访问原文

炸场!神经网络扩散来了!扩散模型可以生成高性能神经网络参数 2024-02-23 12:13
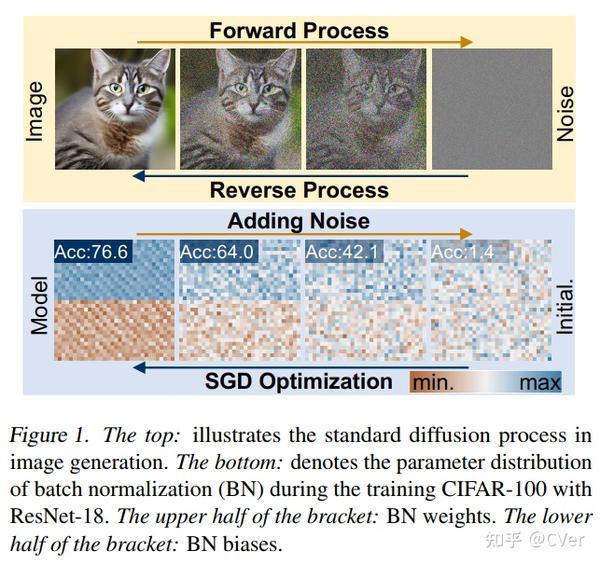
生成不限于图像,视频,而是生成新参数!好家伙!本文观察并证明扩散模型可以用来生成高性能和新颖的神经网络参数,证明了它们的优越性!使用扩散进行神经网络参数更新是深度学习中一种潜在的新范式,太强了!代码已开源!
点击关注 @CVer官方知乎账号,可以第一时间看到最优质、最前沿的CV、AI、3D视觉工作~
Neural Network Diffusion
单位:NUS(尤洋团队), UC伯克利, Meta(刘壮)
论文:https://arxiv.org/abs/2402.13144
CVPR 2023 论文和开源项目合集请戳—> https://github.com/amusi/CVPR2023-Papers-with-Code
ICCV 2023 论文和开源项目合集请戳—> https://githu
......长按二维码访问原文

EfficientViT-SAM重磅开源!加速分割一切模型而不会造成性能损失 2024-02-23 17:18
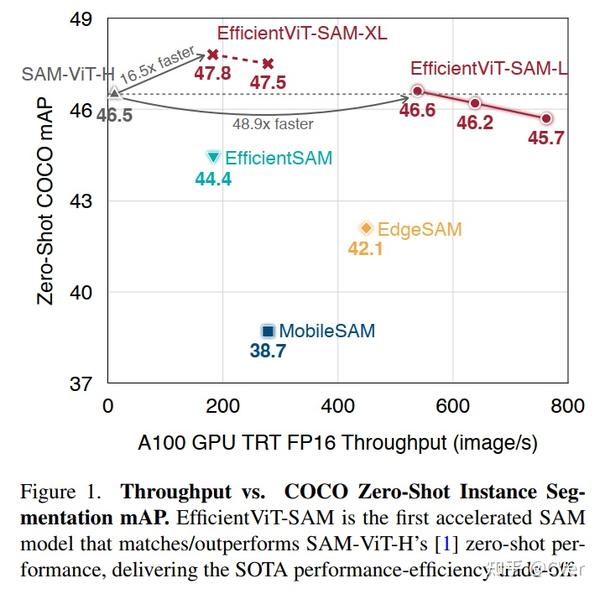
加速 48.9 倍!EfficientViT-SAM:第一个加速 SAM 模型,它能匹配/优于 SAM-ViT-H 的零样本性能,实现了 SOTA 性能与效率的权衡,代码刚刚开源!
点击关注 @CVer官方知乎账号,可以第一时间看到最优质、最前沿的CV、AI、3D视觉工作~
EfficientViT-SAM
EfficientViT-SAM: Accelerated Segment Anything Model Without Performance Loss
单位:清华大学, MIT(韩松团队), NVIDIA
代码:https://github.com/mit-han-lab/efficientvit
论文:https://arxiv.org/abs/2402.05008
CVPR 2023
......长按二维码访问原文

改进何恺明的MAE!谷歌新作VideoPrism:视频理解的基础视觉编码器 2024-02-22 22:50
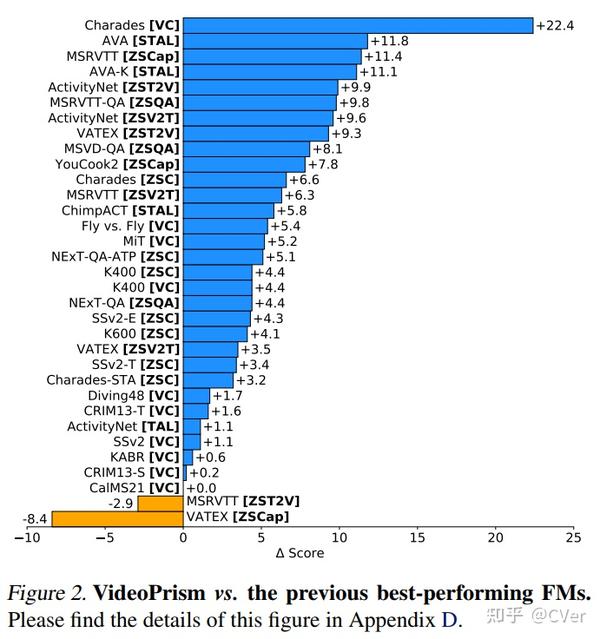
VideoPrism:一种基础视频编码器,出色改进了何恺明的掩码自编码器,在各种视频理解任务上的30个基准测试中实现最先进的性能,优于VideoMAE-v2、InternVideo等网络。
点击关注 @CVer官方知乎账号,可以第一时间看到最优质、最前沿的CV、AI、3D视觉工作~
VideoPrism
VideoPrism: A Foundational Visual Encoder for Video Understanding
单位:Google
论文:https://arxiv.org/abs/2402.13217
CVPR 2023 论文和开源项目合集请戳—> https://github.com/amusi/CVPR2023-Papers-with-Code
ICCV 2023 论文和
......长按二维码访问原文

Talk|北京理工大学陈焕然:损失函数景观与泛化性的关系 2024-02-23 12:00

公众号:将门创投(thejiangmen)
本期为TechBeat人工智能社区第573期线上Talk。
这次我“门”有幸邀请到,北京理工大学本科生—陈焕然来到TechBeat人工智能社区,为我们分享主题为“损失函数景观与泛化性的关系”,Talk已在TechBeat人工智能社区上线!【点击这里】,即可马上免费观看!
本次Talk中,他介绍了他们在发现loss landscape closeness也和泛化性强相关等相关工作所做的研究。
Talk·介绍
之前我们已经了解到loss landscape的平坦性与泛化性强相关。那么,除了平坦性外,还有什么性质和泛化性有关呢?在这篇工作中,我们发现loss landscape closeness也和泛化性强相关。我们证明了对于任何一个有方差的分布,通过优化clo
......长按二维码访问原文

视觉常用的目标识别方法有三种:Blob分析法、模板匹配法、深度学习法 2024-02-22 14:53
传统方法做目标识别大多都是靠人工实现,从形状、颜色、长度、宽度、长宽比来确定被识别的目标是否符合标准,已广泛应用于一些简单的项目中,但随着被识别物体的变动,所有的规则和算法都要重新设计和开发,即使是同样的产品,不同批次的变化都会造成不能重用的现实。
而随着机器学习,深度学习的发展,很多肉眼很难去直接量化的特征,深度学习可以自动学习这些特征,视觉常用的目标识别方法有三种:Blob分析法、模板匹配法、深度学习法。
Blob分析法
图像中的具有相似颜色、纹理等特征所组成的一块连通区域,Blob分析是对图像中相同像素的连通域进行分析,将图像进行二值化,分割得到前景和背景,然后进行连通区域检测,从而得到Blob块的过程。简单来说,blob分析就是在一块“光滑”区域内,将出现“灰度突变”的小区域寻找出来。
举例来说
......长按二维码访问原文

LLD-MMRI2023 多相位MR肝脏病变诊断数据集介绍 2024-02-23 09:54
数据集信息
LLD-MMRI2023 (Liver Lesion Diagnosis Challenge on Multi-phase MRI) 是一个用于提高肝脏病变诊断准确性的MRI 数据集,旨在推动计算机辅助诊断系统的发展。相比于传统的 MRI det 任务,LLD-MMRI2023 有配准后的 8 个 phase 的 MRI 数据,提供了丰富的多模态视觉线索。LLD-MMRI2023数据集包含完整的体素数据、病变的边界框和预裁剪的 ROI(发布者根据边界框)。数据集涵盖7种不同的肝脏病变类型,包括4种良性类型(肝血管瘤、肝脓肿、肝囊肿和局灶性结节性增生)和3种恶性类型(肝内胆管癌、肝转移瘤和肝细胞性癌)。参与者需要对每个案例中的肝脏病变类型进行诊断。数据集的比例为:训练案例316个,验证案例78个,测
......长按二维码访问原文

【文章精读】An image is worth 16X16 words transformers for image recognition at scale 2024-02-23 08:49
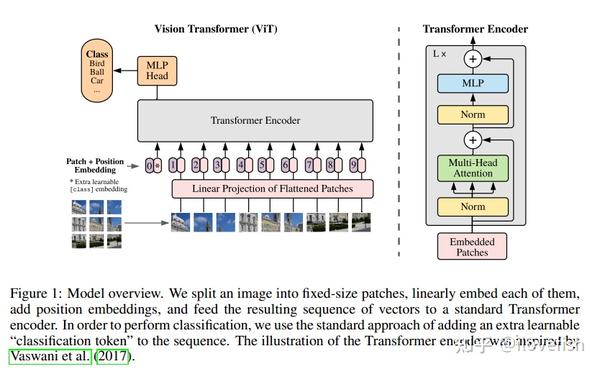
这是一篇引用次数非常高的文章,基本上这几年跟Transformer有关的文章必引。
现存问题:
在NLP中,Self-attention结构的效果很好,由于transformer模型的计算有效性和可扩展性,模型可以配备超大参数,并且可容纳更多的数据。 在视觉领域,有很多工作也尝试将cnn结构和self-attention结合起来,但效果不是很好,且扩展性不强。
作者为了解决,提出了什么假设,解决办法:
由于transformer scaling在NLP领域的成功,我们也尝试将其直接照搬用于图像。我们直接将一张图划分为patches,然后计算这些patches的embedding作为transformer的输入。这些patches类似于NLP中的tokens。
当我们在中等规模的数据集(如ImageNe
......长按二维码访问原文

【论文精读】IBOT 2024-02-22 22:37
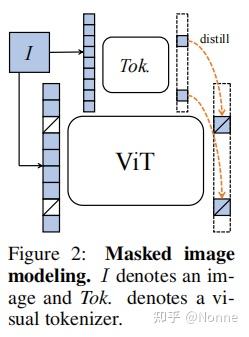
摘要
掩码语言建模(MLM)是一种流行的语言模型预训练范式,在nlp领域取得了巨大的成功。然而,它对视觉Transformer (ViT)的潜力尚未得到充分开发。为在视觉领域延续MLM的成功,故而探索掩码图像建模(MIM),以训练更好的视觉transformer,使其可以像NLP一样作为标准组件。
MLM最关键的问题是语言标记器(lingual tokenizer),其功能是将语言分成语义上有意义的标记。类似,MIM的关键也在于视觉标记器(vision tokenizer)的设计,以及实际要训练的目标网络(target network)。但是,由于图像的连续特性,视觉语义的提取非常困难,故而以往Beit等算法都是分步先计算tokenizer,在根据tokenizer训练target network。然而,由
......长按二维码访问原文

提示文本理解更好,图像质量更强的Stable Diffusion 3来啦! 2024-02-23 10:47
2月23日,著名大模型开源平台stability.ai在官网推出了——Stable Diffusion 3。
该版本与Stable Diffusion 2相比,在文本语义理解、色彩饱和度、图像构图、分辨率、类型、质感、对比度等方面大幅度增强,可对标闭源模型Midjourney。
Stable Diffusion 3的参数在8亿——80亿之间,也就是说Stable Diffusion 3可能是专为移动设备开发的,AI算力消耗将更低,推理速度却更快。
目前,Stable Diffusion 3支持申请使用,未来会扩大测试范围。
申请地址:https://stability.ai/stablediffusion3
公号:天网AI,可使用GPT/DALL-E/Claude/MJ/SD等AI工具
......长按二维码访问原文

image:
......长按二维码访问原文

How to Train a YOLOv9 Model on a Custom Dataset: 2024-02-23T11:52:55.000Z
On February 21st, 2024, Chien-Yao Wang, I-Hau Yeh, and Hong-Yuan Mark Liao released the “YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information'' paper, which introduces a new computer vision model architecture: YOLOv9. Later, the source code was made available, allowing anyone to train their own YOLOv9 models.
According to the proj
......长按二维码访问原文

LLMs on DO+PS Multinode H100s: Pretraining and Finetuning MosaicML Models: 2024-02-22T17:00:25.000Z
We run large language model (LLM) pretraining and finetuning end-to-end using Paperspace by DigitalOcean's multinode machines with H100 GPUs. 4 nodes of H100×8 GPUs provide up to 127 petaFLOPS of compute power, enabling us to pretrain or finetune full-size state-of-the-art LLMs in just a few hours.
In this blogpost, we show how this process proceeds in prac
......长按二维码访问原文







